2023.1.23 关于 Redis 哨兵模式详解
目录
引言
人工恢复主节点故障
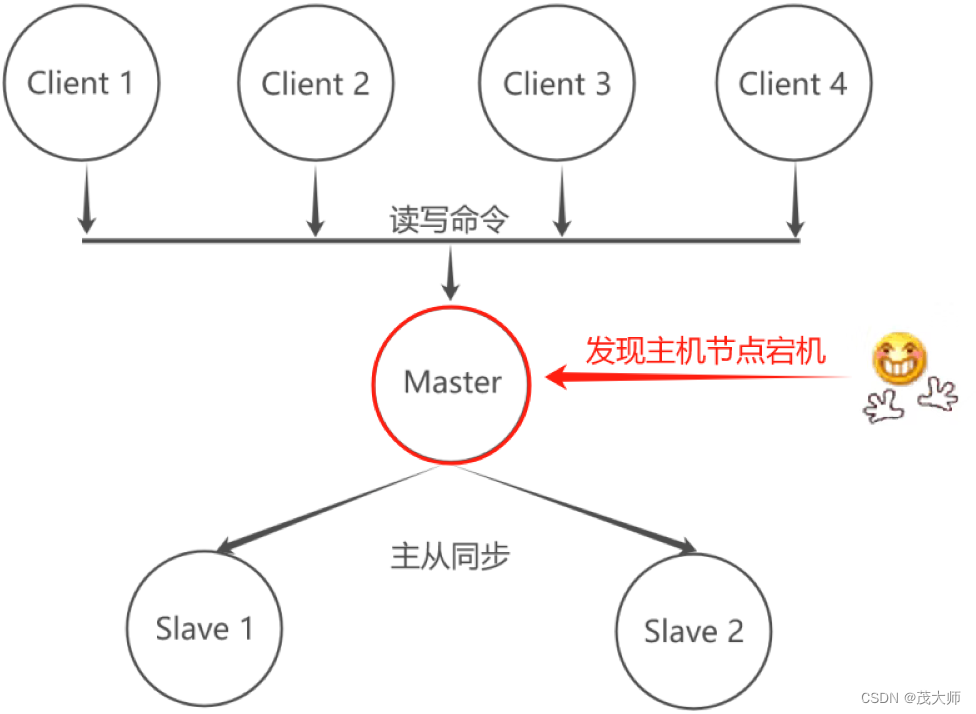
1、正常情况
2、主节点宕机
3、程序员主动恢复
- 先看看该主节点还能不能抢救
- 如果不好定位主节点是啥原因挂的,或知道原因,但是短时间难以解决,此时便需要挑一个从节点,将其设置为新的主节点
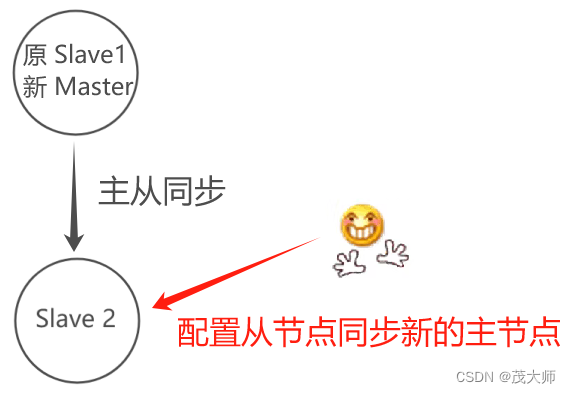
a)将选中的从节点,通过 slaveof no one 命令解除之前的主从关系
b)其他的从节点,通过修改 slaveof 命令,将?ip 和 port 改为新上任的主节点
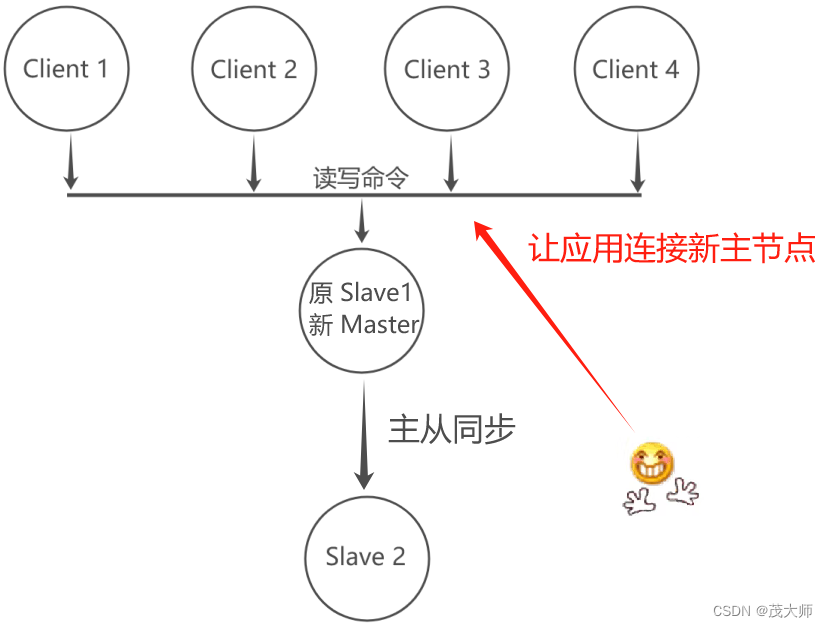
c)告知客户端(修改客户端配置)让客户端能够连接新的主节点,用来完成修改数据的操作
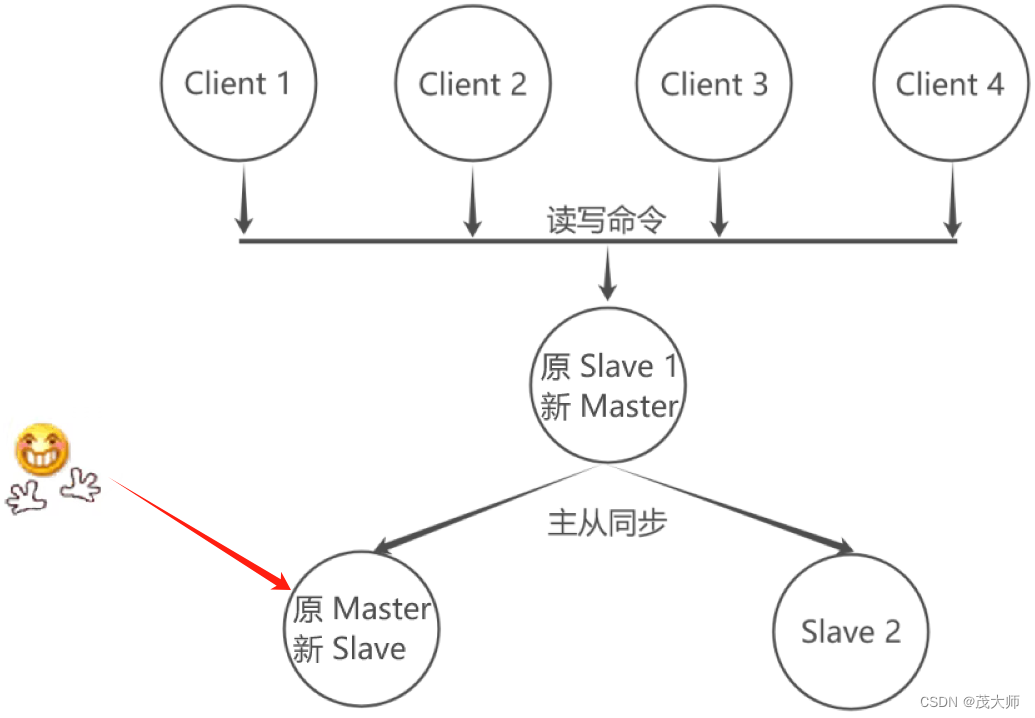
d)原先挂掉的主节点修好后,将其作为一个新的从节点,挂到这组机器中
小总结:
- Redis 主从复制模式下,主节点故障后需要进行的人工工作是比较繁琐的
- 如果这个操作过程如果出错,可能会导致问题愈发严重
- 通过人工干预的做法,就算程序员第一时间看到了报警信息,第一时间处理,恢复的过程也至少需要 半小时 以上
- 在这期间,整个 Redis 一直不能进行写操作!
注意:
- 实际开发过程中,对于服务器后端开发,监控程序是非常重要的!
原因:
- 服务器需具有高可用性,因为其 7*24 小时不间断运行
- 服务器长期运行总会有一些 意外,同时我们也难以预料具体啥时候会出现意外
- 总不可能全靠人工来不间断盯着服务器运行吧!
解决方案:
- 写一个程序,用监控程序来盯着服务器的运行状态
- 监控程序用于发现 服务器的运行是否出现状态异常
- 监控程序往往还需搭配 报警程序 一起使用
- 给程序员报警,通过短信/电话/邮件/微信/钉钉等,通知程序员该服务器程序出现异常
- 本文主要详解 Redis?部署方式中的主从 + 哨兵模式


主从 + 哨兵模式
- 如上图所示,此处提供了多个单独的 redis sentinal 进程
- 这三个哨兵进程会监控现有的 Redis 主节点?和 从节点
注意点一:
- 这些进程之间会建立 TCP 长连接,通过长连接定期发送心跳包
- 借助上述的监控机制,便可以及时发现某个主机是否挂了
- 如果是从节点挂了 其实没多大关系
- 如果是主节点挂了,哨兵就要发挥作用了!
具体流程:
- 当一个哨兵节点发现主节点挂了时,还不够,还需要多个哨兵节点来共同认定这件事(主要是为了防止误判)
