Python基础知识总结2——python中的字符串
python字符串
字符串基本特点
1 字符串的本质是:字符序列。
2 Python不支持单字符类型,单字符也是作为一个字符串使用的。
??Python的字符串是不可变的,我们无法对原字符串做任何修 改。但,可以将字符串的一部分复制到新创建的字符串,达到 “看起来修改”的效果
空字符串和len()函数
Python允许空字符串的存在,不包含任何字符且长度为0。例如:
c = ''
print(len(c)) #结果:0
len()用于计算字符串含有多少字符。例如:
d = 'abcdef'
len(d) #结果:6
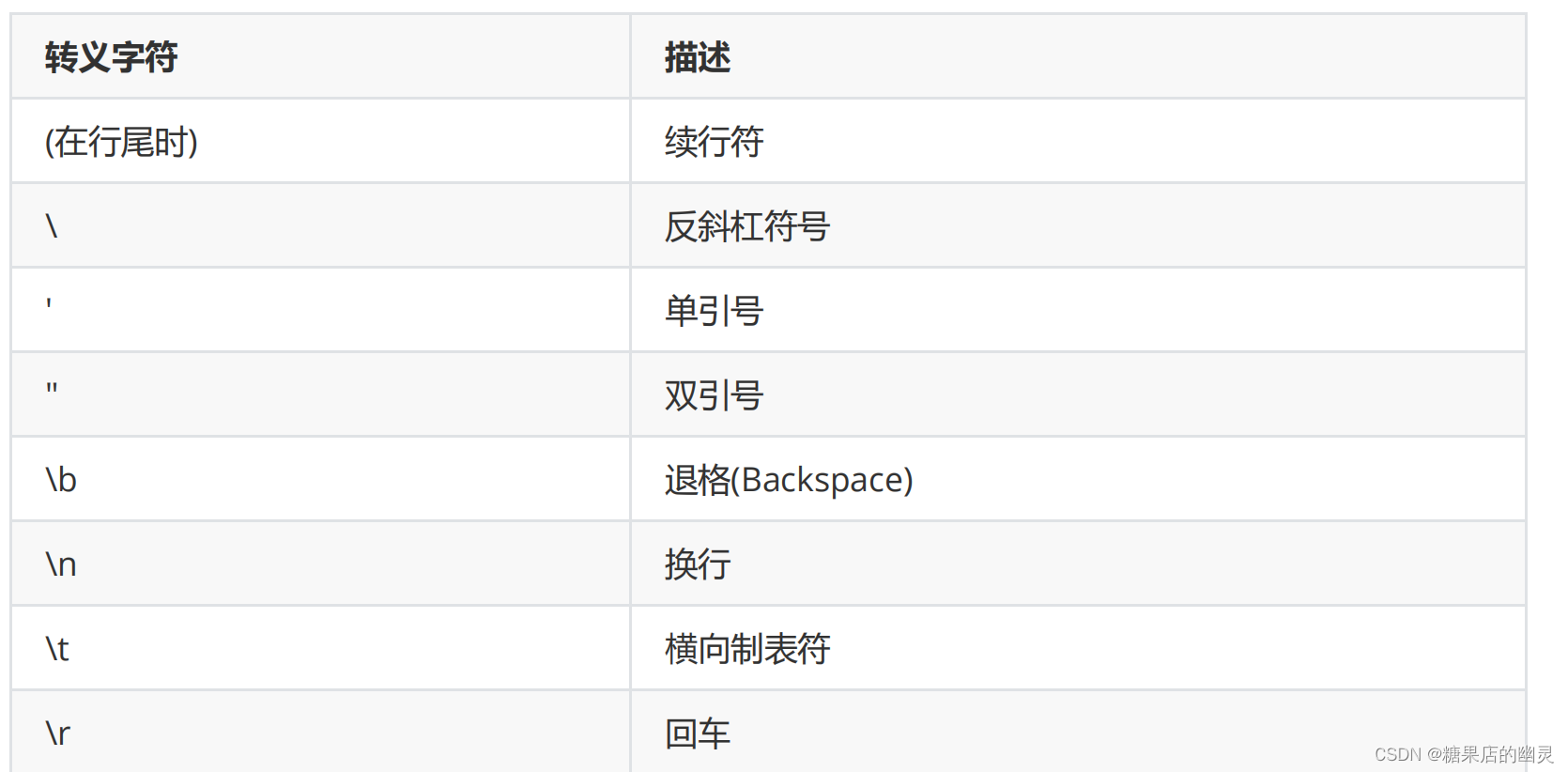
转义字符
我们可以使用 +特殊字符 ,实现某些难以用字符表示的效果。比如:换
行等。常见的转义字符有这些:
字符串拼接
可以使用 + 将多个字符串拼接起来。例如: ’aa’+ ’bb’ 结果
是 ’aabb’
- 如果 + 两边都是字符串,则拼接。
- 如果 + 两边都是数字,则加法运算
- 如果 + 两边类型不同,则抛出异常
可以将多个字面字符串直接放到一起实现拼接。例
如: ’aa’’bb’ 结果是 ’aabb’
a = 'sxt'+'gaoqi' #结果是:'sxtgaoqi'
b = 'sxt''gaoqi' #结果是:'sxtgaoqi'
字符串复制
使用*可以实现字符串复制a = 'Sxt'*3 #结果:'SxtSxtSxt'
不换行打印
我们前面调用print时,会自动打印一个换行符。有时,我们不想换
行,不想自动添加换行符。我们可以自己通过参数end = “任意字符
串”。实现末尾添加任何内容:
print("sxt",end=' ')
print("sxt",end='##')
