【PyTorch实战演练】基于全连接网络构建RNN并生成人名
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文基于PyTorch中的全连接模块 nn.Linear() 构建RNN,并使用人名数据训练RNN,最后使用RNN生成人名。
1. RNN简介
循环神经网络(Recurrent Neural Network,简称RNN)是一种深度学习模型,我在之前的文章介绍过RNN的结构及算法基础——基于Numpy构建RNN模块并进行实例应用(附代码)这里不再赘述。

RNN独特之处在于它能够处理序列数据,并且在处理过程中,上一时刻的隐藏状态会作为当前时刻的一部分输入。这种结构使得RNN具有捕捉和处理时间序列数据中长期依赖关系的能力,非常适合于自然语言处理、语音识别、音乐生成等各种涉及时序数据的任务。
这里再介绍下根据输入输出长度的RNN分类:
-
1 vs 1 RNN: 在这种结构中,网络接受一个单一时间步长的输入,并产生一个单一时间步长的输出。这通常用于处理不需要考虑时序依赖或只需要针对单个输入元素生成单个输出元素的任务,例如情感分析或文本分类,其中每个样本代表整个输入。
-
1 vs N RNN: 这种结构接收一个单独的时间步长作为输入,但产生一个包含多个时间步长的输出序列。例如,在音乐创作或者生成任务中,模型可能从一个音符开始,然后预测接下来的一系列音符,形成一段旋律。
-
N vs 1 RNN: 此类RNN接受一个包含多个时间步长的输入序列,但只输出一个单一的总结性结果。例如,在文本摘要任务中,模型读取一整段文本(可能是多个句子),然后生成一个简洁的总结;或者是语音识别任务,输入是一段音频信号,输出是识别出的一个词或一句话。
-
N vs N RNN: 它处理同样长度不同的输入和输出序列。比如在机器翻译中,源语言句子被转换为目标语言句子,两者长度往往不等,但经过处理后成为等长的序列。每一个时间步,RNN都会基于之前的隐藏状态和当前输入计算新的隐藏状态,并输出对应位置的预测值。Seq2Seq模型中的Encoder-Decoder结构就是典型的N vs N结构,其中Encoder将输入序列编码为固定长度的上下文向量,而Decoder则根据该上下文向量逐步解码出目标序列。
2. 实例说明
本文使用人名数据,具体来说是日文中的姓氏数据来训练RNN。训练后,给定首写字母使用训练好的RNN生成名字的剩余部分。
为什么使用小日子的姓氏呢?因为我只有这个数据。。。
2.1 训练数据
日文中的姓氏:

总共992个名字。
需要源文件可以评论留下邮箱
2.2 数据导入及处理
这一步需要把原始数据导入成一维列表,并且在每个名字后加上“!”作为结束符号(好让RNN知道什么时候停止)
import unicodedata
import string
from io import open
all_letters = string.ascii_letters+'!'
n_letters = len(all_letters)+1
name_path = 'names.txt'
names = open(name_path, encoding='utf-8').read().strip().split('\n')
names_with_endmark=[]
for name in names:
names_with_endmark.append(name + '!')
# print(names_with_endmark)生成的一维列表为:
['Abe!', 'Abukara!', 'Adachi!', 'Aida!'... 'Yuhara!', 'Yunokawa!']2.3 onehot编码
One-hot编码是一种将分类变量或离散特征转换为数值型数据的常用方法,在机器学习和深度学习领域中广泛应用。它通过创建一个“独热”向量来表示每个类别,该向量的长度等于所有可能类别的总数,且向量中只有一个位置(对应类别所在的位置)的值为1,其他所有位置的值均为0。
在本文实例中共使用53个字符:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!所以字母‘a’的onehot编码为[1, 0, 0, 0.....,0],‘b’的onehot编码为[0, 1, 0, 0.....,0],以此类推。
本文实例使用N vs N RNN结构,需要进行两种onehot编码:
def input_onehot(name):
onehot_tensor = torch.zeros(len(name),1,n_letters)
for i in range(len(name)):
onehot_tensor[i][0][all_letters.find(name[i])] = 1
return onehot_tensor
def target_onehot(name):
onehot = []
for i in range(1, len(name)):
onehot.append(all_letters.find(name[i]))
onehot.append(all_letters.find('!'))
