机器学习的一些有趣的点【异常检测】
- 机器能不能知道自己不知道,而不是给出判断中的一种?
- Classifier(分类)
- Anomaly Detection(异常检测)
- 机器能不能说出为什么知道?
- 有时候可能是因为数据的问题导致了这种错觉。
- 机器学习是否会有错觉?
- Adversarial Attack
- “对抗攻击”。这是指针对机器学习模型或人工智能系统的一种攻击方法,攻击者通过精心设计的输入,试图欺骗模型,使其产生错误的输出或分类。这种攻击是通过对输入数据进行微小的、人眼难以察觉的改动,来误导模型而使其做出错误判断。对抗攻击对于深度学习和其他机器学习模型的鲁棒性提出了挑战,研究人员致力于开发对抗性训练和其他技术来提高模型的抗对抗性。
- 机器也能“终身学习“吗
- Catastrophic Forgetting
- “灾难性遗忘”。这是指在机器学习和神经网络领域中的一种现象,当一个模型在学习新任务时,可能会忘记先前学过的任务,导致性能急剧下降。这种遗忘发生在模型在面对新数据时调整权重以适应新任务,但这可能会导致已有的知识丧失,从而影响之前学到的任务的表现。灾难性遗忘是在增量学习和迁移学习等场景中需要处理的一个重要问题。
- 学习如何学习(learn to learn)
- 自我进化?
- 需要很多训练资料吗?
- Few-shot learning
- Zero-shot learning
- Reinforcement Learning(增强式学习)
- 这是一种机器学习范式,其中智能体通过与环境的交互学习如何做出决策,以最大化某种累积奖励。在增强式学习中,智能体通过试错的方式学习,根据其行动的结果调整其策略,以达到更好的性能。
- Network Compression(神经网络压缩)
-这是一种用于减小神经网络模型大小的技术。在深度学习中,神经网络通常包含大量参数和层,这可能导致模型庞大、计算资源需求高,以及不适用于嵌入式设备或移动应用。神经网络压缩旨在通过减少参数数量、层的数量或其他手段,来减小模型的体积,同时尽可能保持其性能。这有助于在有限的资源下部署更轻量级的模型。
Anomaly Detection(异常检测)
Binary Classification二分类问题?
不是一个简简单单的二分类问题。
当训练数据时带有标签的时候
异常检测的训练资料的类型。
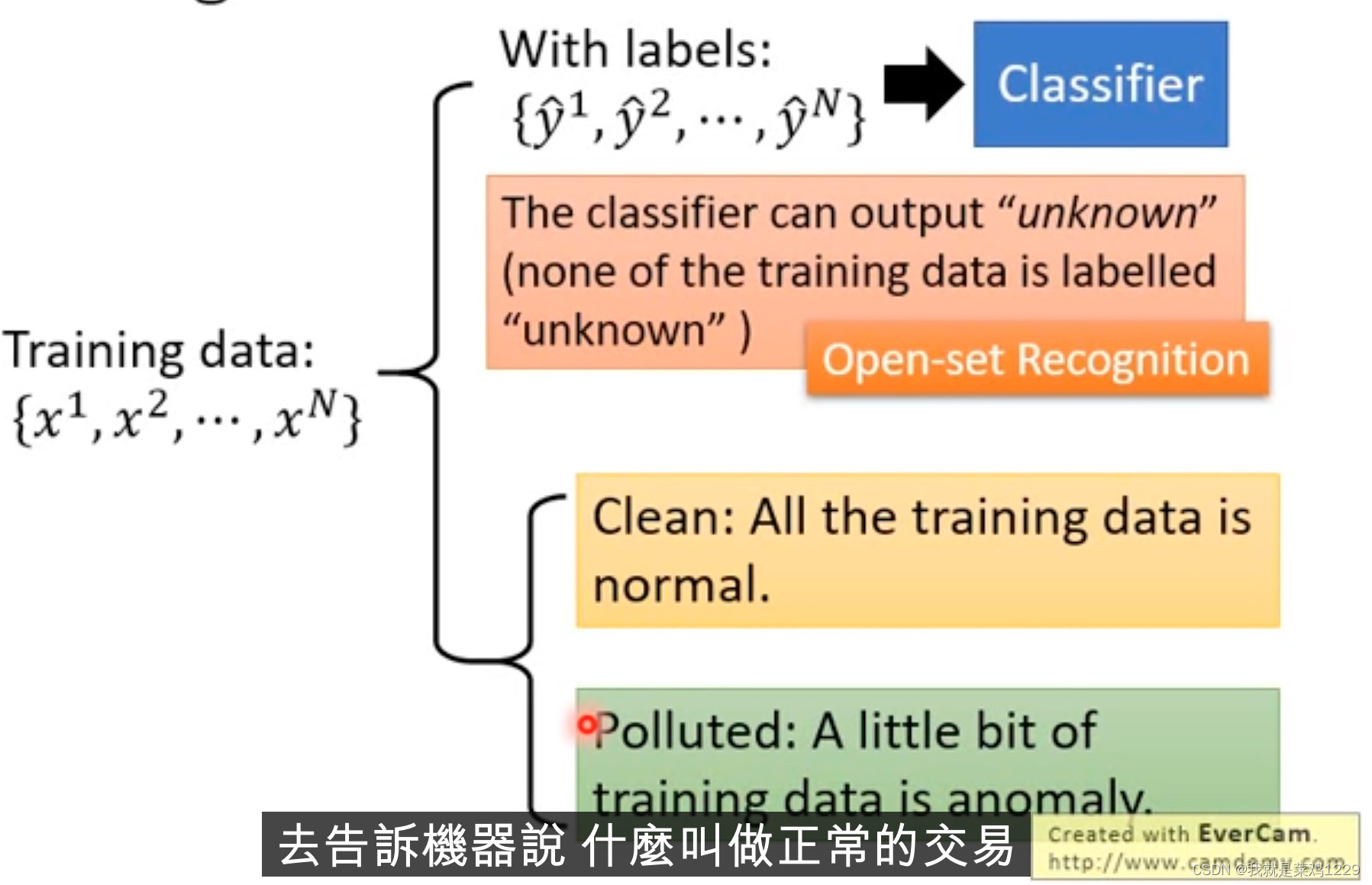
我们可以先根据标签训练一个分类器,之后根据训练器的得分来解决异常检测这一问题。
方法1:可以获得一个信息分数来了解,机器对于自己判断的confidence。
需要设置一个Threshold来判断。
如何计算一个异常检测系统的性能好坏:我们需要一个CostTable来对应混淆矩阵中的假阳和假阴,从而计算出惩罚。
一个常用的是AUC。
如何解决异常资料的缺失
让机器在看到异常资料的时候给出低的confidence,当没有异常资料时我们通过Generative Models来生成。