print("sxt")
从控制台读取字符串
myname = input("请输入名字:")
print("您的名字是:"+myname)
replace() 实现字符串替换
字符串是“不可改变”的,我们通过[]可以获取字符串指定位置的字
符,但是我们不能改变字符串。我们尝试改变字符串中某个字符,
发现报错了
>>> a = 'abcdefghijklmnopqrstuvwxyz'
>>> a
'abcdefghijklmnopqrstuvwxyz'
>>> a[3]='高'
Traceback (most recent call last):
File "<pyshell#94>", line 1, in <module>
a[3]='高'
TypeError: 'str' object does not support item
assignment
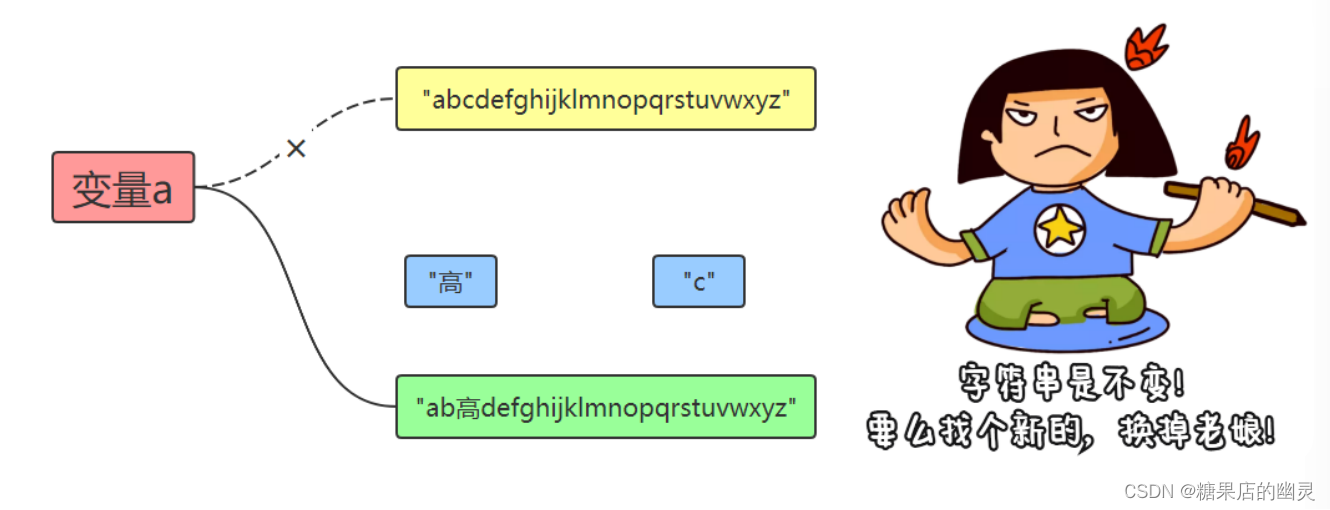
字符串不可改变。但是,我们确实有时候需要替换某些字符。这
时,只能通过创建新的字符串来实现。
整个过程中,实际上我们是创建了新的字符串对象,并指向了变量
a,而不是修改了以前的字符串。 内存图如下:
str()实现数字转型字符串
str()可以帮助我们将其他数据类型转换为字符串。例如:
>>> a = 'abcdefghijklmnopqrstuvwxyz'
>>> a
'abcdefghijklmnopqrstuvwxyz'
>>> a = a.replace('c','高')
'ab高defghijklmnopqrstuvwxyz'
整个过程中,实际上我们是创建了新的字符串对象,并指向了变量
a,而不是修改了以前的字符串。 内存图如下:

str()实现数字转型字符串
str()可以帮助我们将其他数据类型转换为字符串。例如:
a = str(5.20) #结果是:a = ‘5.20’
b = str(3.14e2) #结果是:b = ’314.0’
c = str(True) #结果是:c = ‘True’
使用[]提取字符
字符串的本质就是字符序列,我们可以通过在字符串后面添加[],
在[]里面指定偏移量,可以提取该位置的单个字符。
1 正向搜索:
最左侧第一个字符,偏移量是0,第二个偏移量是1,以此类推。
直到len(str)-1为止。
2 反向搜索:
最右侧第一个字符,偏移量是-1,倒数第二个偏移量是-2,以此
类推,直到-len(str)为止。
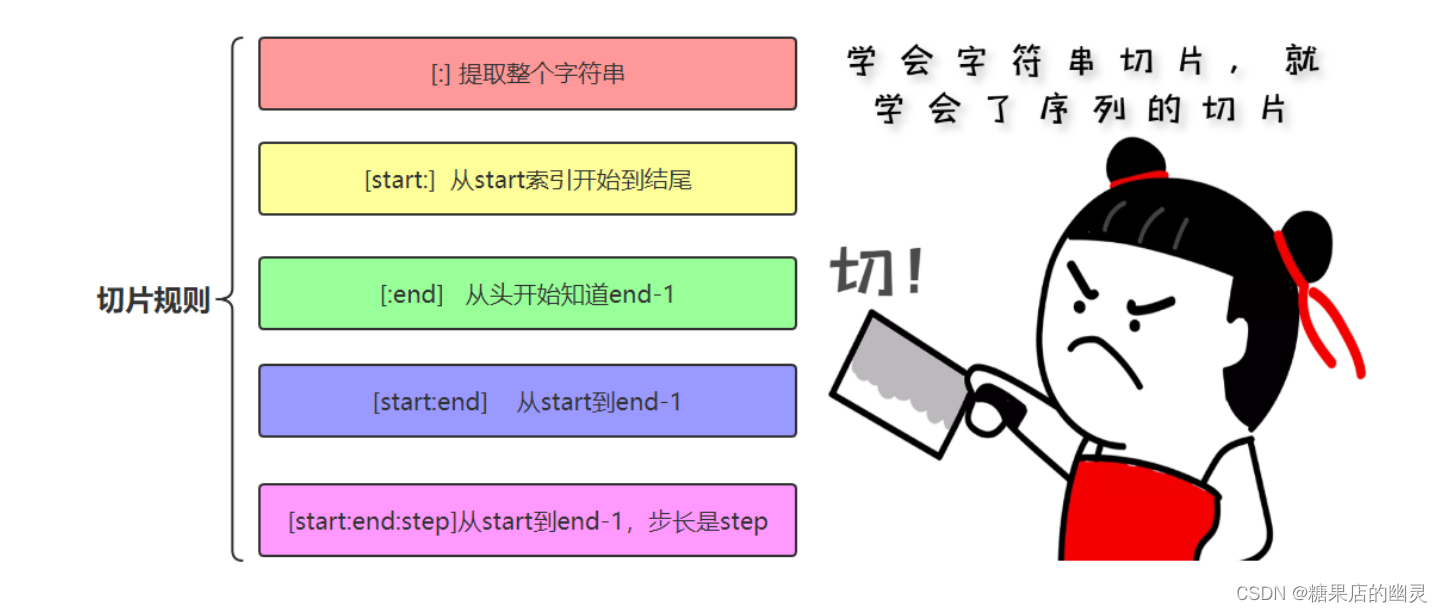
字符串切片slice操作

split()分割和join()合并
split()可以基于指定分隔符将字符串分隔成多个子字符串(存储到列
表中)。如果不指定分隔符,则默认使用空白字符(换行符/空格/制表
符)。示例代码如下:
>>> a = "to be or not to be"
>>> a.split()
['to', 'be', 'or', 'not', 'to', 'be']
>>> a.split('be')
['to ', ' or not to ', '']
join()的作用和split()作用刚好相反,用于将一系列子字符串连接起
来。示例代码如下:
>>> a = ['sxt','sxt100','sxt200']
>>> '*'.join(a)
'sxt*sxt100*sxt200'
拼接字符串要点:
使用字符串拼接符 + ,会生成新的字符串对象,因此不推荐使
用 + 来拼接字符串。推荐使用 join 函数,因为 join 函数在拼接字
符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一