- 如果主节点确实挂了,便会在这些哨兵节点中推举出一个 leader,由这个 leader 负责从现有的从节点中挑选一个作为新的主节点
- 挑选出新的主节点后,哨兵节点便会自动控制被选中的节点,执行 slaveof no one 命令,并且控制其他从节点修改 slaveof 到新的主节点上
- 最后哨兵节点会自动通知客户端程序,告知新的主节点是谁,以便后续客户端再进行写操作时,可直接针对新的主节点进行操作
Redis 哨兵核心功能:
- 监控
- 自动的故障转移
- 通知
注意:
- 虽然可以仅有一个 Redis 哨兵节点,但是相应也会存在一定问题
1、如果哨兵节点只有一个,它自身也容易出现问题
- 万一这个哨兵节点挂了,后续 Redis 节点也挂了,此时便无法进行自动恢复了
2、出现误判的概率也比较高
- 比如 网络传输时容易出现抖动或者延迟丢包等
基本的原则:
- 在分布式系统中,应该避免使用 单点
- 哨兵节点,最好搞奇数个,最少也应该是 3 个(选举机制)

Docker 模拟部署哨兵模式
- 此处我们模拟上图进行部署
- 按理说,这 6个节点需在?6个不同的服务器主机上
- 但是此时只能在一个 云服务器上完成此处的部署操作
注意点一:
- 实际工作中,把上述节点放到一个服务器上是毫无意义的!
- 当前这么做只是条件有限,我仅买了一个云服务器!
注意点二:
- 由于这些节点还挺多,相互之间容易打架,比如依赖的端口号、配置文件、数据文件等
- 如果直接部署的话,便需要小心翼翼地避开这些冲突
- 十分繁琐的同时也会和在不同主机上部署存在较大差异
解决方案:
- 使用 docker 便可以有效的解决上述的问题
- docker 中有一个关键概念 ——> 容器
- 每个容器可看做一个轻量级的虚拟机
?1、安装 docker 和 docker-compose(点击下方链接即可跳转安装)
CentOS7 安装 docker 和 docker-compose
2、停止之前的 Redis 服务器
3、使用 docker 获取?Redis 镜像
- 此处我们通过下方命令,直接从 docker hub 上拉取?redis 5.0.9 的镜像
docker pull redis:5.0.9
- 使用 docker images 命令查看是否成功拉取镜像
注意点一:
- docker 中的 镜像 和 容器
- 类似于 可执行程序 和 进程 的关系
注意点二:
- 镜像可以自己构建,也可以直接拿别人已经构建好的
- docker hub 中包含了很多其他大佬们构建好的镜像,其中便有?Redis 官方提供的镜像
注意点三:
- 拉取到的镜像里面包含一个精简的 Linux 操作系统,并且上面会安装 Redis
- 只要直接基于这个镜像创建一个 容器 跑起来,此时 Redis 服务器便搭建好了!
