MySQL的高级SQL语句
发布时间:2023年12月28日
目录
1.mysql高阶查询
例:
use ybc;
create table location (Region char(20),Store_Name char(20));
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');
create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');
select:显示表格中一个或数个字段的所有数据记录
语法:
select "字段" from "表名";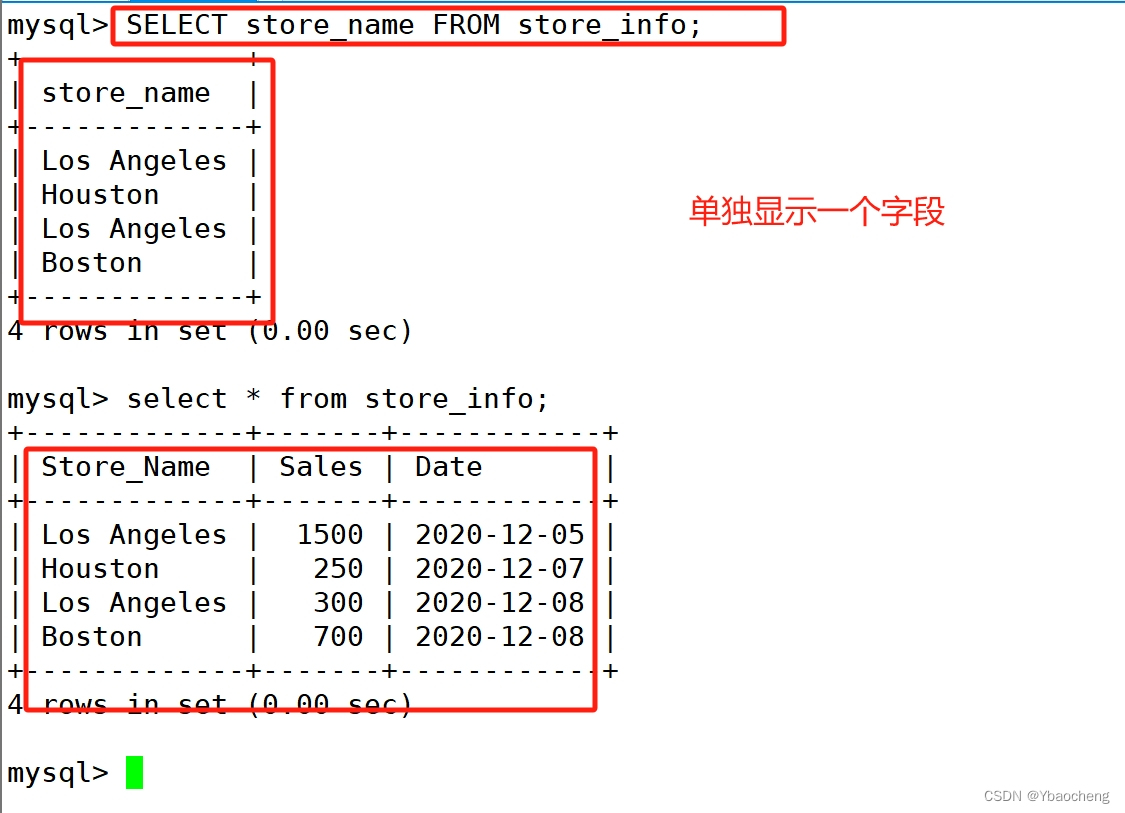
?distinct:不显示重复的数据记录
语法:
select distinct "字段" from "表名";
where:有条件查询
语法:
select "字段" from "表名" where "条件";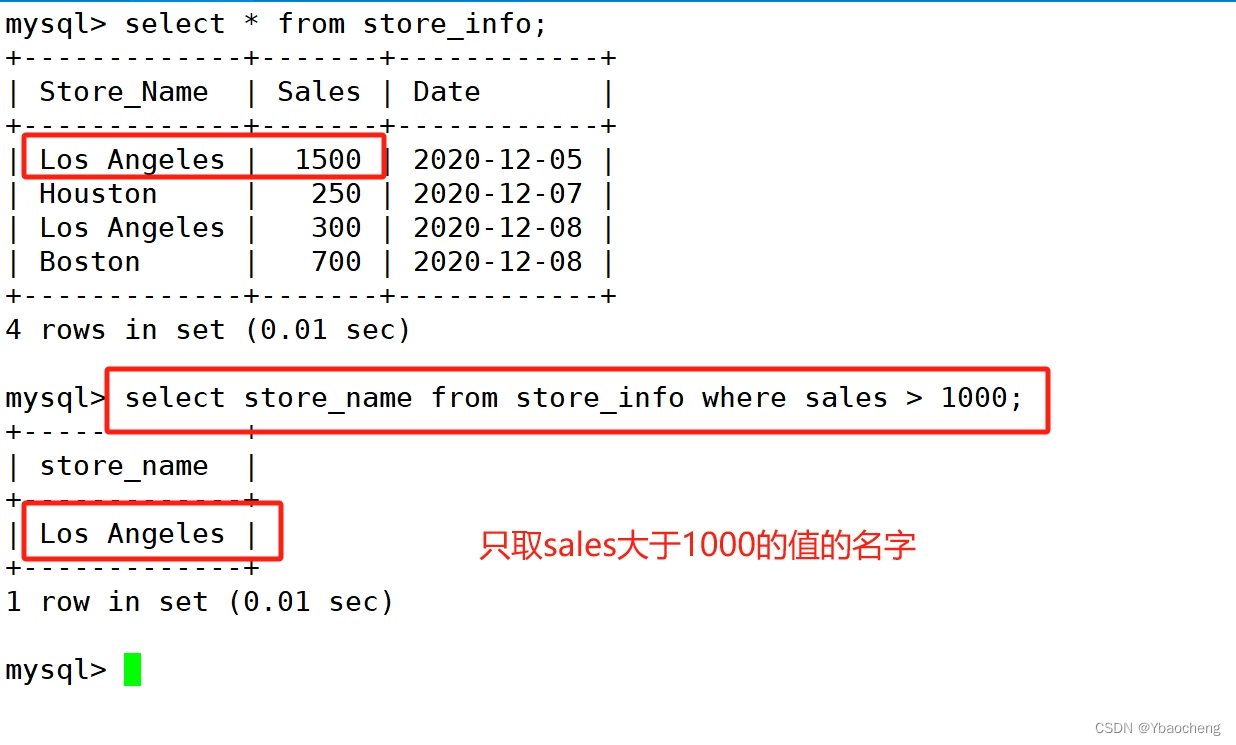
AND OR :且? 或
语法:
select "字段" from "表名" where "条件1" {[and|or] "条件2"}+ ;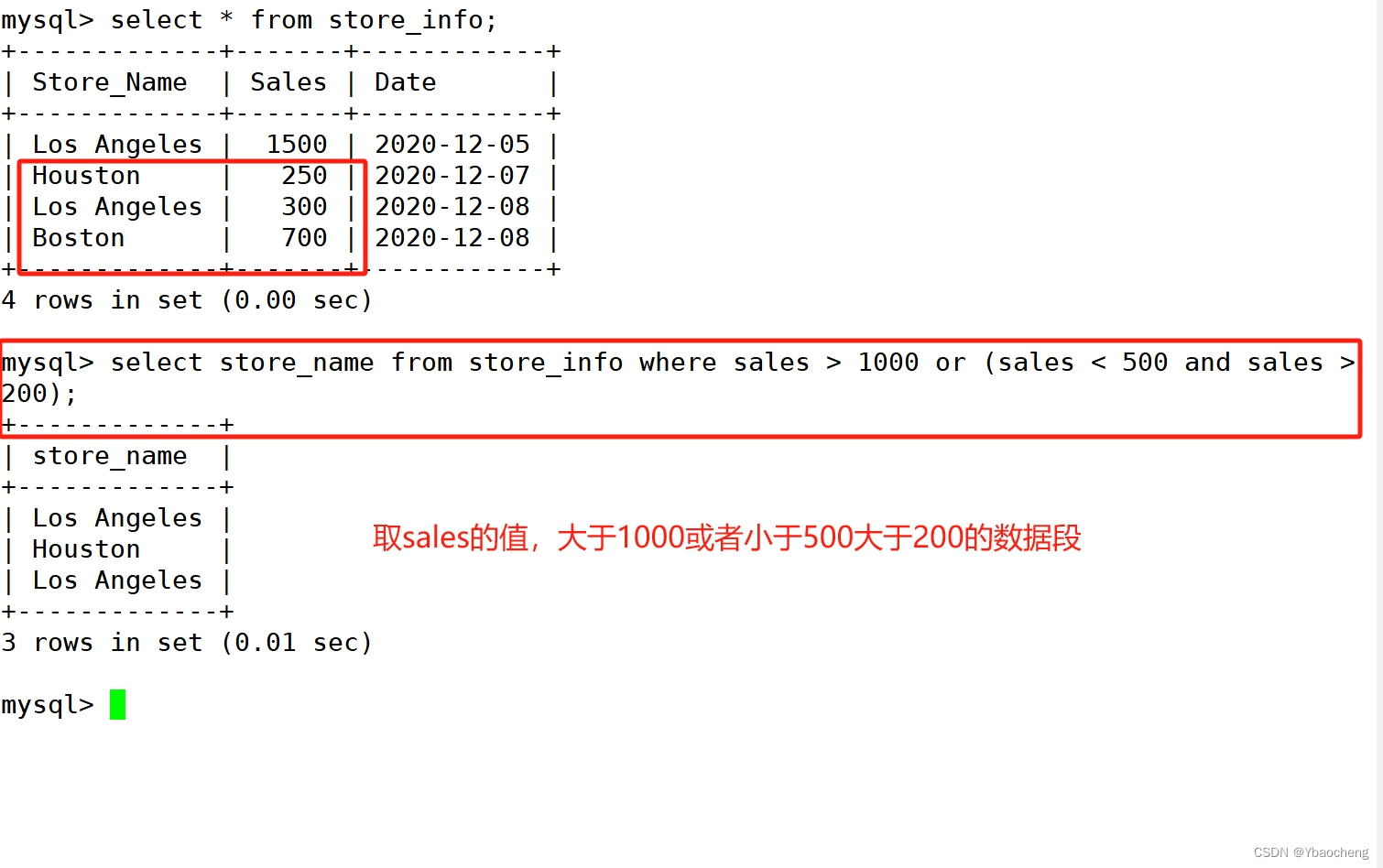
in:显示已知值的数据记录
语法:
select "字段" from "表名" where "字段" in ('值1', '值2', ...);

between:显示两个值范围内的数据记录
语法:
select "字段" from "表名" where "字段" between '值1' and '值2';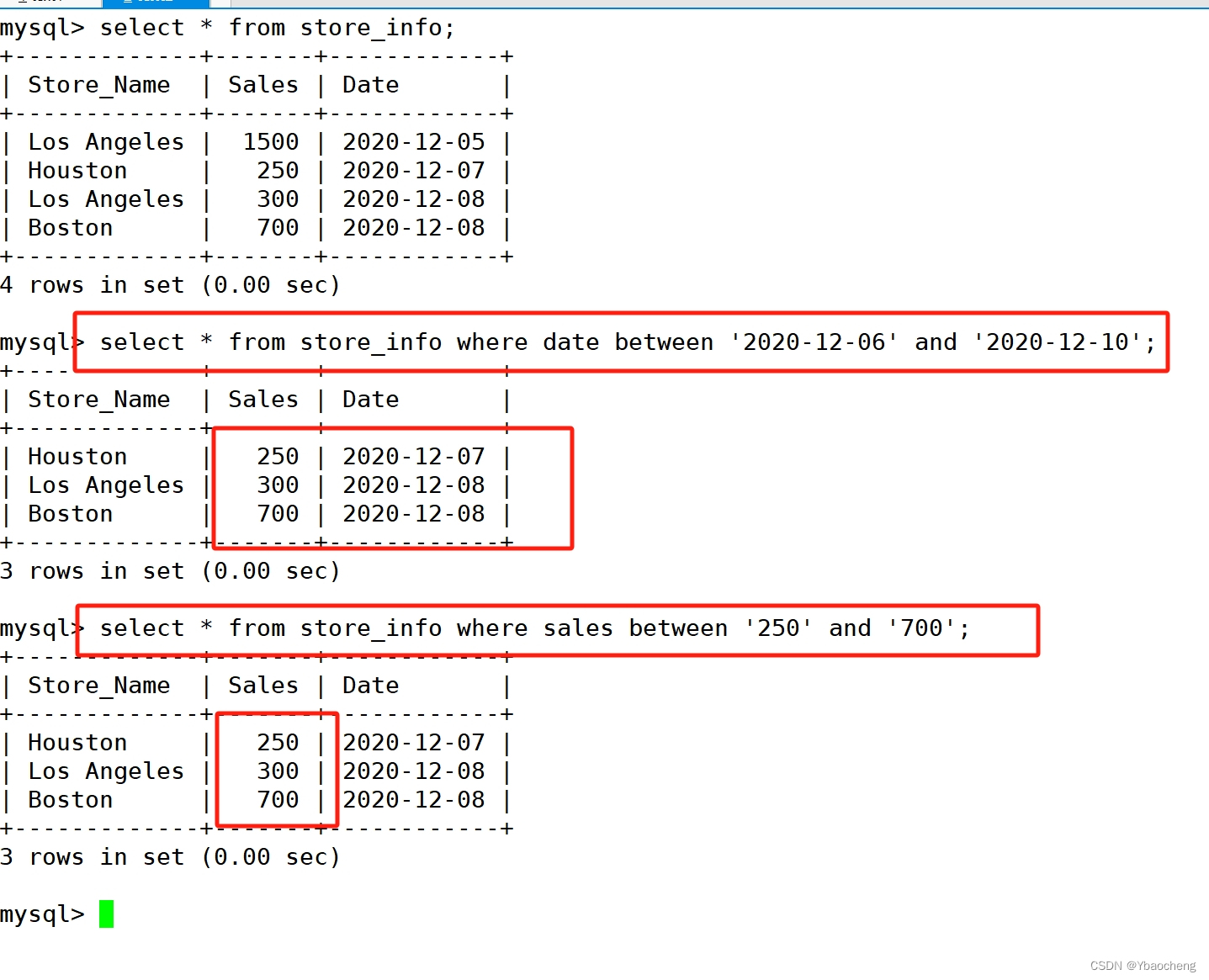
order by:关键字排序
语法:
select "字段" from "表名" [where "条件"] order by "字段" [ASC, DESC];
ASC 是按照升序进行排序的,是默认的排序方式。
DESC 是按降序方式进行排序。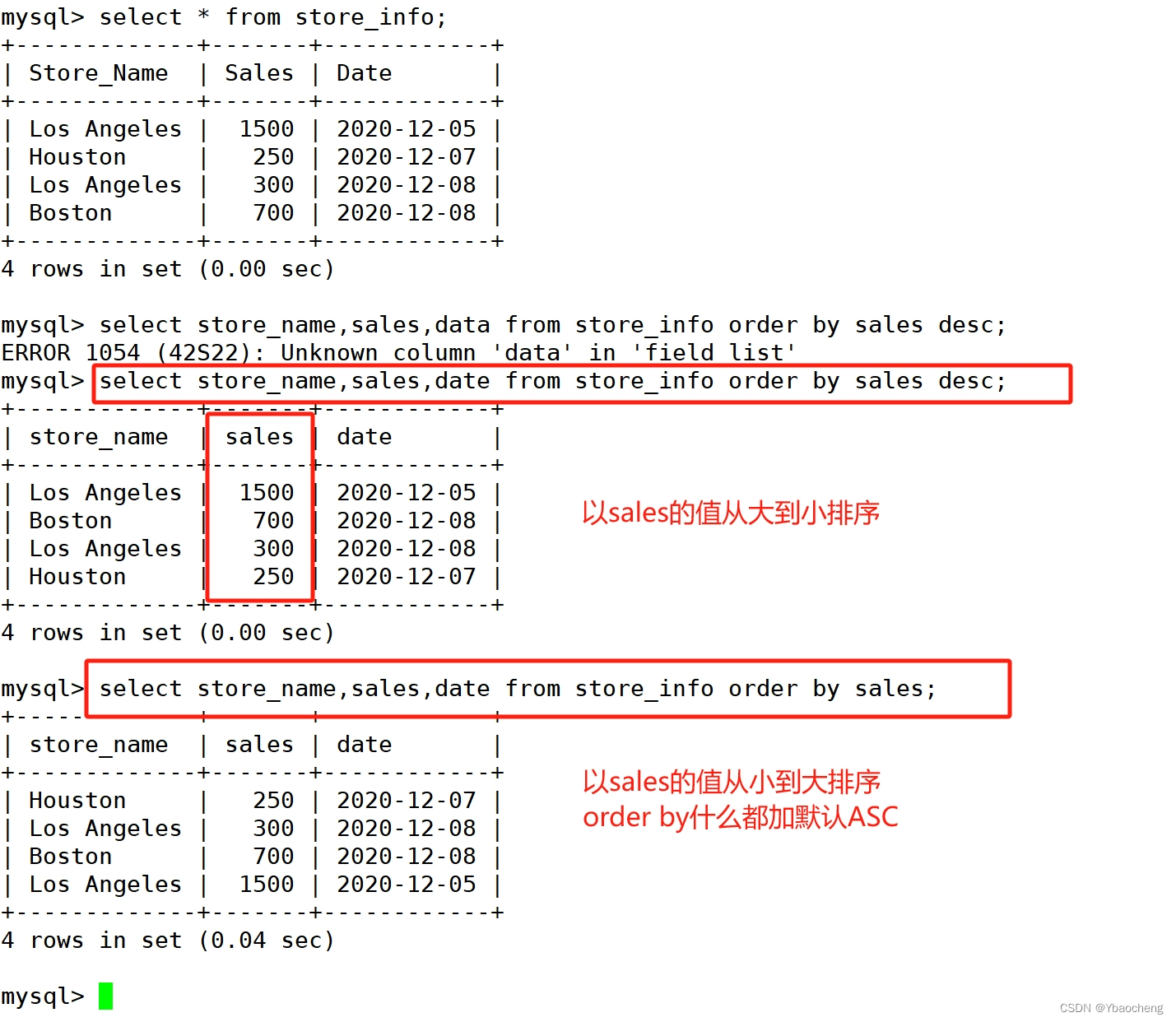
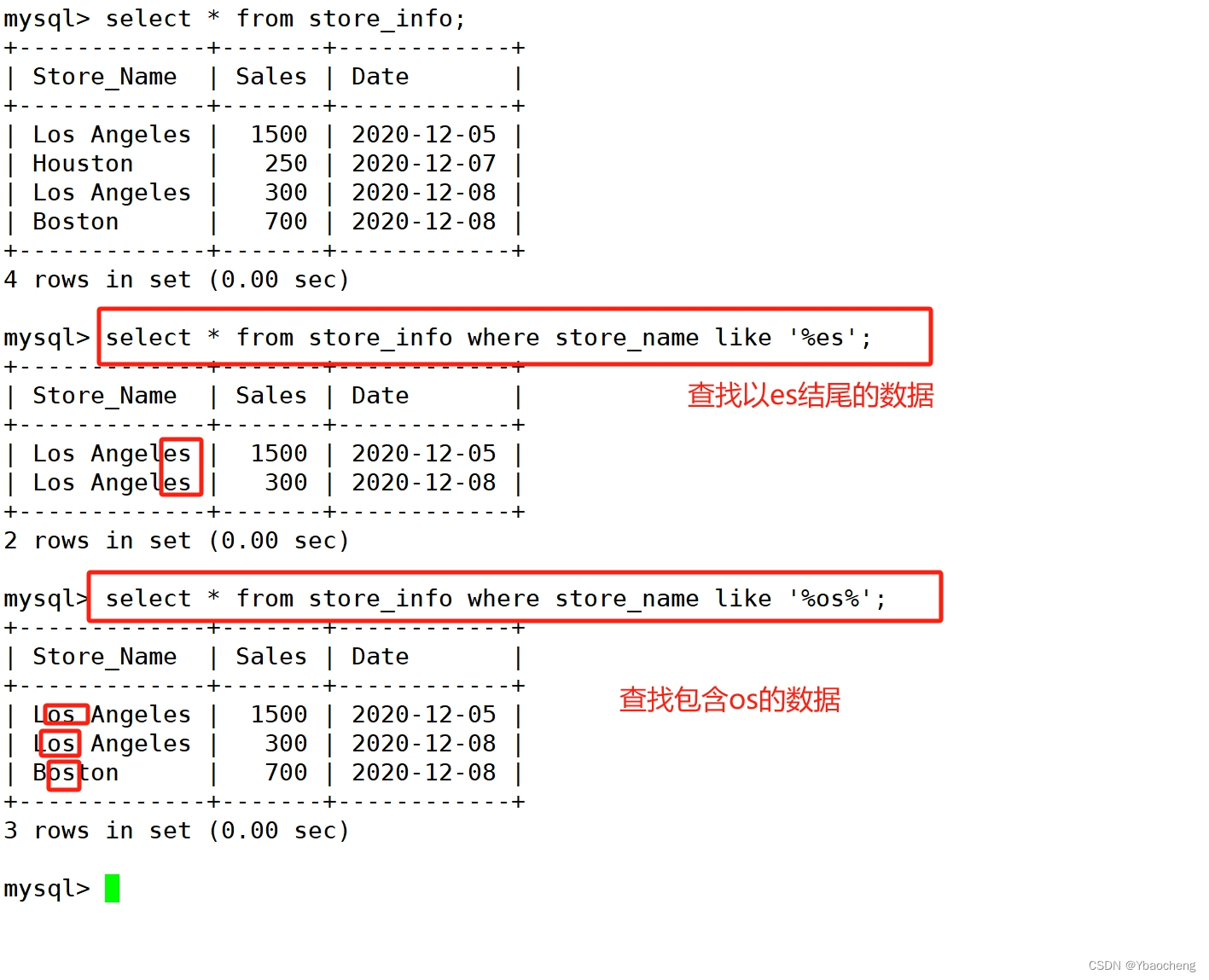
