工具系列:PyCaret介绍_单变量时间序列代码示例
👋 工具系列:PyCaret介绍_单变量时间序列代码示例
PyCaret是一个开源的、低代码的Python机器学习库,可以自动化机器学习工作流程。它是一个端到端的机器学习和模型管理工具,可以大大加快实验周期,提高工作效率。
与其他开源机器学习库相比,PyCaret是一个替代低代码库,可以用几行代码代替数百行代码。这使得实验的速度和效率成倍增加。PyCaret本质上是围绕几个机器学习库和框架(如scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray等)的Python封装。
PyCaret的设计和简洁性受到了Gartner首次使用的公民数据科学家这一新兴角色的启发。公民数据科学家是能够执行简单和中等复杂的分析任务的高级用户,而以前这些任务需要更多的技术专长。
💻 安装
PyCaret在以下64位系统上进行了测试和支持:
- Python 3.7 - 3.10
- 仅适用于Ubuntu的Python 3.9
- Ubuntu 16.04或更高版本
- Windows 7或更高版本
您可以使用Python的pip软件包管理器安装PyCaret:
pip install pycaret
PyCaret的默认安装不会自动安装所有额外的依赖项。为此,您需要安装完整版本:
pip install pycaret[full]
或者根据您的用例,您可以安装以下其中一个变体:
pip install pycaret[analysis]pip install pycaret[models]pip install pycaret[tuner]pip install pycaret[mlops]pip install pycaret[parallel]pip install pycaret[test]
# 导入pycaret库
import pycaret
# 打印pycaret库的版本号
pycaret.__version__
'3.0.0'
🚀 快速开始
PyCaret时间序列预测模块现已可用。该模块目前适用于单变量/多变量时间序列预测任务。时间序列模块的API与PyCaret的其他模块保持一致。
它内置了预处理功能和超过30种算法,包括统计/时间序列方法和基于机器学习的模型。除了模型训练外,该模块还具有许多其他功能,如自动超参数调整、集成、模型分析、模型打包和部署能力。
在PyCaret中,典型的工作流程按照以下5个步骤进行:
设置 ?? 比较模型 ?? 分析模型 ?? 预测 ?? 保存模型
### 从pycaret数据集模块加载示例数据集
from pycaret.datasets import get_data
data = get_data('airline')
Period
1949-01 112.0
1949-02 118.0
1949-03 132.0
1949-04 129.0
1949-05 121.0
Freq: M, Name: Number of airline passengers, dtype: float64
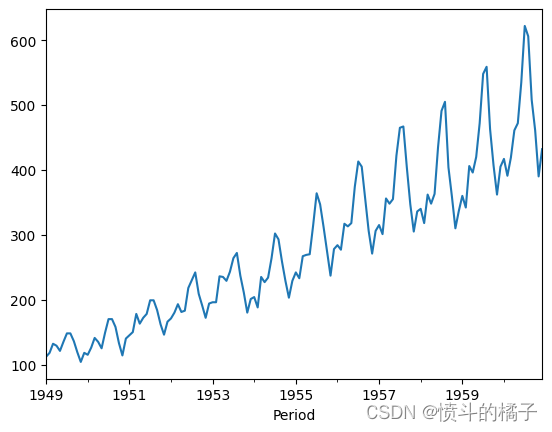
# 绘制数据集
data.plot()
<AxesSubplot:xlabel='Period'>
设置
此函数初始化训练环境并创建转换流水线。在执行PyCaret中的任何其他函数之前,必须调用设置函数。设置只有一个必需的参数,即数据。所有其他参数都是可选的。
# 导入 pycaret time series 模块
from pycaret.time_series import *
# 初始化设置
# data: 数据集
# fh: 预测的未来时间步数
# session_id: 用于复现实验结果的随机种子
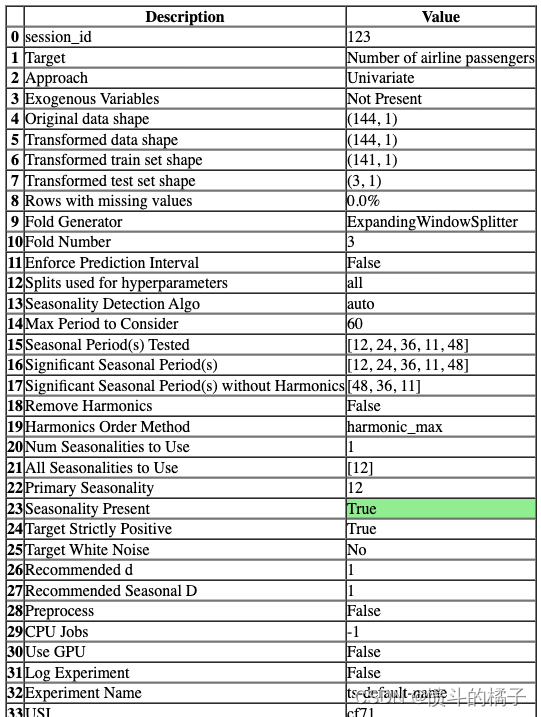
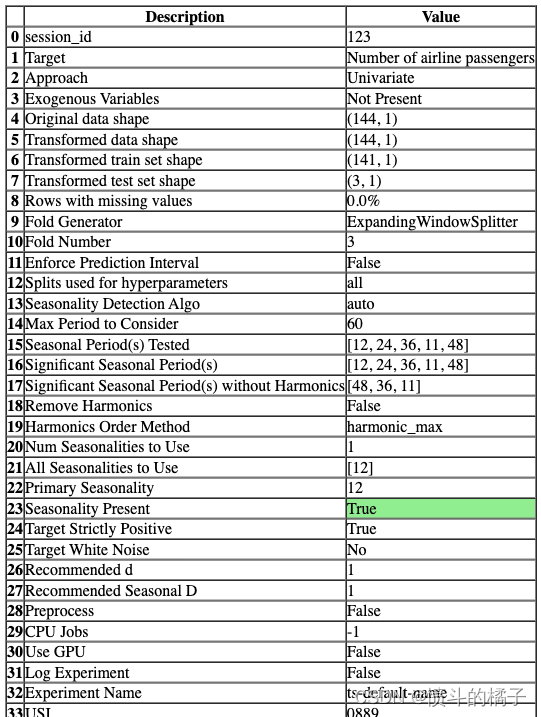
s = setup(data, fh=3, session_id=123)
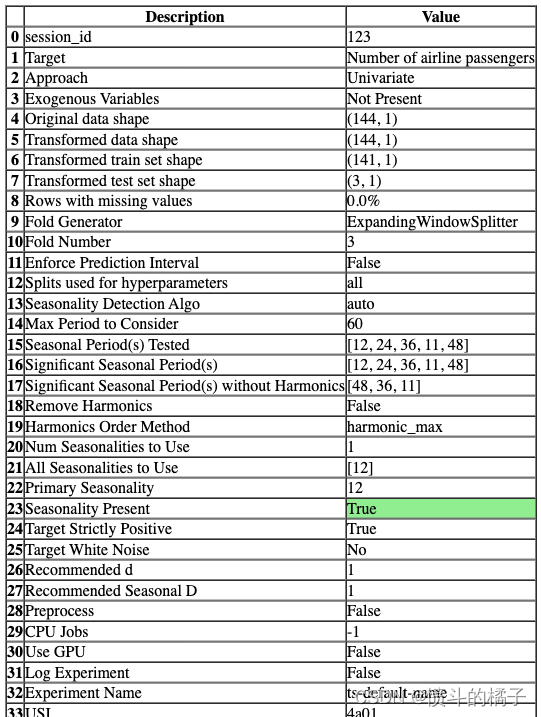
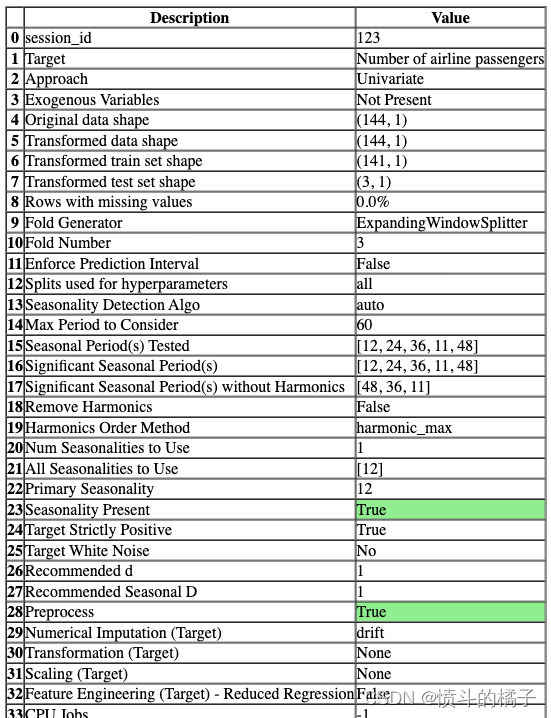
一旦设置成功执行,它会显示包含实验级别信息的信息网格。
- 会话ID: 一个伪随机数,作为种子在所有函数中分布,以便以后能够重现。如果没有传递
session_id,则会自动生成一个随机数,并分发给所有函数。
- 方法: 单变量或多变量。
- 外生变量: 用于模型的外生变量。
- 原始数据形状: 在任何转换之前的原始数据形状。
