记录一次接近24万条数据导入Mysql的过程
发布时间:2024年01月09日
由于开发项目的需求,之前有部分数据要写入阿里云的表格存储,过了一年多时间,表A的数据量接近24万条,现在需要将表A的数据转到Mysql中。
利用官方工具导出数据后,发现文件里面有238999条数据,文件大小是460MB。
想了个流程:
- 按照表A的结构先在Mysql中创建对应的表格
- 文件先上传到OSS中,再从OSS中通过流方式读取回来,逐行回放,每10条发送一次到Mysql写入
说干就干,写好了程序,本地测试了小文件没有什么问题,放到服务器上的Docker中运行。
网卡打满,内存,CPU全部满载。失败告终。最终成果,只写入了1万多条数据。
总结了原因,读取OSS时用了公网,转成内网再试了一次,公网网卡不受影响了。内存,CPU照样全部满载。又是失败告终。
后来又想了个办法,将文件通过内网下载到Docker中,再用流读取方式,但是有个矛盾始终无法解决。就是控制流速的问题,试了response.data.on(‘data’, (chunk) => {})做等待,也是徒劳。
又尝试了某网友介绍的event-stream包,始终很好地控制流速,导致硬盘IO、内存、CPU全部满载,Mysql只写了几百条数据就失败了。
根据削峰填谷的思想,今天尝试了一个新方法,先将OSS上的数据按照准备写入Mysql的格式放到Redis里,Redis内存使用暴增400多M,之后逐条回放,操作成功就删除Redis上面的对应的数据,经过了差不多一个小时操作,数据入库成功,Redis内存使用量也恢复正常。写入的过程服务器和Mysql的监控显示CPU、内存、带宽、硬盘IO都比较平衡,重要的是没有影响其他服务。经过一个星期的试验和实践,算是完美解决了此问题。
服务器监控数据:
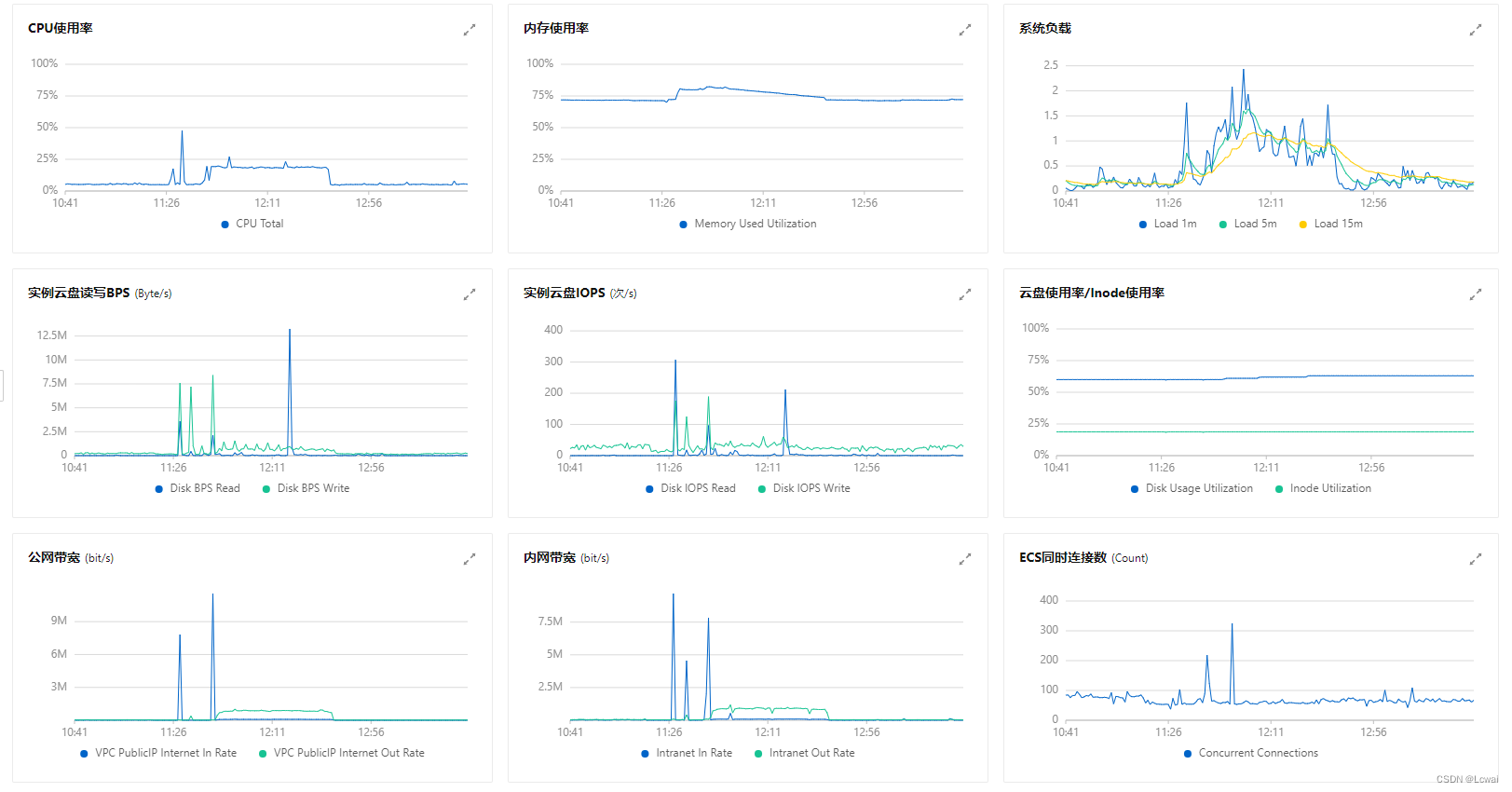
数据监控数据:
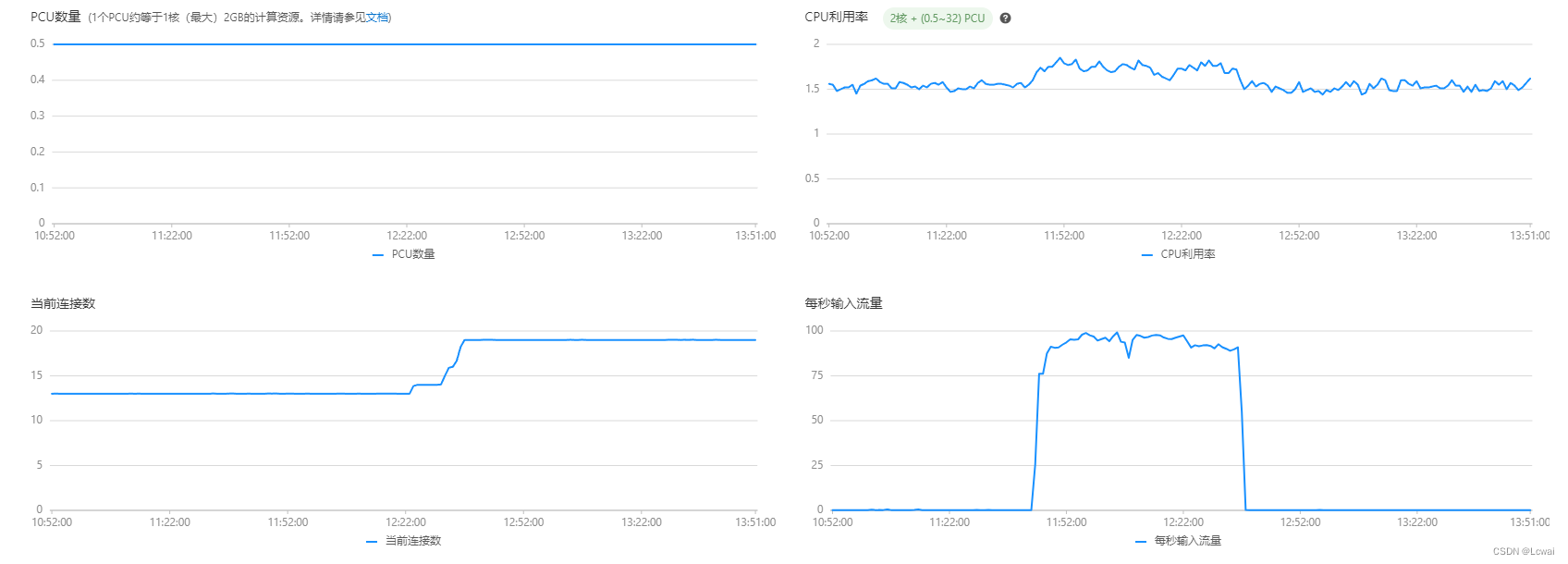