2.like+通配符
语法:
select "字段" from "表名" where "字段" like {模式};| 通配符 | 含义 |
|---|---|
| % | 表示零个、一个或多个字符 |
| _ | 表示单个字符 |
| 'A_Z' | 所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串 |
| 'ABC%' | 所有以 'ABC' 起头的字符串 |
| '%XYZ' | 所有以 'XYZ' 结尾的字符串 |
| '%AN%' | 所有含有 'AN'这个模式的字符串 |
| '_AN%' | 所有第二个字母为 'A' 和第三个字母为 'N' 的字符串 |
3.SQL函数
数学函数
| 函数 | 含义 |
|---|---|
| abs(x) | 返回 x 的绝对值 |
| rand() | 返回 0 到 1 的随机数 |
| mod(x,y) | 返回 x 除以 y 以后的余数 |
| power(x,y) | 返回 x 的 y 次方 |
| round(x) | 返回离 x 最近的整数 |
| round(x,y) | 保留 x 的 y 位小数四舍五入后的值 |
| sqrt(x) | 返回 x 的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2...) | 返回集合中最大的值,也可以返回多个字段的最大的值 |
| least(x1,x2...) | 返回集合中最小的值,也可以返回多个字段的最小的值 |



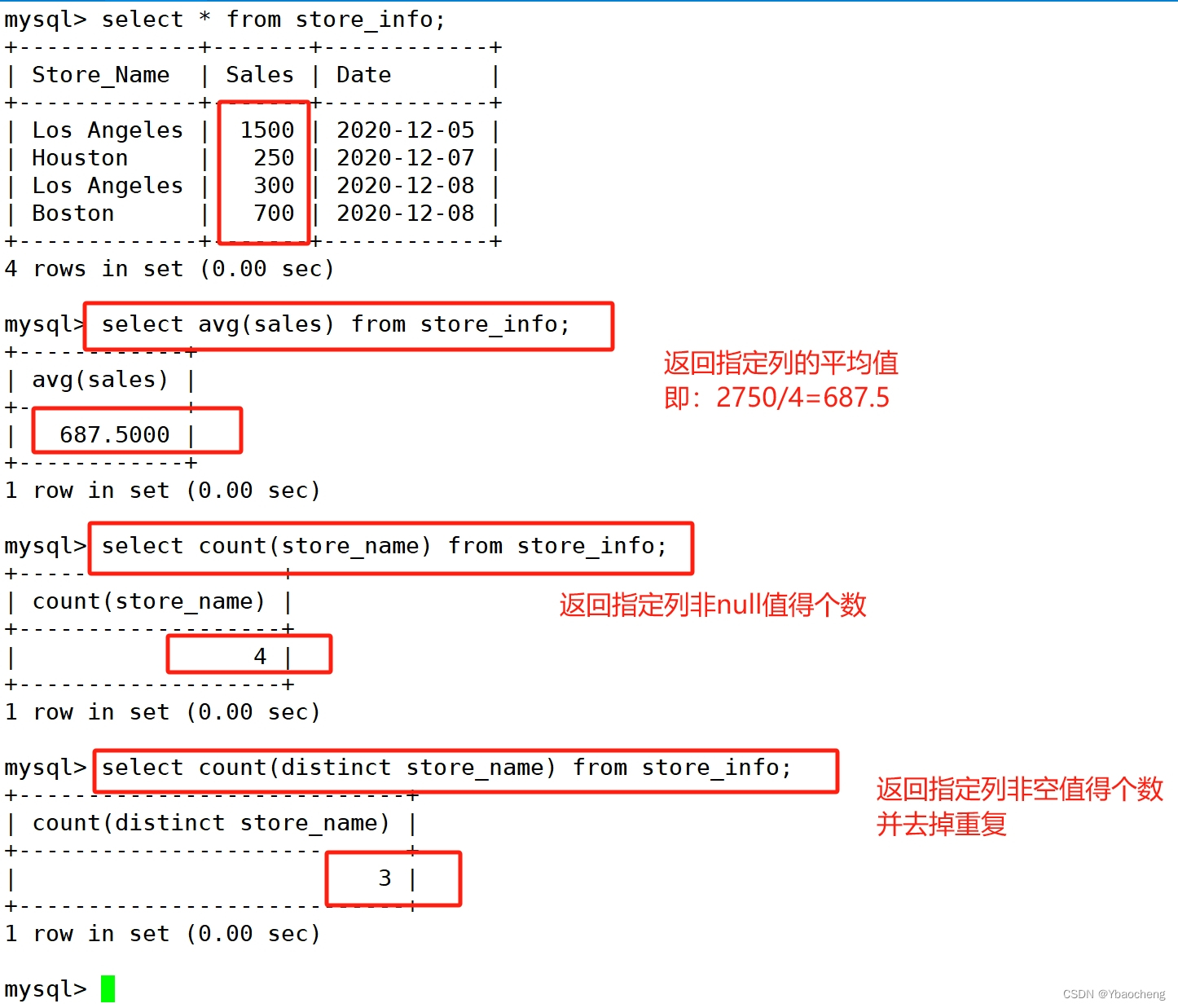
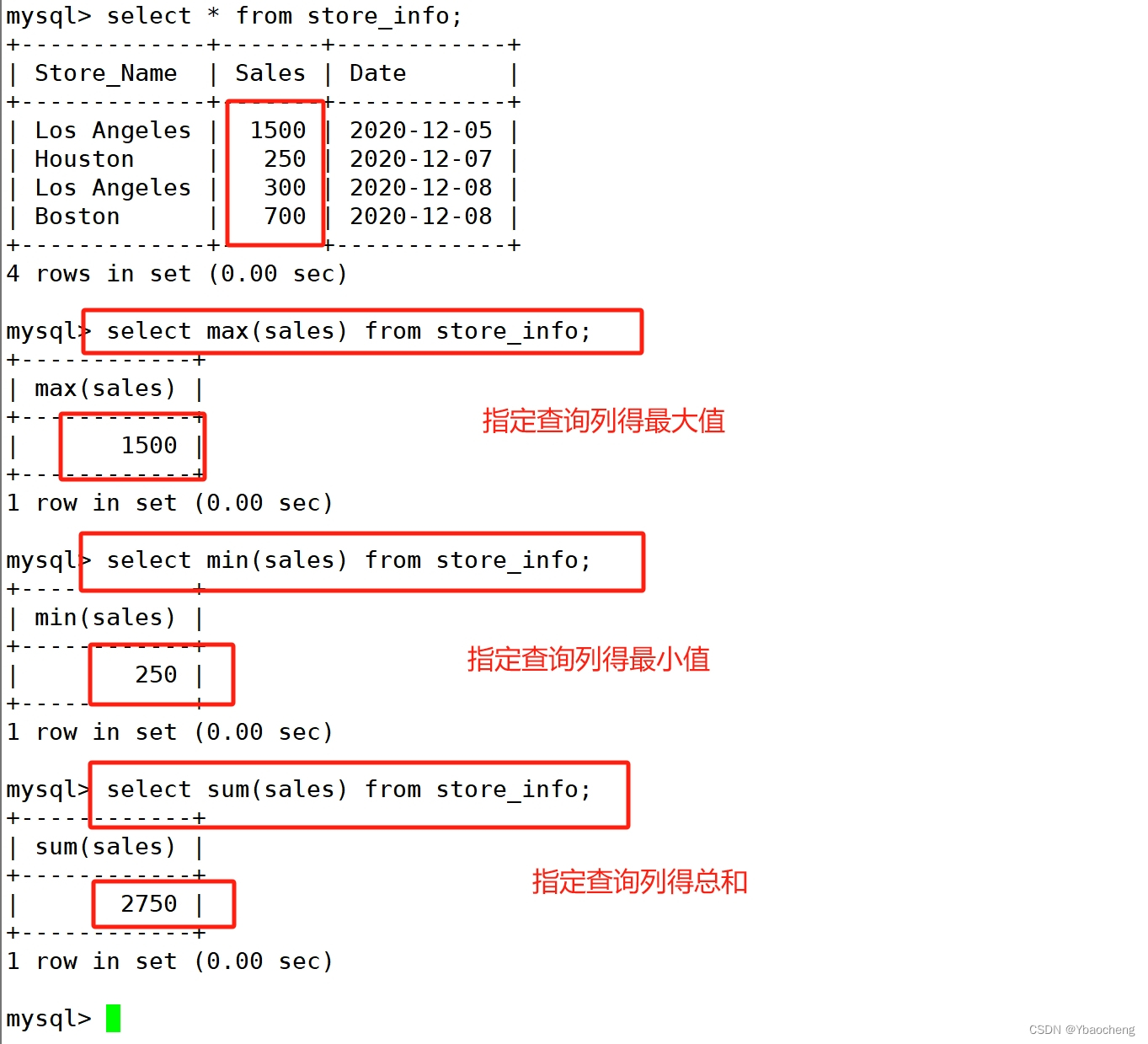
聚合函数
| 函数 | 含义 |
|---|---|
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
字符串函数
| 函数 | 含义 |
|---|---|
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
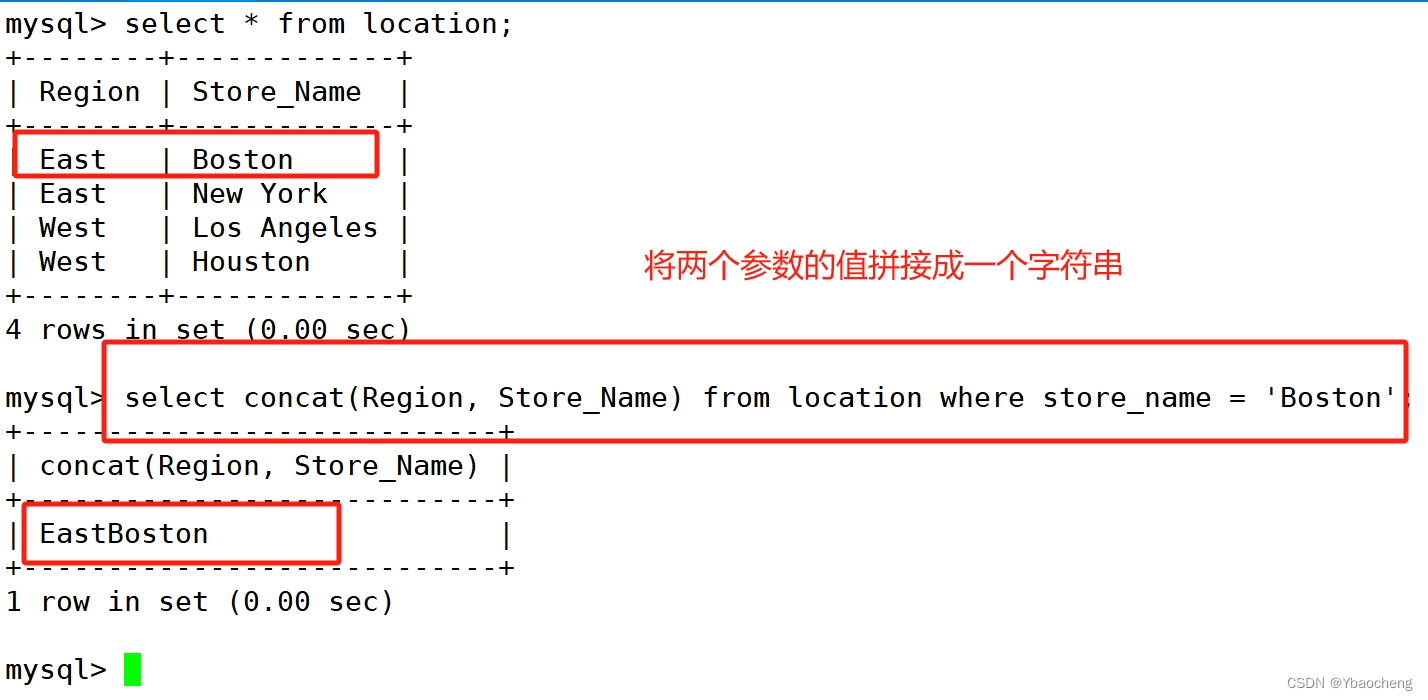
concat
