grep笔记240103
常用选项::
-i:忽略大小写进行匹配。
-v:反向匹配,只打印不匹配的行。
-n:显示匹配行的行号。
-r:递归查找子目录中的文件。
-l:只打印匹配的文件名。
-c:只打印匹配的行数。
-A: 空格接数字,打印匹配行和之后数字行
-B: 空格接数字,打印匹配行和之前数字行
-C: 空格接数字,打印匹配行和之前数字行和之后数字行
grep的 -e , -E , -F , -G , -P 有什么区别
grep 是一个常用的命令行工具,用于在文本文件中搜索匹配指定模式的行。-e、-E、-F、-G 和 -P 是 grep 的选项,它们具有不同的功能和用途。
-e选项:grep -e pattern1 file.txt:仅匹配pattern1。grep -e pattern2 -e pattern3 file.txt:同时匹配pattern2和pattern3。- 可以多次使用
-e选项来指定多个模式。
-E选项:grep -E pattern1 file.txt:使用扩展正则表达式匹配pattern1。grep -E 'pattern2|pattern3' file.txt:使用管道符号 (|) 分隔的多个模式进行匹配。得并集- 也可以用
grep -E -e pattern1 -e pattern2 -e pattern3 file.txt来匹配多个表达式,得并集. 注意,是多个-e, 而-E只出现一次,表示启用扩展正则 - 扩展正则表达式提供了更多的元字符和语法,使得模式更加灵活和强大。
-F选项:grep -F pattern1 file.txt:将pattern1当作固定字符串进行匹配。grep -F 'pattern2\|pattern3' file.txt:使用管道符号 (|) 分隔的多个固定字符串进行匹配。- 与正则表达式不同,固定字符串不解释特殊字符或元字符。
-G选项:grep -G pattern1 file.txt:使用基本正则表达式匹配pattern1。- 基本正则表达式是传统的正则表达式语法,与扩展正则表达式相比,它的功能和语法较为有限。
-P选项:grep -P pattern1 file.txt:使用 Perl 兼容的正则表达式匹配pattern1。- Perl 兼容的正则表达式提供了更多的功能和语法,与扩展正则表达式类似,但不受 POSIX 标准限制。
总结:
-e用于指定单个模式进行匹配。-E使用扩展正则表达式进行匹配。-F将模式视为固定字符串进行匹配。-G使用基本正则表达式进行匹配。-P使用 Perl 兼容的正则表达式进行匹配。
在grep命令中,-e、-E、-F、-G和-P选项之间的区别如下:
-e选项:这是grep命令的常规选项,用于指定要搜索的模式。当使用-e选项时,grep会在文本中搜索与指定模式匹配的行。当只有一个表达式时,可以不写-e, 多个-e接多个表达式,相当于并集
-E选项:这个选项允许使用扩展正则表达式(Extended Regular Expression)。它提供了更多的正则表达式功能和灵活性,例如支持?、+、{}、()和|等元字符。使用-E选项可以编写更复杂的正则表达式模式来进行搜索。
-F选项:这个选项允许使用固定字符串进行搜索,而不是正则表达式。当使用-F选项时,grep会直接匹配指定的字符串,而不会解释为正则表达式。这提供了一种简单的方式来搜索特定的文本片段。
-G选项:这个选项允许使用基本正则表达式(Basic Regular Expression)进行搜索。基本正则表达式是传统的正则表达式语法,它提供了一些基本的元字符和语法,用于匹配文本中的模式。使用-G选项可以编写基本的正则表达式模式来进行搜索。
-P选项:这个选项允许使用Perl兼容的正则表达式(Perl-compatible Regular Expression)进行搜索。Perl正则表达式提供了比基本正则表达式更强大的功能,包括非捕获组、零宽断言和命名捕获组等高级功能。使用-P选项可以利用Perl正则表达式的强大功能进行复杂的文本搜索和处理。
这些选项为grep命令提供了不同的搜索模式和控制方式。根据您的具体需求,您可以选择适合的选项来执行特定的搜索任务。
grep的 -e和-E的区别
-e和-E可以一起用,功能没有对立性,没法区别, 应该是有无-E的区别
-e 后接脚本, 可以有多个, 相当于并集
-E 表示使用扩展正则,
当腰使用多个表达式的扩展正则时, 不是写多个-E, 而是多个-e一个-E
例如列出 grep --help 中,匹配到"A",或匹配到"B",或匹配到"C" 的行用:
grep --help | grep -e 'A' -e 'B' -e 'C' -E
# 列出 grep --help 中,匹配到"A",或匹配到"B",或匹配到"C" 的行用:
grep --help | grep -e 'A' -e 'B' -e 'C' -E
# 而不是
grep --help | grep -E 'A' -E 'B' -E 'C' 错误
grep -A -B -C 输出匹配行及相邻行
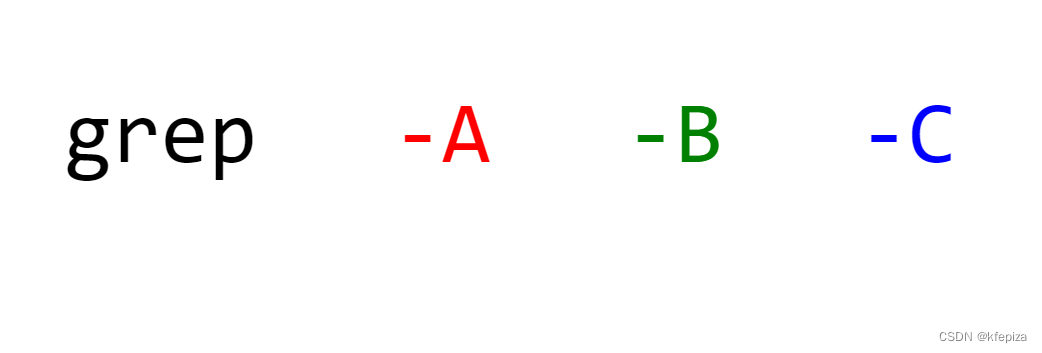
grep --help 摘抄👇
文件控制:
-B, --before-context=数值 打印前面 <数值> 行上下文-A, --after-context=数值 打印后面 <数值> 行上下文-C, --context=数值 打印前后 <数值> 行上下文
文件控制:
-B, --before-context=数值 打印前面 <数值> 行上下文
-A, --after-context=数值 打印后面 <数值> 行上下文
-C, --context=数值 打印前后 <数值> 行上下文
man grep摘抄
-A NUM, --after‐context=NUM
打印出紧随匹配的行之后的下文 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-B NUM, --before‐context=NUM
