多级缓存(nginx本地缓存、JVM进程缓存、redis缓存)
发布时间:2024年01月16日
文章目录
整体示意图
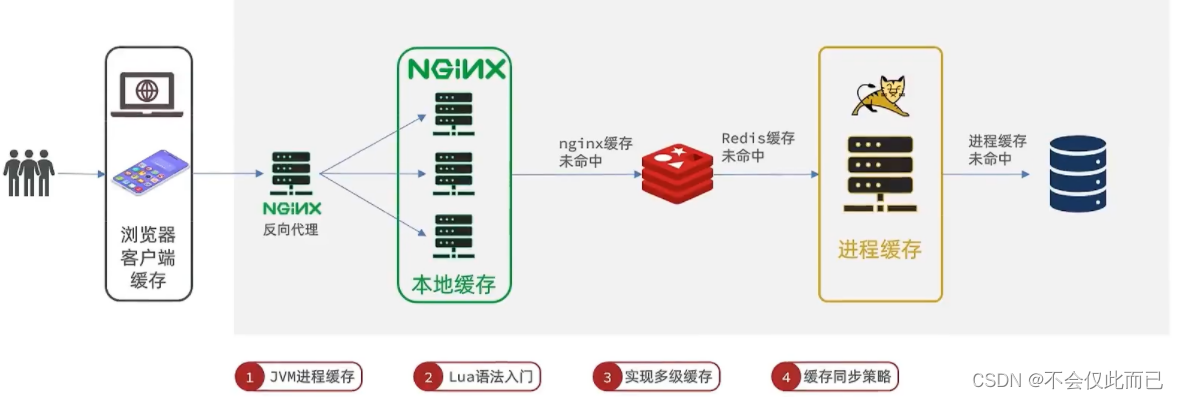
1.nginx缓存
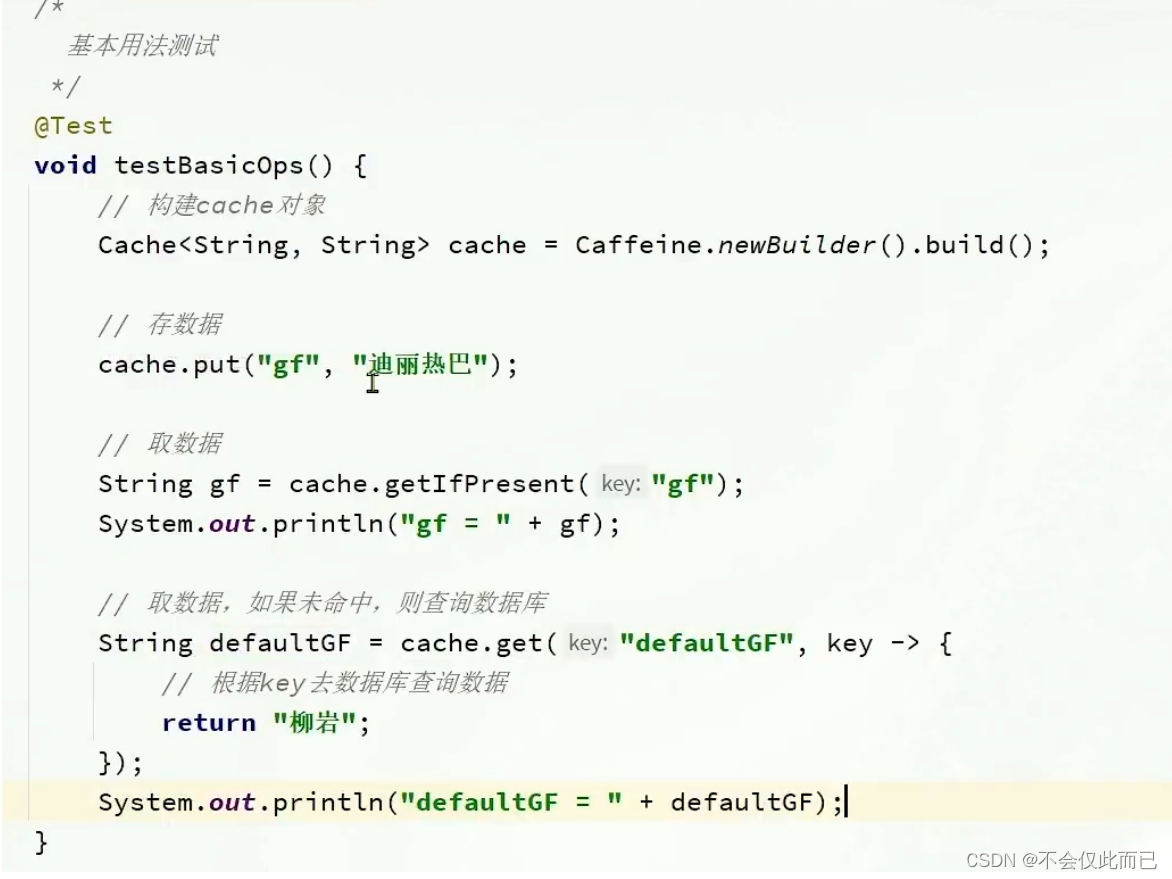
2.进程缓存
Caffeine示例

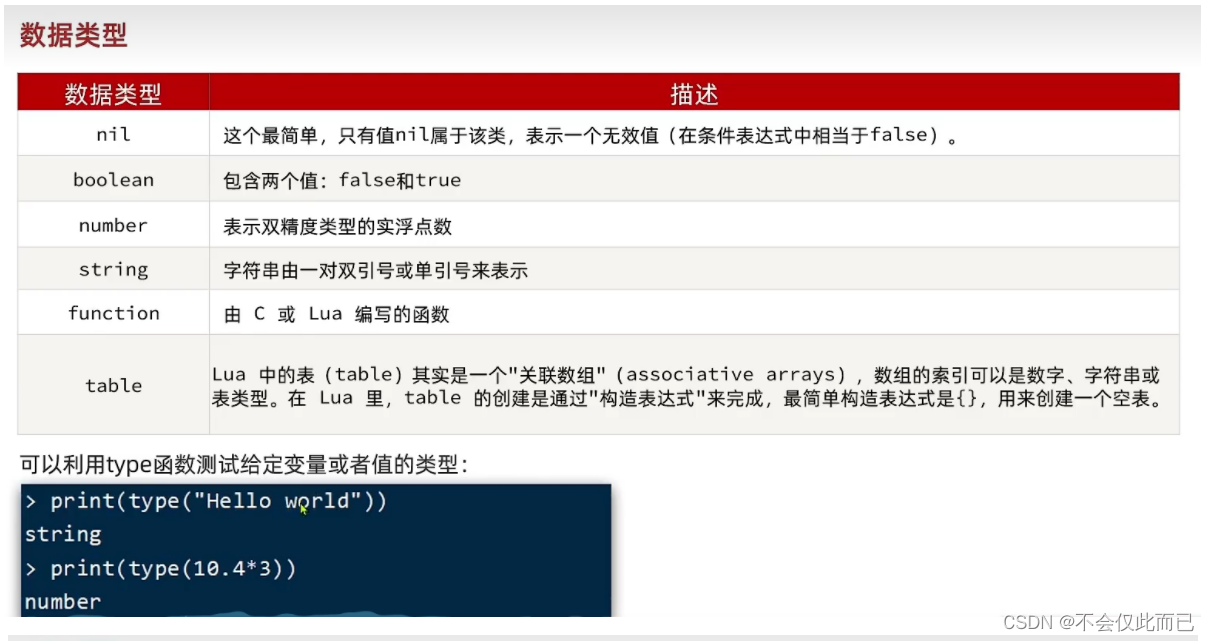
3.Lua语法(为了在nginx中做编程)
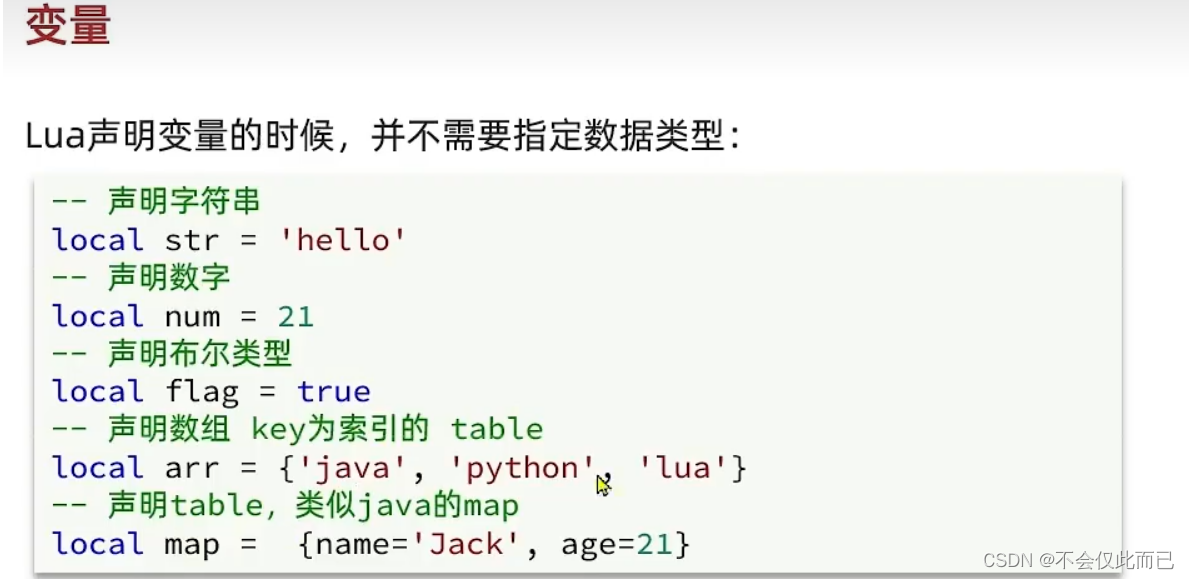



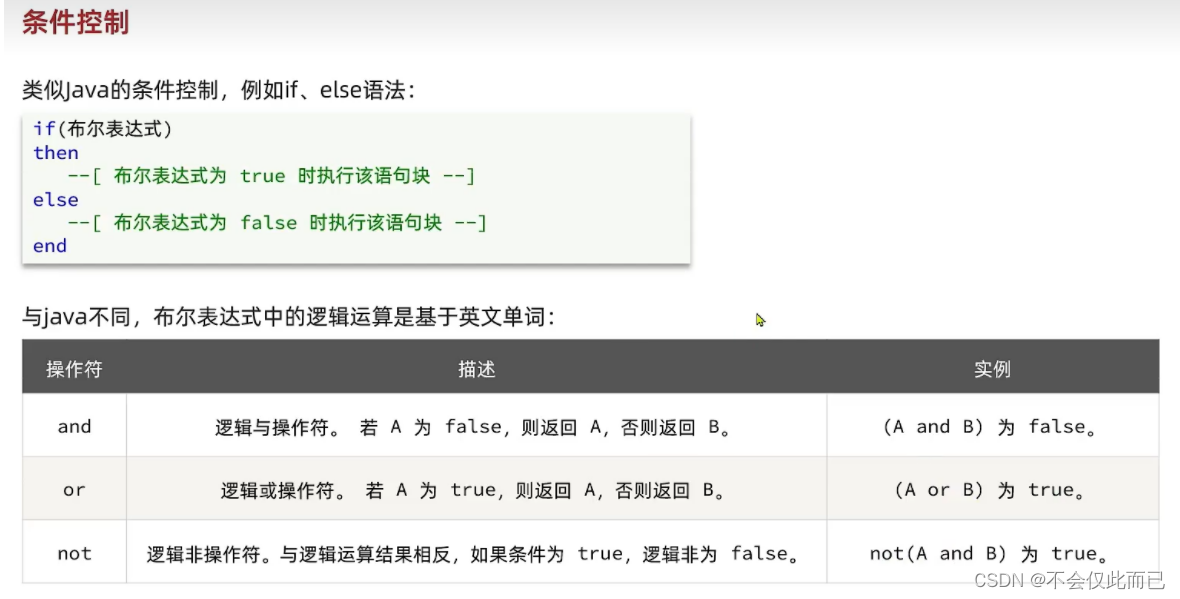
4.OpenResty

5.封装向Tomcat发送的Http请求,获取数据