select concat(Region, Store_Name) from location where store_name = 'Boston';
将两个参数值,拼接成一个字符串
或
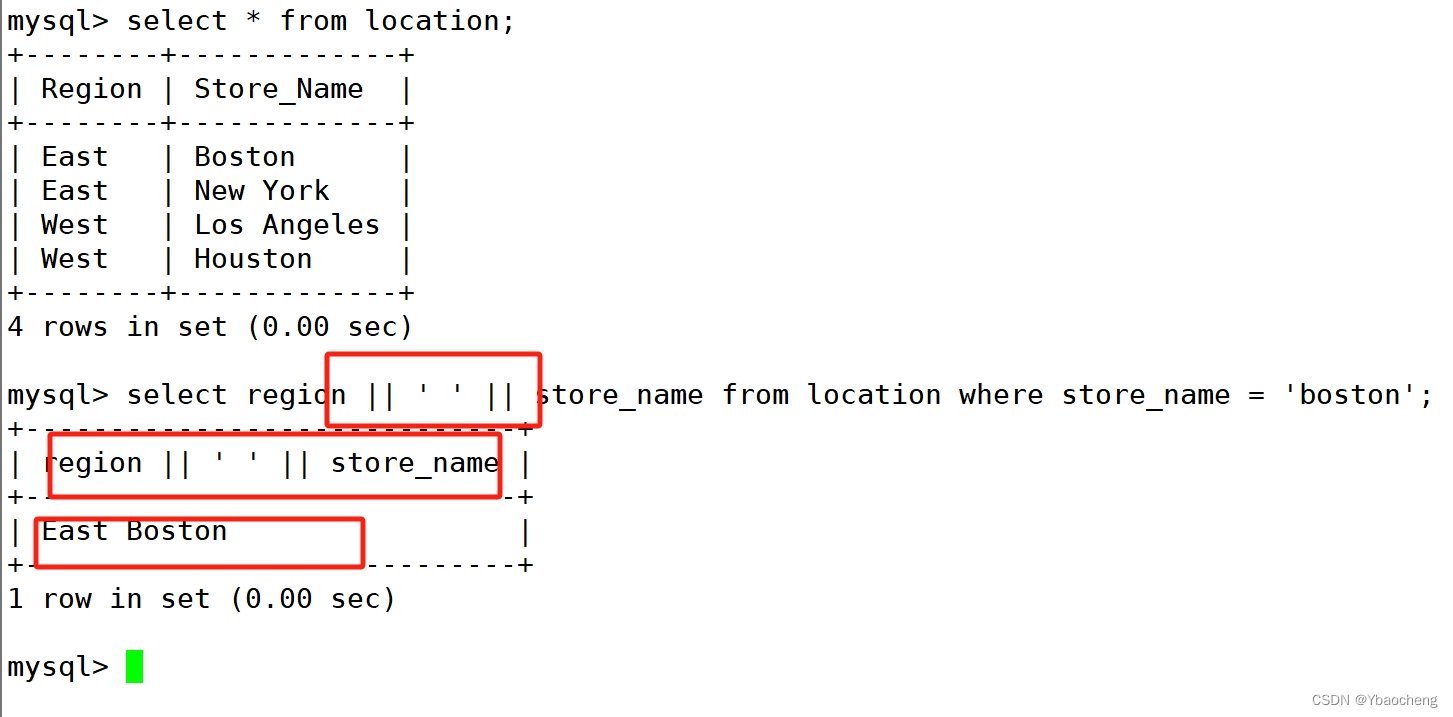
如sql_mode开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
select region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';
substr
select substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
获取字符串中第三个位置开始的字符串
select substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
获取字符串中第二个位置开始长度为4的字符串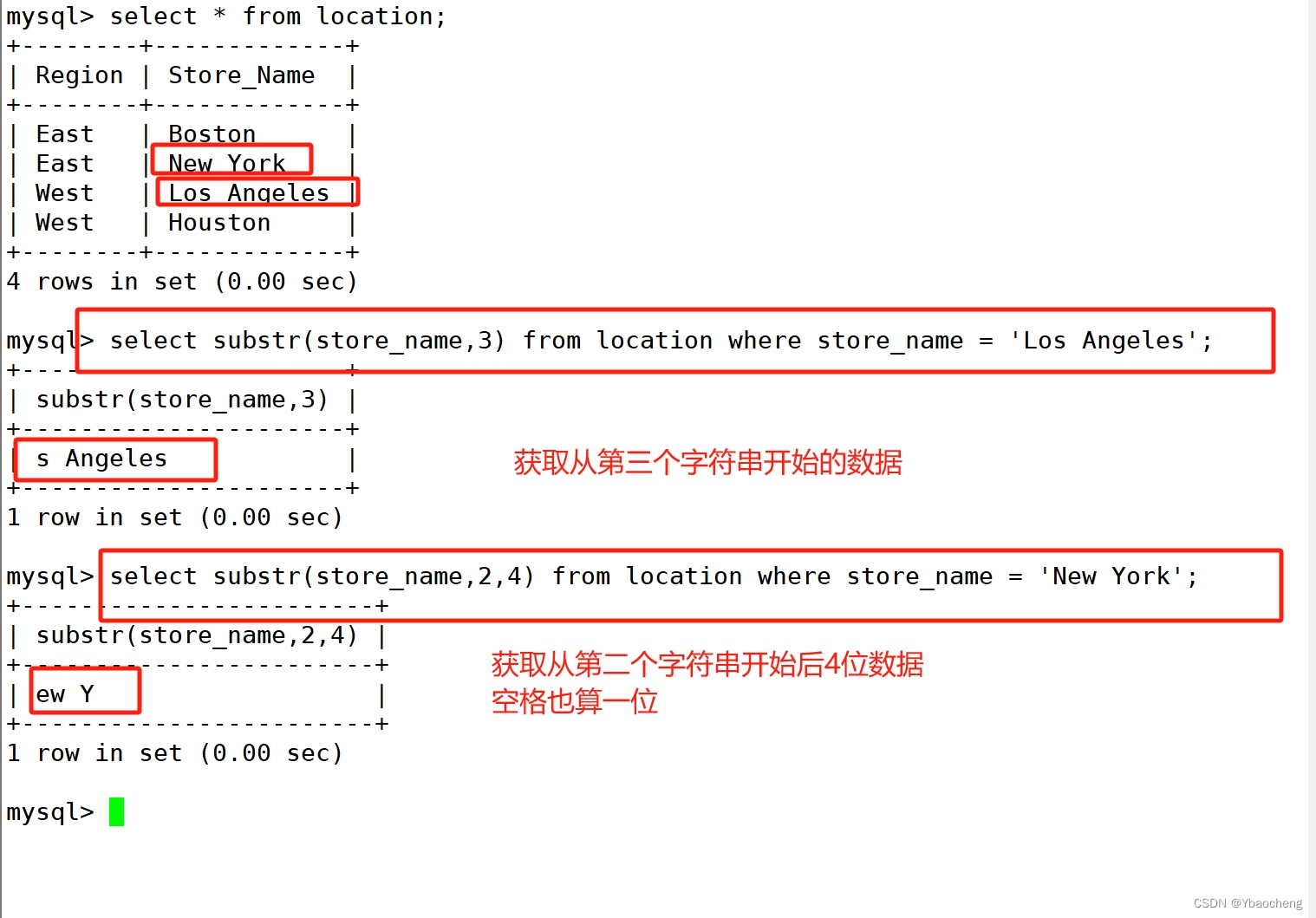
trim
select trim ([ [位置] [要移除的字符串] from ] 字符串);
[位置]:的值可以为 leading (起头), trailing (结尾), both (起头及结尾)。
[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
length
select region,length(store_name) from location;
返回字符串的长度
replace
select replace(region, 'ast', 'astern') from location;
将字段region中的ast替换成astern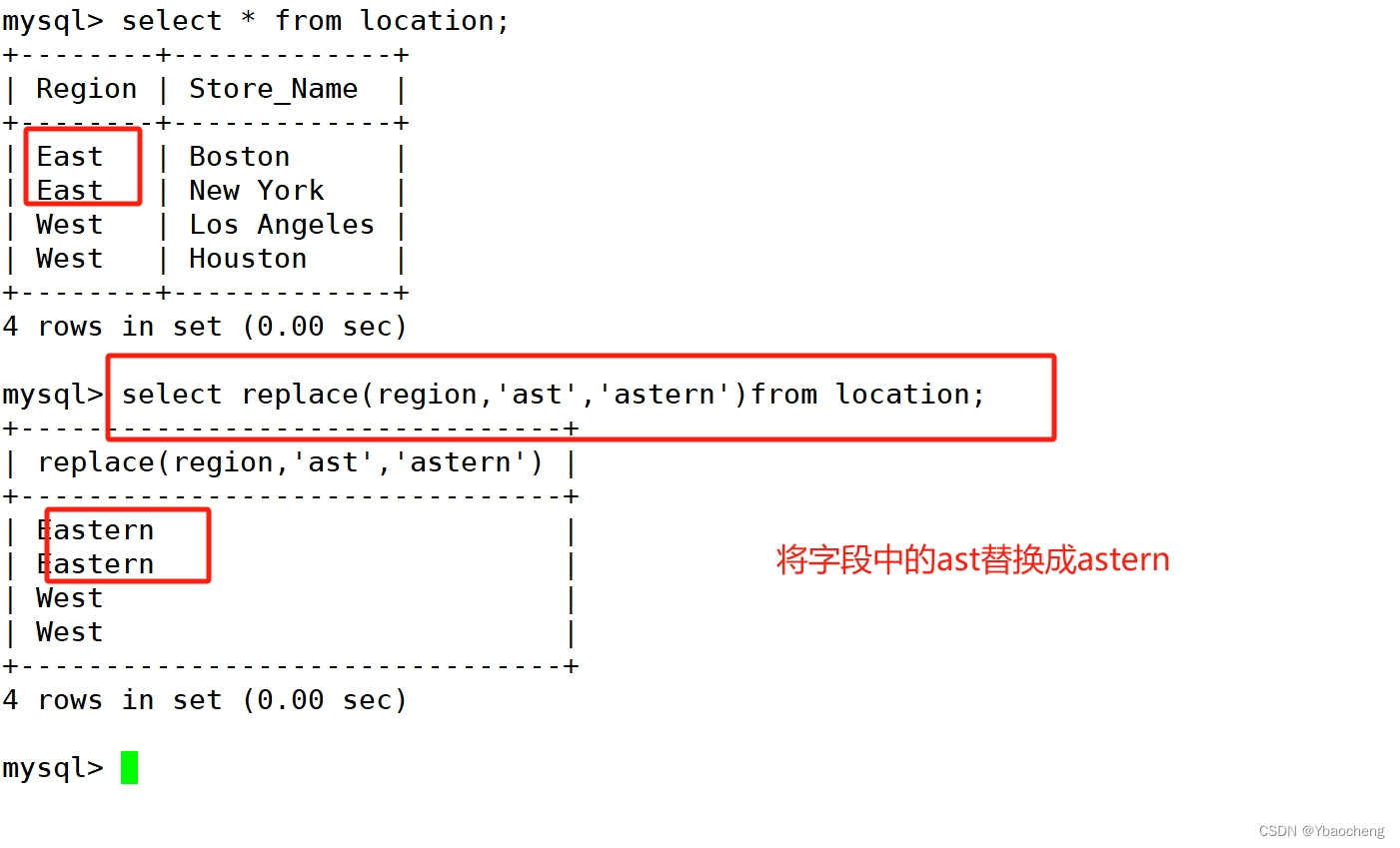
4.查询语句
group by
- 对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
- GROUP BY 有一个原则,凡是在 GROUP BY 后面出现的字段,必须在 SELECT 后面出现;
- 凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面