- 转换后的训练集形状: 转换后的训练集形状。
- 转换后的测试集形状: 转换后的测试集形状。
PyCaret的API
PyCaret有两套可以使用的API。 (1) 函数式API(如上所示)和 (2) 面向对象的API。
使用面向对象的API时,您不会直接执行函数,而是导入一个类并执行类的方法。
# 导入TSForecastingExperiment类并初始化该类
from pycaret.time_series import TSForecastingExperiment
exp = TSForecastingExperiment()
# 检查exp的类型
type(exp)
pycaret.time_series.forecasting.oop.TSForecastingExperiment
# 初始化设置实验
exp.setup(data, fh = 3, session_id = 123)
# 参数说明:
# data:数据集,用于实验的输入数据
# fh:预测的未来时间步数,用于时间序列预测模型
# session_id:实验的会话ID,用于记录实验的状态和结果
<pycaret.time_series.forecasting.oop.TSForecastingExperiment at 0x1d36ad79a90>
你可以使用任何两种方法,即函数式或面向对象编程,并且可以在两组API之间来回切换。选择方法不会影响结果,并且已经测试过其一致性。
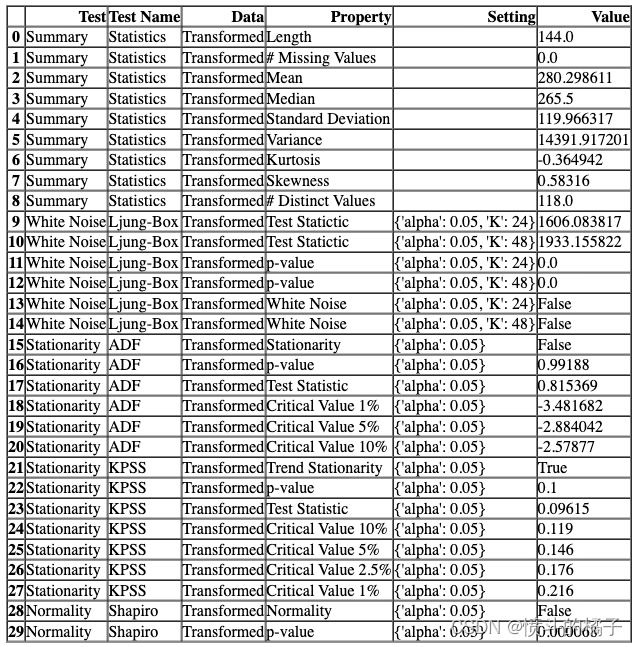
检查统计数据
check_stats 函数用于获取原始数据或模型残差的摘要统计信息并运行统计检验。
# 检查原始数据的统计测试
# 调用check_stats()函数来进行统计测试
check_stats()
比较模型
该函数使用交叉验证训练和评估模型库中所有可用的估计器的性能。该函数的输出是一个带有平均交叉验证分数的评分表格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
# 比较基准模型
# 使用compare_models()函数来比较不同的基准模型,该函数会自动选择最佳的模型
best = compare_models() # 将最佳模型赋值给变量best
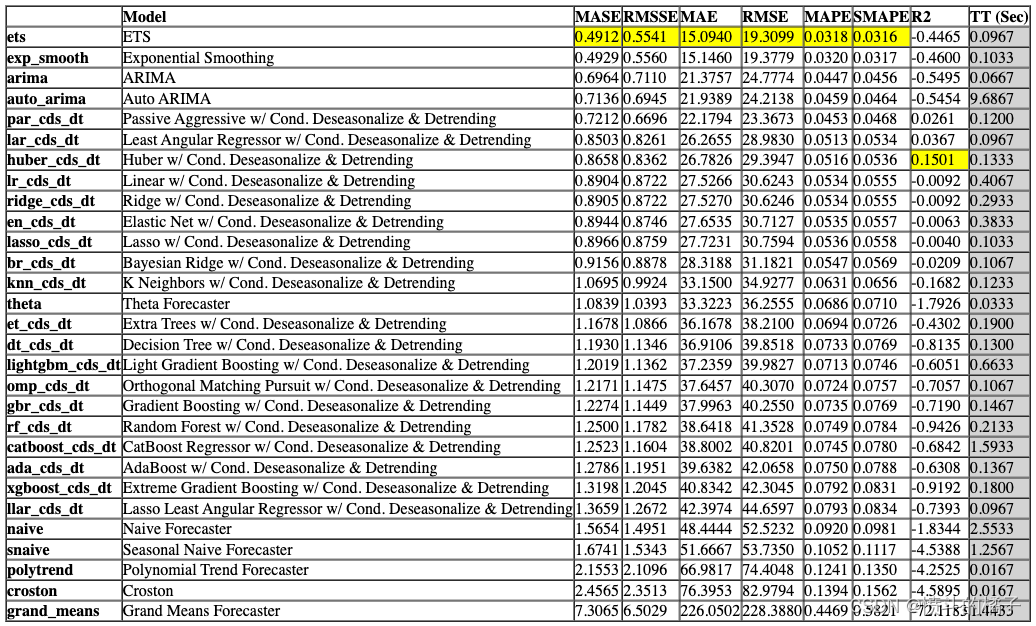
Processing: 0%| | 0/125 [00:00<?, ?it/s]
# 比较模型
exp.compare_models()
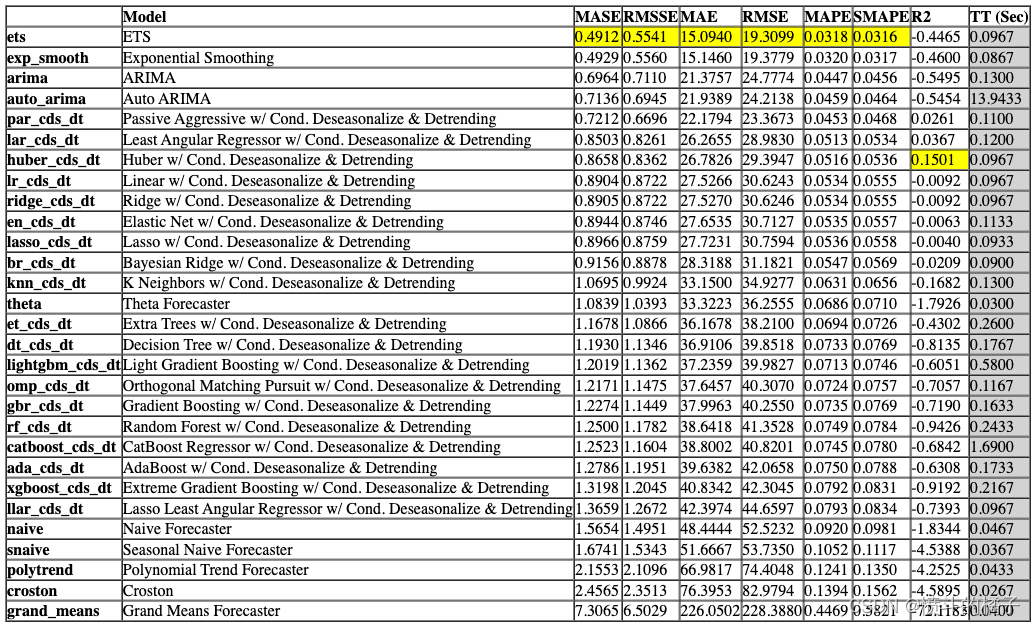
Processing: 0%| | 0/125 [00:00<?, ?it/s]

注意,函数式API和面向对象API之间的输出是一致的。本笔记本中的其余函数将只使用函数式API显示。
分析模型
您可以使用plot_model函数来分析已训练模型在测试集上的性能。在某些情况下,可能需要重新训练模型。
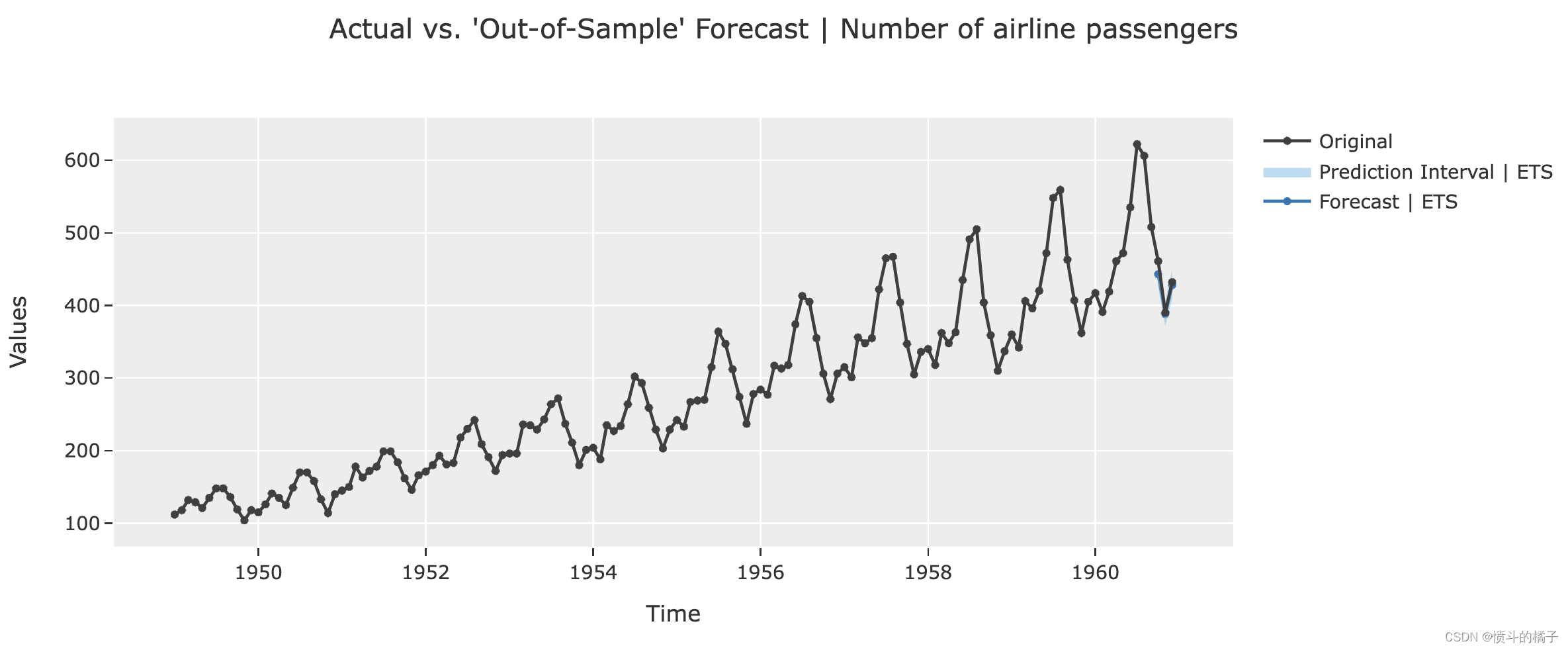
# 绘制预测图表
# best是一个模型对象,plot参数指定绘制的类型为'forecast'
# 'forecast'表示绘制预测结果的图表
plot_model(best, plot='forecast')
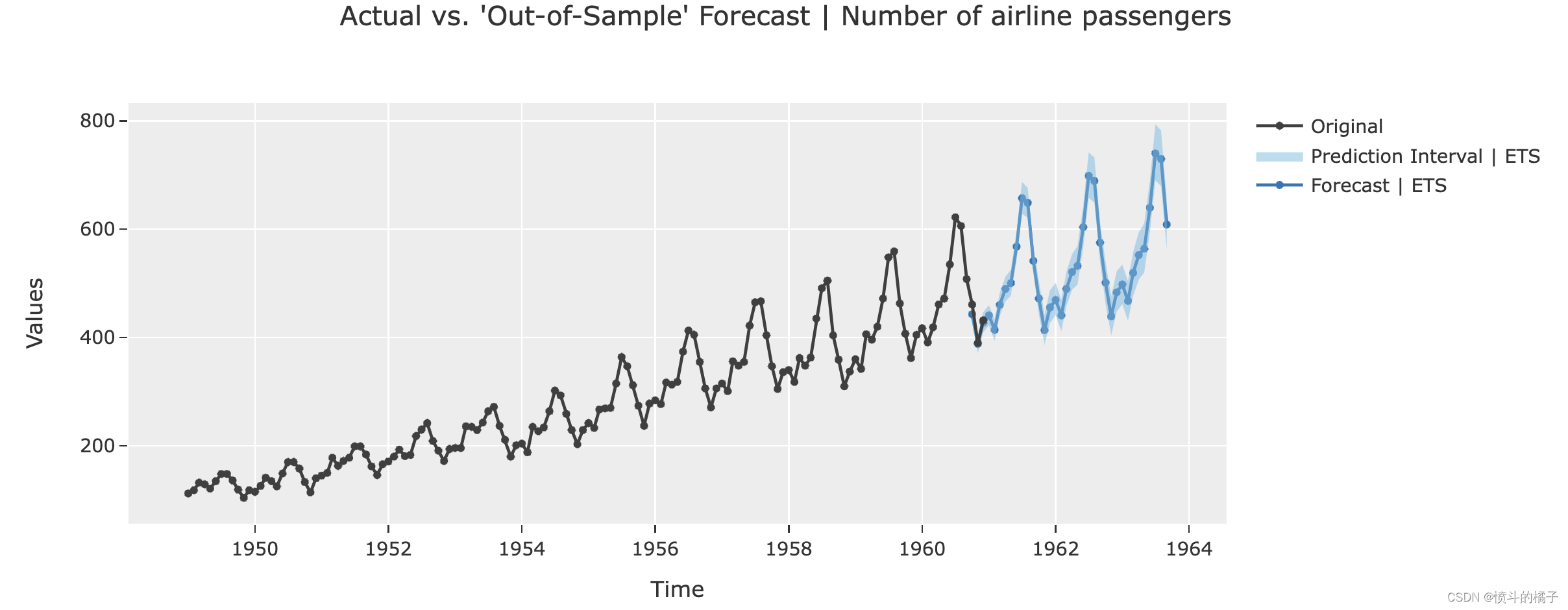
# 使用最佳模型进行预测
# 绘制未来36个月的预测图
# best是最佳模型的名称
# plot参数设置为'forecast',表示绘制预测图
# data_kwargs参数用于传递额外的数据参数,这里设置fh为36,表示预测未来36个月的数据
plot_model(best, plot='forecast', data_kwargs={'fh': 36})
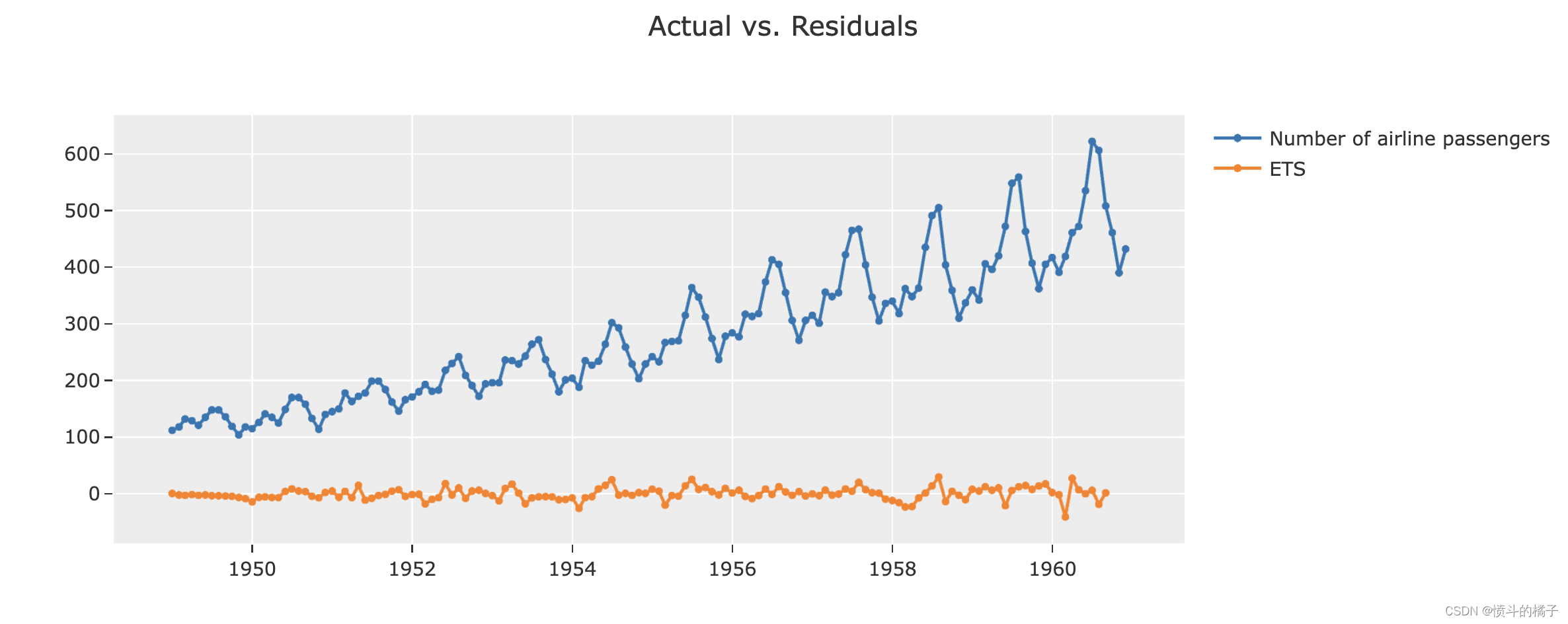
# 绘制残差图
# 使用plot_model函数绘制最佳模型的残差图
# 参数best表示最佳模型
# 参数plot='residuals'表示绘制残差图
plot_model(best, plot = 'residuals')
# help(plot_model)
evaluate_model函数是plot_model函数的替代品。它只能在Notebook中使用,因为它使用了ipywidget。
预测
predict_model 函数返回 y_pred。当数据为 None(默认值)时,它使用在 setup 函数期间定义的 fh。