打印出匹配的行之前的上文 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-C NUM, --context=NUM
打印出匹配的行的上下文前后各 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-A NUM, --after‐context=NUM
打印出紧随匹配的行之后的下文 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-B NUM, --before‐context=NUM
打印出匹配的行之前的上文 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-C NUM, --context=NUM
打印出匹配的行的上下文前后各 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
grep输出匹配行及之后几行用 -A 数值
-A 或 --after-context=数值或 --after-context 数值,等号可有可无
打印后面 <数值> 行上下文
打印出紧随匹配的行之后的下文 NUM 行。在相邻的匹配组之间将会打印
例 打印匹配行和之后3行, 以下效果相同
grep --help | grep '\-A' -A 3
grep --help | grep -A 3 '\-A'
man grep | grep '\-A' -A 3
man grep | grep -A 3 '\-A'
grep --help | grep '\-A' --after-context=3
grep --help | grep '\-A' --after-context 3
man grep | grep '\-A' --after-context=3
man grep | grep '\-A' --after-context 3
grep --help | grep --after-context=3 '\-A'
grep --help | grep --after-context 3 '\-A'
man grep | grep --after-context=3 '\-A'
man grep | grep --after-context 3 '\-A'
grep输出匹配行及之前几行用 -B 数值
-B 数值 或 --before-context=数值或 --before-context 数值,等号可有可无
打印前面 <数值> 行上下文
打印出匹配的行之前的上文 NUM 行。在相邻的匹配组之间将会打印内容是 – 的一行。
例 : 打印匹配行和之前3行, 以下效果相同
grep --help | grep '\-B' -B 3
grep --help | grep -B 3 '\-B'
man grep | grep '\-B' -B 3
man grep | grep -B 3 '\-B'
grep --help | grep '\-B' --before-context=3
grep --help | grep '\-B' --before-context 3
man grep | grep '\-B' --before-context=3
man grep | grep '\-B' --before-context 3
grep --help | grep --before-context=3 '\-B'
grep --help | grep --before-context 3 '\-B'
man grep | grep --before-context=3 '\-B'
man grep | grep --before-context 3 '\-B'
grep输出匹配行及之前几行用 -C 数值
-C 数值 或 --context=数值或 --context 数值,等号可有可无
打印前后 <数值> 行上下文
打印出匹配的行的上下文前后各 NUM 行。在相邻的匹配组之间将会打印内容是 – 的一行。
例 : 打印匹配行和之前之后各3行, 以下效果相同
grep --help | grep '\-C' -C 3
grep --help | grep -C 3 '\-C'
man grep | grep '\-C' -C 3
man grep | grep -C 3 '\-C'
grep --help | grep '\-C' --context=3
grep --help | grep '\-C' --context 3
man grep | grep '\-C' --context=3
man grep | grep '\-C' --context 3
grep --help | grep --context=3 '\-C'
grep --help | grep --context 3 '\-C'
man grep | grep --context=3 '\-C'
man grep | grep --context 3 '\-C'
分别用 grep,sed,awk 实现文本筛选过滤功能

筛选ip address show的ipv4
ip address show可简写为ip address可简写为ip a
[z@1235eth5 root]$ ip a | grep 'inet\b'
inet 127.0.0.1/8 scope host lo
inet 10.12.35.5/8 brd 10.255.255.255 scope global dynamic noprefixroute enp7s0
[z@1235eth5 root]$ ip a | sed '/inet\b/p' -n
inet 127.0.0.1/8 scope host lo
inet 10.12.35.5/8 brd 10.255.255.255 scope global dynamic noprefixroute enp7s0