语法:
select "字段1", sum("字段2") from "表名" group by "字段1";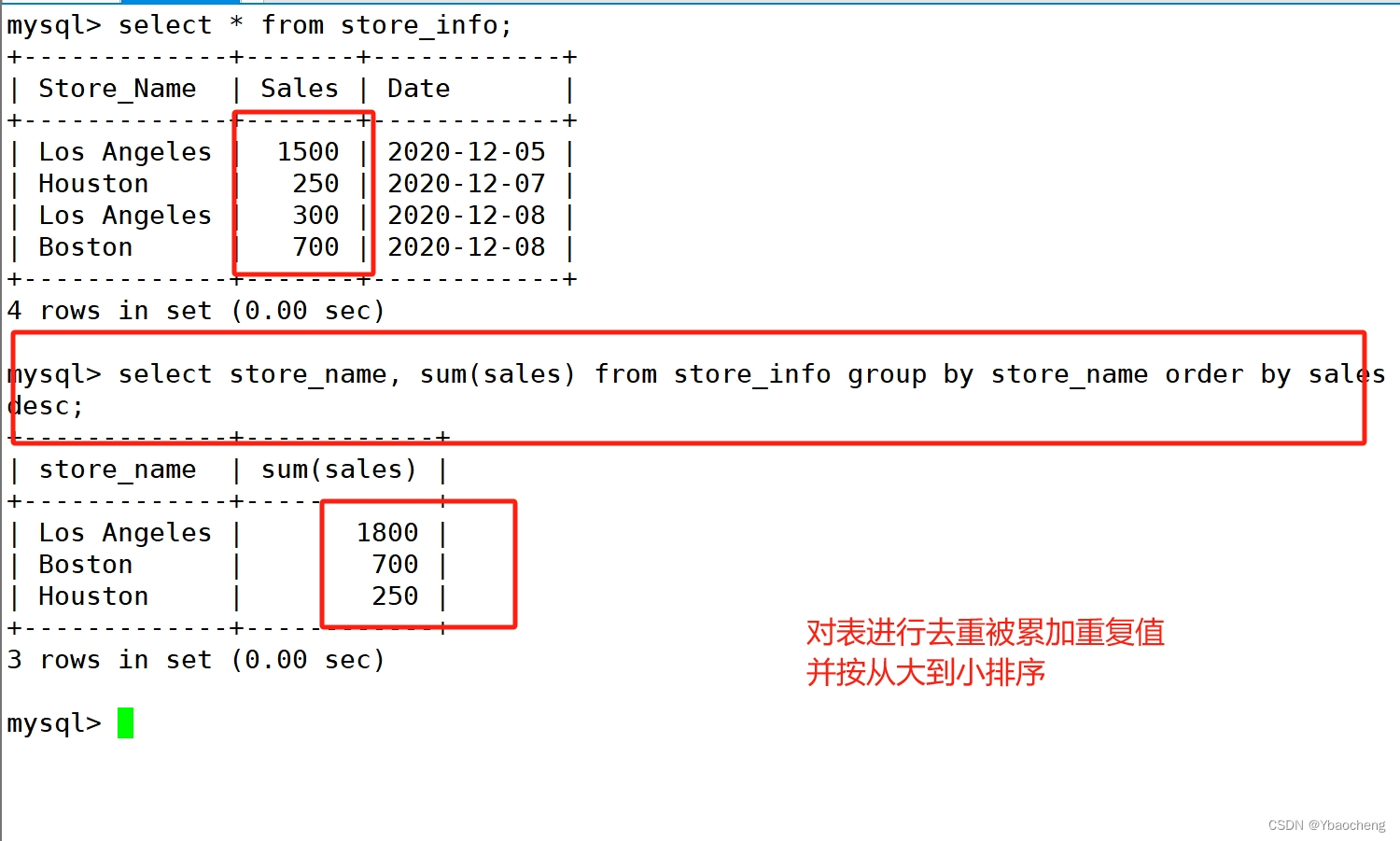
having
- 用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用
- HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
语法:
select "字段1", sum("字段2") from "表格名" group by "字段1" having (函数条件);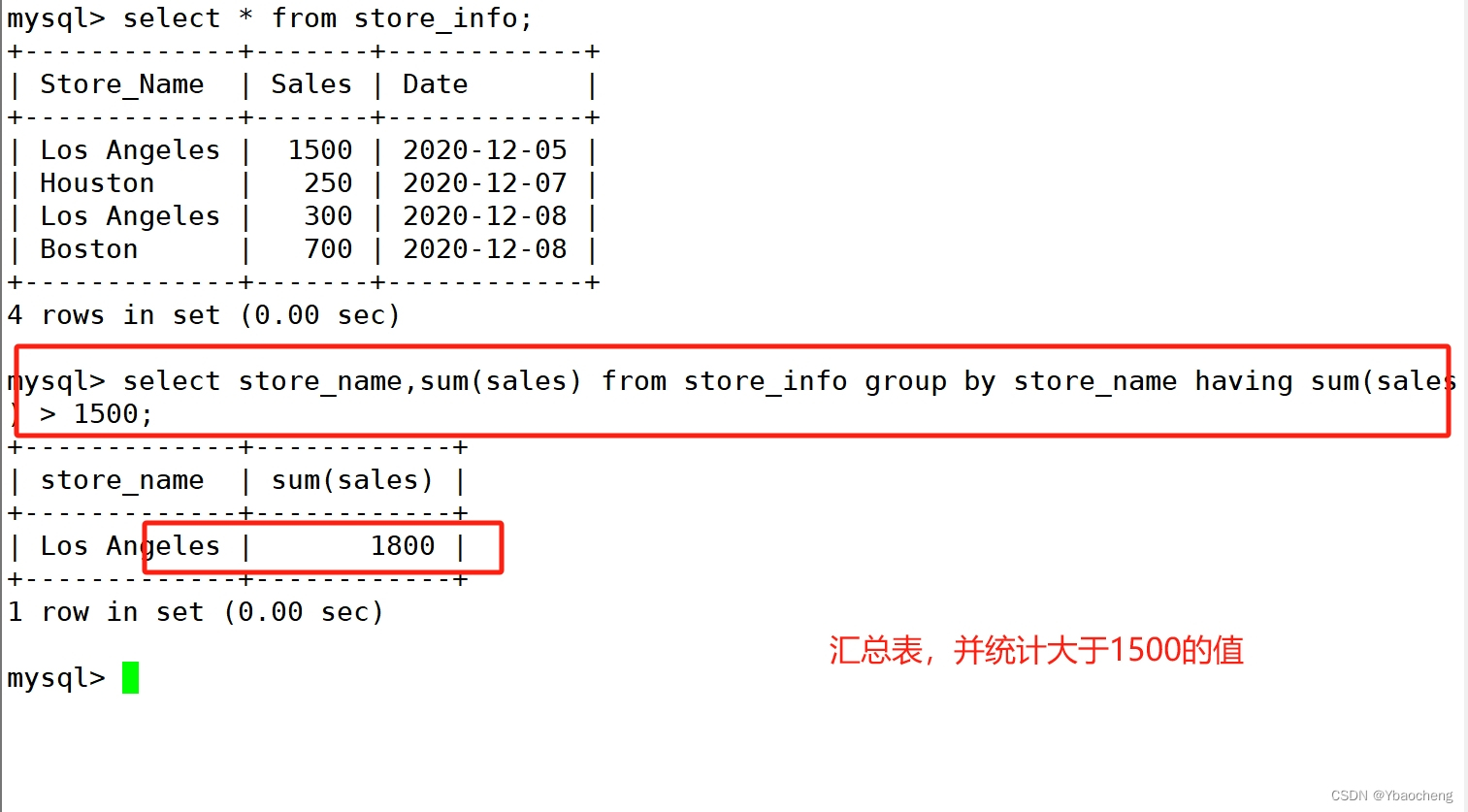
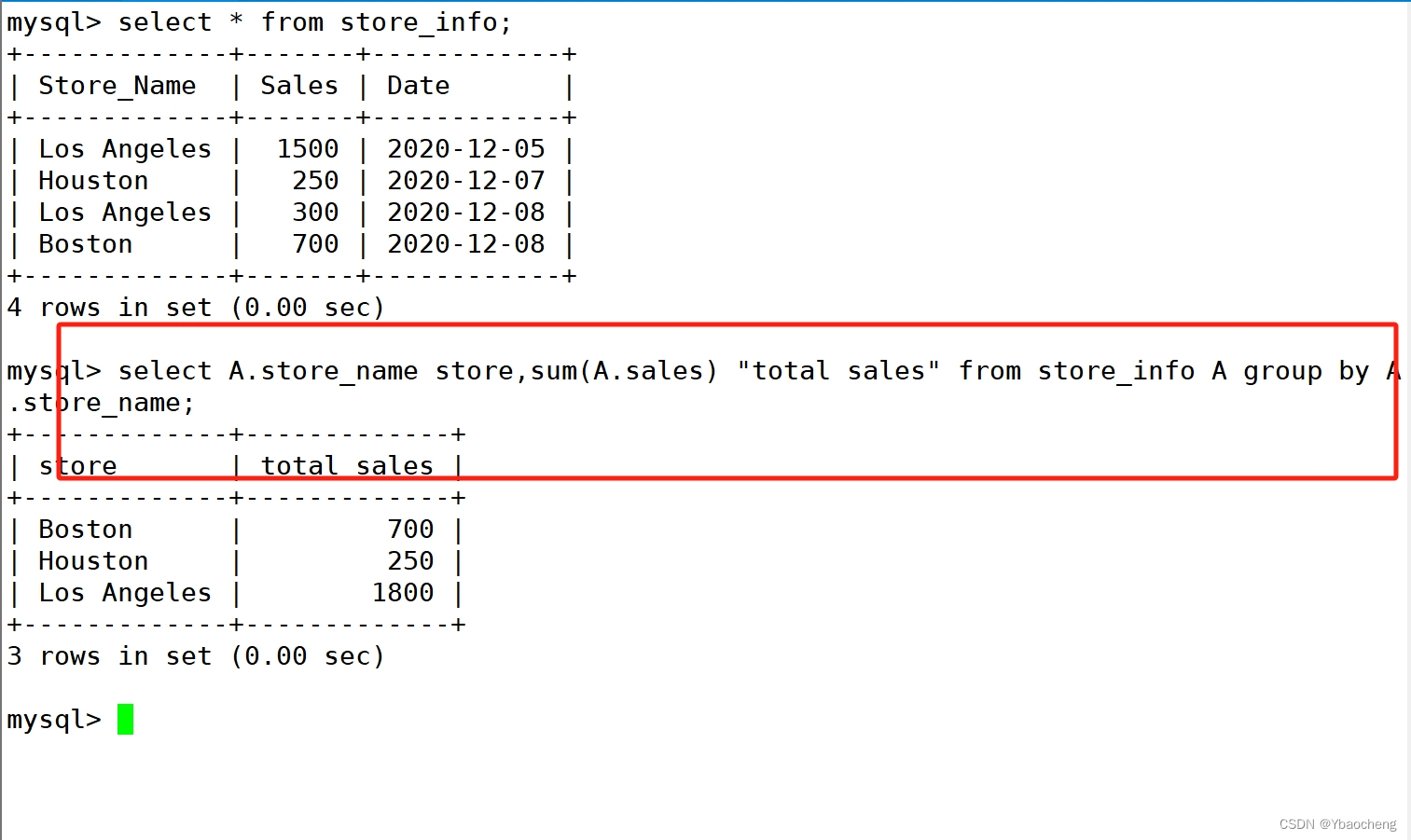
别名
语法:
select "表格別名"."字段1" [as] "字段別名" from "表格名" [as] "表格別名";
子查询
- 连接表格,在WHERE 子句或 HAVING 子句中插入另一个 SQL 语句
语法:
select "字段1" from "表格1" where "字段2" [比较运算符]
#可以是符号的运算符,例如 =、>、<、>=、<= ;也可以是文字的运算符,例如 LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'West');
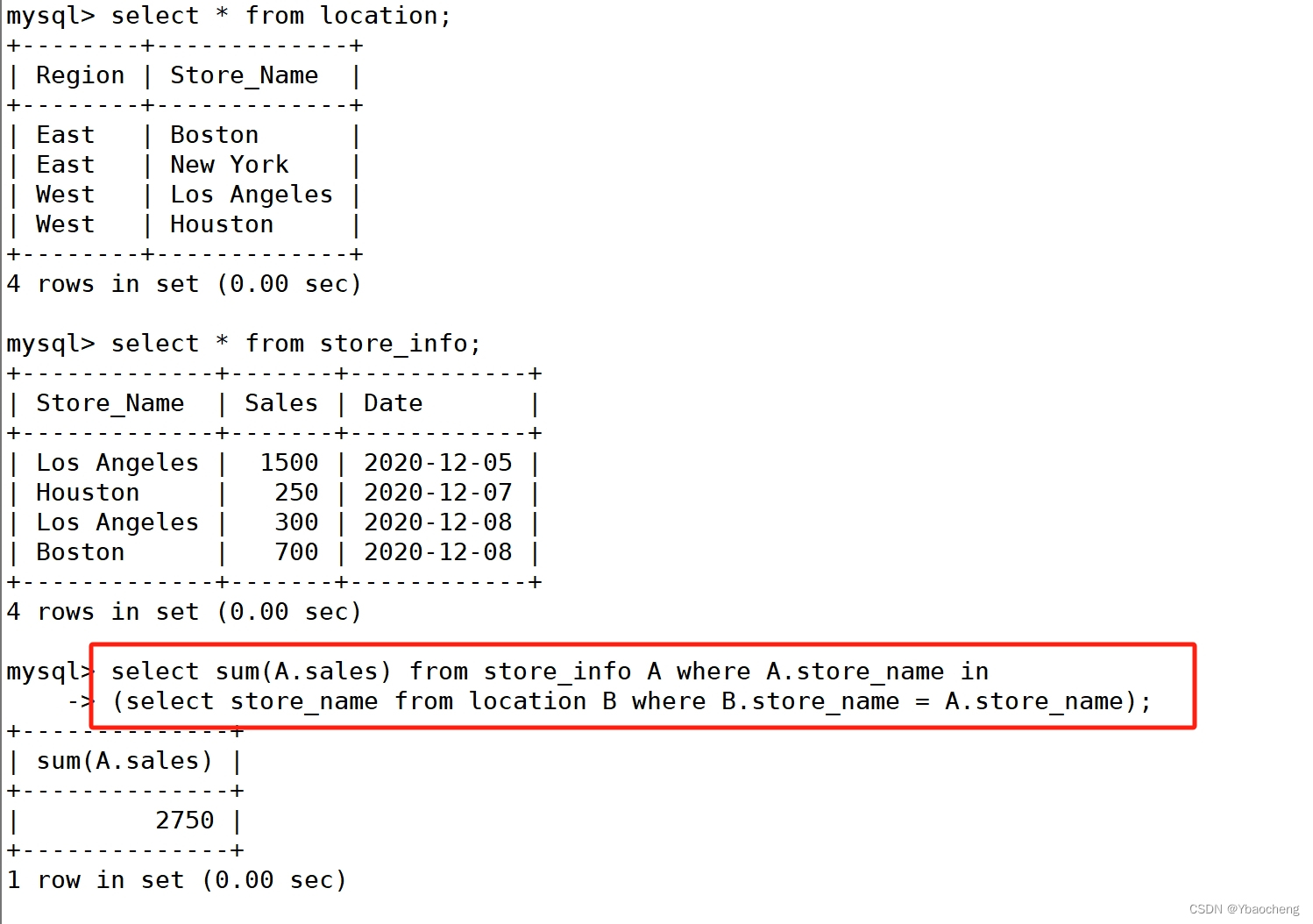
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);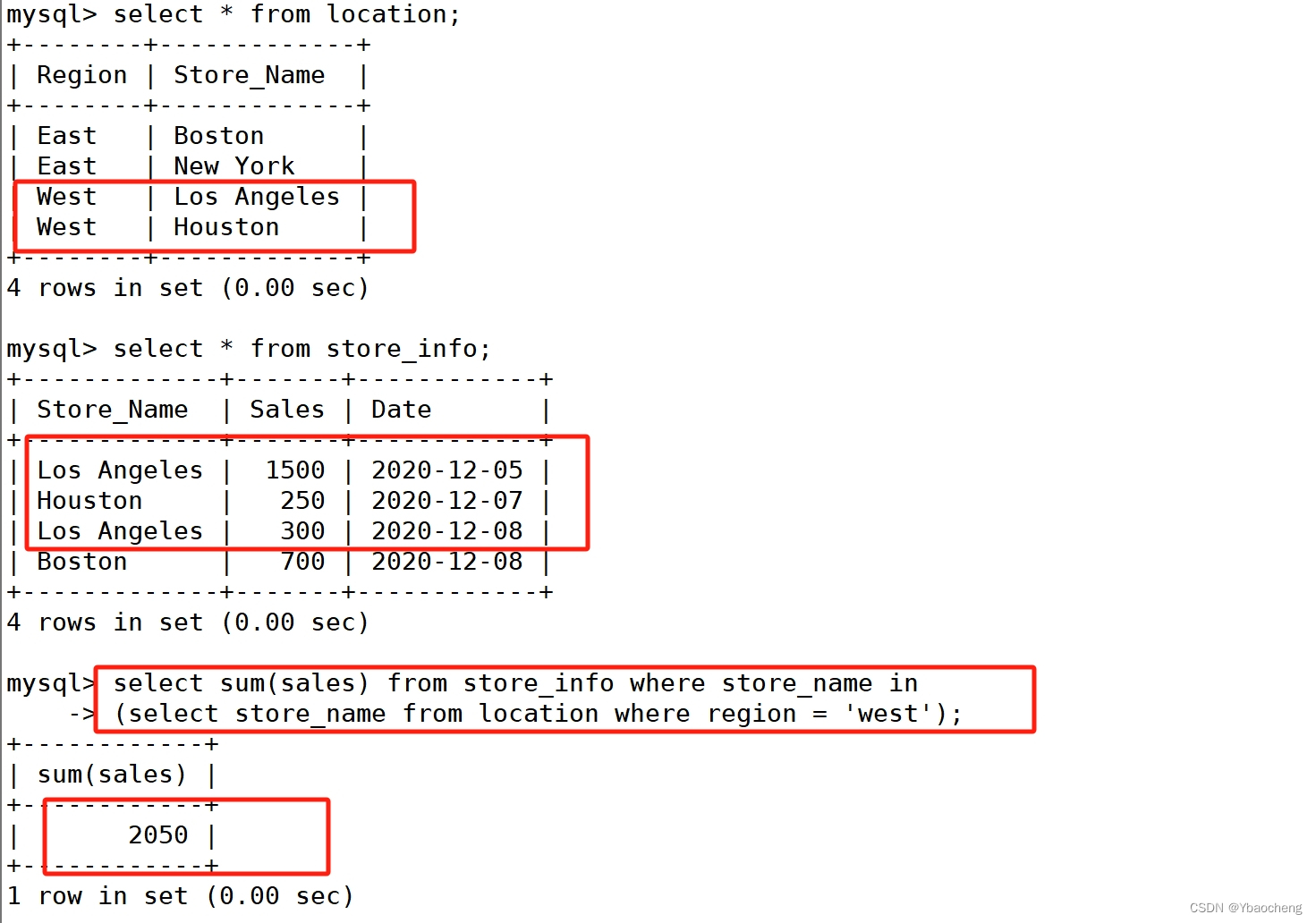
EXISTS
- 用来测试内查询有没有产生任何结果,类似布尔值是否为真
- 如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
语法:
select "字段1" from "表格1" where exists (select * from "表格2" where "条件");
5.连接查询
- inner join ? ?内连接,只返回两个表的字段相等的行记录