# 对测试集进行预测
holdout_pred = predict_model(best)

# 展示预测结果的数据框
# 使用head()方法显示数据框holdout_pred的前几行数据,默认显示前5行
holdout_pred.head()

# 使用已经训练好的模型best,生成未来36个时间段的预测结果
# predict_model是一个函数,它接受两个参数:best和fh
# best是已经训练好的模型,它将被用于生成预测结果
# fh是一个整数,表示未来的时间段数,这里设置为36
predict_model(best, fh=36)

保存模型
最后,您可以使用pycaret的save_model函数将整个流水线保存到磁盘上以供以后使用。
# 保存模型
# 使用save_model函数将最佳模型保存为'my_first_pipeline'文件
Transformation Pipeline and Model Successfully Saved
(AutoETS(seasonal='mul', sp=12, trend='add'), 'my_first_pipeline.pkl')
# 加载已经训练好的模型
loaded_best_pipeline = load_model('my_first_pipeline')
# 执行加载好的模型,返回一个pipeline对象
loaded_best_pipeline
Transformation Pipeline and Model Successfully Loaded

👇 详细的逐个函数概述
? 设置
该函数初始化训练环境并创建转换流水线。在执行PyCaret中的任何其他函数之前,必须调用设置函数。设置只有一个必需的参数,即数据。所有其他参数都是可选的。
# 设置数据集和参数
# data: 数据集
# fh: 时间序列预测的步长(默认为1)
# session_id: 用于重现实验结果的随机种子(默认为None)
s = setup(data, fh=3, session_id=123)
为了访问由设置函数创建的所有变量,例如转换后的数据集、随机状态等,您可以使用get_config方法。
# 获取所有可用的配置信息
get_config()
{'USI',
'X',
'X_test',
'X_test_transformed',
'X_train',
'X_train_transformed',
'X_transformed',
'_available_plots',
'_ml_usecase',
'all_sps_to_use',
'approach_type',
'candidate_sps',
'data',
'dataset',
'dataset_transformed',
'enforce_exogenous',
'enforce_pi',
'exogenous_present',
'exp_id',
'exp_name_log',
'fh',
'fold_generator',
'fold_param',
'gpu_n_jobs_param',
'gpu_param',
'html_param',
'idx',
'index_type',
'is_multiclass',
'log_plots_param',
'logging_param',
'memory',
'model_engines',
'n_jobs_param',
'pipeline',
'primary_sp_to_use',
'seasonality_present',
'seed',
'significant_sps',
'significant_sps_no_harmonics',
'strictly_positive',
'test',
'test_transformed',
'train',
'train_transformed',
'variable_and_property_keys',
'variables',
'y',
'y_test',
'y_test_transformed',
'y_train',
'y_train_transformed',
'y_transformed'}
# 获取'y_train_transformed'的配置信息
get_config('y_train_transformed')
Period
1949-01 112.0
1949-02 118.0
1949-03 132.0
1949-04 129.0
1949-05 121.0
...
1960-05 472.0
1960-06 535.0
1960-07 622.0
