unity中使用protobuf工具将proto文件转为C#实体脚本
unity中使用protobuf工具将proto文件转为C#实体脚本
介绍
protobuf也就是Google Protocol Buffers是一种轻便、高校的结构化数据存储格式,可以用于结构化数据串行化,很适合做数据存储或RPC数据交换格式。
它可用于通信协议、数据存储等领域的语言无关、平台无关扩展的序列化结构数据格式。
优点
- 更小、更快—protobuf类似XML,不过它更小、更快。用户可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构,甚至可以在无需重新部署程序的情况下更新数据结构。
- 跨平台、跨语言—只需要使用protobuf对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对结构化数据进行轻松读/写。
- 向后兼容性好—它有一个非常棒的特性,即“向后”兼容性好,不必破坏已部署的、依靠“老”数据格式的程序就可以对数据结构进行升级。这样就可以不必担心因为消息结构的改变而造成大规模的代码重构或者迁移。
- 语义更清晰——Protobuf的语义更清晰,无须类似XML解析器的内容(因为Protobuf编译器会将.proto文件编译成对应的数据访问类,以对Protobuf数据进行序列化、反序列化操作)。
- 简单易学——使用Protobuf无须学习复杂的文档对象模型。 Protobuf的编程模式比较友好、简单易学,同时它拥有良好的文档和示例。对于喜欢简单事物的人而言, Protobuf比其他技术更有吸引力。
缺点
- 无法表示复杂概念——Protobuf与XML相比也有不足之处。它功能简单,却无法用来表示复杂的概念。
- 通用性不足——XML已经成为多种行业标准的编写工具,而Protobuf只是Google公司内部使用的工具,在通用性上相差很多由于文本并不适合用来描述数据结构,所以Protobuf也不适合用来对基于文本的标记文档(如HTML)建模。
- 无法自解释,可读性差——另外,由于XML具有某种程度上的自解释性,它可以被直接读取编辑。而Protobuf以二进制的方式存储,除非有proto定义,否则无法直接读出Protobuf的任何内容。