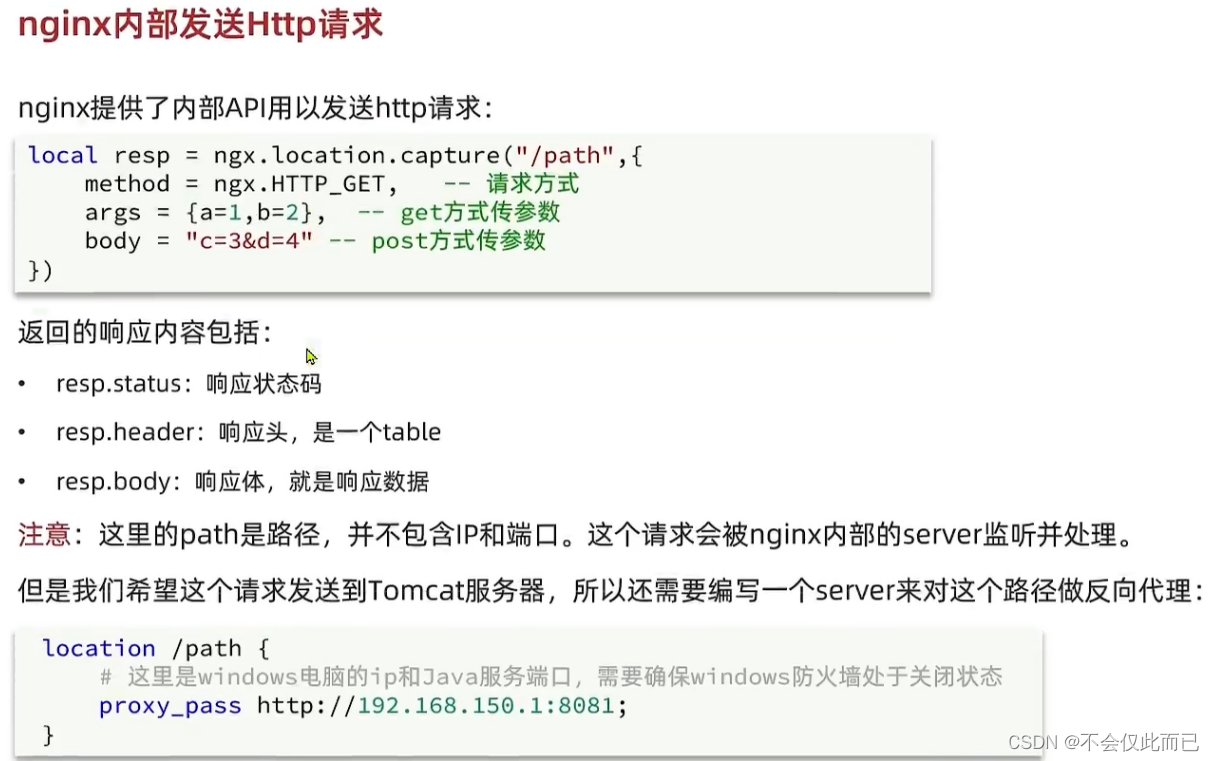
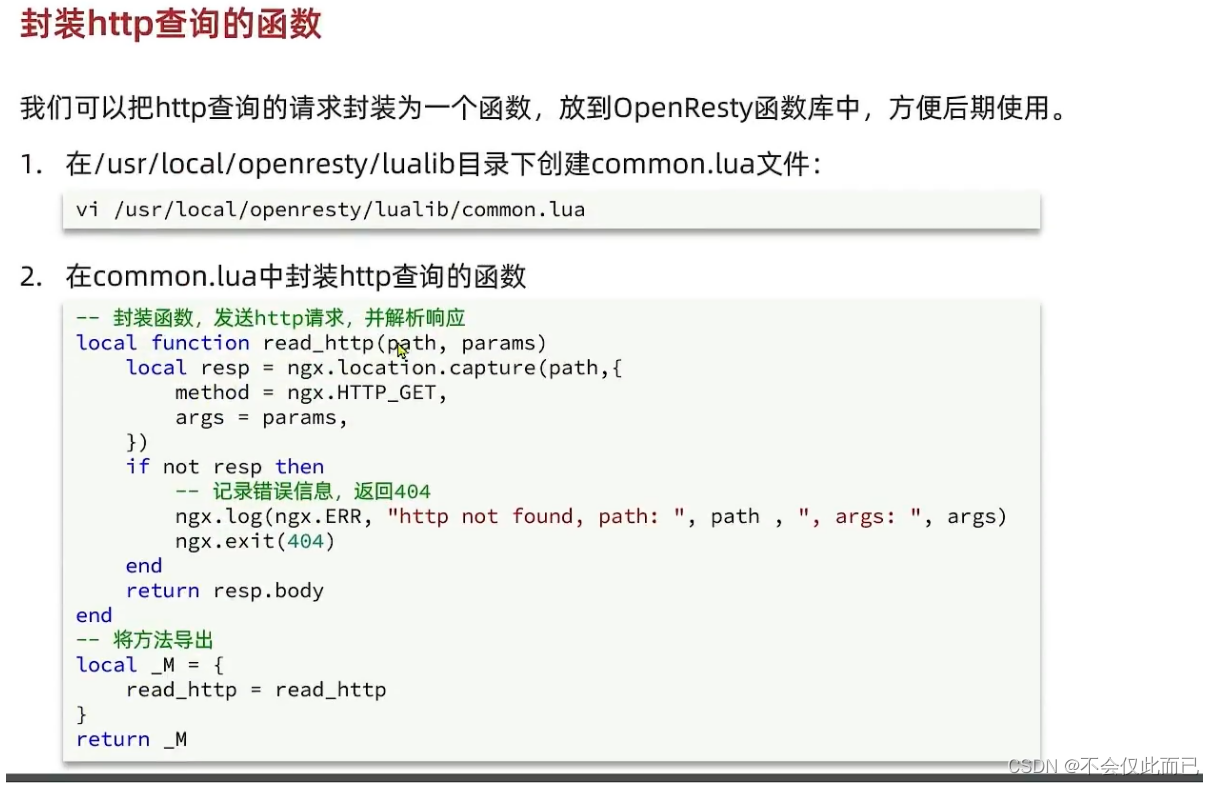
封装完函数之后,我们对nginx.conf进行修改(请求进来之后会去寻找item.lua)
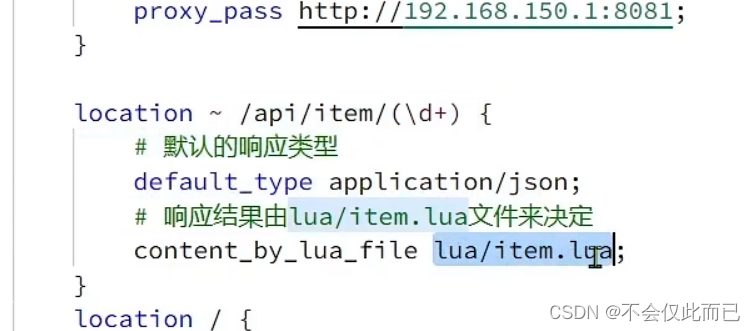
item.lua文件内容
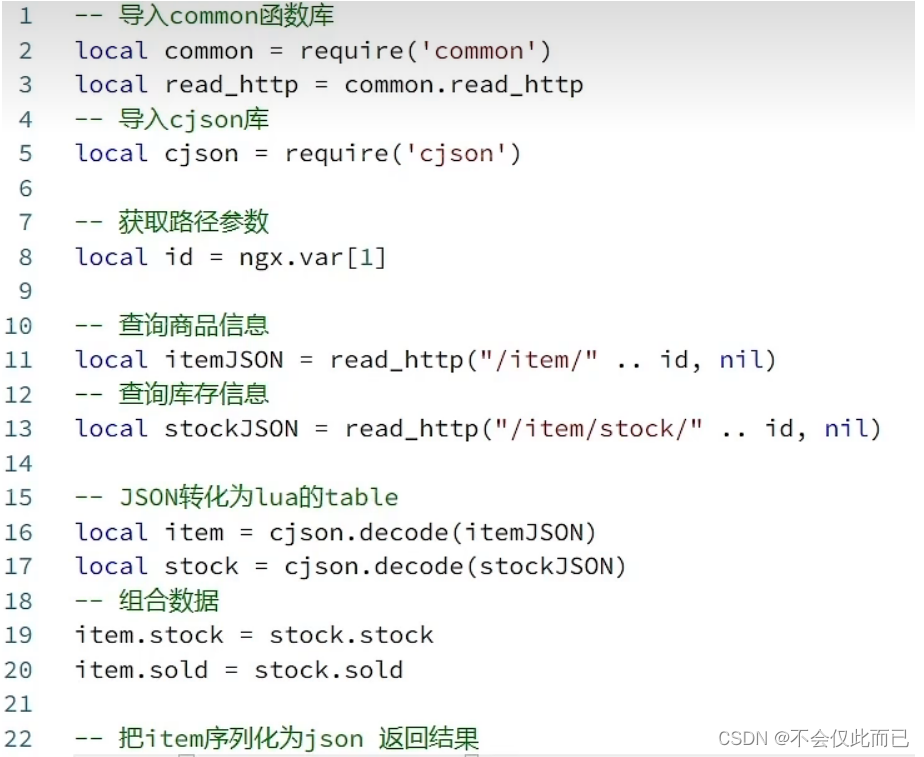
上面的item.lua文件中需要进行拼接数据,我们需要JSON结果处理

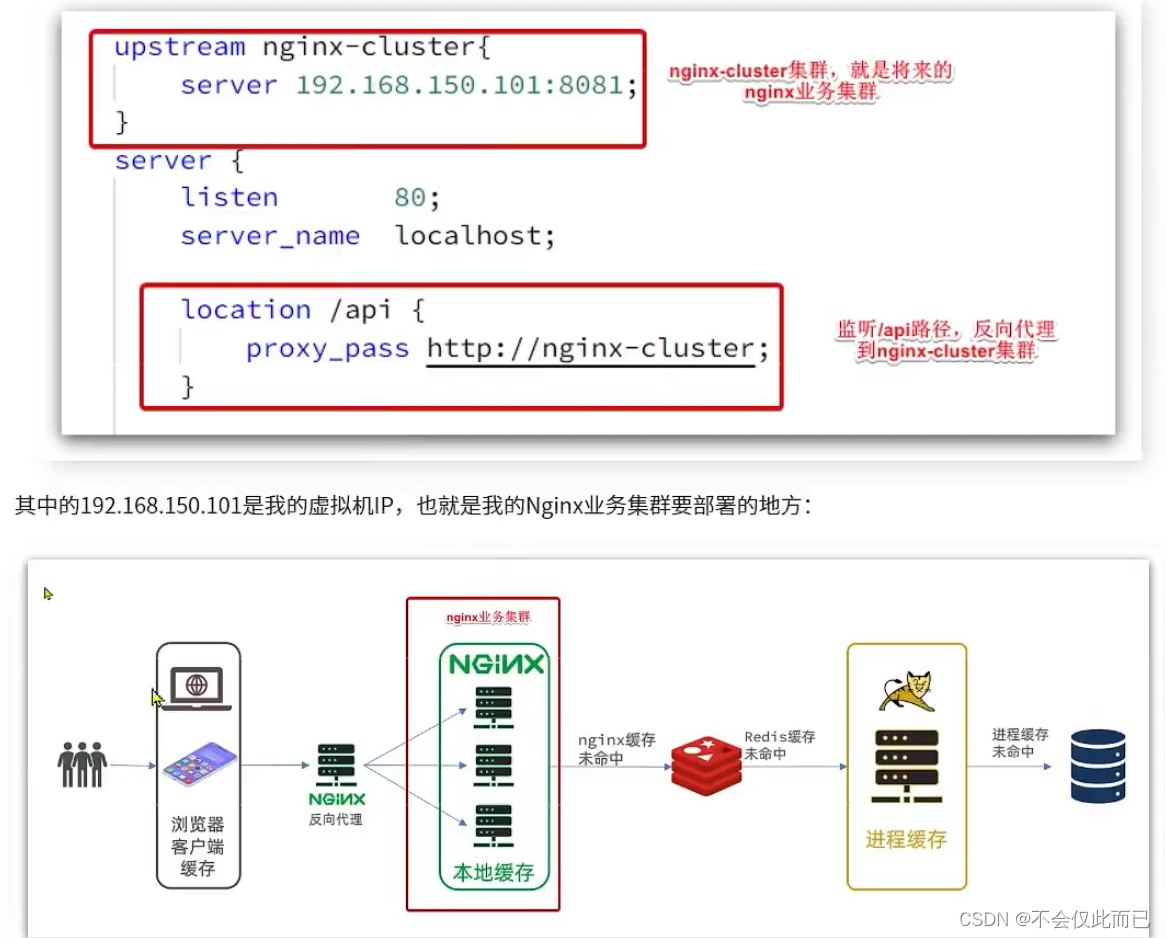
6.Tomcat集群的负载均衡
在实际生产中tomcat是肯定以集群的方式存在