- left join ? ? 左连接,返回左表所有的行记录和右表字段相等的行记录,不相等的行返回null
- right join ? ?右连接,返回右表所有的行记录和左表字段相等的行记录,不相等的行返回null
- union ? ? ? ? 联集,将两个select查询语句的结果合并,并去重
- union all ? ? 联集,将两个select查询语句的结果合并,不去重
左连接
语法:
select A.字段 from 左表 as A left join 右表 as B on A.字段 = B.字段 where B.字段 is not null;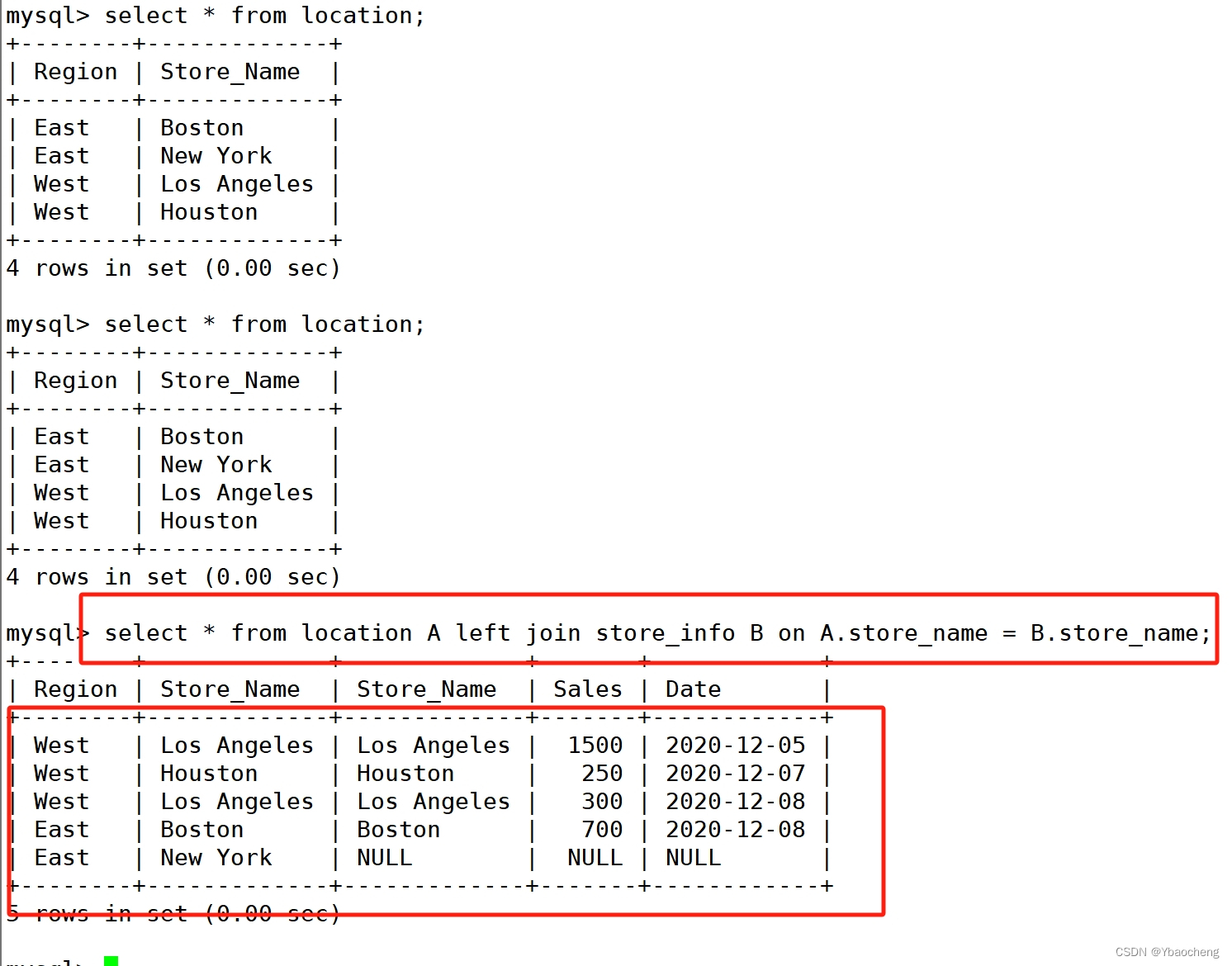
右连接
语法:
select B.字段 from 左表 as A right join 右表 as B on A.字段 = B.字段 where A.字段 is not null;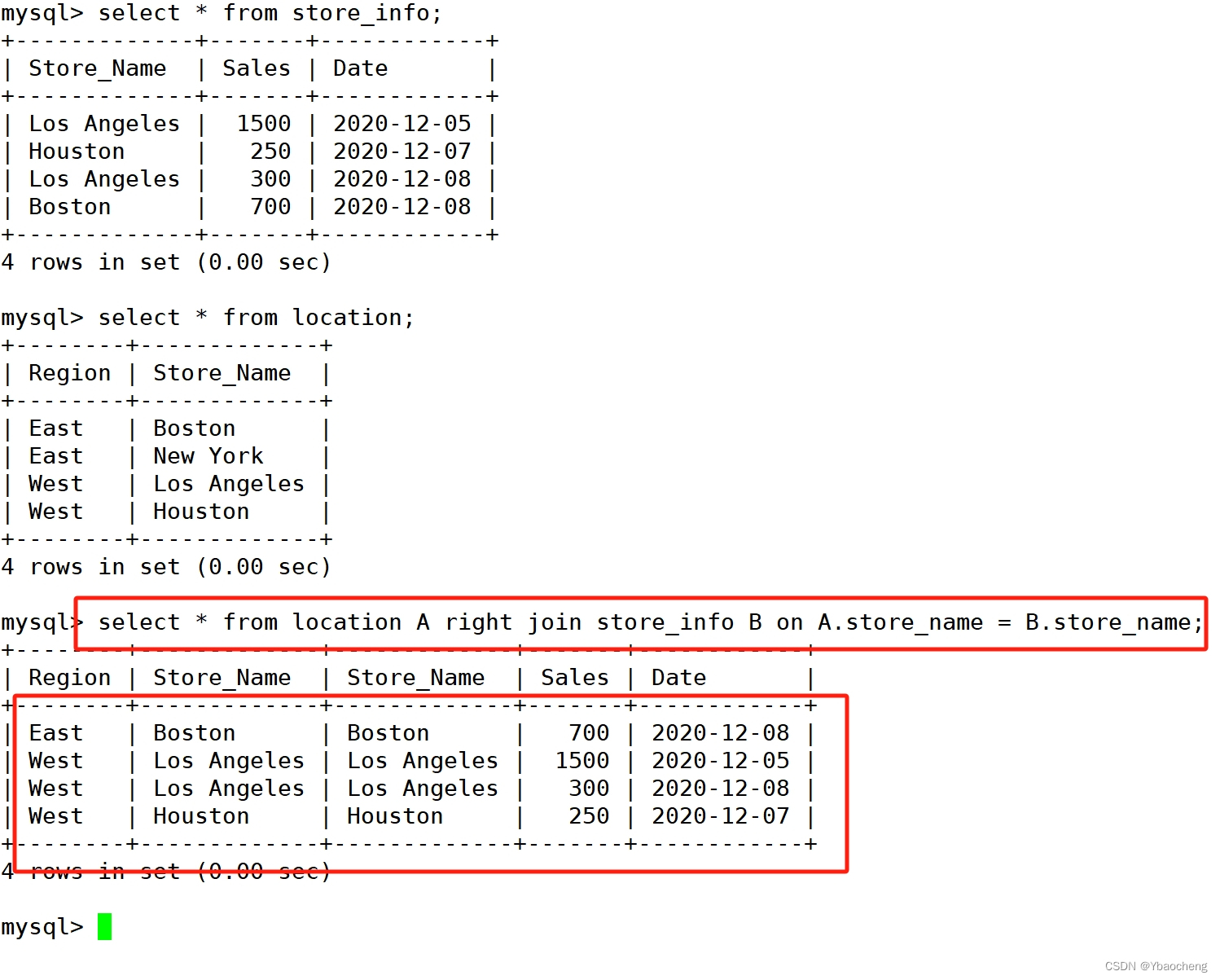
内连接
语法:
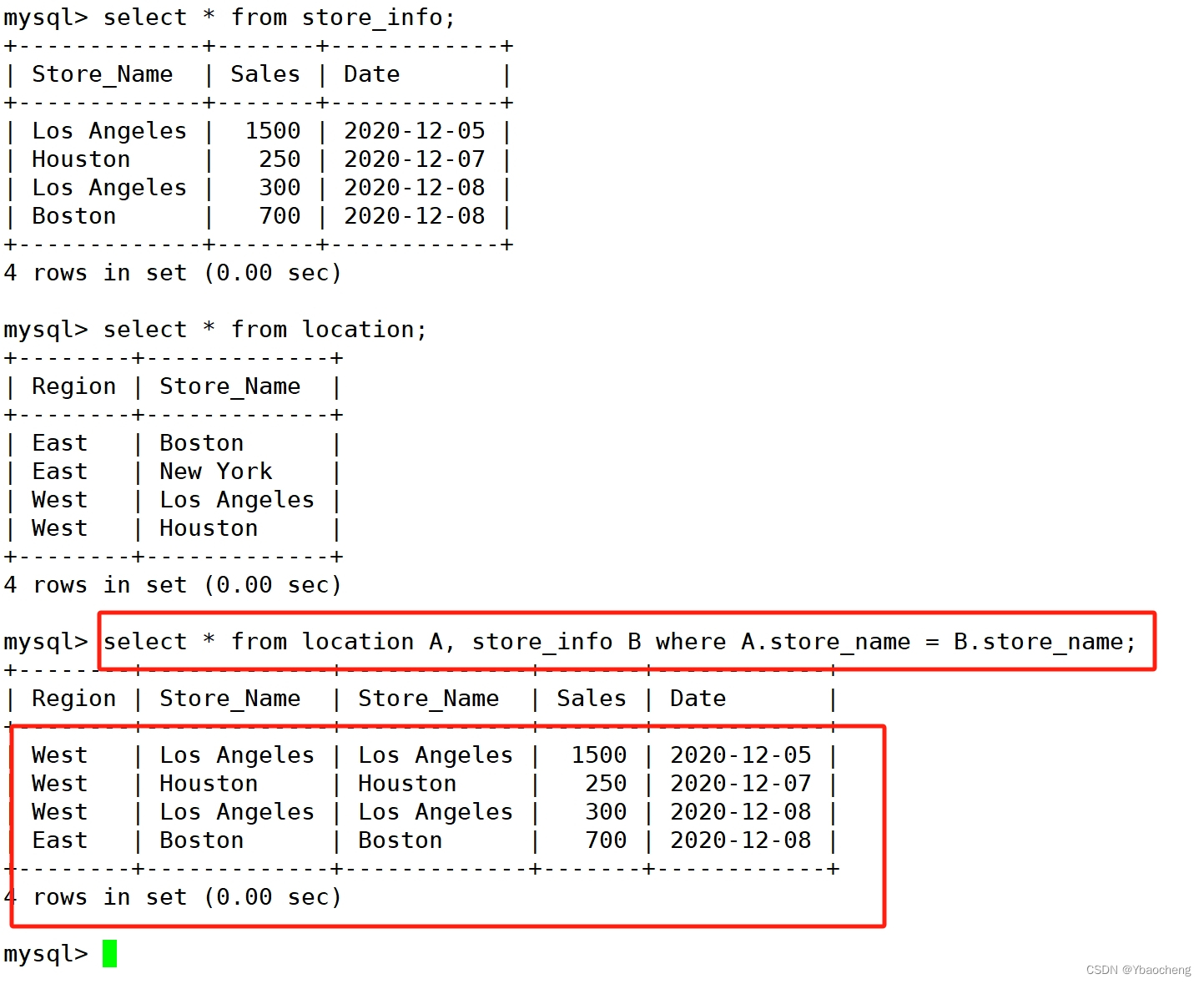
SELECT * FROM location A INNER JOIN Store_Info B on A.Store_Name = B.Store_Name ;
SELECT * FROM location A, Store_Info B WHERE A.Store_Name = B.Store_Name;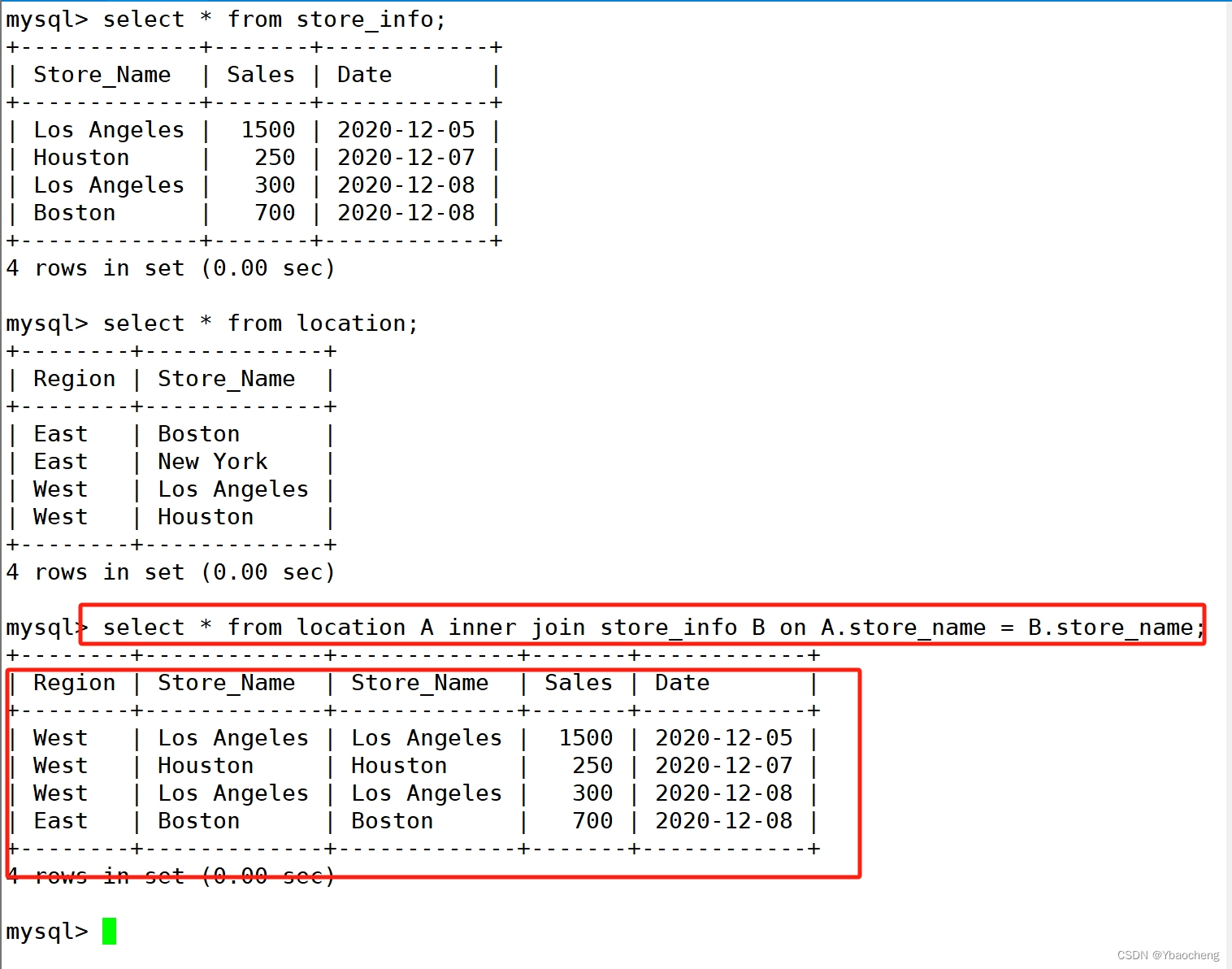
汇总统计
select A.region region, sum(B.sales) sales from location A, store_info B
where A.store_name = B.store_name group by region;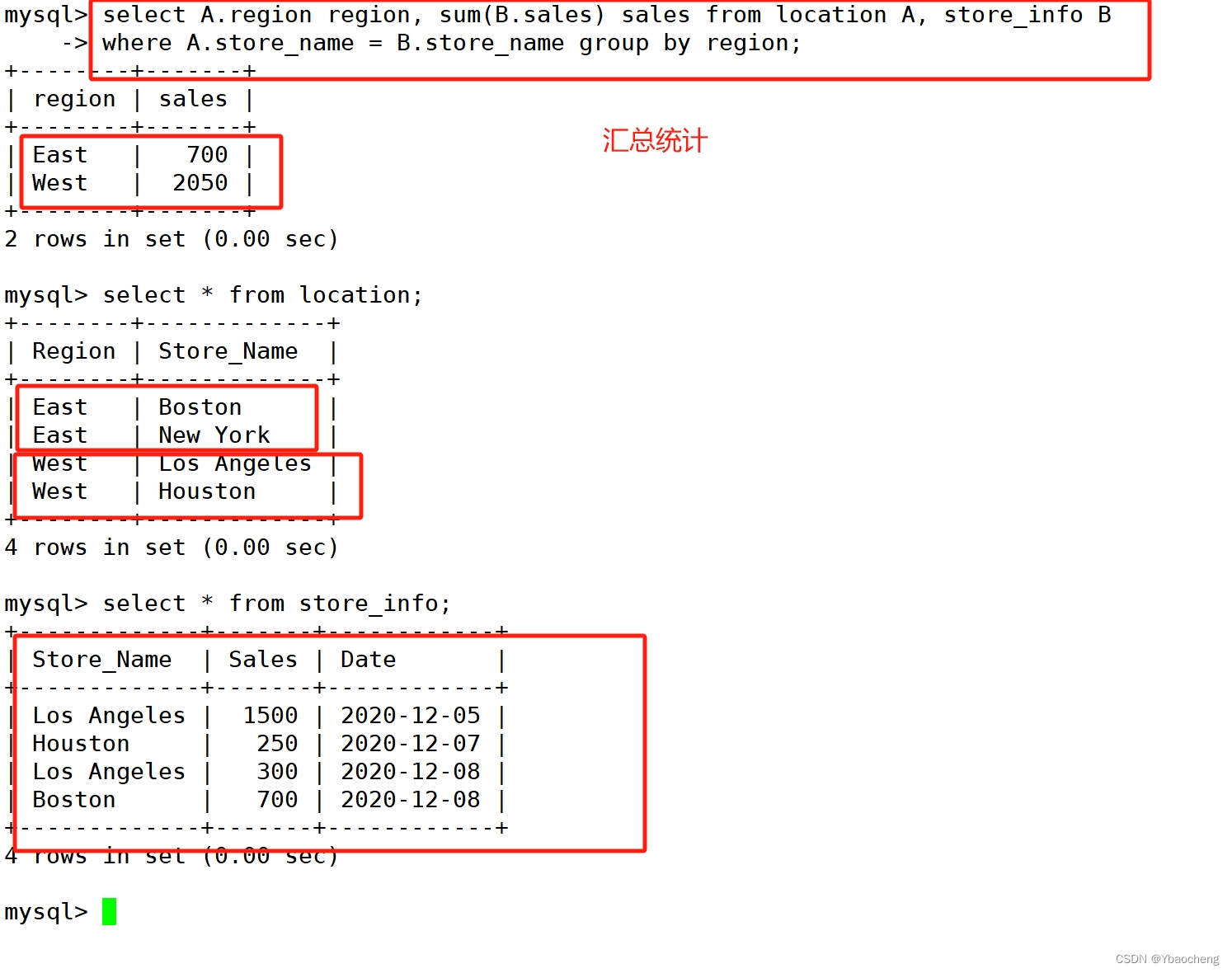
UNION 联集
UNION
- 生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:
[select 语句 1] union [select 语句 2];
UNION ALL