- Protobuf3 之前只支持Java/Python/C++,Protobuf3 以后开始支持 Go/Ruby/PHP 等。
Protobuf 为什么比 XML 快得多?
跟XML相比,Protobuf的主要优点在于性能高。它以高校的二进制方式存储,比XML小3-10倍,快20-100倍。
有两项技术保证了采用Protobuf的程序能获得相对于XML极大的性能提高。
首先,可以考察Protobuf序列化后的信息内容。可以看到Protobuf信息的表示非常紧凑,这意味着消息的体积减小,自然需要更少的资源,如网络上传输的字节数更少、需要的IO更少等,从而提高性能。
其次,需要理解Protobuf封解包的大致过程,从而理解它为什么会比XML快很多。
Protobuf的Encoding
Protobuf序列化后生成的二进制消息非常紧凑,这得益于Protobuf采用了非常巧妙的Encoding方法。在考察消息结构之前,首先介绍一个名为Variant的术语。
Variant是一种紧凑的表示数字的方法、它用一个或者多个字节来表示一个数字,值越小的数字使用越少的字节,这样就能减少用来表示数组的字节数。
消息进过序列化后会成为一个二进制数据流,该流中的数据喂一系列的Key/Value键值对。
采用这种Key/Value结构无需使用分隔符来分割不同的Field。对于可选的Field,如果消息中不存在该Field,那么在最终的MessageBuffer中就没有该Field。
这些特性都有助于减少消息本身的大小。
Protobuf封解包的过程
首先来了解一下XML的封解包过程。
XML需要先从文件中读取字符串,在转换为XML文档对象结构模型,然后再从XML文档对象结构模型中读取指定节点的字符串,最后将这个字符串转换成指定类型的变量。
这个过程非常复杂,其中将XML文件转换为文档对象结构的过程通常需要完成词法、文法分析等大量消耗CPU的复杂计算。
反观Protobuf,只需要简单的将一个二进制序列按照指定的格式读取到C++对应的结构类型中即可,速度非常快。
通常编写一个Google Protocol Buffer应用需要以下几步:
- 定义消息格式文件,文件通常以.proto作为后缀名结尾;
- 使用Google提供的Protocol Buffer环境进行文件编译,编译成指定的(Jave、Python、C++等)文件;