1960-08 606.0
1960-09 508.0
Freq: M, Name: Number of airline passengers, Length: 141, dtype: float64
# 输出当前的种子值
print("当前的种子值为: {}".format(get_config('seed')))
# 使用set_config函数来改变种子值
set_config('seed', 786)
# 输出新的种子值
print("新的种子值为: {}".format(get_config('seed')))
The current seed is: 123
The new seed is: 786
所有的预处理配置和实验设置/参数都传递给setup函数。要查看所有可用的参数,请检查docstring:
# help(setup)
# 初始化设置
# 设置折叠策略为expanding,即逐步扩大折叠的训练集大小
# 设置fh参数为3,表示使用3个时间步长作为预测目标
# 设置session_id参数为123,用于生成随机种子
# 设置numeric_imputation_target参数为'drift',表示使用漂移方法进行数值插补
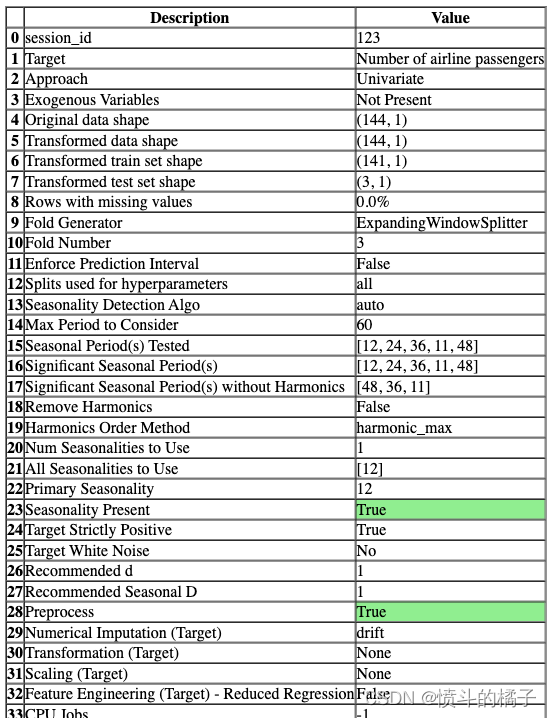
s = setup(data, fh=3, session_id=123, fold_strategy='expanding', numeric_imputation_target='drift')
? 比较模型
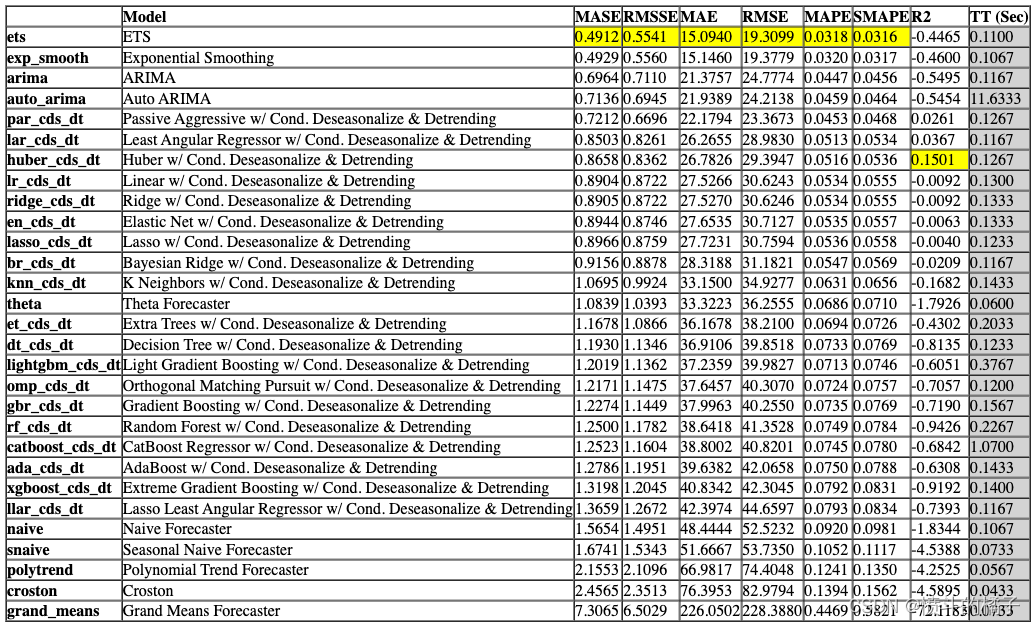
该函数使用交叉验证训练和评估模型库中所有可用的估计器的性能。该函数的输出是一个带有平均交叉验证分数的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
# 调用compare_models()函数,返回最佳模型
best = compare_models()
Processing: 0%| | 0/125 [00:00<?, ?it/s]
compare_models 默认使用模型库中的所有估计器(除了 Turbo=False 的模型)。要查看所有可用的模型,您可以使用函数 models()。
# 调用函数来检查可用的模型
models()
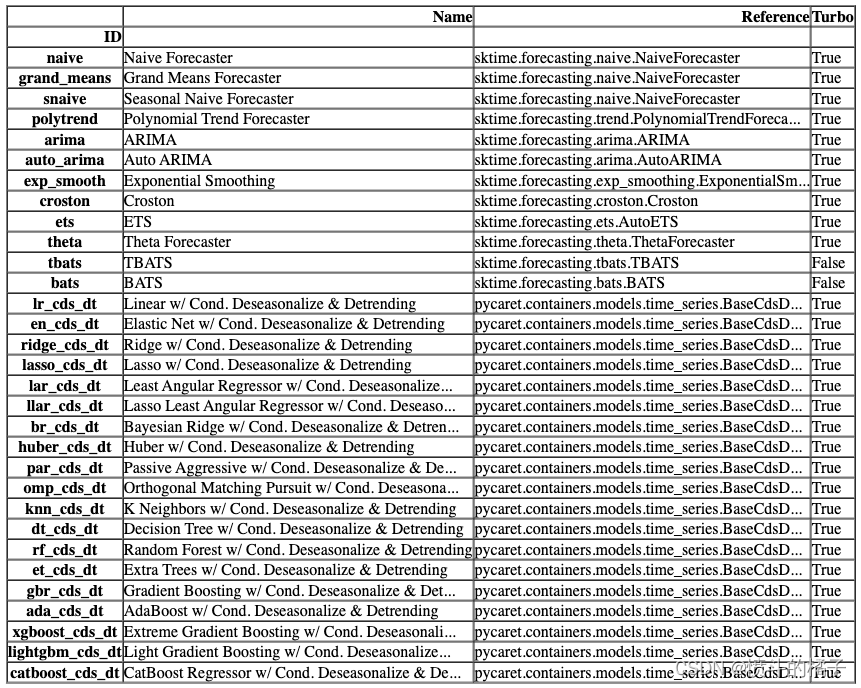
你可以在compare_models中使用include和exclude参数,只训练选择的模型或通过在exclude参数中传递模型id来排除特定模型的训练。
# 调用函数,比较不同时间序列模型的性能
compare_ts_models = compare_models(include=['ets', 'arima', 'theta', 'naive', 'snaive', 'grand_means', 'polytrend'])
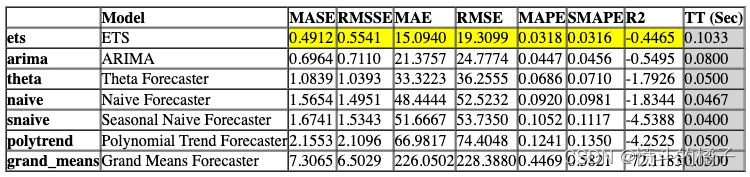
Processing: 0%| | 0/33 [00:00<?, ?it/s]
compare_ts_models

功能上面的函数返回训练好的模型对象作为输出。评分网格只显示,不返回。如果您需要访问评分网格,可以使用pull函数来访问数据框。
# 从数据库中获取时间序列模型的比较结果数据
compare_ts_models_results = pull()
compare_ts_models_results
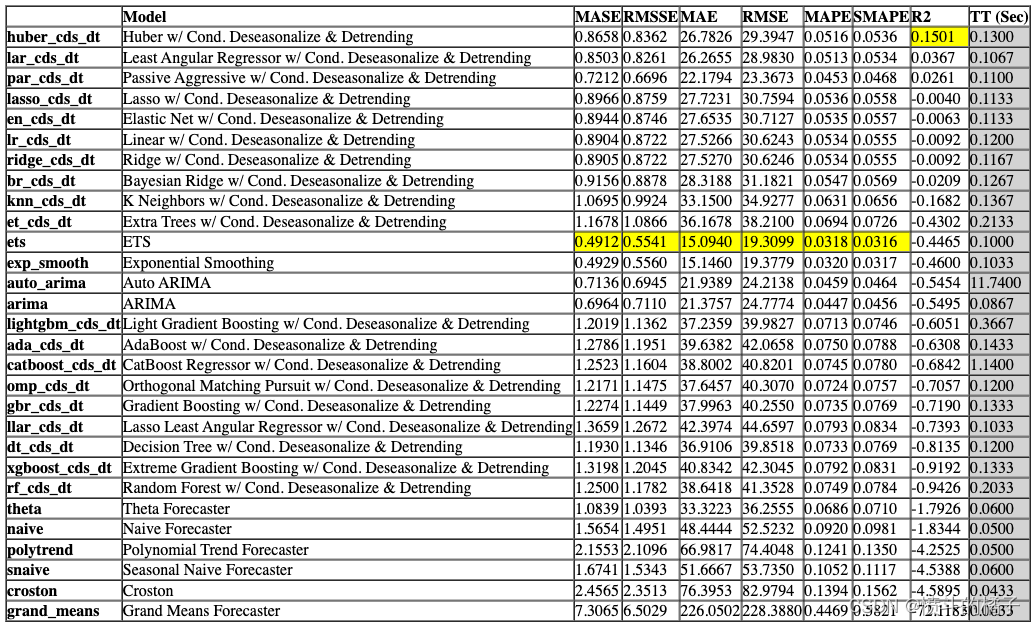
默认情况下,compare_models函数返回基于sort参数中定义的指标的最佳模型。让我们修改我们的代码,返回基于MAE的前3个最佳模型。
# 比较模型的性能并选择最佳的三个模型
# sort = 'R2' 表示按照R2指标进行排序
# n_select = 3 表示选择排名前三的模型
best_mae_models_top3 = compare_models(sort = 'R2', n_select = 3)
Processing: 0%| | 0/127 [00:00<?, ?it/s]
# 定义一个变量best_mae_models_top3,用于存储最佳的3个模型的列表
# 以下是代码实现部分,没有给出具体代码,只是给出了一个变量的定义
best_mae_models_top3
[BaseCdsDtForecaster(fe_target_rr=[WindowSummarizer(lag_feature={'lag': [12, 11,
