Kubernetes
应该程序部署方式
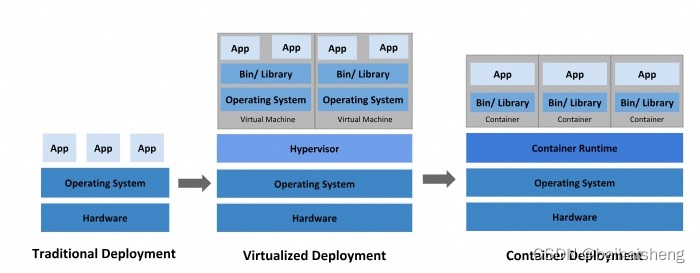
一、物理机 —传统方式
二、虚拟化部署,一台物理机运行多个虚拟机,多个操作系统
三、容器化部署,共享操作系统
容器管理-容器编排:
Swarm:docker自己的容器编排工具
kubernetes google开源的容器编排工具
kubernetes简介
是一个全新的基于容器技术的分布式架构方案,是google开源的容器编排工具,于2015年7月发布第一个正式版本
kubernetes本质是一组服务器集群,集群每个节点运行特定的程序,目的是实现资源管理自动化,主要提供的功能:
自我修复:容器崩溃,快速启动新的
弹性伸缩:自动对集群中运行的容器数据量进行调整
负载均衡:一个服务启动多个容器,自动实现请求的负载均衡
版本回退:发布版本有问题,可以回退到原来的版本
存储编排:根据自身自动创建存储卷
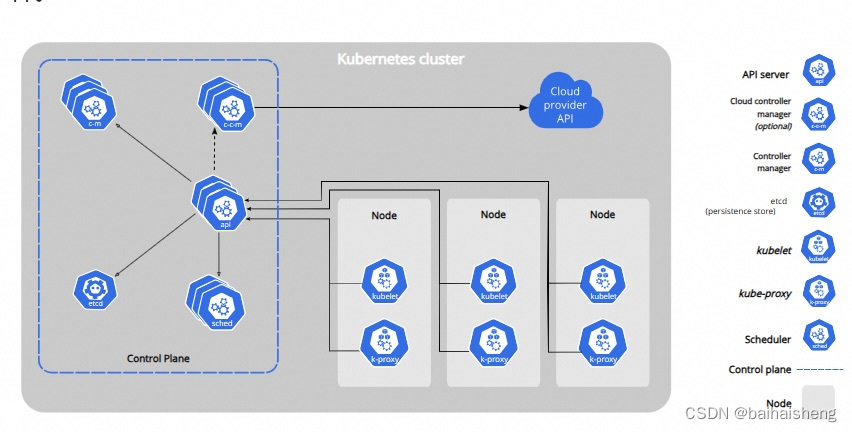
kubernetes核心组件
master(管理节点)和worker(工作节点)组成
master(管理节点):集群管理
Apiserver:资源操作的唯一入口,接受用户输入的命令,提供认证、授权、api注册和发现等机制
Scheduler:负责集群资源调度,按照预定的调度策略将POD调度到相应的worker节点上
controllerManager:负责维护集群的状态,例如程序部署安排,故障检测、自动扩展、滚动更新等
Etcd:负责存储集群中各种资源对象信息
worker(工作节点):容器运行环境
Kubelet:负责维护容器的生命周期、即通过控制docker、来创建、更新、销毁容器
Kubeproxy:负责提供集群内部的服务发现和负载均衡–程序对外服务
Docker:负责节点上容器的各种操作
组件调用关系:
程序安装请求–>master–>Apiserver–>Scheduler(计算安装节点)–>Etcd(Scheduler读取Etcd节点信息选择节点)-Apiserver-controllerManager-Kubelet-docker(启动一个pod)
Kubernetes组件社区:https://kubernetes.io/zh-cn/docs/concepts/overview/components/
kubernetes概念:
Pod:容器都是运行在pod中,一个pod可以有1个活多个容器
controller:
Service:pd对外服务的统一入口
Label:标签 用于对pod进行分类,同一类pod会拥有相同的标签
NameSpace:命名空间,用于隔离pod运行环境
Kubernetes集群部署规划:
一主多从:一台master节点和多台worker节点组成,一般测试环境使用
多主多从:多台master节点和多台worker节点组成,一般生产环境使用
一、资源管理方式:
kubectl–集群命令行工具,通过他能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署
kubectl [command] [type] [name] [flags]
command:指定要对资源执行的操作
type:指定资源类型,例如pod、service
name:指定资源名称
flags:指定额外可选参数
命令式对象对象管理,直接使用命令去操作kubernetes资源 -操作对象