次对象。
字符串驻留机制和字符串比较
字符串驻留:常量字符串只保留一份。
c = "dd#"
d = "dd#"
print(c is d) #True
字符串比较和同一性
我们可以直接使用 == != 对字符串进行比较,是否含有相同的字符。
我们使用 is not is ,判断两个对象是否同一个对象。比较的是对象的
地址,即 id(obj1) 是否和 id(obj2) 相等。
成员操作符判断子字符串
in not in 关键字,判断某个字符(子字符串)是否存在于字符串中。
"ab" in "abcdefg" #true
字符串常用方法汇总
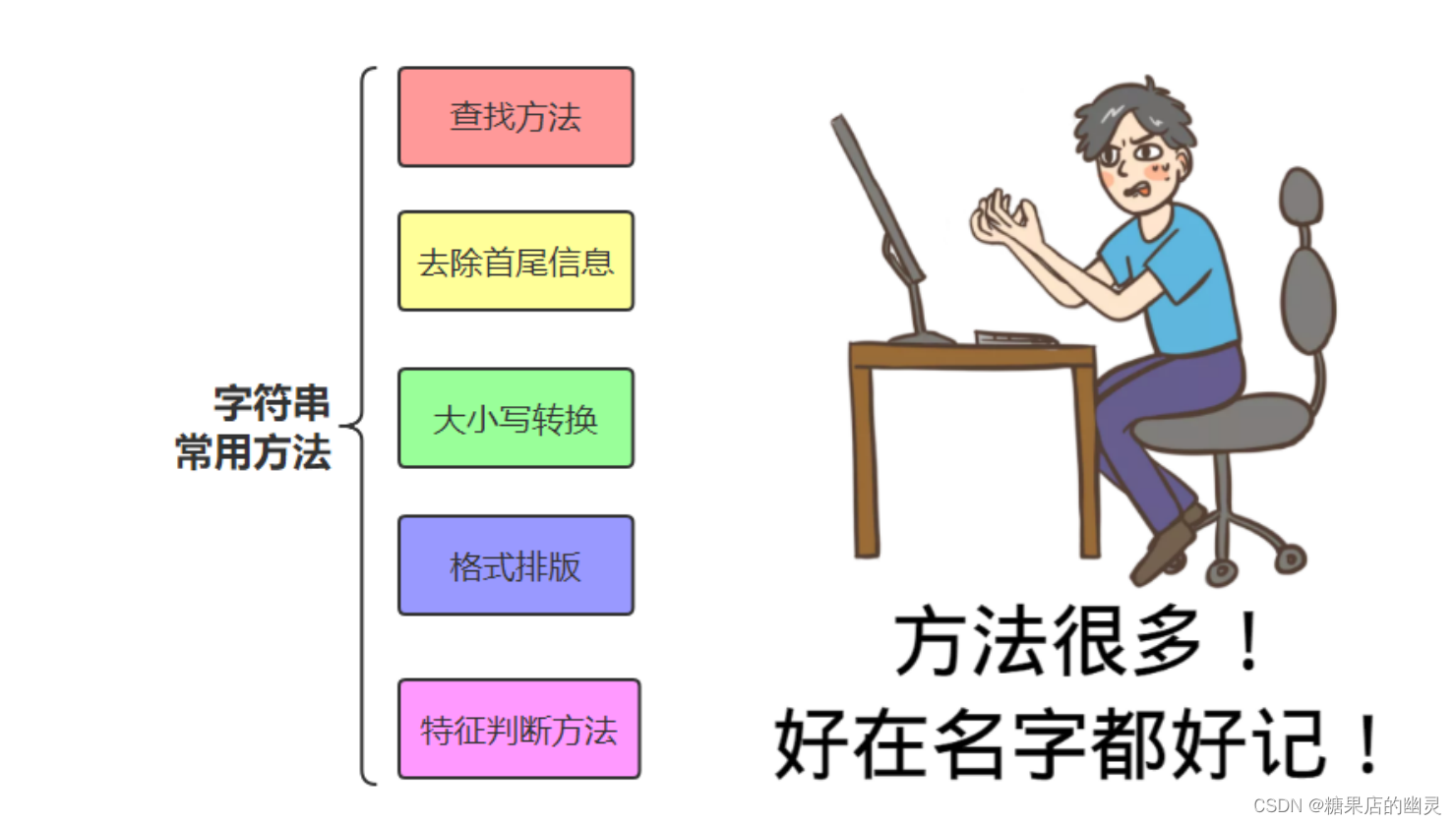
常用查找方法
a='''我是高淇,我在北京尚学堂科技上班。我的儿子叫高洛
希,他6岁了。我是一个编程教育的普及者,希望影响6000万
学习编程的中国人。我儿子现在也开始学习编程,希望他18岁
的时候可以超过我'''
去除首尾信息
我们可以通过strip()去除字符串首尾指定信息。通过lstrip()去除字符
串左边指定信息,rstrip()去除字符串右边指定信息。
大小写转换
编程中关于字符串大小写转换的情况,经常遇到。我们将相关方法
汇总到这里。为了方便学习,先设定一个测试变量:
a = "gaoqi love programming, love SXT"

格式排版
center() 、 ljust() 、 rjust() 这三个函数用于对字符串实现排版。示例如
下:
>>> a="SXT"
>>> a.center(10,"*")
'***SXT****'
>>> a.center(10)
' SXT '
>>> a.ljust(10,"*")
'SXT*******'
特征判断方法