10, 9,
8, 7, 6,
5, 4, 3,
2, 1]},
n_jobs=1)],
regressor=HuberRegressor(), sp=12, window_length=12),
BaseCdsDtForecaster(fe_target_rr=[WindowSummarizer(lag_feature={'lag': [12, 11,
10, 9,
8, 7, 6,
5, 4, 3,
2, 1]},
n_jobs=1)],
regressor=Lars(random_state=123), sp=12, window_length=12),
BaseCdsDtForecaster(fe_target_rr=[WindowSummarizer(lag_feature={'lag': [12, 11,
10, 9,
8, 7, 6,
5, 4, 3,
2, 1]},
n_jobs=1)],
regressor=PassiveAggressiveRegressor(random_state=123),
sp=12, window_length=12)]
一些在compare_models中可能非常有用的其他参数包括:
- fold
- cross_validation
- budget_time
- errors
- parallel
- engine
您可以查看函数的文档字符串以获取更多信息。
# help(compare_models)
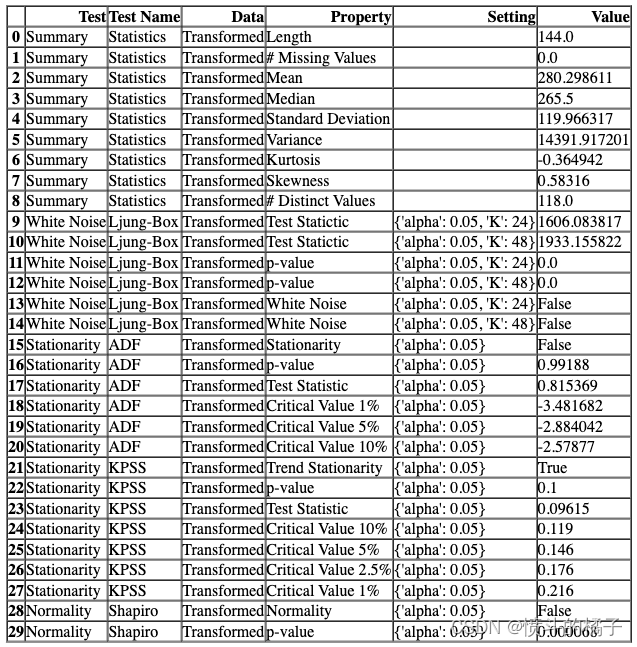
? 检查统计信息
check_stats 函数用于获取原始数据或模型残差的摘要统计信息并运行统计测试。
# 检查原始数据的统计信息
check_stats()
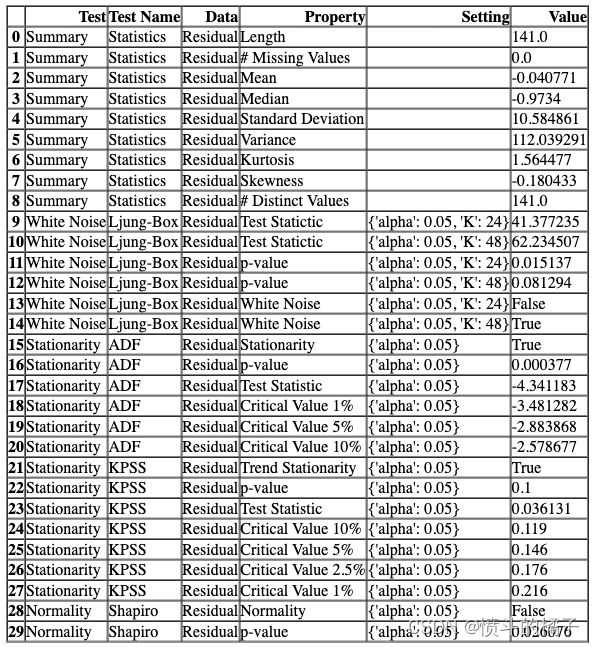
# 调用check_stats函数,对最佳模型的残差进行统计分析
check_stats(estimator = best)
? 实验日志记录
PyCaret与许多不同类型的实验记录器集成(默认为’mlflow’)。要在PyCaret中启用实验跟踪,您可以设置log_experiment和experiment_name参数。它将根据定义的记录器自动跟踪所有指标、超参数和工件。
# 导入pycaret.time_series模块
from pycaret.time_series import *
# 设置数据集、预测步长(fh)、会话ID(session_id)、实验日志(log_experiment)和实验名称(experiment_name)
s = setup(data, fh=3, session_id=123, log_experiment='mlflow', experiment_name='airline_experiment')
# 比较模型
# 使用compare_models()函数比较不同的模型,找出最佳模型。
# best = compare_models()
# !mlflow ui
默认情况下,PyCaret使用MLFlow记录器,可以使用log_experiment参数进行更改。以下记录器可用:
- mlflow
- wandb
- comet_ml
- dagshub
您可能会发现有用的其他与日志记录相关的参数有:
- experiment_custom_tags
- log_plots
- log_data
- log_profile
有关更多信息,请查看setup函数的文档字符串。
# help(setup)
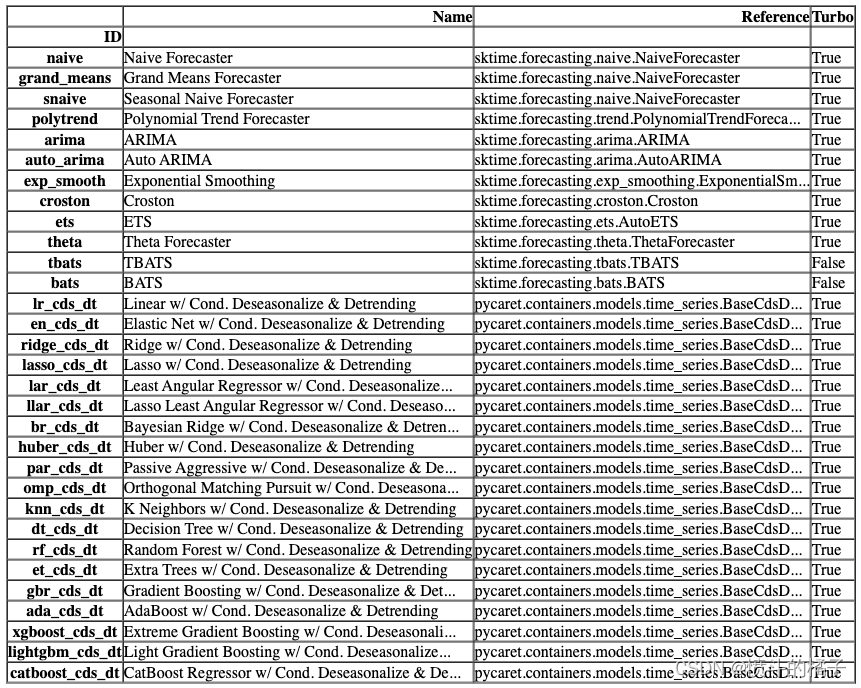
? 创建模型
该函数使用交叉验证训练和评估给定估计器的性能。该函数的输出是一个包含每个折叠的CV分数的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。可以使用models函数访问所有可用的模型。
# 调用函数,查看所有可用的模型
models()
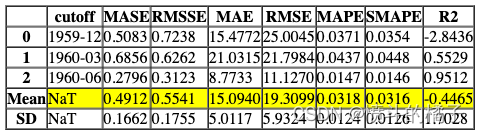
# 使用默认参数创建一个ETS模型
ets = create_model('ets')
Processing: 0%| | 0/4 [00:00<?, ?it/s]
功能以上返回训练好的模型对象作为输出。评分网格仅显示而不返回。如果您需要访问评分网格,可以使用pull函数访问数据框。
# 从pull()函数中获取ets_results变量的值
ets_results = pull()
# 打印ets_results的数据类型
print(type(ets_results))
