LLM之RAG实战(七)| 使用llama_index实现多模态RAG

一、多模态RAG
? ? ? ?OpenAI开发日上最令人兴奋的发布之一是GPT-4V API(https://platform.openai.com/docs/guides/vision)的发布。GPT-4V是一个多模态模型,可以接收文本/图像,并可以输出文本响应。最近还有一些其他的多模态模型:LLaVa和Fuyu-8B。
?? ? ? 在过去的一年里,大部分应用程序开发都是围绕文本输入/文本输出范式。最典型的例子之一是检索增强生成(RAG)——将LLM与外部文本语料库相结合,对模型未经训练的数据进行推理。通过处理任意文档(比如PDF、网页),将其切分为块并存储到向量数据库中,然后通过检索到相关的块输入给LLM,让LLM给出用户期待的回复。
? ? ? ?与标准RAG pipeline对比,我们看一下多模态RAG的所有步骤:
输入:输入可以是文本或图像。
检索:检索到的上下文可以是文本或图像。
合成:答案可以在文本和图像上合成。
响应:返回的结果可以是文本和/或图像。
? ? ? ?也可以在图像和文本之间采用链式/顺序调用,例如检索增强图像字幕或在多模态代理进行循环。
二、多模态LLM
? ?OpenAIMultiModal类可以直接支持GPT-4V模型,ReplicateMultiModal类可以支持开源多模式模型(目前处于测试版,因此名称可能会更改)。SimpleDirectoryReader能够接收音频、图像和视频,现在可以直接将它们传递给GPT-4V并进行问答,如下所示:
from llama_index.multi_modal_llms import OpenAIMultiModalfrom llama_index import SimpleDirectoryReader?image_documents = SimpleDirectoryReader(local_directory).load_data()?openai_mm_llm = OpenAIMultiModal(model="gpt-4-vision-preview", api_key=OPENAI_API_TOKEN, max_new_tokens=300)response = openai_mm_llm.complete(prompt="what is in the image?", image_documents=image_documents)
? ? ? ?与默认具有标准的完成/聊天端点的LLM类不同,多模态模型(MultiModalLLM)可以接受图像和文本作为输入。
三、多模态嵌入
? ? ? 我们介绍一个新的MultiModalEmbedding基类,它既可以embedding文本也可以embedding图像。它包含了我们现有嵌入模型的所有方法(子类BaseEmbedding),但也公开了get_image_embedding。我们在这里的主要实现是使用CLIP模型的ClipEmbedding。
四、多模态索引与检索
? ? ??MultiModalVectorIndex可以从向量数据库中索引文本和图像。与我们现有的(最流行的)索引VectorStoreIndex不同,这个新索引可以存储文本和图像文档。索引文本与之前是一样的——使用文本嵌入模型嵌入的,并存储在矢量数据库中。图像索引是一个单独的过程,如下所示:、
- 使用CLIP嵌入图像;
- 使用base64编码或路径表示图像节点,并将其与嵌入一起存储在矢量数据库中(与文本分离)。
? ? ? ?我们将图像和文本分开存储,因为我们可能希望对文本使用纯文本嵌入模型,而不是CLIP嵌入(例如ada或sbert)。
在检索期间,我们执行以下操作:
- 通过在文本嵌入上进行矢量搜索来检索文本;
- 通过在图像嵌入上进行矢量搜索来检索图像
文本和图像作为节点返回到结果列表中,然后再汇总这些结果。
五、多模态RAG实战
? ? ? ?下面我们以查询特斯拉为例展示llama_index实现多模态RAG,根据给出特斯拉的网站或车辆、SEC填充物和维基百科页面的截图来查询特斯拉。
加载文本和图像混合文本:
documents = SimpleDirectoryReader("./mixed_wiki/").load_data()? ? ? ?然后,我们在Qdrant中定义两个独立的矢量数据库:一个用于存储文本文档,一个用于存储图像。然后我们定义一个MultiModalVectorStoreIndex。
# Create a local Qdrant vector storeclient = qdrant_client.QdrantClient(path="qdrant_mm_db")?text_store = QdrantVectorStore(client=client, collection_name="text_collection")image_store = QdrantVectorStore(client=client, collection_name="image_collection")storage_context = StorageContext.from_defaults(vector_store=text_store)?# Create the MultiModal indexindex = MultiModalVectorStoreIndex.from_documents(documents, storage_context=storage_context, image_vector_store=image_store)
? ? ? ?最后,我们可以通过我们的多模态语料库进行提问。
示例1:检索增强字幕
? ? ? ?我们复制/粘贴初始图像标题作为输入,以获得检索增强输出:
retriever_engine = index.as_retriever(similarity_top_k=3, image_similarity_top_k=3)# retrieve more information from the GPT4V responseretrieval_results = retriever_engine.retrieve(query_str)
检索到的结果包含图像和文本:

我们可以将其提供给GPT-4V,以提出后续问题或综合一致的回答:

示例2:多模态RAG查询
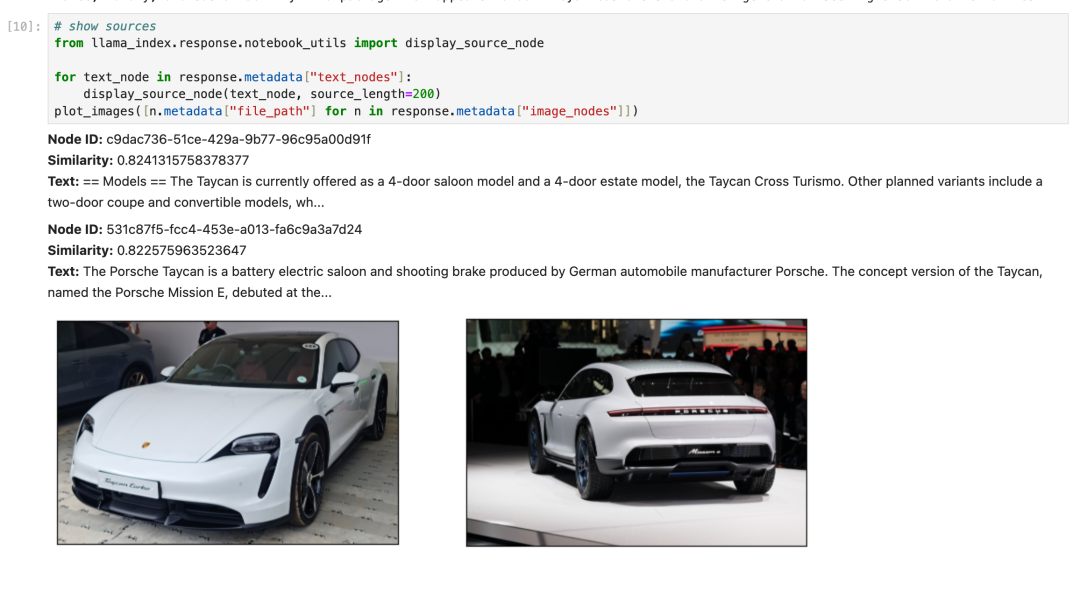
? ? ? 我们提出了一个问题,并从整个多模态RAG pipeline中得到回应。SimpleMultiModalQueryEngine首先检索相关图像/文本集,并将其输入给视觉模型,以便合成响应。
from llama_index.query_engine import SimpleMultiModalQueryEngine?query_engine = index.as_query_engine(multi_modal_llm=openai_mm_llm,text_qa_template=qa_tmpl)?query_str = "Tell me more about the Porsche"response = query_engine.query(query_str)
? ? ? ? ?生成的结果+来源如下所示:

参考文献:
[1]?https://blog.llamaindex.ai/multi-modal-rag-621de7525fea
[2]?https://github.com/run-llama/llama_index/blob/main/docs/examples/multi_modal/llava_multi_modal_tesla_10q.ipynb
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ROS:rosdep与ROS2的安装记录
- 关于C#中的LINQ的延迟执行
- 前端开发1:HTML
- js逆向第21例:猿人学第20题新年挑战
- 从测试工程师到测试经理,年终总结背后的不同焦点和策略揭秘!
- 数字人解决方案——ER-NeRF实时对话数字人模型推理部署带UI交互界面
- 基于 InternLM 和 LangChain 搭建知识库
- 【刷题】前缀树
- 【虹科分享】使用Allegro网络万用表进行网络分析
- linux 内核工作延迟机制-工作队列