4、基于 docker 来搭建 redis 哨兵环境
注意点一:
- 此处涉及到多个 Redis 服务器?,同时也有多个 Redis 哨兵节点
- 每个 Redis 服务区 或 每个 Redis 哨兵节点 都作为一个单独的容器(6个容器)
- 通过配置文件,把具体要创建哪些容器 和 每个容器运行的各种参数 给描述清楚
- 后续通过一个简单的命令,便能批量的启动 或 停止这些容器了!
注意点二:
- 此处我们使用 yml 格式来作为配置文件
注意点三:
- 此处我们创建两个 yml 配置文件
- 创建三个容器,作为 Redis 的数据节点(一主两从)
- 创建三个容器,作为 Redis 的哨兵节点
问题:
- 是否可以直接仅用一个 yml 配置文件直接启动上述的 6个容器?
- 即将?Redis 的数据节点和?Redis 的哨兵节点放到一个配置文件中,然后统一启动或停止
回答:
- 如果将这?6个容器同时启动,可能是 哨兵节点 先启动完成,数据节点后启动完成
- 此时哨兵节点便可能会认为数据节点挂了
- 虽然对于大局不影响,即可以成功启动,但是会影响这些节点的执行过程,从而影响后续日志的观察
注意点四:
- 为了方便部署,此处我们使用 docker-compose 来进行 容器的编排!
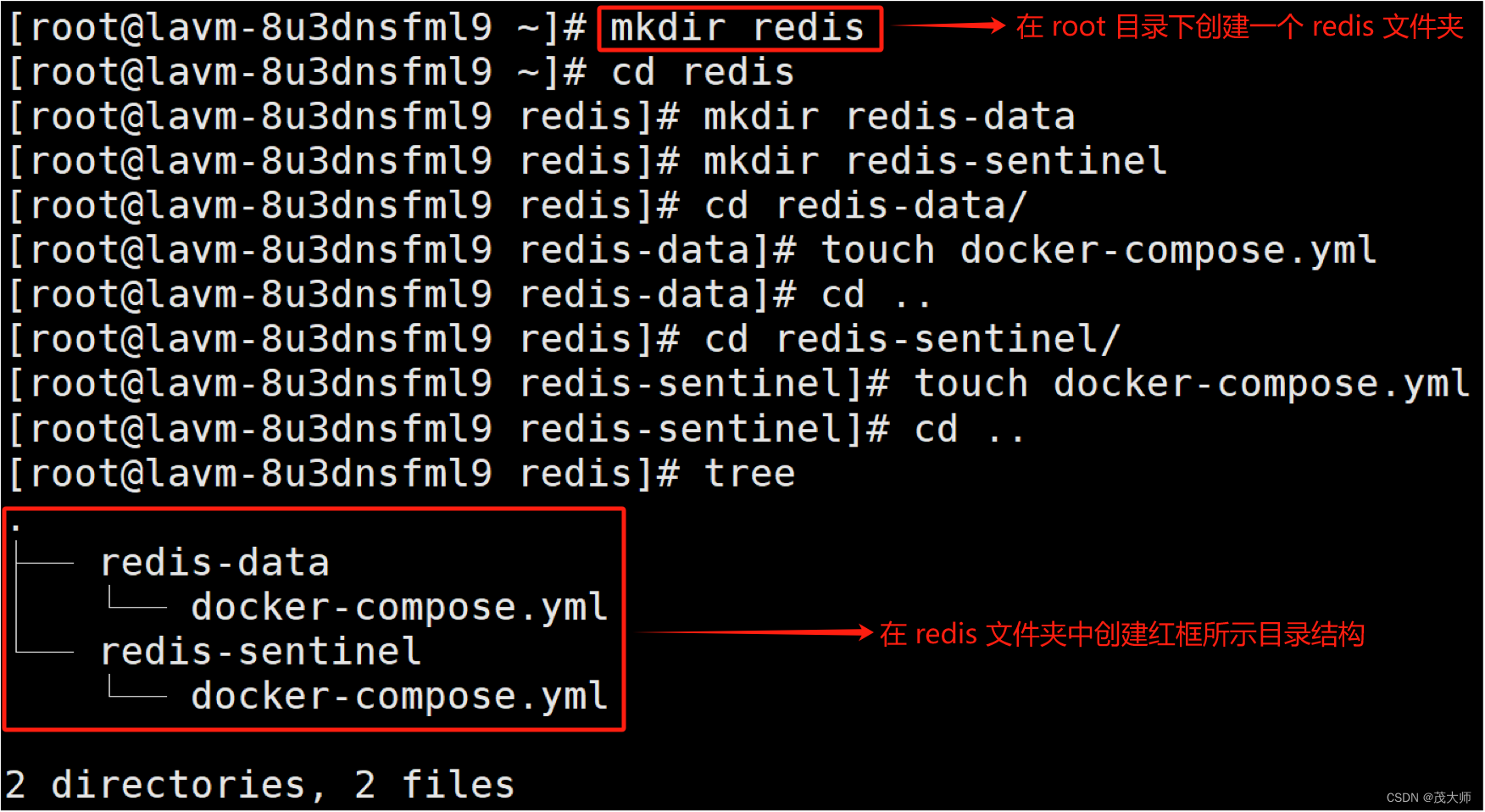
5、配置数据节点的 yml 文件
version: '3.7' services: master: image: 'redis:5.0.9' container_name: redis-master restart: always command: redis-server --appendonly yes ports: - 6379:6379 slave1: image: 'redis:5.0.9' container_name: redis-slave1 restart: always command: redis-server --appendonly yes --slaveof redis-master 6379 ports: - 6380:6379 slave2: image: 'redis:5.0.9' container_name: redis-slave2 restart: always command: redis-server --appendonly yes --slaveof redis-master 6379 ports: - 6381:6379