# 打印ets_results的值
ets_results
<class 'pandas.core.frame.DataFrame'>
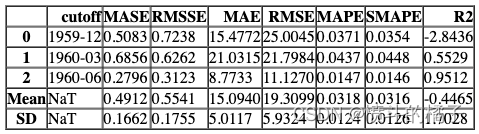
# 创建一个theta模型,并设置fold参数为5,用于训练模型
theta = create_model('theta', fold=5)
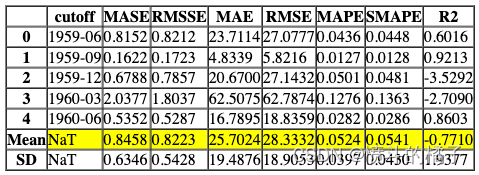
Processing: 0%| | 0/4 [00:00<?, ?it/s]
# 创建一个名为'theta'的模型,并使用特定的模型参数进行训练
# deseasonalize参数设置为False,表示不进行季节性调整
# fold参数设置为5,表示使用5折交叉验证进行训练
create_model('theta', deseasonalize = False, fold=5)
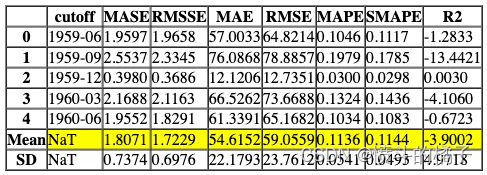
Processing: 0%| | 0/4 [00:00<?, ?it/s]

一些在create_model中可能非常有用的其他参数包括:
- cross_validation
- engine
- fit_kwargs
您可以查看函数的文档字符串以获取更多信息。
# help(create_model)
? 调整模型
调整模型函数用于调整模型的超参数。该函数的输出是一个通过交叉验证得到的得分网格。根据optimize参数中定义的指标选择最佳模型。可以使用get_metrics函数来访问交叉验证期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
# 使用默认参数创建一个决策树模型
dt = create_model('dt_cds_dt')
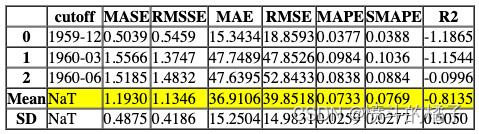
Processing: 0%| | 0/4 [00:00<?, ?it/s]
# 调整决策树模型的超参数
# 使用tune_model函数对决策树模型进行超参数调整,并将调整后的模型赋值给tuned_dt变量。
tuned_dt = tune_model(dt)
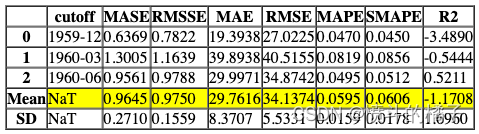
Processing: 0%| | 0/7 [00:00<?, ?it/s]
Fitting 3 folds for each of 10 candidates, totalling 30 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 3.2s finished
优化的度量标准可以在optimize参数中定义(默认为’MASE’)。此外,还可以使用custom_grid参数传递自定义调整的网格。
dt

# 定义调参网格
dt_grid = {'regressor__max_depth' : [None, 2, 4, 6, 8, 10, 12]}
# 使用自定义网格和评估指标为MAE来调整模型
tuned_dt = tune_model(dt, custom_grid = dt_grid, optimize = 'MAE')
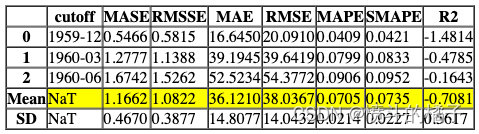
Processing: 0%| | 0/7 [00:00<?, ?it/s]
Fitting 3 folds for each of 7 candidates, totalling 21 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 21 out of 21 | elapsed: 2.9s finished
tuned_dt

# 使用tune_model函数对决策树模型进行调参
# 返回调参后的决策树模型和调参器对象
tuned_dt, tuner = tune_model(dt, return_tuner=True)
# 注意:为了访问调参器对象,需要将return_tuner参数设置为True
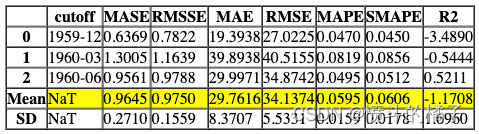
Processing: 0%| | 0/7 [00:00<?, ?it/s]
Fitting 3 folds for each of 10 candidates, totalling 30 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 3.8s finished