[z@1235eth5 root]$ ip a | awk '/inet\>/{print}'
inet 127.0.0.1/8 scope host lo
inet 10.12.35.5/8 brd 10.255.255.255 scope global dynamic noprefixroute enp7s0
ip a | grep 'inet\b'
ip a | sed '/inet\b/p' -n
ip a | awk '/inet\>/{print}'
也可不写{}, 当没有大括号{}时, 相当于有{print $0}={print}
ip a | awk '/inet\>/{print $0}'
ip a | awk '/inet\>/{print}'
ip a | awk '/inet\>/'
测试时, \b在awk中不起作用, 使用了\>代替
在正则中,
\b表示单词边界\<表示单词开始边界\>表示单词结束边界
awk分gawk,mawk等
在Ubuntu2204Desktop版中, awk \b和 \> 都不起作用, 原因是使用了 mawk . Ubuntu2204Server默认用的是 gawk , 也能用 mawk
Fedora39的awk是gawk
ip a | sed '/inet\b/p' -n
👆也可写成👇
ip a | sed -n '/inet\b/p'
-n 是不输出过滤前的内容, p是输出过滤匹配的行 ;
- 如果只有
-n, 那就什么都看不到 - 如果只有
p, 会发现所有内容都输出, 且匹配的内容出现两遍
grep反匹配用-v , 输出匹配不到内容的行
grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行。Unix的grep家族包括grep、egrep和fgrep。Windows系统下类似命令FINDSTR。
grep -v 反匹配输出,结果取反,输出不匹配的行,输出不匹配的结果,反匹配,不匹配表达式,输出与表达式不匹配的内容



用法: grep [选项]... 模式 [文件]...
在每个<文件>中查找给定<模式>。
例如:grep -i 'hello world' menu.h main.c
<模式>可以包括多个模式字符串,使用换行符进行分隔。
模式选择与解释:
-E, --extended-regexp <模式> 是扩展正则表达式
-F, --fixed-strings <模式> 是字符串
-G, --basic-regexp <模式> 是基本正则表达式
-P, --perl-regexp <模式> 是 Perl 正则表达式
-e, --regexp=<模式> 用指定的<模式>字符串来进行匹配操作
-f, --file=<文件> 从给定<文件>中取得<模式>
-i, --ignore-case 在模式和数据中忽略大小写
--no-ignore-case 不要忽略大小写(默认)
-w, --word-regexp 强制<模式>仅完全匹配字词
-x, --line-regexp 强制<模式>仅完全匹配整行
-z, --null-data 数据行以一个 0 字节结束,而非换行符
杂项:
-s, --no-messages 不显示错误信息
-v, --invert-match 选中不匹配的行
-V, --version 显示版本信息并退出
--help 显示此帮助并退出
输出控制:
-m, --max-count=<次数> 得到给定<次数>次匹配后停止
-b, --byte-offset 输出的同时打印字节偏移
-n, --line-number 输出的同时打印行号
--line-buffered 每行输出后刷新输出缓冲区
-H, --with-filename 为输出行打印文件名
-h, --no-filename 输出时不显示文件名前缀
--label=<标签> 将给定<标签>作为标准输入文件名前缀
-o, --only-matching 只显示行中非空匹配部分
-q, --quiet, --silent 不显示所有常规输出
--binary-files=TYPE 设定二进制文件的 TYPE(类型);
TYPE 可以是 'binary'、'text' 或 'without-match'
-a, --text 等同于 --binary-files=text
-I 等同于 --binary-files=without-match
-d, --directories=ACTION 读取目录的方式;
ACTION 可以是`read', `recurse',或`skip'
-D, --devices=ACTION 读取设备、先入先出队列、套接字的方式;
ACTION 可以是`read'或`skip'
-r, --recursive 等同于--directories=recurse
-R, --dereference-recursive 同上,但遍历所有符号链接
--include=GLOB 只查找匹配 GLOB(文件模式)的文件
--exclude=GLOB 跳过匹配 GLOB 的文件
--exclude-from=FILE 跳过所有匹配给定文件内容中任意模式的文件
--exclude-dir=GLOB 跳过所有匹配 GLOB 的目录
-L, --files-without-match 只打印没有匹配上的<文件>的名称
-l, --files-with-matches 只打印有匹配的<文件>的名称
-c, --count 只打印每个<文件>中的匹配行数目
-T, --initial-tab 行首制表符对齐(如有必要)
-Z, --null 在<文件>名最后打印空字符
文件控制:
-B, --before-context=NUM 打印文本及其前面NUM 行
-A, --after-context=NUM 打印文本及其后面NUM 行
-C, --context=NUM 打印NUM 行输出文本
-NUM same as --context=NUM