- 将生成结果的数据记录值都列出来,无论有无重复
语法:
[select 语句 1] union all [select 语句 2];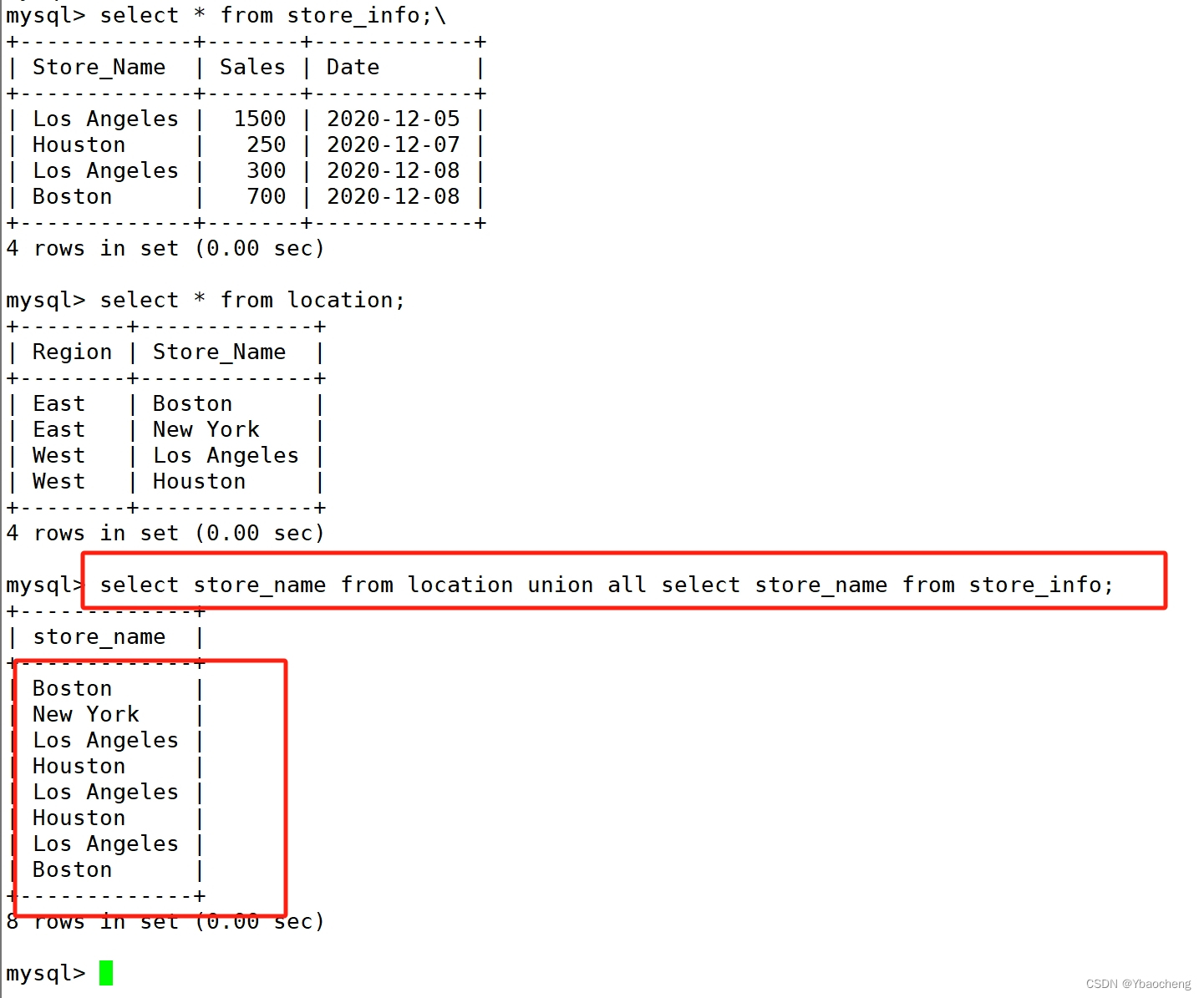
交集值
取两个SQL语句结果的交集
#求交集
#内连接
select A.字段 from 左表 as A inner join 右表 as B on A.字段 = B.字段;
select A.字段 from 左表 as A inner join 右表 as B using(同名字段);
select A.store_name from location A inner join store_info B on A.store_name = B.store_name;
或
select A.store_name from location A inner join store_info B using(store_name);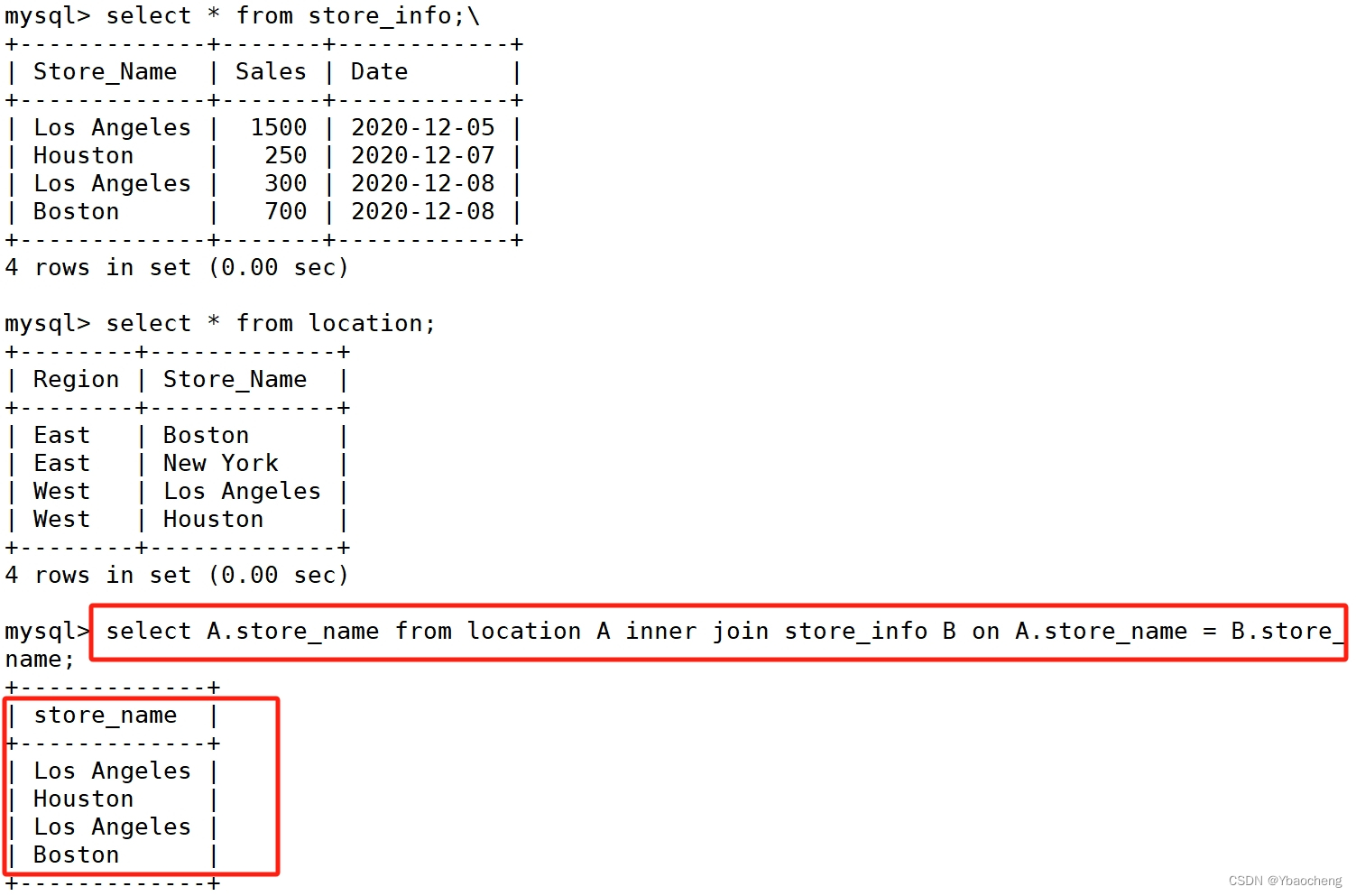
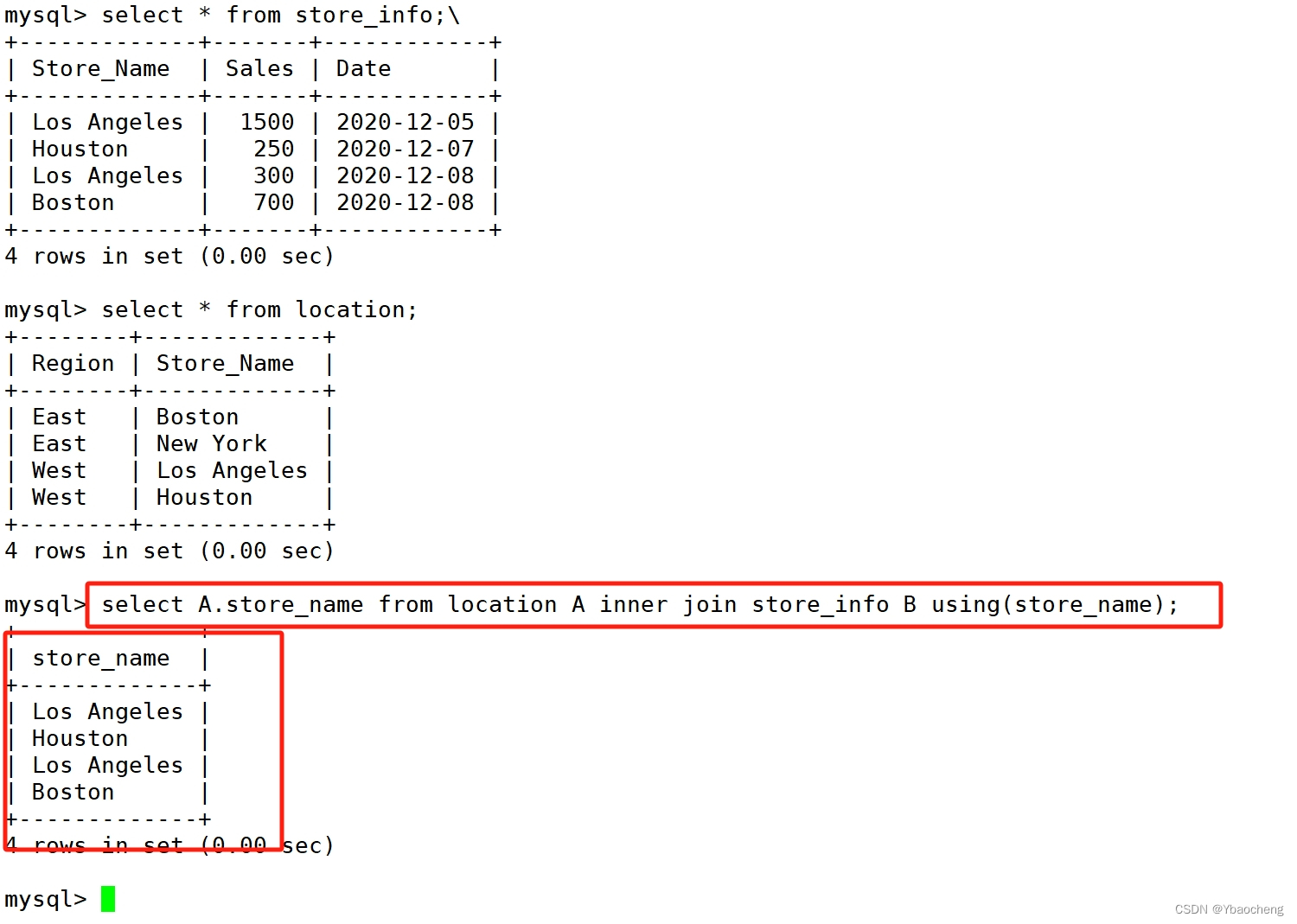
取两个SQL语句结果的交集,且没有重复
select distinct A.store_name from location A inner join store_info B using(store_name);
select distinct store_name from location where (store_name) in (select store_name from store_info);
select distinct A.store_name from location A left join store_info B using(store_name) where B.store_name is not null;
select A.store_name from(select B.store_name from location B inner join store_info C on B.store_name = C.store_name) A group by A.store_name;