tuned_dt

# 创建一个调参器对象
tuner
<pycaret.utils.time_series.forecasting.model_selection.ForecastingRandomizedSearchCV at 0x1d36d1965b0>
有关所有可用的search_library和search_algorithm的更多详细信息,请查看docstring。在tune_model中,您可能会发现以下一些非常有用的其他参数:
- choose_better
- custom_scorer
- n_iter
- search_algorithm
- optimize
您可以查看函数的docstring以获取更多信息。
# help(tune_model)
? 混合模型
该函数用于训练EnsembleForecaster,其中选择的模型通过estimator_list参数传递。该函数的输出是一个包含每个折叠的CV得分的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
# top 3 models based on mae
# 基于平均绝对误差(mae)的前3个模型
best_mae_models_top3
[BaseCdsDtForecaster(fe_target_rr=[WindowSummarizer(lag_feature={'lag': [12, 11,
10, 9,
8, 7, 6,
5, 4, 3,
2, 1]},
n_jobs=1)],
regressor=HuberRegressor(), sp=12, window_length=12),
BaseCdsDtForecaster(fe_target_rr=[WindowSummarizer(lag_feature={'lag': [12, 11,
10, 9,
8, 7, 6,
5, 4, 3,
2, 1]},
n_jobs=1)],
regressor=Lars(random_state=123), sp=12, window_length=12),
BaseCdsDtForecaster(fe_target_rr=[WindowSummarizer(lag_feature={'lag': [12, 11,
10, 9,
8, 7, 6,
5, 4, 3,
2, 1]},
n_jobs=1)],
regressor=PassiveAggressiveRegressor(random_state=123),
sp=12, window_length=12)]
# blend_models函数用于将最佳的三个模型进行融合
# 参数best_mae_models_top3是一个包含最佳三个模型的列表
# blend_models函数的作用是将这三个模型进行融合,得到一个更加准确的模型
# 融合模型的方法可以是平均预测值、加权平均预测值等
# 融合后的模型可以用于对新的数据进行预测,得到更准确的结果
blend_models(best_mae_models_top3)
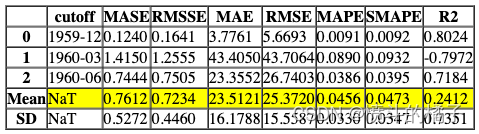
Processing: 0%| | 0/6 [00:00<?, ?it/s]

一些在blend_models中可能非常有用的其他参数包括:
- choose_better
- method
- weights
- fit_kwargs
- optimize
您可以查看函数的文档字符串以获取更多信息。
# help(blend_models)
? 绘制模型
功能说明
该函数用于分析在保留集上训练模型的性能。在某些情况下,可能需要重新训练模型。
# 绘制预测图表
# best是一个模型对象,plot参数用于指定绘制的类型为forecast(预测)
plot_model(best, plot='forecast')
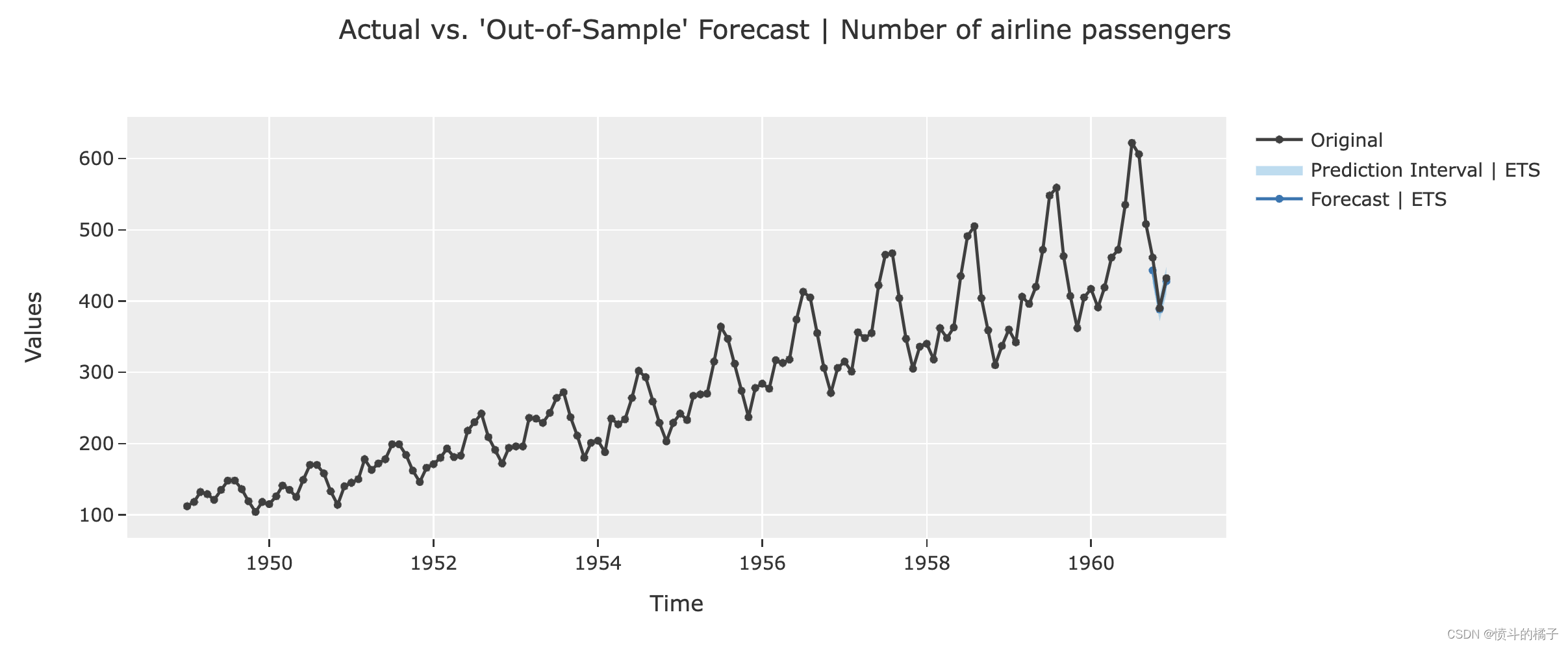
# 绘制自相关函数图
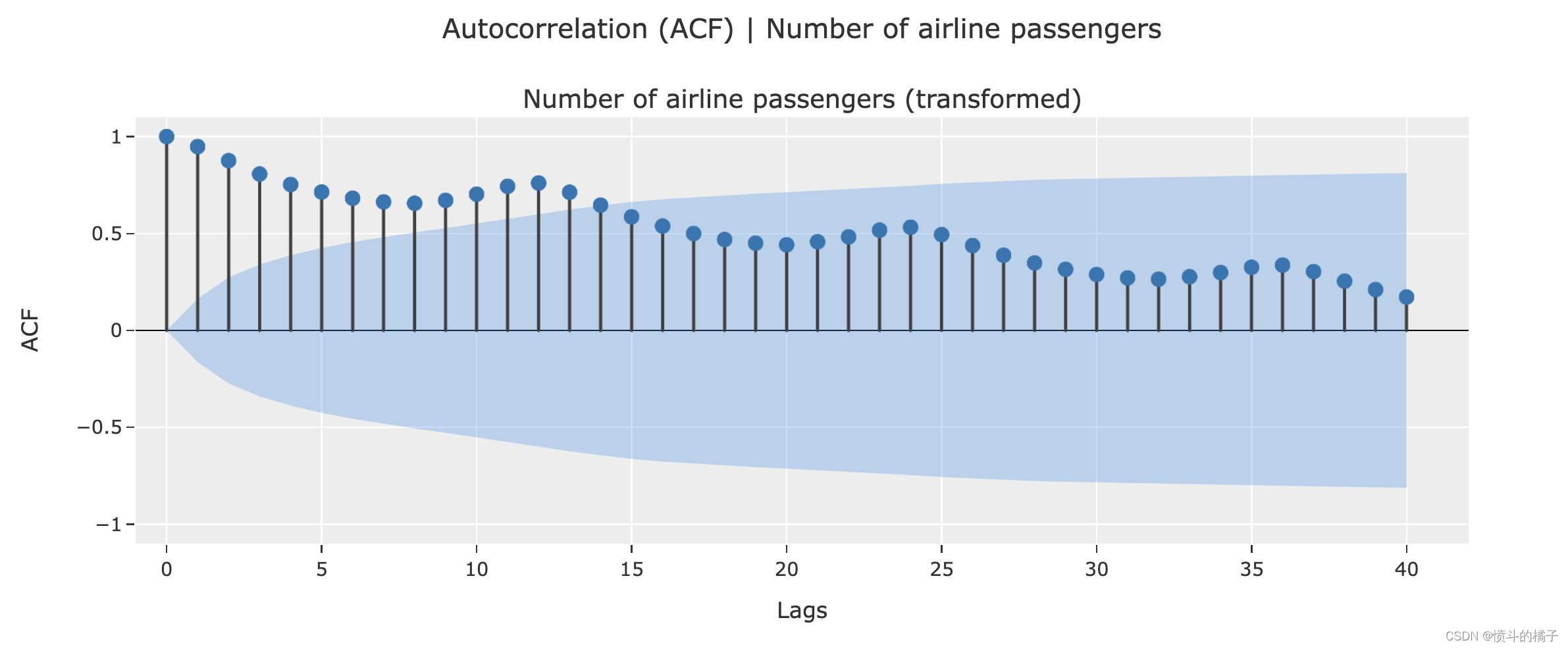
plot_model(plot = 'acf')
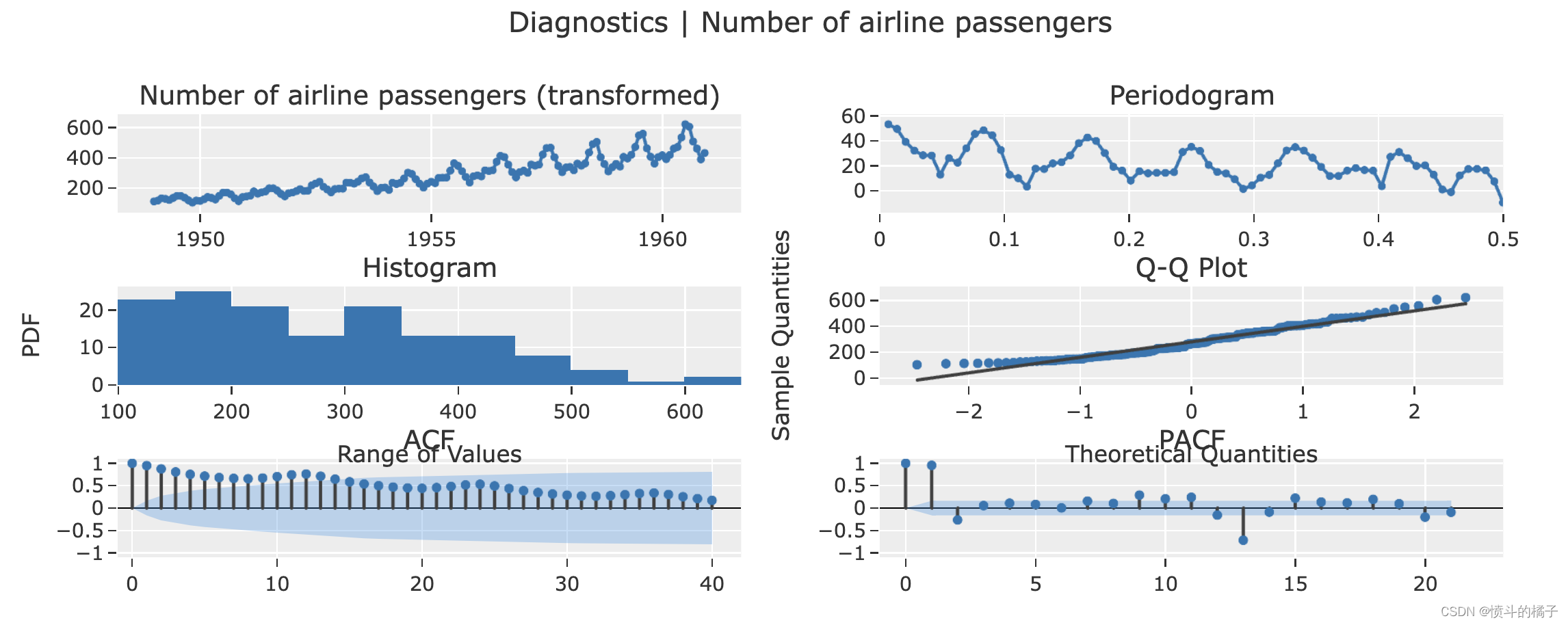
# 绘制诊断图
# 对于某些图形,您不需要训练好的模型
# 绘制模型的诊断图
plot_model(plot = 'diagnostics')
一些在plot_model中可能非常有用的其他参数有:
- fig_kwargs
- data_kwargs