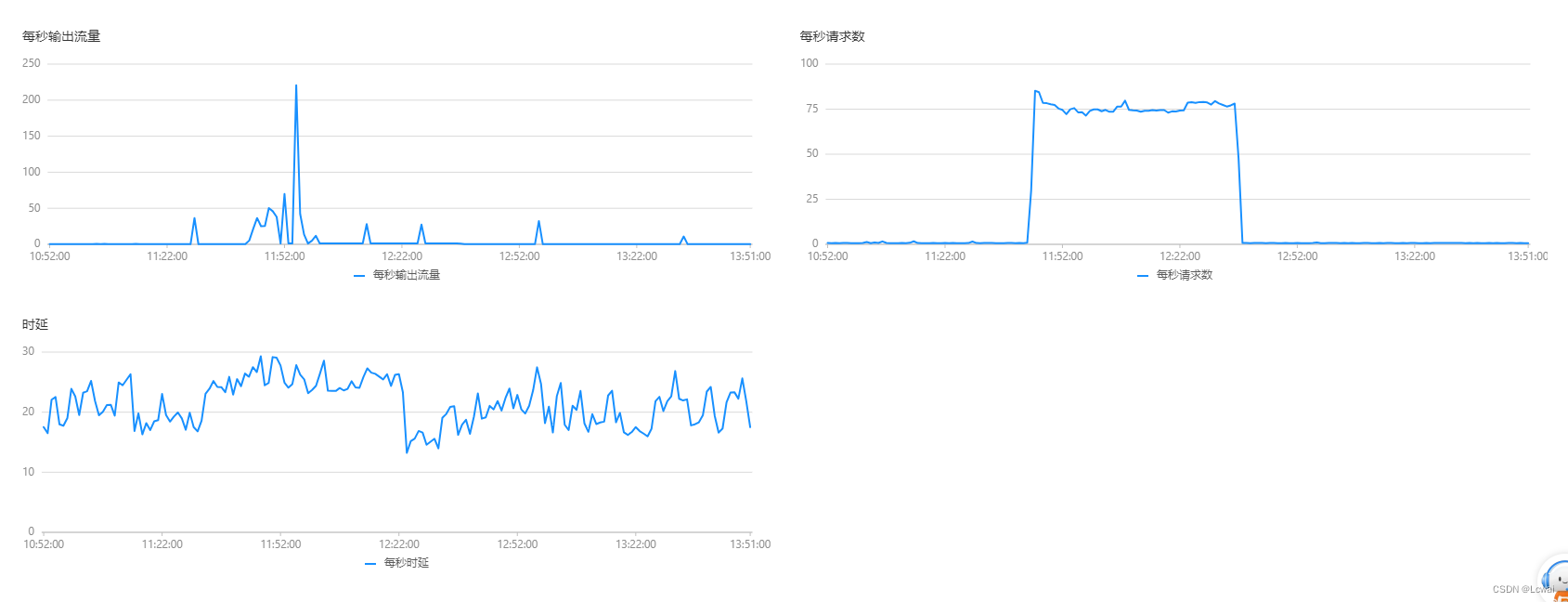
文章来源:https://blog.csdn.net/Wai_Leung/article/details/135478817
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据结构和算法】子数组最大平均数 I
- 【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述
- echarts使用01
- 继续理解Nacos的CP和AP架构模型!
- 【机组期末速成】指令系统|机器指令概述|操作数类型与操作类型|寻址方式|指令格式
- 软件功能测试的流程
- 全网最低价——组合预测模型全家桶
- Web前端与低代码可以碰出什么火花?
- 【资源分享】免费好用的API接口汇总
- 虚拟机(克隆)导入/导出镜像(VOA&VOF)