kubectl run nginxpd --image=nginx:1.xxx --port=80
命令式对象配置,通过命令配置和配置文件去操作kubernetes资源–操作对象目录文件
kubectl create(创建)/patch(更新) -f nginx-pod.yaml
声明式对象配置 通过apply命令和配置文件去操作kubernetes资源 --操作对象目录
kubectl apply -f nginx-pod.yaml --创建更新资源,有就更新,没有就创建
Ingress介绍
Service对集群之外暴露服务的主要方式有两种:nodeport和loadbalance
这两种方式缺点:
nodeport:占用集群节点端口
loadbalance:每个service需要一个loadbalance,浪费,麻烦。且需要集群之外的设备支持
kubernetes提供了Ingress资源对象,只需要一个nodeport或者一个loadbalance就可以满足暴露多个service的需求
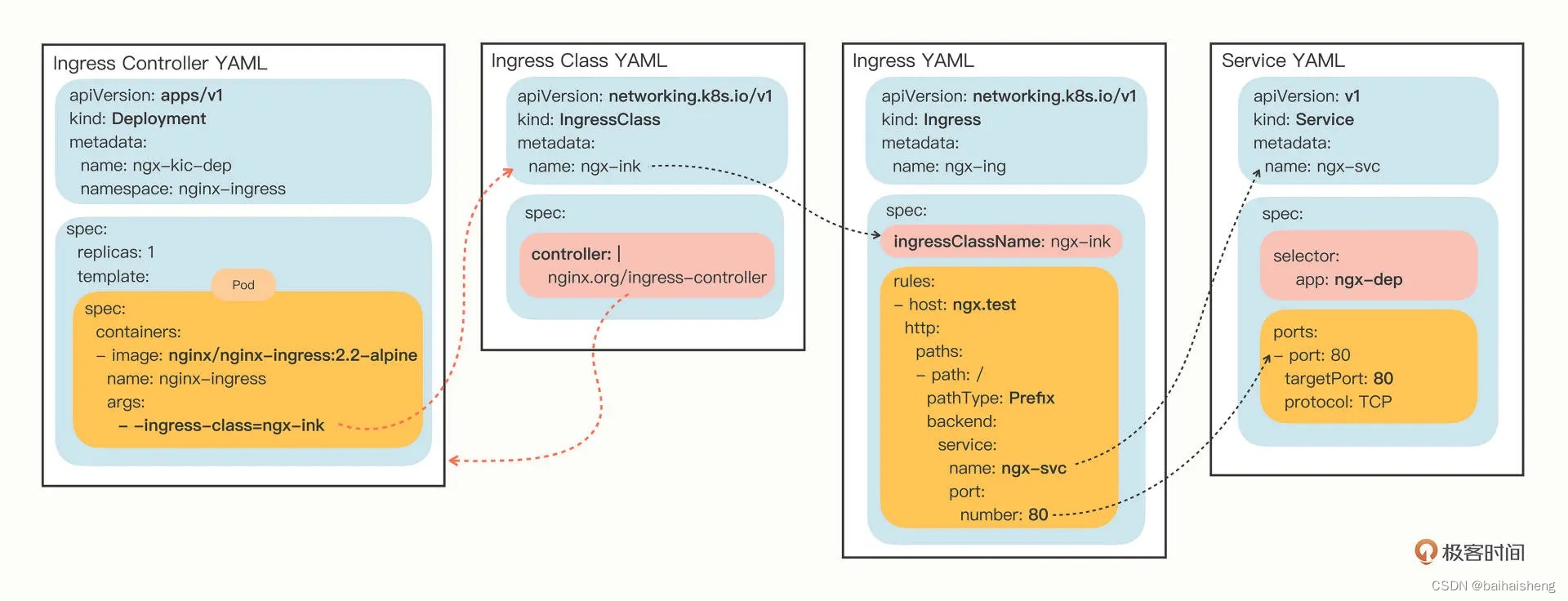
Ingress相对于一个7层的负载均衡,是kubernetes对反向代理的一个抽象,它的工作原理类型与Nginx,可以理解成Ingress里建立了多个映射规则,Ingress controller通过监听这些配置规则并转化成nginx的配置,然后对外提供服务,
Ingress:作用是定义请求如何转发到service的规则
Ingress controller:具体实现反向代理及负载均衡程序,对Ingress定义的规则进行解析,根据配置的规则来实现请求转发,实现的方式有很多,例如nginx haproxy等
工作原理(以ngix为例)原理:
1、编写Ingress规则,说明那个域名对应kubernetes集群中的那个service
2、Ingress控制器动态感知Ingress服务规则的变化,然后生成一段对应的nginx配置
3、Ingress控制器会将生成的nginx配置写入到一个运行着的nginx服务中,并动态更新
4、真正工作的就是nginx
yaml主要配置:
host:外部访问域名
paths:路径
servicename: service服务名
port:service的服务端口
https额外增加配置
tls:
Ingress 、Service、Ingress Class Ingress controller关系:
service详解
在kubernetes中,pod是应用程序的载体,可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的(可能会频繁的创建销毁),所以不方便采用pod的ip对外提供服务
kubernetes提供了service资源,提供一个统一的入口地址,通过访问service的入口地址就能访问pod
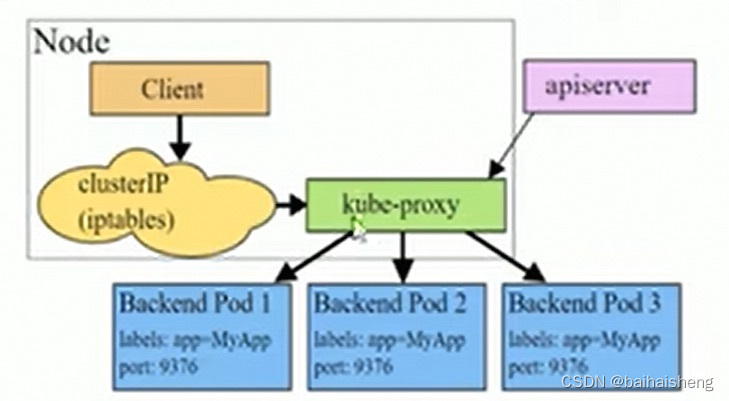
service只是一个概念,实际起作用的是kube-proxy服务进程,每个节点上都运行着一个kube-proxy进程,当创建service的时候会通过api-server向etcd写入创建service的信息,而kube-proxy会基于监听的机制发现这种service的变动然后它会将最新的service信息转换成对应的访问规则
kube-proxy会基于rr(轮询)策略,转发请求到pod
kube-proxy支持三种工作模式:
userspace模式
userspace模式下,kube-proxy会为每一个service创建一个监听端口,发向cluster IP的请求被iptables规则重定向到kube-proxy
监听端口上,kube-proxy根据LB算法选择一个提供服务的pod并和其建立链接,以将请求转发到pod上
该模式下,kube-proxy充当一个四层负债均衡的角色,由于kube-proxy运行在userspace中,在进行转发处理时会增加内核和用户空间之间的数据拷贝,虽然稳定,但是效率比较低
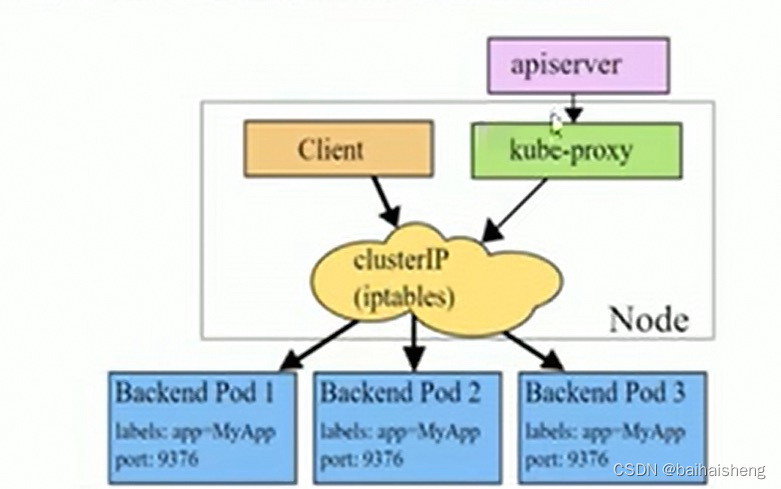
iptables模式
iptables模式下,kube-proxy为service后端的每一个pod创建对应的iptables规则,直接将发向cluster ip的请求重定向到一个pod ip
该模式下kube-proxy不承担四层负载均衡器的角色,只负责创建iptables规则,该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端pod不可用时无法进行重试
ipvs
该模式和iptables类似,kube-proxy监控pod的变化并创建相应的ipvs规则
ipvs相对iptables转发效率更高,ipvs支持更多的LB算法
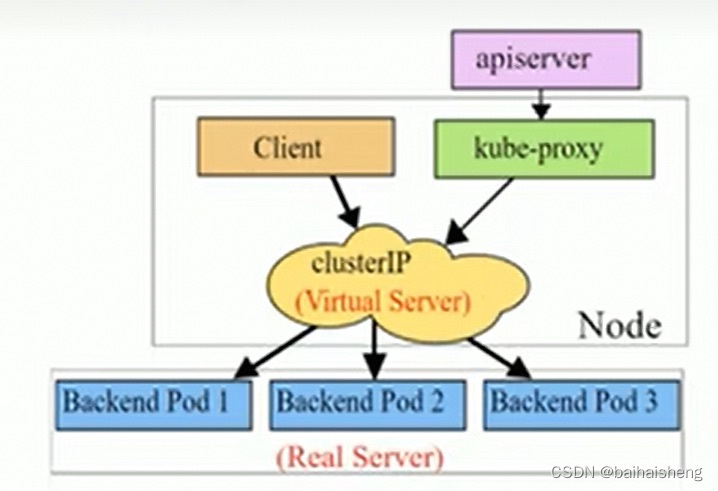
api-server接受创建service的请求,这个时候kube-proxy会生成一套ipvs规则策略,业务访问的时候基于策略转发
创建service的spec参数:
selector 标签选择器
type 类型
cluster ip service的ip
session session亲和性
ports
service 端口
pod 端口
nodeport 主机端口
service的yaml配置文件可以配置session亲和性–基于客户端地址的会话保持模式,即来自同一客户端发起的所有请求都会转发到固定的一个pod上,如果不定义,默认使用kube-proxy的策略:轮询
type 类型介绍
Cluster ip :是kubernetes系统自动分配的虚拟IP,只能在集群内部访问,缺点:cluster集群内部ip地址
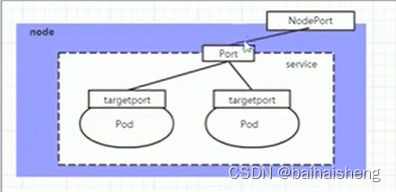
Nodeport: 将service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务,service配置文件增加了nodeport端口信息,node的ip地址:nodeport访问即可访问service的ip:service的端口
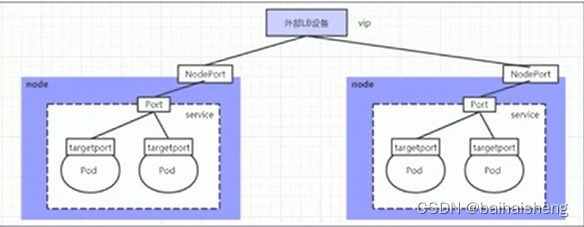
Loadbalance 和Nodeport很类似,区别在与Loadbalance 会在集群外部再来做一个负载均衡设备,使用外接负载均衡器完成到服务的负载分发,此模式需要外部云环境支持,外部服务发送到这个设备的请求,会被设备负载之后转发到集群中
ExternalName 把集群外部的服务引入到集群内部,直接使用
pod介绍:容器的封装
有状态
无状态
存储介绍
为了持久化保存容器的数据,kubernetes引入了Volume的概念,Volume是pod中能够被多个容器访问的共享目录,它被定义在pod上,然后被一个pod里的多个容器挂载到具体的文件目录下,kubernetes通过Volume实现同一个pod中不同容器之间的数据共享及数据的持久化存储,Volume的生命周期不与pod中单个容器生命周期相关,当容器终止或者重启,Volume中的数据也不会丢失