onehot_tensor = torch.tensor(onehot)
return onehot_tensor用‘Abe’这个名字举例来说,input_onehot就是对应[Abe]的onehot向量(训练输入),而target_onehot就是对应[be!]的onehot向量(训练输出目标)。
还需要定义一个onehot解码的函数,用于把训练后的onehot向量转回字母:
def onehot_letter(onehot): #onehot编码转letter
_,letter_index = torch.topk(onehot,k=1)
return all_letters[letter_index]2.4 RNN构建
本文构建的RNN是基于RNN的改进版,改进前后的对比原理图如下:

首先我们看下用全连接层 nn.Linear() 构建正常RNN的方法:
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size) # 输入到隐藏层的权重和偏置
self.h2o = nn.Linear(hidden_size, output_size) # 隐藏层到输出层的权重和偏置
self.activation = nn.Tanh() # 非线性激活函数,这里使用tanh
def forward(self, input_step, hidden_state):
combined_input = torch.cat((input_step, hidden_state), dim=1)
hidden_state = self.activation(self.i2h(combined_input))
output = self.h2o(hidden_state)
return output, hidden_state本文的改进结构为:
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.h0 = torch.zeros(1, self.hidden_size)
# i2h input → hidden,hidden理解为语义
# i2o input → output
# o2o output→ output
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1) #抑制过拟合
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
input_combined = torch.cat(( input, hidden), 1)
hidden = self.i2h(input_combined)
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden我们可以把隐藏层输出理解为“语义”,本文的改进目的是让最终输出不仅考虑t-1时刻的隐藏层输出(语义),也把t时刻的隐藏层输出纳入考虑。
3. 模型训练
训练相关参数设定如下:
criterion = nn.NLLLoss() #Negative Log Likelihood Loss,即负对数似然损失。
opt = torch.optim.SGD(params=rnn.parameters(),lr = 5e-4) #随机梯度下降优化方法
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt, T_max=100, last_epoch= -1) #增加余弦退火自调整学习率
epoch = 1000训练过程如下:
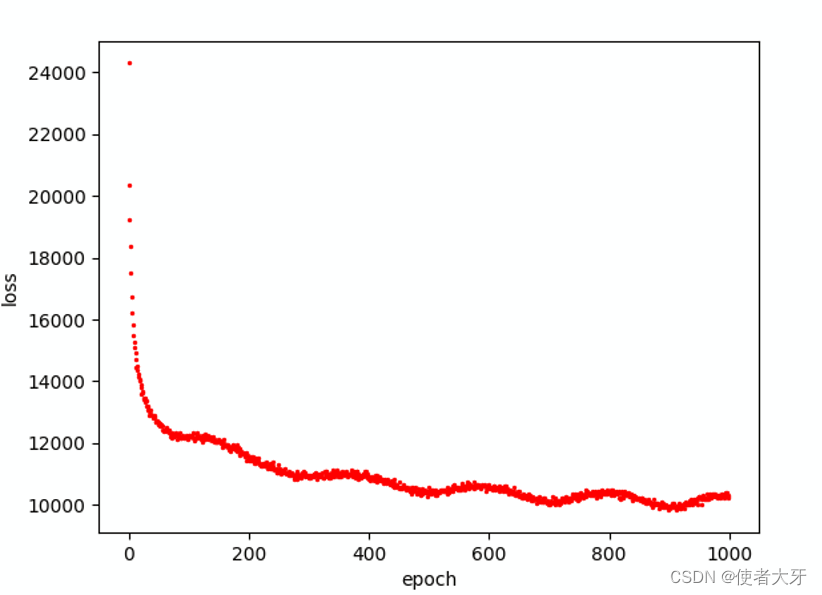
这里loss值很大是因为取的所有992个名字的loss总和。
4. 验证结果
以字母'A'开头,使用训练好的RNN输出的名字为'Aso',即あそ,麻生(或阿苏,两个姓氏同音)。
5. 完整代码
5.1 训练组
from io import open
import unicodedata
import string
import torch
import torch.nn as nn
from tqdm import tqdm
import matplotlib.pyplot as plt
all_letters = string.ascii_letters+'!'
n_letters = len(all_letters)+1
name_path = 'names.txt'
names = open(name_path, encoding='utf-8').read().strip().split('\n')
names_with_endmark=[]
for name in names:
names_with_endmark.append(name + '!')