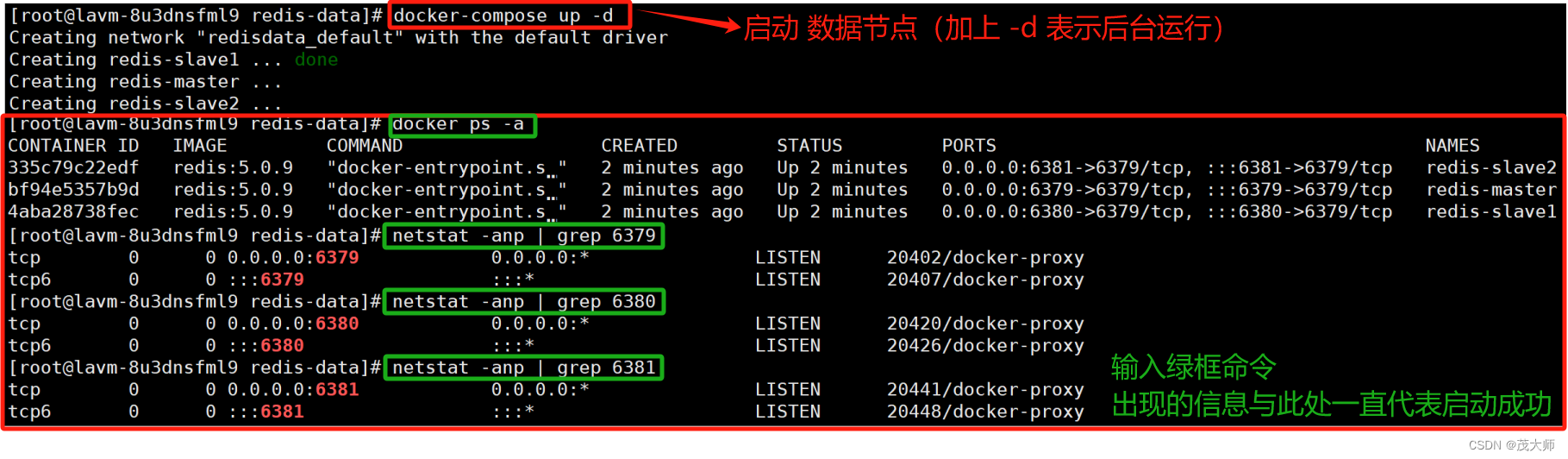
7、启动数据节点
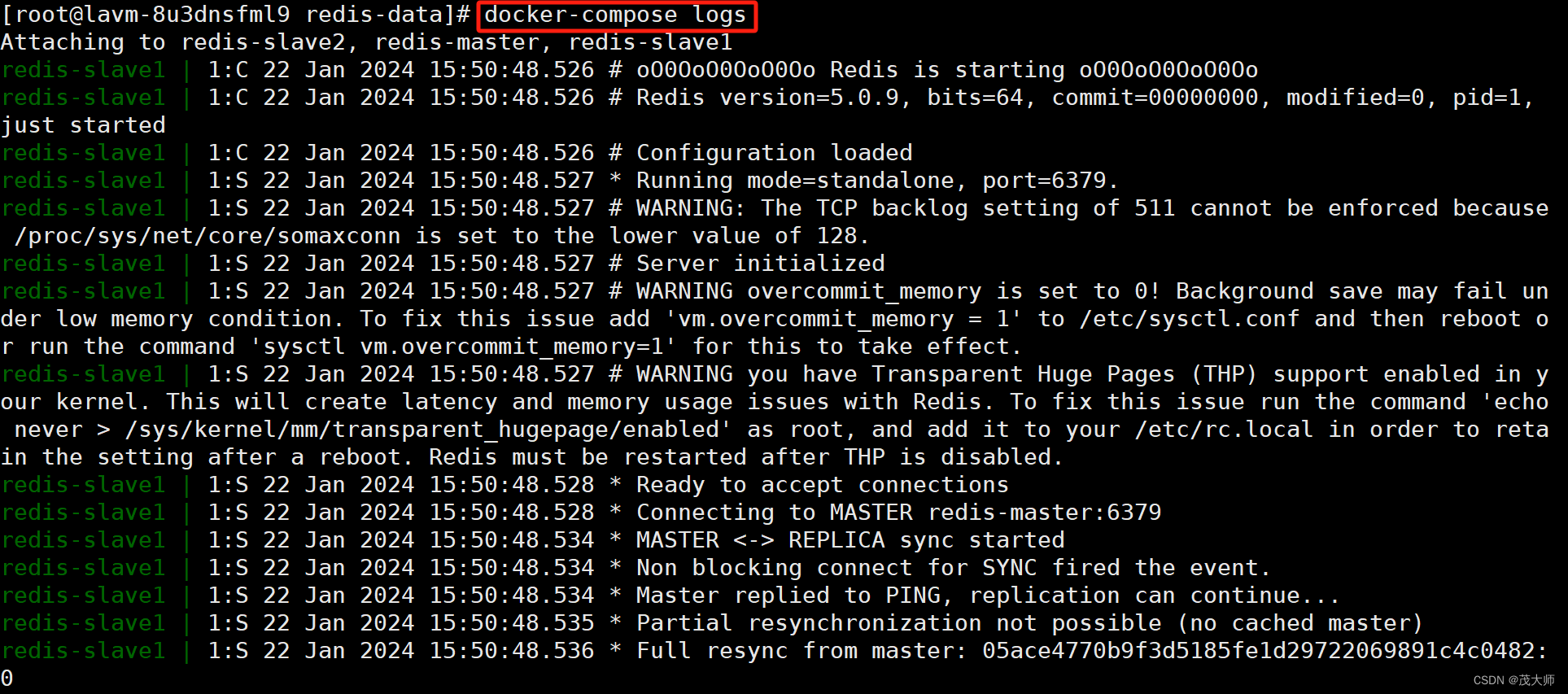
- 当然我们也可以通过输入 docker-compose logs 命令来查看运行日志信息
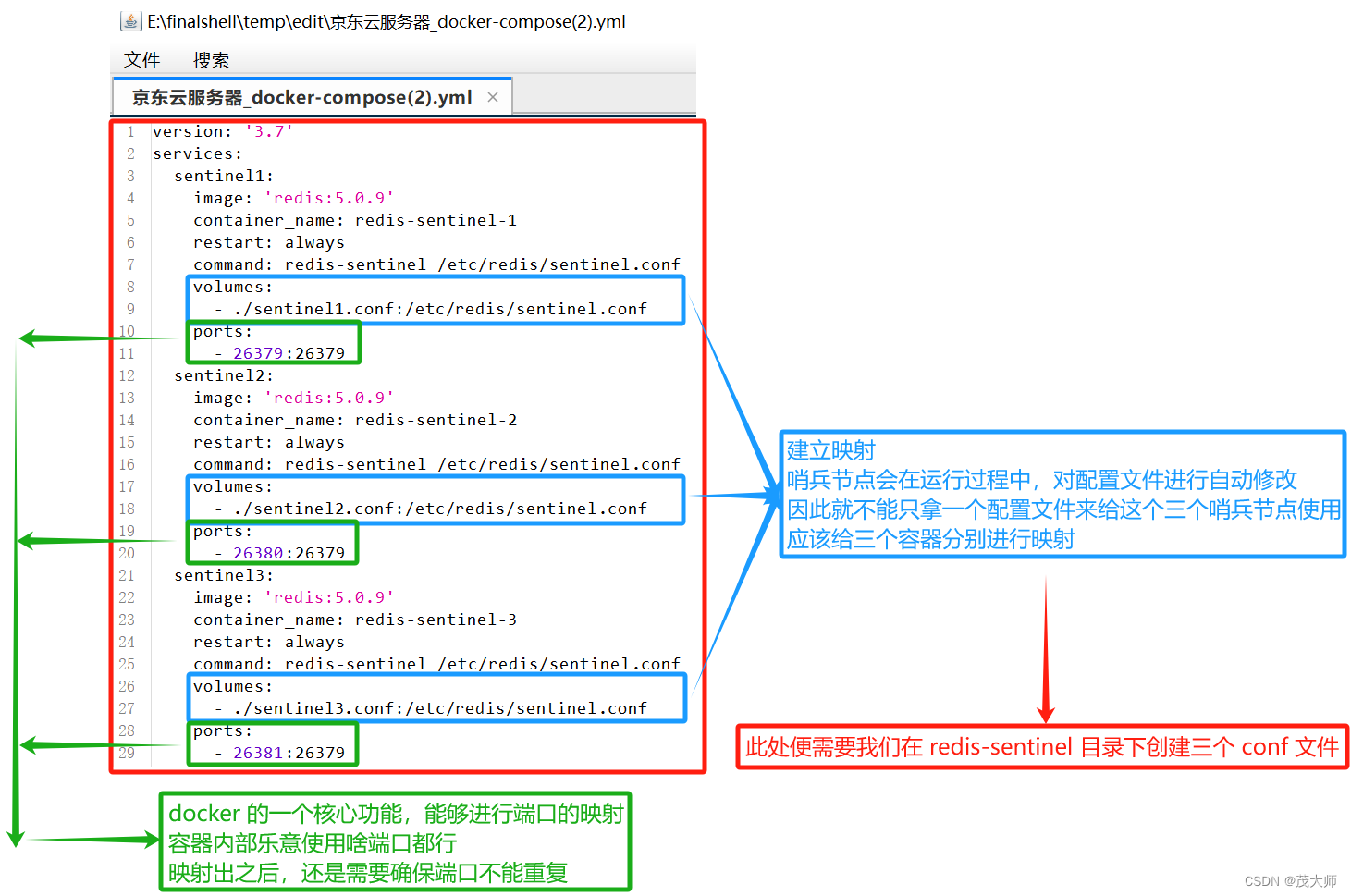
8、配置哨兵节点的 yml 文件
?redis 哨兵节点 是单独的 redis 服务器进程
- 根据上图所示,需要我们在 redis-sentinel 目录下创建三个 conf 文件 !!
version: '3.7' services: sentinel1: image: 'redis:5.0.9' container_name: redis-sentinel-1 restart: always command: redis-sentinel /etc/redis/sentinel.conf volumes: - ./sentinel1.conf:/etc/redis/sentinel.conf ports: - 26379:26379 sentinel2: image: 'redis:5.0.9' container_name: redis-sentinel-2 restart: always command: redis-sentinel /etc/redis/sentinel.conf volumes: - ./sentinel2.conf:/etc/redis/sentinel.conf ports: - 26380:26379 sentinel3: image: 'redis:5.0.9' container_name: redis-sentinel-3 restart: always command: redis-sentinel /etc/redis/sentinel.conf volumes: - ./sentinel3.conf:/etc/redis/sentinel.conf ports: - 26381:26379