--group-separator=SEP print SEP on line between matches with context
--no-group-separator do not print separator for matches with context
--color[=WHEN],
--colour[=WHEN] use markers to highlight the matching strings;
WHEN is 'always', 'never', or 'auto'
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
若给定文件为“-”,则从读取标准输入。 若无文件参数,则除非处于
递归工作模式视为从“.”读取之外,一律视为从“-”读取。如果提供了少于
两个文件参数,则默认启用 -h 选项。如果有任意行被匹配则退出状态为 0,
否则为 1;如果有错误产生且未指定 -q 参数,则退出状态为 2。
用法: grep [选项]… 模式 [文件]…
在每个<文件>中查找给定<模式>。
例如:grep -i ‘hello world’ menu.h main.c
<模式>可以包括多个模式字符串,使用换行符进行分隔。
模式选择与解释:
-E, --extended-regexp <模式> 是扩展正则表达式
-F, --fixed-strings <模式> 是字符串
-G, --basic-regexp <模式> 是基本正则表达式
-P, --perl-regexp <模式> 是 Perl 正则表达式
-e, --regexp=<模式> 用指定的<模式>字符串来进行匹配操作
-f, --file=<文件> 从给定<文件>中取得<模式>
-i, --ignore-case 在模式和数据中忽略大小写
–no-ignore-case 不要忽略大小写(默认)
-w, --word-regexp 强制<模式>仅完全匹配字词
-x, --line-regexp 强制<模式>仅完全匹配整行
-z, --null-data 数据行以一个 0 字节结束,而非换行符
杂项:
-s, --no-messages 不显示错误信息
-v, --invert-match 选中不匹配的行
-V, --version 显示版本信息并退出
–help 显示此帮助并退出
输出控制:
-m, --max-count=<次数> 得到给定<次数>次匹配后停止
-b, --byte-offset 输出的同时打印字节偏移
-n, --line-number 输出的同时打印行号
–line-buffered 每行输出后刷新输出缓冲区
-H, --with-filename 为输出行打印文件名
-h, --no-filename 输出时不显示文件名前缀
–label=<标签> 将给定<标签>作为标准输入文件名前缀
-o, --only-matching 只显示行中非空匹配部分
-q, --quiet, --silent 不显示所有常规输出
–binary-files=TYPE 设定二进制文件的 TYPE(类型);
TYPE 可以是 ‘binary’、‘text’ 或 ‘without-match’
-a, --text 等同于 --binary-files=text
-I 等同于 --binary-files=without-match
-d, --directories=ACTION 读取目录的方式;
ACTION 可以是read', recurse’,或skip' -D, --devices=ACTION 读取设备、先入先出队列、套接字的方式; ACTION 可以是read’或`skip’
-r, --recursive 等同于–directories=recurse
-R, --dereference-recursive 同上,但遍历所有符号链接
–include=GLOB 只查找匹配 GLOB(文件模式)的文件
–exclude=GLOB 跳过匹配 GLOB 的文件
–exclude-from=FILE 跳过所有匹配给定文件内容中任意模式的文件
–exclude-dir=GLOB 跳过所有匹配 GLOB 的目录
-L, --files-without-match 只打印没有匹配上的<文件>的名称
-l, --files-with-matches 只打印有匹配的<文件>的名称
-c, --count 只打印每个<文件>中的匹配行数目
-T, --initial-tab 行首制表符对齐(如有必要)
-Z, --null 在<文件>名最后打印空字符
文件控制:
-B, --before-context=NUM 打印文本及其前面NUM 行
-A, --after-context=NUM 打印文本及其后面NUM 行
-C, --context=NUM 打印NUM 行输出文本
-NUM same as --context=NUM
–group-separator=SEP print SEP on line between matches with context
–no-group-separator do not print separator for matches with context
–color[=WHEN],
–colour[=WHEN] use markers to highlight the matching strings;
WHEN is ‘always’, ‘never’, or ‘auto’
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
若给定文件为“-”,则从读取标准输入。 若无文件参数,则除非处于
递归工作模式视为从“.”读取之外,一律视为从“-”读取。如果提供了少于
两个文件参数,则默认启用 -h 选项。如果有任意行被匹配则退出状态为 0,
否则为 1;如果有错误产生且未指定 -q 参数,则退出状态为 2。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!