- 使用Protocol Buffer提供的应用接口(API)类库来完成业务程序开发。
Protostuff是什么
相对于json来说,Protocol Buffer门槛更高,因为需要编写.proto文件,再把它编译成目标语言,这样使用起来就很麻烦。
但是现在有了protostuff之后,就不需要依赖.proto文件了,他可以直接对POJO进行序列化和反序列化,使用起来非常简单。
Protobuf工具
这里我是用的是proto2,将.proto的文件打成C#文件
下图是完整的工具,里面还包含了一些其他工具可自己研究,这里我是用的是ProtoGen这个工具
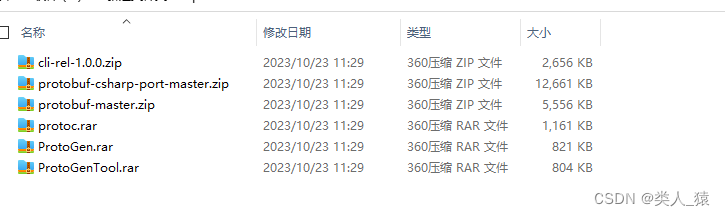
这个可以在我资源库中搜索protobuf查找文件
打开ProtoGen文件夹如下图所示
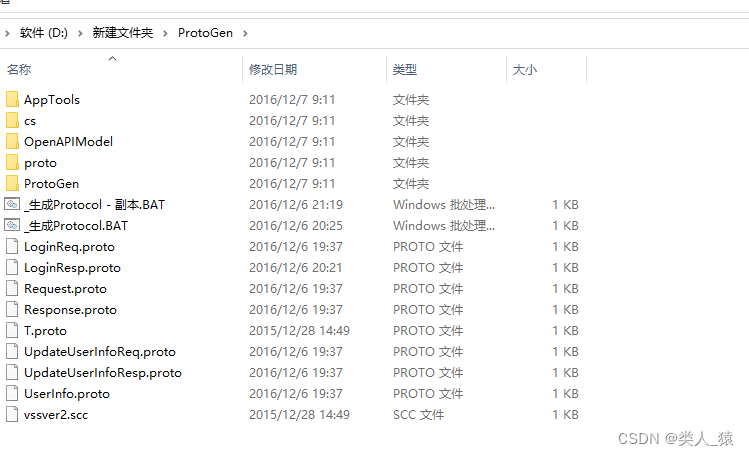
下面放了两个命令文件.BAT文件
如下图文件是将对应的这几个.proto文件生成对应的C#实体文件
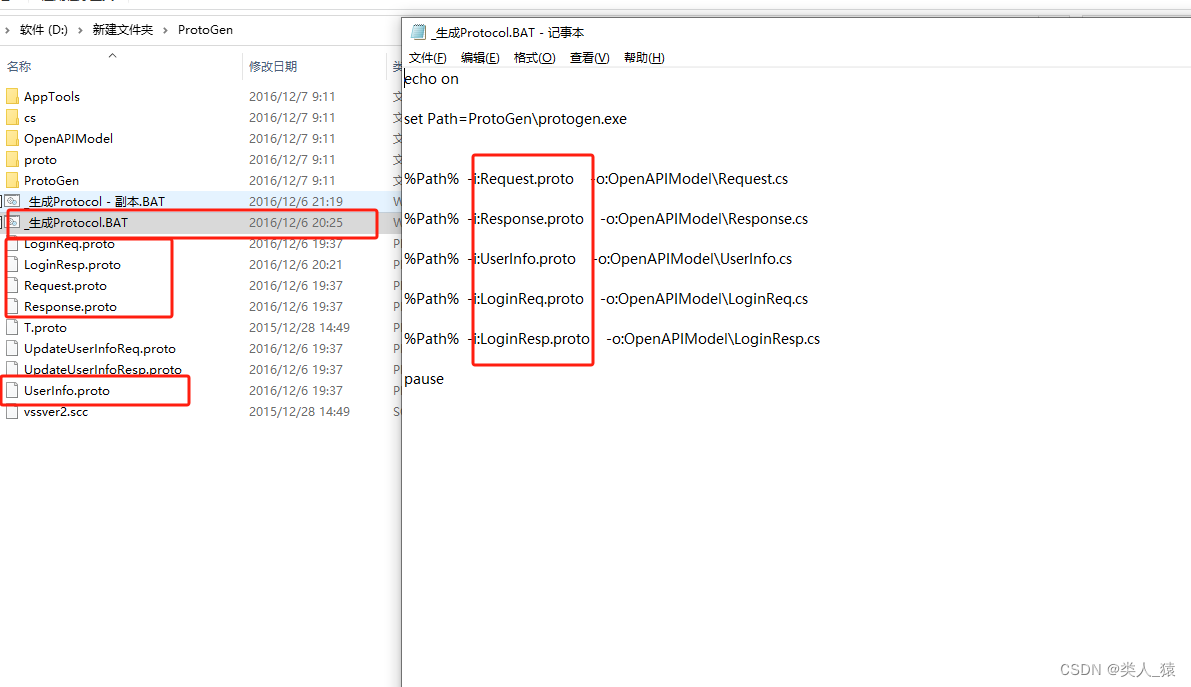
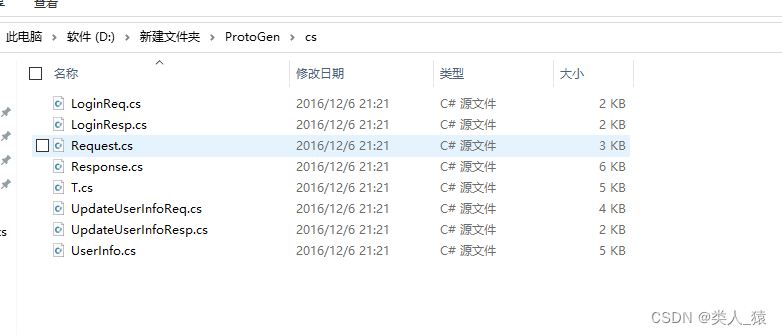
双击运行生成的C#文件如下
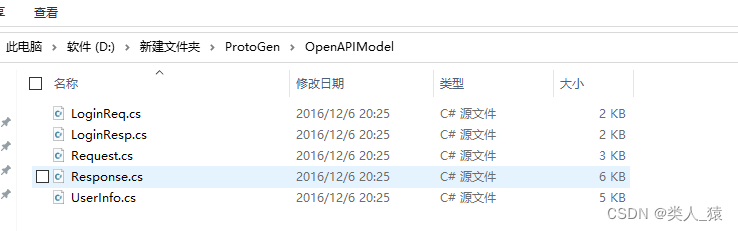
如下图所示的文件是将所有的.proto文件生成对应的C#文件
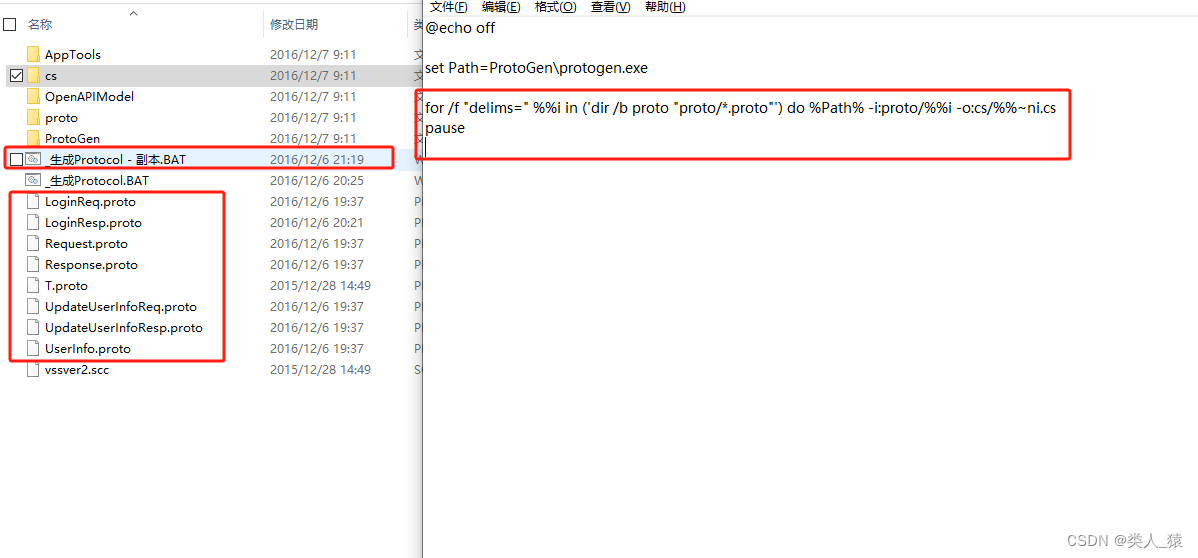
生成的C#文件如下图
总结
如果大家有别的更简便的方法可以私信一下,知识互相分享感谢
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【方案】如何利用大数据+云计算技术打造智能环境监控系统?
- 图数据库Gremlin语法(1)| 图基本概念与操作
- CPU缓存---致性协议剖析
- 爱思唯尔的KBS——模板、投稿、返修、接收的总结
- java 版本企业招标投标管理系统源码+多个行业+tbms+及时准确+全程电子化
- Mysql事务transaction简介
- html引入react以及hook的使用
- 【Linux C | 进程】Linux 进程间通信的10种方式(1)
- C++ 函数对象
- 用指针删除字符