volume支持多种类型,常见的有:
简单存储:EmptyDir hostpath NFS
EmptyDir
是最基础的Volume,一个Volume就是host上一个空目录,EmptyDir是在pod被分配到node是创建的,它的初始内容为空,并且无须指定主机上对应的目录文件,因为kubernetes会自动分配,一个目录,当pod销毁时,emptydir中的数据也会被永久删除,emptydir用途如下:临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留,一个容器需要从另一个容器中获取数据目录(多容器共享目录)
举例:在一个pod中准备两个容器nginx和busybox,然后声明一个volumw分别挂在到两个容器的目录中,然后nginx容器负责向volume中写日志,busybox中通过命令将日志内容读到控制台
volume-empytdir.yaml
apiVersion:v1
kind:pod
metadata:
name:volume-empytdir
namespace:dev
spec:
containers:
- name:nginx
image:nginx:1.17.1
ports:
- containerport:80
volumeMounts:#将logs-volumes挂载到nginx容器中,对应的目录为 /var/log/nginx
-name:logs-volume
mountPath:/var/log/nginx
- name:busybox
image:busybox:1.30
command:[] #初始命令,动态读取指定文件中的内容
volumeMounts: #将logs-volume挂载到busybox容器中,对应目录为 /logs
-name:logs-volume
mountpath:/logs
volumes:声明volume name为logs-volume 类型为emptyDIR
- name:logs-volume
emptyDIR:{}
hostpath:就是将node主机中一个实际目录挂载到pod中,以供容器使用,这样设计就可以保证pod,销毁了,但是数据依然可以存在于node主机上
volumes:声明volume name为logs-volume 类型为emptyDIR
- name:logs-volume
hostpath:
path:/
type: dirtoryorcreate
NFS
hostpath方法node一旦故障了,pod会转移到其他节点上了,就会出现问题,此时需要准备单独的网络存储系统常用的有NFS,CIFS
NFS是一个网络文件存储系统可以搭建一台NFS服务器,然后将pod中的存储直接连接到nfs系统上,这样的话,无论pod在节点这么转移,只要node跟nfs的对接没问题,数据就可以成功访问
volumes:声明volume name为logs-volume 类型为emptyDIR
- name:logs-volume
nfs:
server: 192.168.109.11
path:/nfs
高级存储:PV PVC
PV是持久话卷的意思,是对底层的共享存储的一种抽象,一般情况下PV有kubernetes管理进行创建和配置 它与底层具体的共享存储技术有关,并通过插件完成与共享存储的对象