select A.store_name from (select distinct store_name from location union all select distinct store_name from store_info) A group by A.store_name;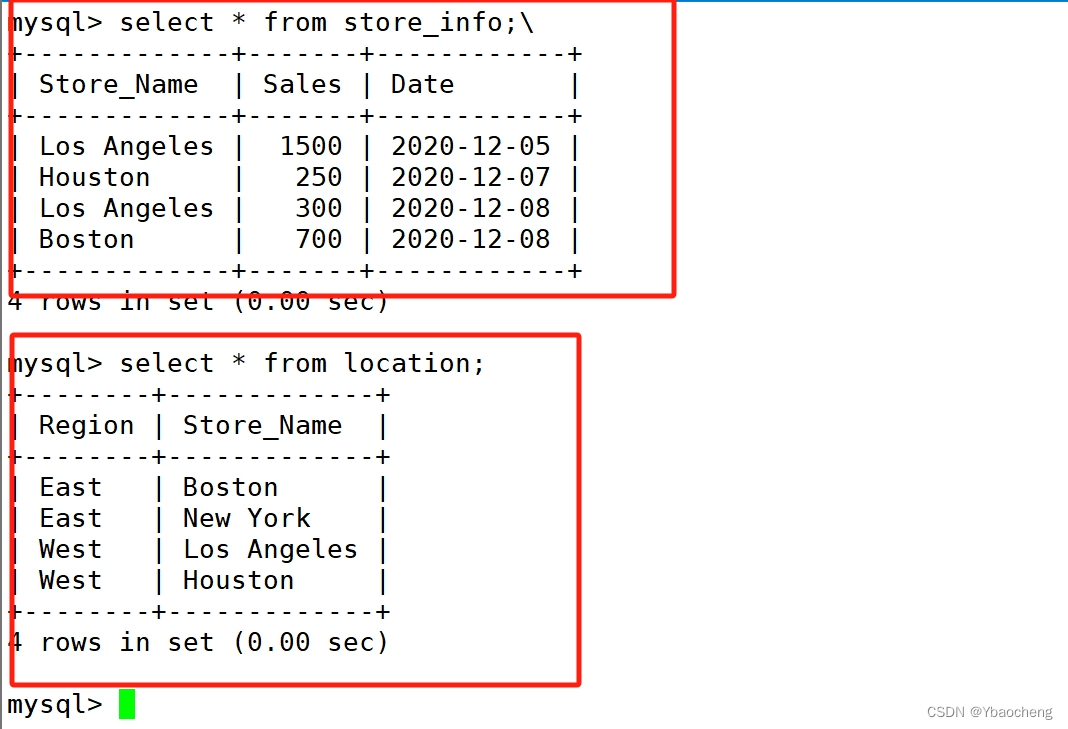
无交集值
- 显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
求左表无交集
select A.字段 from 左表 as A left join 右表 as B on A.字段 = B.字段 where B.字段 is null;
select A.字段 from 左表 A where A.字段 not in (select B.字段 from 右表 B);
求右表无交集
select B.字段 from 左表 as A right join 右表 as B on A.字段 = B.字段 where A.字段 is null;
select B.字段 from 右表 B where B.字段 in (select A.字段 from 左表 A);
求两个表无交集
select A.字段 from 左表 as A left join 右表 as B on A.字段 = B.字段 where B.字段 is null union select B.字段 from 左表 as A right join 右表 as B on A.字段 = B.字段 where A.字段 is null;
select A.字段 from (select distinct 字段 from 左表 union all select distinct 字段 from 右表) A group by A.字段 having count(A.字段) = 1;
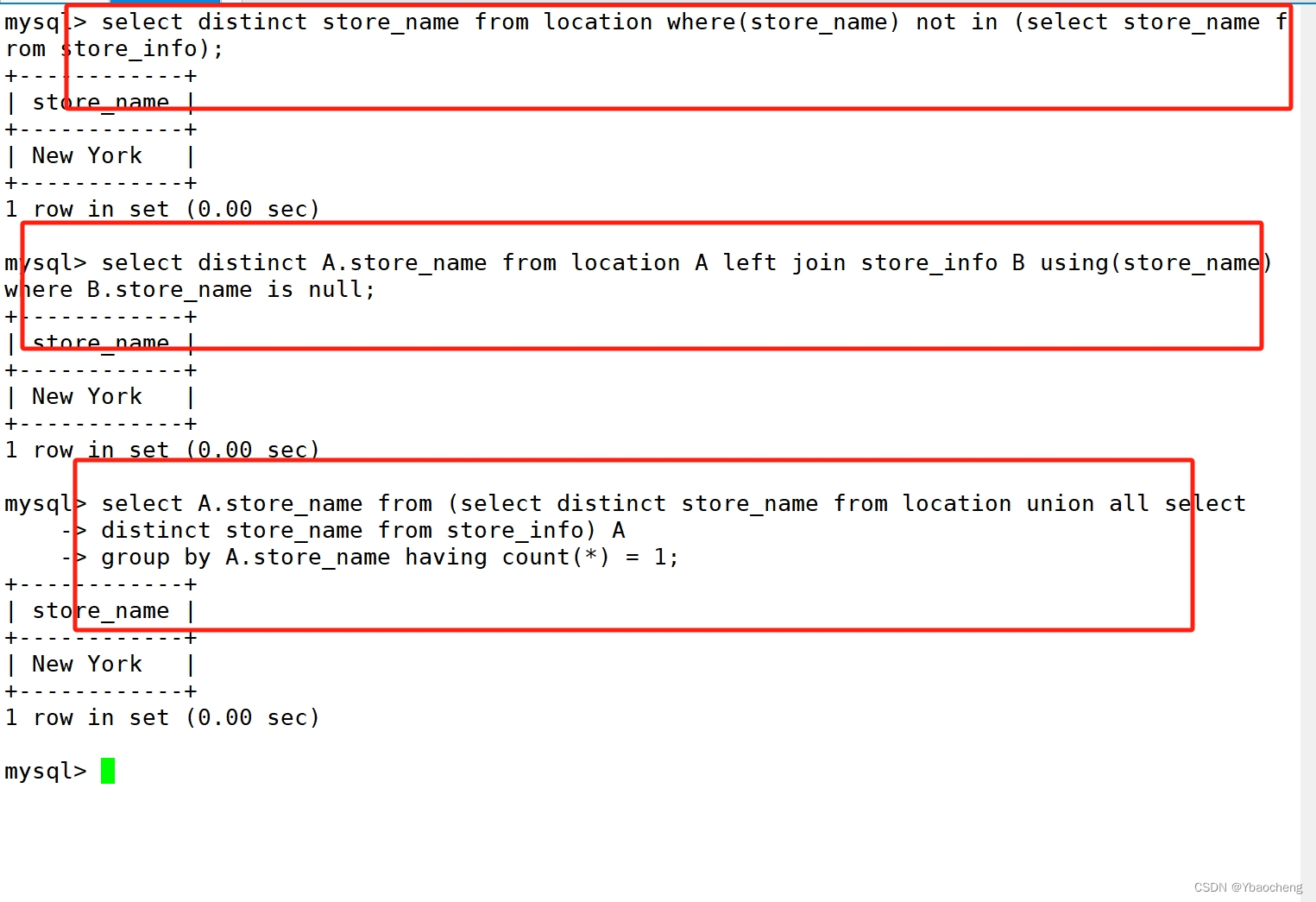
select distinct store_name from location where(store_name) not in (select store_name from store_info);