当我们修改nginx.conf发送请求为集群的时候,如下图

这个时候存在一个问题,集群的负载均衡算法是轮询,会导致tomcat进程缓存产生浪费,举个例子
- 假如现在有两台Tomcat服务器,一台端口为8080,一台端口为8081
- 进行访问,查询id为1的信息,第一次查询8080端口的tomcat服务器,此时8080端口的tomcat服务器上有id为1信息的缓存,但是当我们再次查询id为1的信息,因为轮询的机制,会查询8081端口的tomcat服务器,但是id为1的进程缓存在8080端口的tomcat服务器上,并且进程缓存在集群之间不会共享,这就导致会发生一种情况,有多少tomcat服务器,就会有多少份进程缓存,这对资源是一种极大的浪费
解决方法:更换负载均衡算法为 hash $request_uri

这种负载均衡算法是通过对id值进行hash运算然后进行对tomcat服务器数量取余来判断访问哪台tomcat服务器,这样就保证了同一个id访问同一个tomcat服务器
7.redis缓存
两个问题

缓存预热代码(逻辑代码根据自己的更换即可)
public class CaffeineConfig implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService itemStockService;
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void afterPropertiesSet() throws Exception {
// 初始化缓存
// 1.查询商品信息
List<Item> itemList = itemService.list();
// 2.放入缓存
for (Item item : itemList) {
// 2.1 item序列化为JSON
String json = MAPPER.writeValueAsString(item);
// 2.2 存入redis
redisTemplate.opsForValue().set("item:id:" + item.getId(),json);
}
// 3.查询商品库存信息
List<ItemStock> stockList = itemStockService.list();
// 2.放入缓存
for (ItemStock stock : stockList) {
// 2.1 item序列化为JSON
String json = MAPPER.writeValueAsString(stock);
// 2.2 存入redis
redisTemplate.opsForValue().set("item:stock:id:" + stock.getId(),json);
}
}
}
API简介
InitializingBean
- 一定要实现其中的afterPropertiesSet()方法
- 该方法会在创建Bean之后执行,也就是项目启动的时候执行,也就可以实现缓存预热效果了
ObjectMapper
- spring自带的json序列化工具
8.查询Redis缓存



9.Nginx本地缓存

文章来源:https://blog.csdn.net/qq_62669235/article/details/135622560
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- html火焰文字特效
- 系统设计 - 我们如何通俗的理解那些技术的运行原理 - 第六部分:开发运维
- 嵌入式(八)电源低功耗管理 | 五种运行模式 模式转换 睡眠定时器唤醒
- 除法器原理之恢复余数法
- 【JDK新特性】JDK和Springboot各版本新特性介绍
- 使用logrotate对日志文件进行转储
- 基于Python的短视频APP大学生用户数据分析预测
- Python集合(set)
- 基于JAVA的木马文件检测系统 开源项目
- 解析二二复制-----白酒厂家实现潮流大爆发,月销量破千万