【大模型AIGC系列课程 5-2】视觉-语言大模型原理
发布时间:2023年12月18日
重磅推荐专栏: 《大模型AIGC》;《课程大纲》
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
VisualGLM
BLIP-2
https://arxiv.org/pdf/2301.12597.pdf
BLIP-2是一种用于视觉-语言预训练的方法,它利用了冻结的预训练图像编码器和大型语言模型。BLIP-2的核心架构是Querying Transformer(Q-Former),它经过两个阶段的预训练来弥合模态差距。
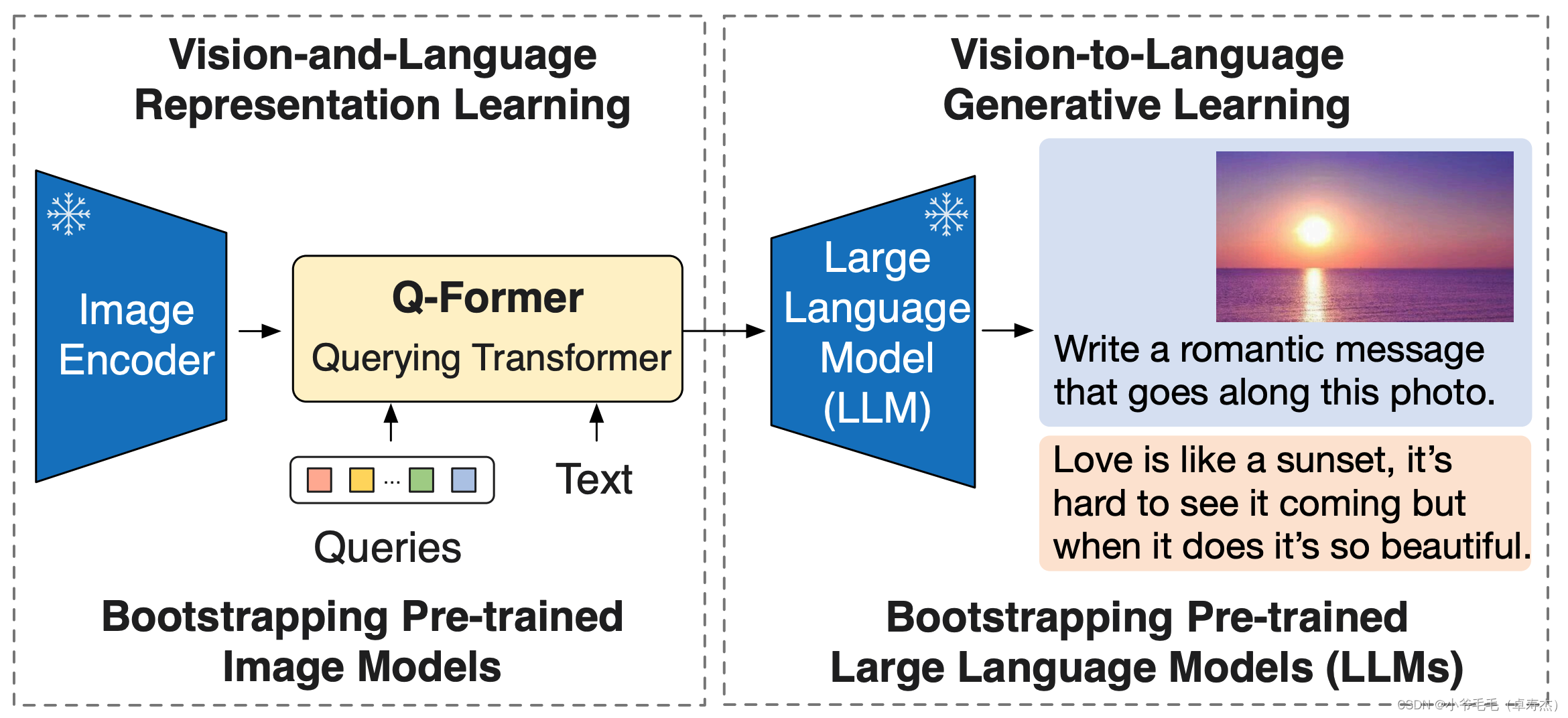
在第一个预训练阶段,Q-Former与一个冻结的图像编码器一起进行视觉-语言表示学习。这个阶段的目标是让Q-Former学习与文本最相关的视觉表示。通过与图像编码器的连接,Q-Former可以从冻结的图像编码器中获取视觉特征。
在第二个预训练阶段,Q-Former与一个冻结的语言模型进行视觉-语言生成学习。这个阶段的目标是让Q-
文章来源:https://blog.csdn.net/u011239443/article/details/135067033
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LogGPT: Exploring ChatGPT for Log-Based Anomaly Detection
- 【保姆级教程】PAI x EasyPhoto,节日氛围AI写真生成
- Web端3D开发工具包HOOPS,助力建筑服务商6个月打造差异化云端产品!
- Nginx快速入门:nginx实现正向代理|反向代理和正向代理的区别(八)
- eds文件
- 3.docker交互【 】
- 确定转角起始扭矩值的方法有哪些
- 【pytorch】自动求导机制
- 在SQL脚本中删除所有的 prompt那一行
- 视频剪辑方法:批量剪辑新思路,AI智剪来助阵