- display_format
- return_fig
- return_data
- save
您可以查看函数的文档字符串以获取更多信息。
# help(plot_model)
? 完善模型
该函数在整个数据集上训练给定的模型,包括保留集。
# 将模型进行最终的优化
final_best = finalize_model(best)
# 定义一个变量final_best,用于存储最终的最佳结果
final_best

? 部署模型
此函数在云上部署整个机器学习流程。
AWS: 在AWS S3上部署模型时,必须使用命令行界面配置环境变量。要配置AWS环境变量,请在终端中输入aws configure命令。以下信息是必需的,可以使用您的Amazon控制台帐户的身份和访问管理(IAM)门户生成:
- AWS访问密钥ID
- AWS秘密密钥访问
- 默认区域名称(可以在AWS控制台的全局设置下看到)
- 默认输出格式(必须留空)
GCP: 要在Google Cloud Platform(‘gcp’)上部署模型,必须使用命令行或GCP控制台创建项目。创建项目后,必须创建服务帐户并将服务帐户密钥下载为JSON文件,以在本地环境中设置环境变量。了解更多信息:https://cloud.google.com/docs/authentication/production
Azure: 要在Microsoft Azure(‘azure’)上部署模型,必须在本地环境中设置用于连接字符串的环境变量。转到Azure门户上的存储帐户设置以访问所需的连接字符串。
AZURE_STORAGE_CONNECTION_STRING(作为环境变量必需)
了解更多信息:https://docs.microsoft.com/en-us/azure/storage/blobs/storage-quickstart-blobs-python?toc=%2Fpython%2Fazure%2FTOC.json
# 部署模型到AWS S3
# 部署最佳模型到AWS S3
deploy_model(best, model_name='my_first_platform_on_aws', platform='aws', authentication={'bucket': 'pycaret-test'})
# 从AWS S3加载模型
# 从AWS S3加载模型,模型名称为'my_first_platform_on_aws',平台为'aws'
# 使用认证信息{'bucket' : 'pycaret-test'}进行身份验证
# loaded_from_aws = load_model(model_name = 'my_first_platform_on_aws', platform = 'aws',
# authentication = {'bucket' : 'pycaret-test'})
# loaded_from_aws
? 保存/加载模型
这个函数将转换流水线和训练好的模型对象保存为pickle文件,以便以后使用,保存在当前工作目录中。
# 保存模型
# 使用save_model函数将最佳模型保存为'my_first_model'文件
save_model(best, 'my_first_model')
Transformation Pipeline and Model Successfully Saved
(AutoETS(seasonal='mul', sp=12, trend='add'), 'my_first_model.pkl')
# 加载模型
loaded_from_disk = load_model('my_first_model') # 从磁盘上加载名为'my_first_model'的模型文件,并将其存储在变量loaded_from_disk中
loaded_from_disk # 打印加载的模型
Transformation Pipeline and Model Successfully Loaded

? 保存/加载实验
该函数将实验中的所有变量保存到磁盘上,以便以后恢复而无需重新运行设置函数。
# 保存实验
save_experiment('my_experiment')
# 从磁盘加载实验
# 使用load_experiment函数从磁盘加载名为'my_experiment'的实验
# 参数data表示实验所需的数据
exp_from_disk = load_experiment('my_experiment', data=data)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!