构建中国人自己的私人GPT—与文档对话
先看效果
?
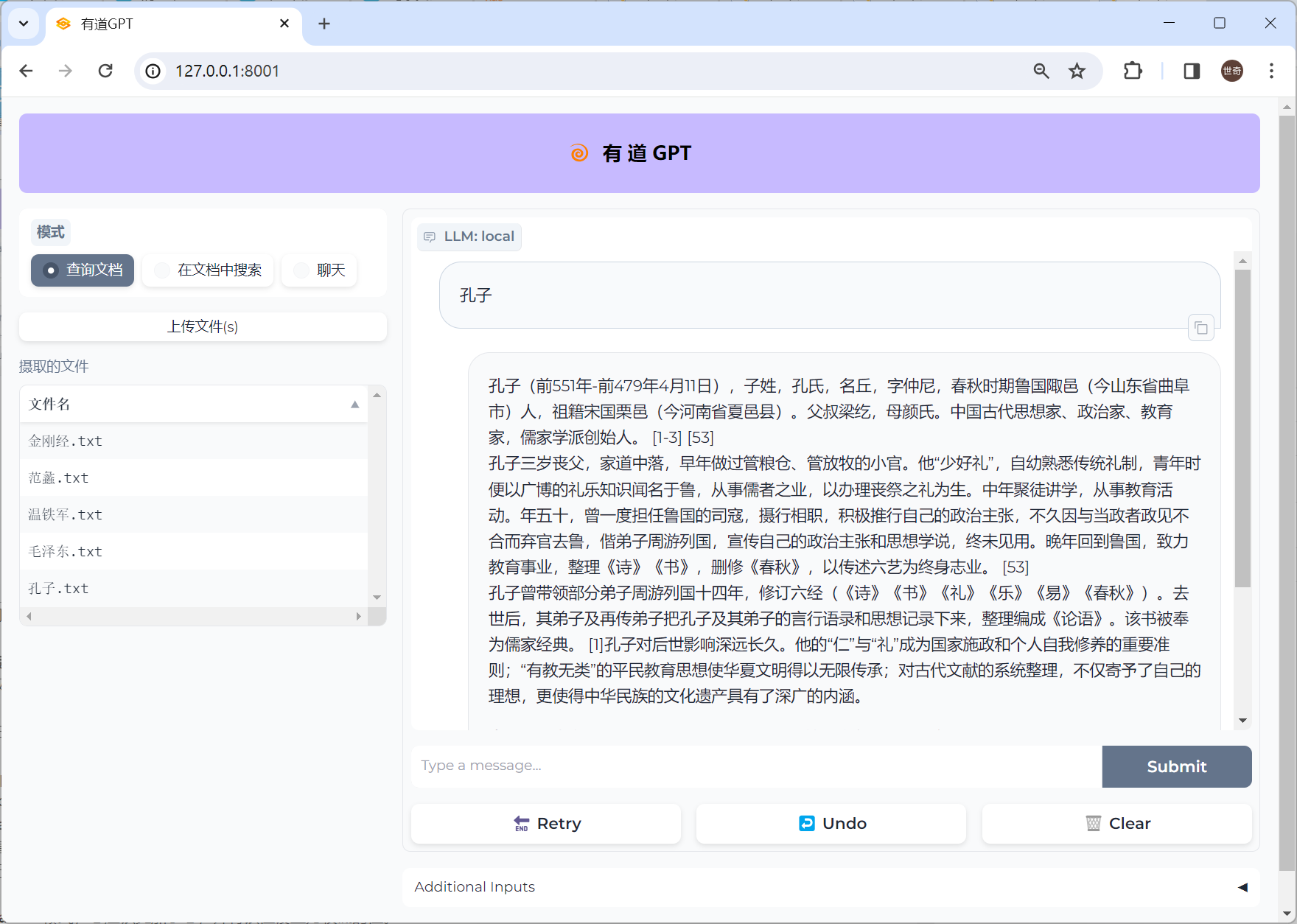
他可以从上传的文件中提取内容作为答案。
上传文件摄取速度
摄取速度取决于您正在摄取的文档数量以及每个文档的大小。为了加快摄取速度,您可以在配置中更改摄取模式。
存在以下摄取模式:
simple:历史行为,一次按顺序摄取一份文档
batch:使用批量读取、解析和嵌入多个文档(批量读取,然后批量解析,然后批量嵌入)
parallel:并行读取、解析和嵌入多个文档。这是本地设置最快的摄取模式。要更改摄取模式,您可以使用embedding.ingest_mode配置值。默认值为simple。
要配置用于并行或批量摄取的工作线程数量,您可以使用embedding.count_workers配置值。如果将此值设置得太高,可能会耗尽内存,因此设置此值时请务必小心。默认值为2。对于batch模式,您可以轻松地将此值设置为 CPU 上可用的线程数,而不会耗尽内存。对于parallel模式,您应该更加小心,并将该值设置为较低的值。
对于想要对硬件施加更多压力的用户来说,以下配置应该足够了:
embedding:
??ingest_mode: parallel
??count_workers: 4
如果您的硬件足够强大,并且您正在加载大量文档,则可以增加工作人员的数量。建议您自己进行测试以找到适合您的硬件的最佳值。
支持的文件格式
privateGPT 默认支持所有包含明文的文件格式(例如,.txt文件.html等)。然而,这些基于文本的文件格式仅被视为文本文件,并且不以任何其他方式进行预处理。
它还支持以下文件格式:
.hwp
.pdf
.docx
.pptx
.ppt
.pptm
.jpg
.png
.jpeg
.mp3
.mp4
.csv
.epub
.md
.mbox
.ipynb
.json
请注意以下细微差别:虽然privateGPT支持这些文件格式,但可能需要在 python 虚拟环境中安装额外的依赖项。例如,如果您尝试提取.epub文件,privateGPT可能会失败,而是会显示一条解释性错误,要求您下载安装此文件格式所需的依赖项。
其他文件格式也可能有效,但它们将被视为纯文本文件(换句话说,它们将作为.txt文件被摄取)。
重置本地文档数据库
在本地设置中运行时,您只需删除local_data文件夹的所有内容(.gitignore 除外)即可删除所有摄取的文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mysql无法连接问题及其环境变量配置
- 【JUnit技术专题】「入门到精通系列」手把手+零基础带你玩转单元测试,让你的代码更加“强壮”(场景化测试篇)
- 封装那些事、0603、0805你知道多少?
- 面试记录一
- 基于java的影视创作论坛系统设计与实现
- php array_diff 比较两个数组bug避坑 深入了解
- 企业如何开展百科营销?需要创建哪些百科词条?
- centos 安装rabbitmq集群
- [每周一更]-(第28期):Windows服务自启动设置
- 2024年,Salesforce从业者的10条发展建议!