select distinct A.store_name from location A left join store_info B using(store_name) where B.store_name is null;
select A.store_name from (select distinct store_name from location union all select distinct store_name from store_info) A group by A.store_name having count(*) = 1;
6.视图
创建视图
create view 视图表名 as select distinct 字段 from 左表 union all select distinct 字段 from 右表;
查看视图
select 字段 from 视图表名 group by 字段 having count(字段) = 1;视图表的数据是否能修改
- 视图表保存的是select查询语句的定义
- 如果select语句查询的字段是没有被处理过的源表字段,则可以通过视图表修改源表数据。
- 如果select语句查询的字段被 group by 或 函数 等处理过的字段,则不可以直接修改视图表的数据
文章来源:https://blog.csdn.net/Ybaocheng/article/details/135252907
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【教程】Ipa Guard为iOS应用提供免费加密混淆方案
- 精选顶级期刊中的三幅可复现图表
- 用js的日期函数,写一个简单的时钟
- mysql之数据类型、建表以及约束
- 逼格满满,推荐一个高效测试用例工具:XMind2TestCase !
- React受控组件和非受控组件的理解?应用场景?
- 【新功能上线】mooncakes.io:新一代MoonBit包管理平台来啦!!
- 【基础篇】二、字节码文件的组成 && Arthas + jclasslib +javap
- Node安装极速版
- 国际站店铺装修外贸平台alibaba鼠标经过渐变的效果功能代码代码生成器店铺装修旺铺旺铺装修生成器阿里巴巴国际站店铺怎么装修首页进入装修后台自定义内容模块