?9、创建哨兵节点的三个 conf 配置文件
- 向三个配置文件中写入相同内容
bind 0.0.0.0 port 26379 sentinel monitor redis-master redis-master 6379 2 sentinel down-after-milliseconds redis-master 1000注意:
- 初始情况下,这三个配置文件内容可以是一样的!
10、启动哨兵节点
- 使用?docker-compose logs 查看日志文件
- 此处我们可以看到全是报错信息
- 该哨兵节点,不认识 redis-master
- redis-master 相当于一个域名,docker 会自动对其进行域名解析
原因:
- 当使用 docker-compose 启动 N个容器时
- 此时这 N 个容器均处于同一个局域网中,因此这 N 个容器之间可以相互访问
- 显然因为 数据节点 和 哨兵节点 并不是同时启动的!
- 所以 三个数据节点处在一个局域网,三个哨兵节点处在另一个局域网
- 默认情况下,这俩个局域网之间是不互通的!
实例理解
- 使用 docker network ls 命令列出当前 docker 中的局域网
- 此处先启动了 三个数据节点,就相当于自动创建了 第一个局域网
- 再启动三个哨兵节点,相当于又自动创建了 第二个局域网
解决方案:
- 可以使用 docker-compose 将此处的两组服务器给放到同一个局域网中
- 即直接 三个哨兵节点 加入到 三个数据节点的局域网中
- 而不是让这三个哨兵节点在启动时自动创建第二个局域网
11、在 redis-sentinel 文件下的 docker-compose.yml 配置文件下补充内容
networks: default: external: name: redisdata_default
12、重新哨兵节点的容器
- ?打开 sentinel1.conf 、sentinel2.conf、sentinel3.conf 进行观察
- 通过上述的操作,就完成了 Docker 模拟部署哨兵模式!