# print(names_with_endmark)
Ascii_names = [] #把names格式转为Ascii
for name in names_with_endmark:
Ascii_names.append(''.join(letter for letter in unicodedata.normalize('NFD',name) if unicodedata.category(letter) != 'Mn' and letter in all_letters))
#上面这行代码解读:
# 1. unicodedata.normalize('NFD', name):对输入的字符串name进行NFD(Normalization Form D)标准化。NFD将每个字符分解为其基本形式和所有可分解的组合标记。
# 2. letter for letter in ...:这是一个生成器表达式,它会遍历经过NFD标准化后的字符串name中的每一个字符letter。
# 3. if unicodedata.category(letter) != 'Mn':检查每个字符c的Unicode类别是否不等于'Mn'。'Mn'代表"Mark, Non-Spacing",即非-spacing组合标记,这些标记不占据自己的空间位置,而是附加在其他字符上改变其样式或语意。
# 4. ''.join(...):将所有满足条件(非'Mn'类别)的字符连接成一个新的字符串。由于连接符是空字符串'',所以结果是一个没有分隔符的连续字符串。
# print(Ascii_names) #这里和上面pring(names_with_endmark)输出结果看不出差别,因为只是编码方式不同
def input_onehot(name):
onehot_tensor = torch.zeros(len(name),1,n_letters)
for i in range(len(name)):
onehot_tensor[i][0][all_letters.find(name[i])] = 1
return onehot_tensor
def target_onehot(name):
onehot = []
for i in range(1, len(name)):
onehot.append(all_letters.find(name[i]))
onehot.append(all_letters.find('!'))
onehot_tensor = torch.tensor(onehot)
return onehot_tensor
# print(input_onehot('Arai'))
# print(target_onehot('Arai'))
class RNN(nn.Module): #注意,这不是完全意义上的RNN
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.h0 = torch.zeros(1, self.hidden_size)
# i2h input → hidden,hidden理解为语义
# i2o input → output
# o2o output
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1) #抑制过拟合
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
input_combined = torch.cat(( input, hidden), 1)
hidden = self.i2h(input_combined)
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
if __name__ == '__main__':
rnn = RNN(n_letters, 128, n_letters)
criterion = nn.NLLLoss() #Negative Log Likelihood Loss,即负对数似然损失。
opt = torch.optim.SGD(params=rnn.parameters(),lr = 5e-4) #随机梯度下降优化方法
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt, T_max=100, last_epoch= -1) #增加余弦退火自调整学习率
epoch = 1000
def train(input_name_tensor, target_name_tensor):
target_name_tensor.unsqueeze_(-1)
hidden = rnn.h0 #对h0进行初始化
opt.zero_grad()
name_loss = 0
for i in range(input_name_tensor.size(0)):
output, hidden = rnn(input_name_tensor[i], hidden)
loss = criterion(output, target_name_tensor[i])
name_loss += loss
name_loss.backward() #对整个名字的loss进行backward
opt.step()
return name_loss
for e in tqdm(range(epoch)):
total_loss = 0
for name in Ascii_names:
total_loss = total_loss + train(input_onehot(name),target_onehot(name))
print(total_loss)
plt_loss = total_loss.detach()
plt.scatter(e, plt_loss, s=2, c='r')
scheduler.step()
torch.save(rnn.state_dict(), 'weight/epoch=1000--initial_lr=5e-4.pth') #保存训练好的权重
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()5.2 验证组
import torch
from rnn_main import RNN, input_onehot
import string
all_letters = string.ascii_letters+'!'
n_letters = len(all_letters)+1
rnn_predict = RNN(n_letters, 128, n_letters)
rnn_predict.load_state_dict(state_dict=torch.load('weight/epoch=1000--initial_lr=5e-4.pth'))
def onehot_letter(onehot): #onehot编码转letter
_,letter_index = torch.topk(onehot,k=1)
return all_letters[letter_index]
rnn_predict.eval()
current_letter_onehot = input_onehot('A').squeeze(0)
current_letter = onehot_letter(current_letter_onehot)
hpre = rnn_predict.h0
full_name = ''
while current_letter != '!': #判断是不是该结束了
full_name = full_name + current_letter
predict_onehot, hcur = rnn_predict(current_letter_onehot, hpre)
hpre = hcur
current_letter_onehot = predict_onehot
current_letter = onehot_letter(current_letter_onehot)
print(full_name)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前后端分离下的鸿鹄电子招投标系统:使用Spring Boot、Mybatis、Redis和Layui实现源码与立项流程
- AUTOSAR从入门到精通-车载以太网(二)
- CHS_03.2.1.4+进程控制
- Curl- go的自带包 net/http实现
- 【谭浩强C程序设计精讲 1】数据类型、常量与变量
- 润喉糖行业研究:未来的两年内可达100亿级市场
- LeetCode,第377场周赛,个人题解
- Netty实战(待完善)
- 喜报,思迈特荣获DCMM稳健级认证,数据管理能力达国家标准
- Linux:linux计算机和windows计算机 之间 共享资源