PVC 是持久卷声明的意思,是用户对应存储需求的一种声明,PVC其实就是用户向kubernetes系统发出的一种资源需求申请,pvc绑定PV 实现pod存储需求
1、存储创建
2、pv创建
apiVersion: v1
Kind: persistentVolume
metadata:
name: pv2
没有namespace
spec:
nfs:存储类型 底层实际存储类型
capacity: # 存储能力 目前只能设置存储空间的设置
storage:2Gi
accessmodes:#访问模式 用于描述用户应用对存储资源的访问权限,访问权限有
ReadWriteOnce(RWO) 读写权限 但是只能被单个节点挂载,只能被一个pvc挂载
ReadOnlyMany(ROX)只读权限 可以被多个节点挂载
ReadWriteMany(RWX)读写权限 可以被多个节点挂载
persistentVolumeReclaimPollcy
#当pv不再使用之后,对其的处理方式,目前支持三种
Retain 保留 保留数据,需要管理员手动清理数据
Recycle 回收 清除PV中的数据,效果相当于执行 rm -rf /rr/*
Delete(删除) 与PV相连的后端存储完成volume的删除操作
常见于云服务商的存储服务
storageClassName: #存储类别 # PV可以通过指定一个存储类别,具有特定类别的PV只能与请求该类别的PV进行绑定
status:
一个PV的生命周期
(Available)可用 还未被任何PVC绑定
(Bond)已绑定
(Releaded)已释放 PVC被删除,但是资源还未被集群重新声明
(Failed)失败 PV的自动回收失败
NFS:
server:xxx
path:/sss
3、pvc创建
apiVersion: v1
Kind: persistentVolumeClass
metadata:
name: pvc
namespace:dev
spec:
accessMode:访问模式 用户应用对存储资源的访问权限 与PV一致
selector:采用标签对PV选择 通过Lable
storageClassname 存储类别
resource:请求空间
requests:
storage:10Gi
4、修改pod配置使用pvc
添加
volumes:
- name: volume
persistentVolumeClass:
claimNmae:pvc1
readOnly:false #fase 可读可写
配置存储介绍–configmap**
NFS
hostpath方法node一旦故障了,pod会转移到其他节点上了,就会出现问题,此时需要准备单独的网络存储系统常用的有NFS,CIFS
NFS是一个网络文件存储系统可以搭建一台NFS服务器,然后将pod中的存储直接连接到nfs系统上,这样的话,无论pod在节点这么转移,只要node跟nfs的对接没问题,数据就可以成功访问
volumes:声明volume name为logs-volume 类型为emptyDIR
- name:logs-volume
nfs:
server: 192.168.109.11
path:/nfs
高级存储:PV PVC
PV是持久话卷的意思,是对底层的共享存储的一种抽象,一般情况下PV有kubernetes管理进行创建和配置 它与底层具体的共享存储技术有关,并通过插件完成与共享存储的对象