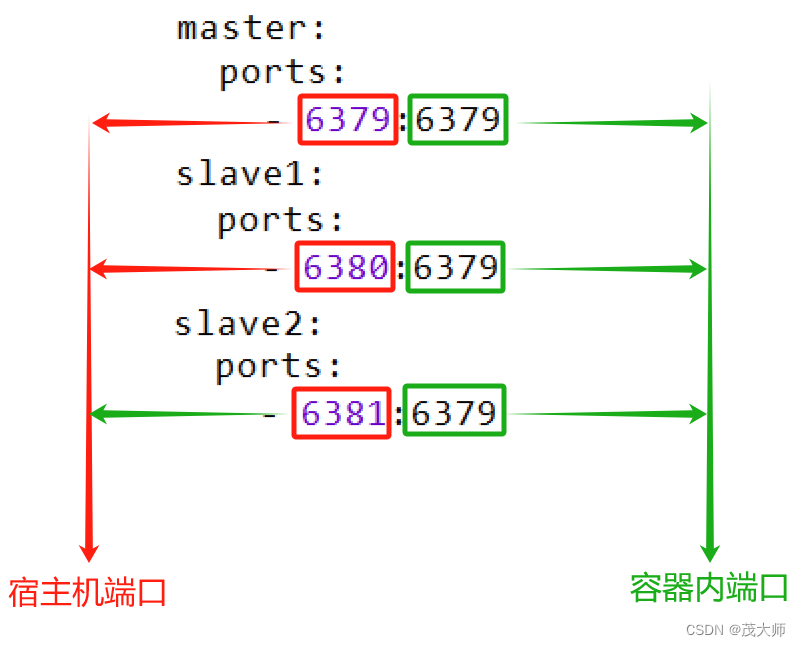
关于端口映射?
- docker 容器可以理解成是一个轻量的虚拟机
- 在该容器中,端口号 和 外面宿主机 的端口号为两个体系
实例理解
- 如果外面宿主机使用了 5000 端口,在容器内部也可以使用 5000 端口
- 彼此不会冲突
- 有时候希望在容器外面能够访问到容器内部的端口
- 此时便需要进行端口映射,将容器里的端口映射到宿主机上
- 后续访问宿主机的这个端口,就相当于在访问对应容器的对应端口了
- 三个容器,每个容器内部的端口号都自成一个小天地
- 即容器1?的?6379 和 容器2 的 6379 之间彼此不会有冲突
- 可以把两个容器视为两个主机
- 站在宿主的角度,访问上述几个端口时,也不知道这个端口实际上是一个宿主机上的服务,还是来自于容器内部的服务
- 只要正常去使用即可
注意:
- 此处的映射过程非常像 NAT
展现哨兵机制
- 哨兵存在的意义,就是能够在 Redis 主从结构出现问题时(比如主节点挂了)
- 此时哨兵节点便能够自动的帮我们重新选出一个节点来代替之前挂了的主节点,以此保证整个 Redis 仍然为可用状态
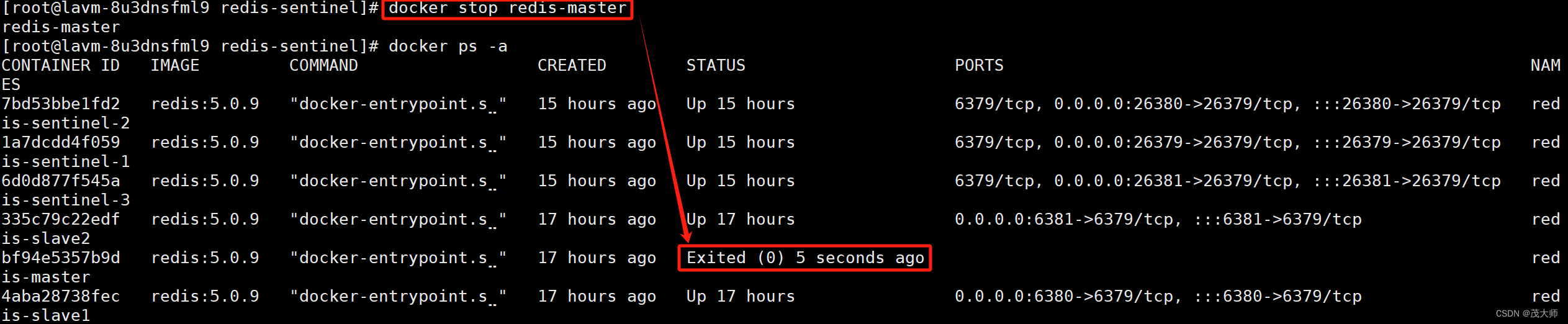
1、这里我们可以通过 docker stop redis-master? 命令手动将主节点给干掉
- 当主节点挂掉之后,哨兵节点便开始工作了!