1 isalnum() 是否为字母或数字
2 isalpha() 检测字符串是否只由字母组成(含汉字)
3 isdigit() 检测字符串是否只由数字组成
4 isspace()检测是否为空白符
5 isupper() 是否为大写字母
6 islower() 是否为小写字母
字符串的格式化
format() 基本用法
基本语法是通过 {} 和 : 来代替以前的 % 。
format() 函数可以接受不限个数的参数,位置可以不按顺序。
可以通过{索引}/{参数名},直接映射参数值,实现对字符串的
格式化,非常方便。
>>> a = "名字是:{0},年龄是:{1}"
>>> a.format("高淇",18)
'名字是:高淇,年龄是:18'
>>> a.format("高希希",6)
'名字是:高希希,年龄是:6'
>>> b = "名字是:{0},年龄是{1}。{0}是个好小伙"
>>> b.format("高淇",18)
'名字是:高淇,年龄是18。高淇是个好小伙'
>>> c = "名字是{name},年龄是{age}"
>>> c.format(age=19,name='高淇')
'名字是高淇,年龄是19'
填充与对齐
填充常跟对齐一起使用
^ 、 < 、 > 分别是居中、左对齐、右对齐,后面带宽度 2
: 号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
>>> "{:*>8}".format("245")
'*****245'
>>> "我是{0},我喜欢数字{1:*^8}".format("高
淇","666")
'我是高淇,我喜欢数字**666***'
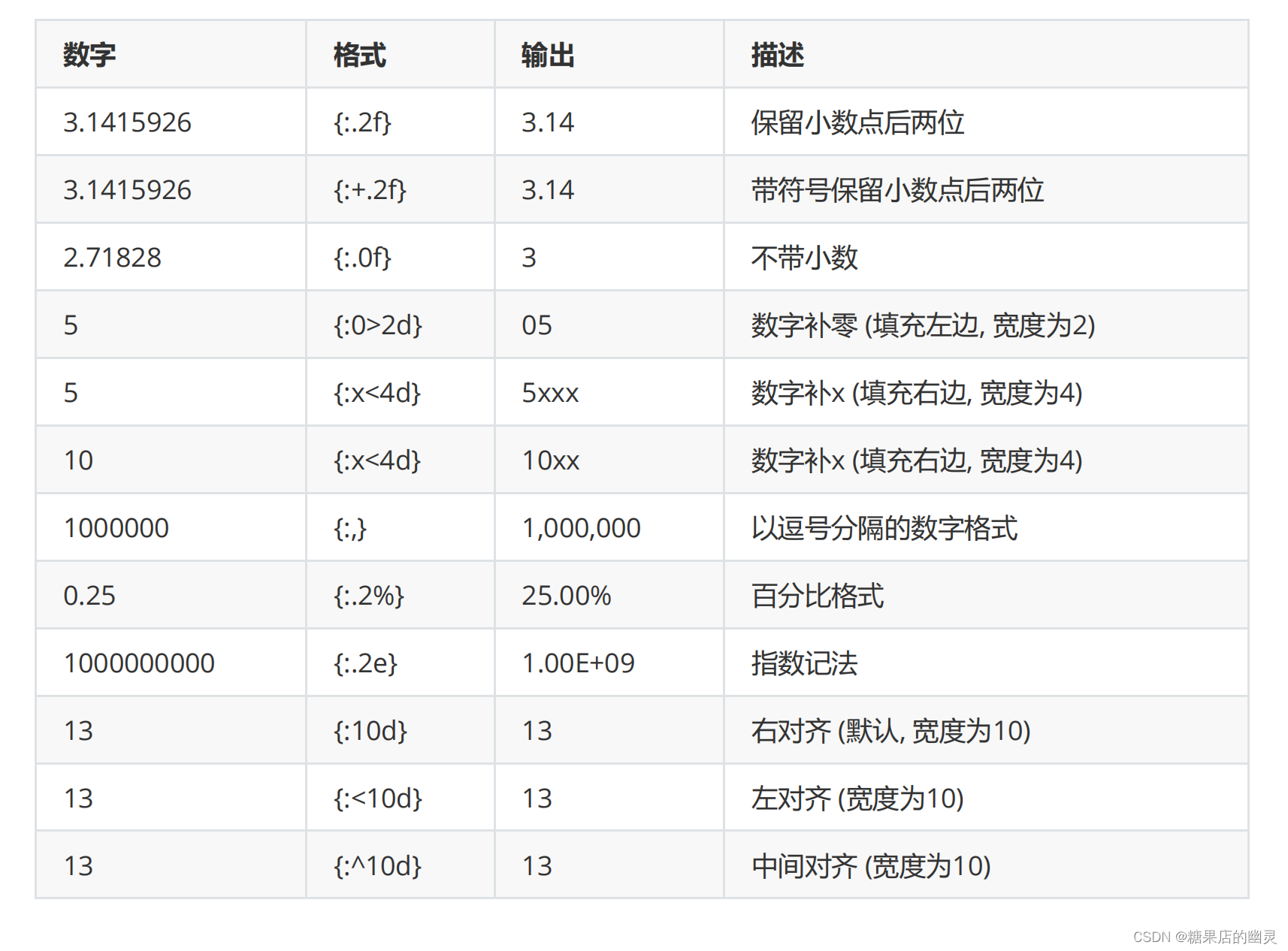
数字格式化
浮点数通过 f ,整数通过 d 进行需要的格式化。案例如下:
a = “我是{0},我的存款有{1:.2f}”
a.format(“高淇”,3888.234342)
‘我是高淇,我的存款有3888.23’
用支持插值的f-string取代C风格的格式字符串与str.format方法
Python 3.6添加了一种新的特性,叫作插值格式字符串(interpolated format string,简称f-string), 新语法特性要求在格式字符串的前面加字母f作为前缀,这跟字母b与字母r的用法类似,也就是分别表示字节形式的字符串与原始的(或者说未经转义的)字符串的前缀。

采用%操作符把值填充到C风格的格式字符串时会遇到许多问题,而且这种写法比较烦琐。str.format方法专门用一套迷你语言来定义它的格式说明符,这套语言给我们提供了一些有用的概念,但是在其他方面,这个方法还是存在与C风格的格式字符串一样的多种缺点,所以我们也应该避免使用它。f-string采用新的写法,将值填充到字符串之中,解决了C风格的格式字符串所带来的最大问题。f-string是个简洁而强大的机制,可以直接在格式说明符里嵌入任意Python表达式。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 力扣面试150题 | 15.三数之和
- 基于YOLOv8的摔倒行为检测系统(Python源码+Pyqt6界面+数据集)
- 【设计模式】迭代器模式
- 学习使用php、js脚本关闭当前页面窗口的方法
- 宠物空气净化器能除毛吗?五款猫用空气净化器测评推荐!
- LinkedList源码
- 第四章 Qt 常用按钮组件
- 预处理详解(#和##运算符、命名约定、#undef??、命令行定义?、条件编译、头文件的包含?)
- Zookeeper-源码启动
- Linux学习笔记(一)