PVC 是持久卷声明的意思,是用户对应存储需求的一种声明,PVC其实就是用户向kubernetes系统发出的一种资源需求申请,pvc绑定PV 实现pod存储需求
1、存储创建
2、pv创建
apiVersion: v1
Kind: persistentVolume
metadata:
name: pv2
没有namespace
spec:
nfs:存储类型 底层实际存储类型
capacity: # 存储能力 目前只能设置存储空间的设置
storage:2Gi
accessmodes:#访问模式 用于描述用户应用对存储资源的访问权限,访问权限有
ReadWriteOnce(RWO) 读写权限 但是只能被单个节点挂载,只能被一个pvc挂载
ReadOnlyMany(ROX)只读权限 可以被多个节点挂载
ReadWriteMany(RWX)读写权限 可以被多个节点挂载
persistentVolumeReclaimPollcy
#当pv不再使用之后,对其的处理方式,目前支持三种
Retain 保留 保留数据,需要管理员手动清理数据
Recycle 回收 清除PV中的数据,效果相当于执行 rm -rf /rr/*
Delete(删除) 与PV相连的后端存储完成volume的删除操作
常见于云服务商的存储服务
storageClassName: #存储类别 # PV可以通过指定一个存储类别,具有特定类别的PV只能与请求该类别的PV进行绑定
status:
一个PV的生命周期
(Available)可用 还未被任何PVC绑定
(Bond)已绑定
(Releaded)已释放 PVC被删除,但是资源还未被集群重新声明
(Failed)失败 PV的自动回收失败
NFS:
server:xxx
path:/sss
3、pvc创建
apiVersion: v1
Kind: persistentVolumeClass
metadata:
name: pvc
namespace:dev
spec:
accessMode:访问模式 用户应用对存储资源的访问权限 与PV一致
selector:采用标签对PV选择 通过Lable
storageClassname 存储类别
resource:请求空间
requests:
storage:10Gi
4、修改pod配置使用pvc
添加
volumes:
- name: volume
persistentVolumeClass:
claimNmae:pvc1
readOnly:false #fase 可读可写
配置存储
configmap secret:是一种特殊的存储卷,作用是用来存储配置信息的,创建后修改pod增加该信息即可使用
社区:https://kubernetes.io/zh-cn/docs/home/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 照片去水印工具有哪些值得一试?去水印效果好不好
- 关于edge浏览器以及插件推荐
- Python列表与元组
- W5500-EVB-Pico评估版介绍
- 【OpenCV学习笔记12】- 更改颜色空间
- vant图标丢失问题
- 7+PPI+机器学习+实验,非肿瘤结合建模筛选生物标志物,可升级
- Spark发送到Kafka的数据出现重复问题解决方案
- Python算法例19 创建最大数
- 地方债务余额数据,Shp、excel格式,2008-2020年,含公共财政收入、支出、负债率等多个字段