2、此处我们可以观察哨兵节点的工作日志
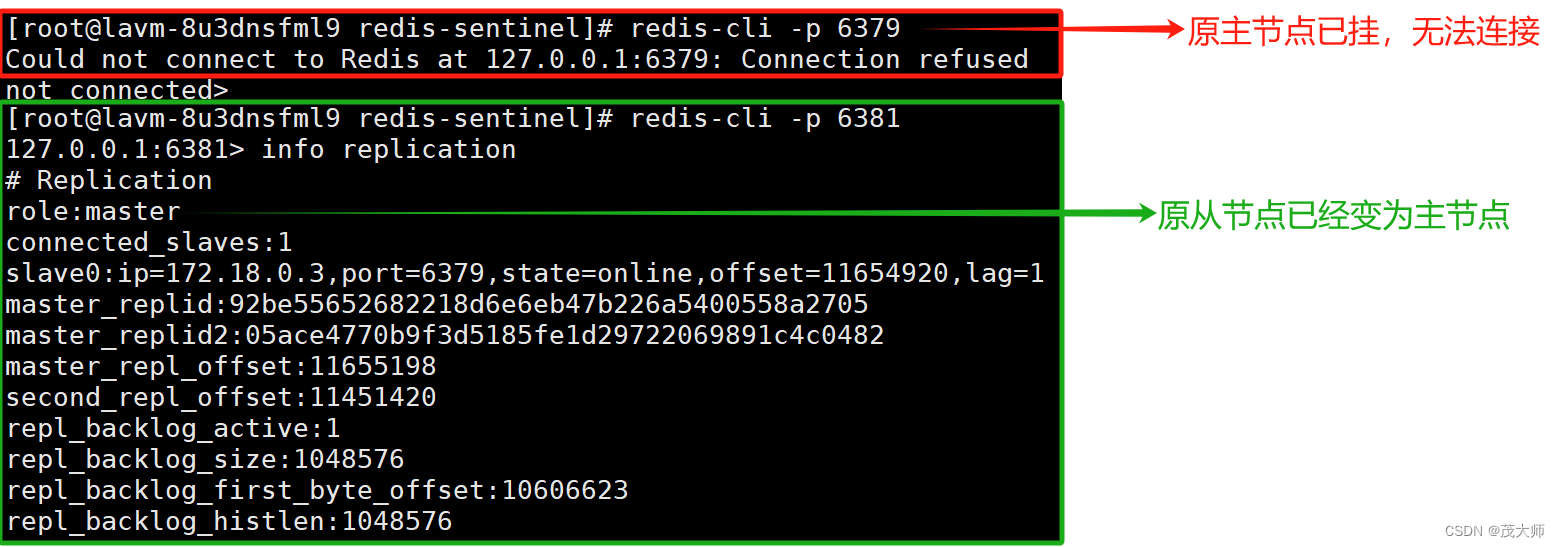
3、此处我们连接到被选中的从节点,即新的主节点
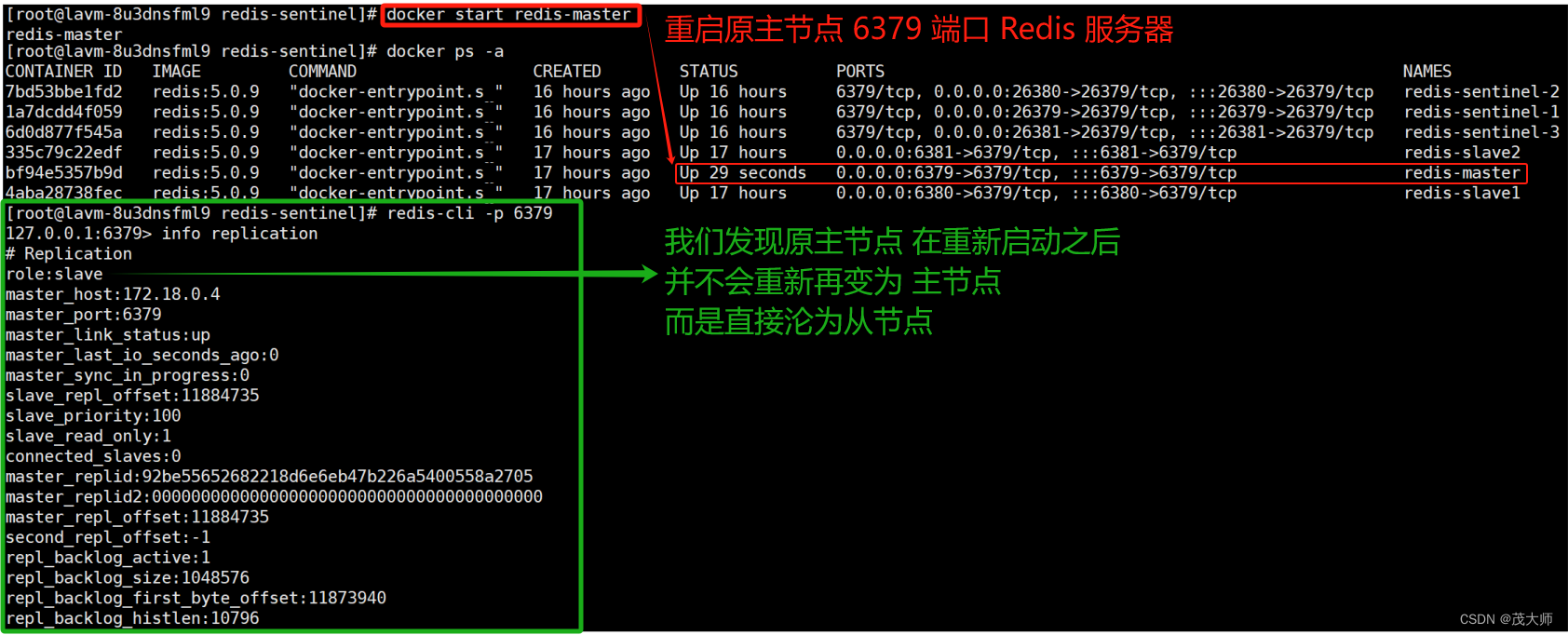
4、此时我们重启 原 6379 端口主节点继续观察

哨兵重新选取主节点的流程
1、主观下线
- 哨兵节点通过心跳包,判定 Redis 服务器是否正常工作
- 如果心跳包没有如约而至,就说明该 Redis 服务器挂了
- 当然此时并不能排网络波动的影响,因此就只能是单方面认为这个 Redis 服务器挂了
2、客观下线
- 多个哨兵都认为主节点挂了,即 认为挂了的哨兵节点数目达到法定票数
- 此时哨兵们便会认为该?主节点为?客观下线
问题:
- 是否可能出现非常严重的网络波动,导致所有哨兵都联系不上 Reids 主节点,从而误判成 Redis 主节点挂了呢?
回答:
- 可能存在!