如果资料没有标签如何处理
需要将一类正常的数据进行训练。训练一个数据和训练集中数据的相似性。
Auto-encoder
Autoencoder(自编码器)是一种神经网络结构,用于学习有效表示输入数据的方法。它通常由两个主要部分组成:编码器(encoder)和解码器(decoder)。其目标是通过编码和解码过程来重构输入数据,同时学习到数据的紧凑、低维表示。
具体来说,Autoencoder 的工作过程如下:
- 编码器(Encoder):将输入数据映射到一个潜在表示(latent
representation)或编码。这一步将输入数据压缩到一个较低维度的表示形式。 - 解码器(Decoder):将编码后的表示还原为输入数据。解码器的目标是尽可能准确地重构原始输入。
- 损失函数(Loss Function):Autoencoder的训练过程通过最小化输入与重构之间的差异来完成,通常使用重构误差(reconstruction error)或其他适当的损失函数。
Autoencoder的一个关键特点是,编码器和解码器的结构是对称的,这使得模型能够学习到输入数据中的有用特征,同时实现压缩和解压缩的功能。
应用Autoencoder的一种常见情景是无监督学习中的特征学习。通过训练Autoencoder,模型可以学到输入数据的紧凑表示,这有助于发现数据中的模式和结构。此外,Autoencoder还可以用于数据降维、去噪、生成等任务。
其他机器学习中异常检测方法
SVM中存在One-class SVM
概念: One-class SVM是支持向量机的一种变体,主要用于异常检测问题。它的训练过程是基于仅有正样本(正常样本)的数据,通过构建一个超平面,将正常样本从原点分离出来。在测试阶段,模型可以用于检测新样本是否与训练数据属于同一类别(正常样本)。
应用: 适用于只有一类样本的情况,例如在异常检测中,其中正常样本远远多于异常样本。
森林系列的代码中存在Isolated Forest
概念: 孤立森林是一种基于树的集成方法,用于异常检测。它通过递归地构建二叉树来“孤立”正常样本,即使在树中的深层,正常样本也更容易被孤立。异常样本在这个过程中通常需要较少的分割。
应用: 适用于异常检测问题,尤其是在高维数据中,因为它在构建树时主要关注的是数据的分离。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- QT上位机开发(日志调试)
- 13.Kubernetes应用部署完整流程:从Dockerfile到Ingress发布完整流程
- [Python进阶] Python操作Excel文件:pandas
- ArkTS - @Prop、@Link
- Prometheus 登录用户认证
- 网上训练补题
- AI大模型引领未来智慧科研暨ChatGPT在地学、GIS、气象、农业、生态、环境等领域中的高级应用
- Java - Lombok的添加和使用详解
- Elasticsearch地理位置数据索引
- Nodejs 第三十章(防盗链)