- 如果出现该情况,可能用户的客户端也连不上 Redis 主节点了
- 此时这个主节点基本也无法正常工作了
注意:
- 挂了 不一定是进程崩了
- 只要无法正常访问,都可以视为是挂了
3、多个哨兵节点选出一个 leader 节点,由?leader 负责选出一个 从节点 作为新的主节点
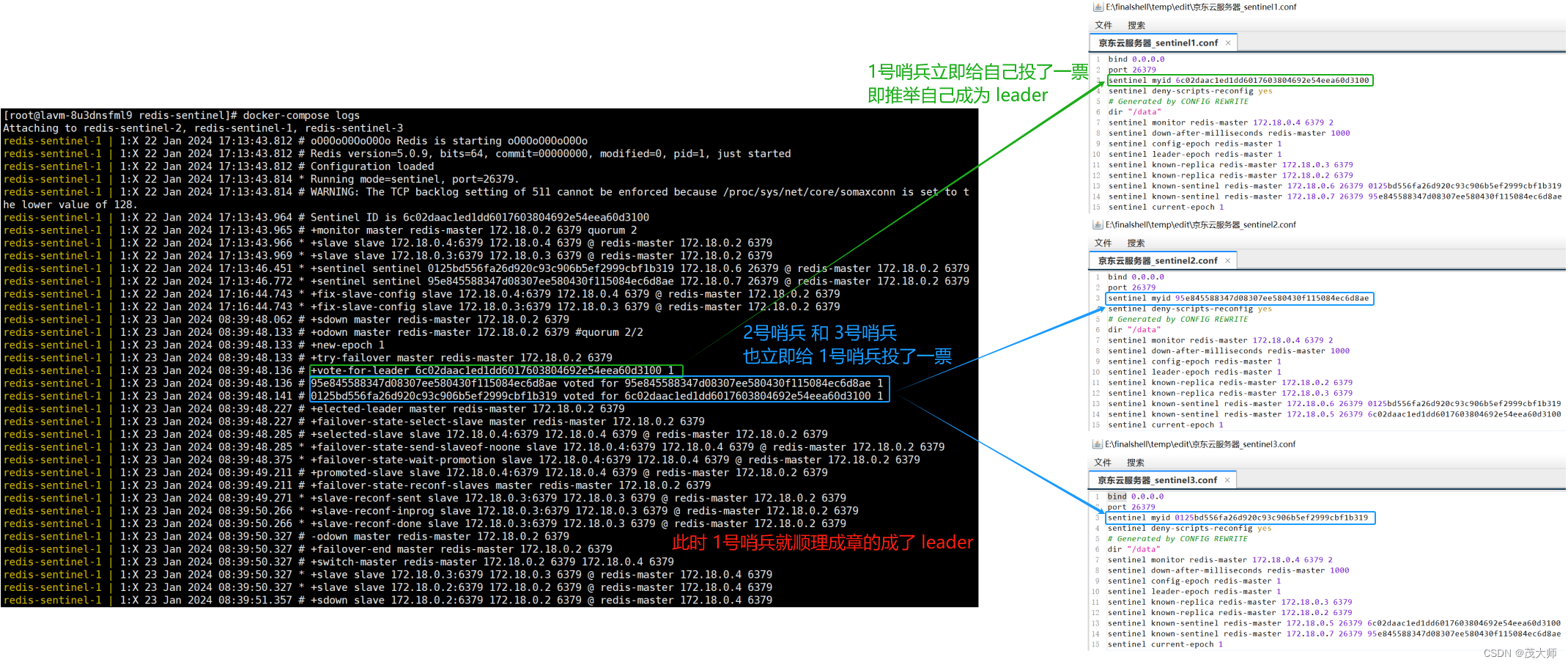
- 每个哨兵手里只有一票
- 当哨兵1 第一个发现当前为客观下线后,便立即给自己投一票,并且告诉哨兵2 和哨兵3 我来负责这件事
- 哨兵2 和 哨兵3 反应慢了半拍后发现为客观下线,一看哨兵1 乐意负责这件事,便立即投了赞成票
注意点一:
- 对于哨兵2 和哨兵3 而言,当它们还未投票时,只要收到拉票请求,便会直接投出该票
- 即 如果有多个拉票请求,会投给最先到达的
注意点二:
- 如果总的投票数超过哨兵总数的一半,此时选举便完成了
- 也正是因为这一点,才建议将哨兵个数设置为奇数个节点,方便投票!
注意点三:
- 上述投票过程,就是看谁的反应快、谁的网络延时小
- 谁的反应快,谁就最有可能成为 leader !
4、leader 选举完毕,leader 挑选一个从节点,作为新的主节点
挑选顺序如下:
- 优先级: 每个 Redis 数据节点都会在配置文件中,均存在优先级设置(slave-priority),即优先级最高的将成为新的主节点
- offset:代表从节点这边同步数据的进度,谁的数值越大,谁的数据和主节点数据就越接近,即 offset 最大的将成为新的主节点
- run id:每个 Redis 节点启动时,都会随机生成的一串数字(大小全凭缘分),此时将随机挑选一个成为新的主节点
5、leader 控制选中的节点执行 slave no one 命令成为 master,再控制其他节点,执行 slave of ,让其他节点以新的 master 作为主节点
小总结:
- 以上是个常见的面试题
- 尤其是注意选举的过程,不是直接选出新的主节点,而是先选 leader 由 leader 负责后续的主节点指定
哨兵模式注意事项
- 哨兵节点不能只有一个,否则哨兵节点挂了也会影响系统可用性
- 哨兵节点最好是奇数个,方便选举 leader ,得票更容易超过半数(大部分情况下 3 个足已)
- 哨兵节点不负责存储数据,仍然是 Redis 主从节点负责存储(哨兵节点就可以使用一些配置不高的机器来部署,但是不能搞一个机器部署三个哨兵)
- 哨兵?+ 主从复制解决的问题是 提高可用性,不能解决 数据极端情况下写丢失 的问题
- 哨兵 + 主从复制不能提高数据的存储容量,当我们需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了
- Redis 集群就是解决存储容量问题的有效方案
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Logstash访问安全访问Elasticsearch集群
- 基于springboot的华府便利店信息管理系统
- 更新钉钉文档封装好的代码
- Java中的输入输出处理(一)
- 运动健身app开发常见问题,项目经理经手10个相关项目后的亲身总结
- 求n个数中出现次数最多的数 (UPC)
- Windows10系统下关于MySQL8.2登录时出现ERROR 1045 (28000)问题的解决方案
- 单调队列及其用法
- 【大数据分析与挖掘技术】推荐
- 2023年03月20日_对李开复3月20日线下媒体会的解读