python中Selenium+Webdriver实现自动化登录
最近做一项工作,需要自动化登录某个网站并实现爬虫,在此总结分享一下相关的技术。
环境准备
首先我们需要安装python环境,chrome浏览器,selenium包和chromedriver。前两者较为基础,就不多赘述了。下载selenium包在命令行里pip install selenium即可。对于chromedriver,首先在在chrome的设置里查看自己的chrome版本:

然后前往网站http://chromedriver.storage.googleapis.com/index.html,找到与你的chrome版本对应的chromedriver的版本,比如我的就是87.0.4280.88。
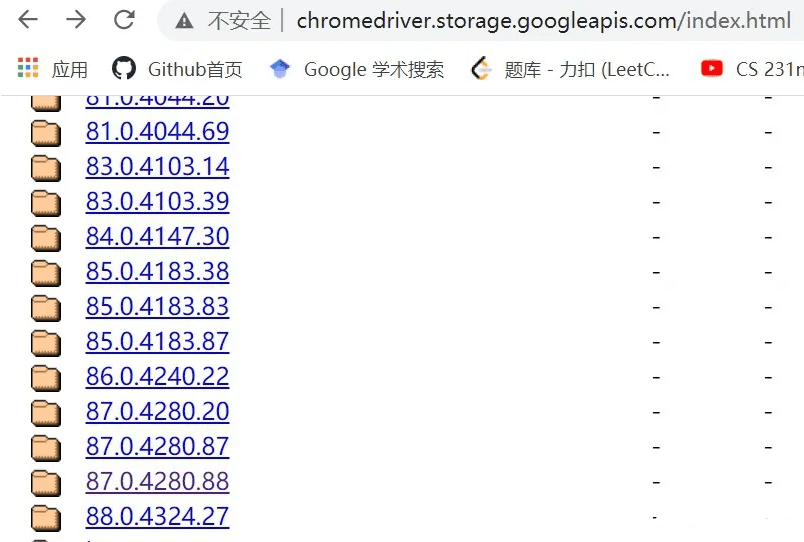 ?
?
下载解压后将解压出的chromedriver.exe文件放在python的安装目录下,如下图所示,这样就完成了selenium+chromedriver的配置,接下来我们就可以编写代码完成自动化登录了。
 ?
?
基础知识
Selenium是ThoughtWorks专门为Web应用而开发的自动化测试工具, 适合进行功能测试、验收测试,同时支持所有基于web的管理任务自动化。主要功能包括:测试与浏览器的兼容性,测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能,创建回归测试检验软件功能和用户需求。
首先介绍一些编写代码所需的基础知识
网页html代码
HTML称为超文本标记语言,是一种标记语言。它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。它的整体结构如下图所示。
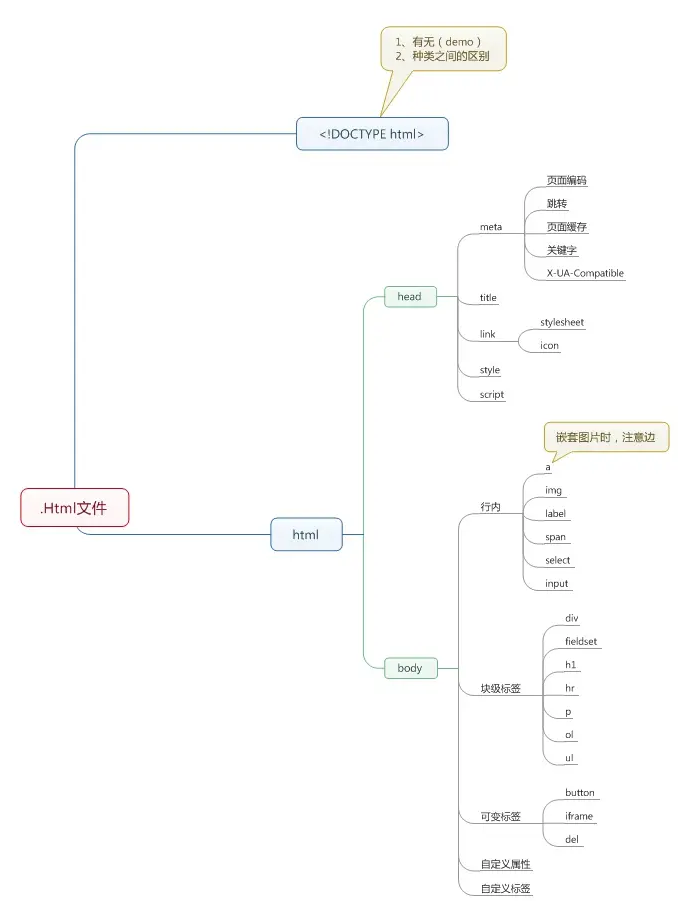
一个示例的HTML代码如下所示:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
可见,HTML的代码由一系列HMTL标签(tag)和字符串构成。代码中的尖括号括起来的文本如<html>、<body>、<a>、<b>就是网页标签,通常成对构成。比如对于<html>,起始标签为<html>,结束标签为</html>。
HTML文件使用网页浏览器打开时,浏览器内置的布局引擎将文档显示成我们看到的样子。对浏览器软件而言,它读取网页文档内容时,同时根据特定标签名构建一个HTML DOM树,这里的DOM是Document Object Model,即文档对象模型。这个树根据读入的HTML文档形成根节点、子节点,如上文档的DOM树结构为:

?
图上看到节点之间有层级关系,如head和body为文档根节点的子节点,head标签内部的title则为其子节点,body内部的div为其子节点,下一级的a和button之间为兄弟节点,与div为父子关系。
如果我们需要登录,或者模拟点击网页上的一些按钮,就需要找到其对应的标签,定位其对应的元素,而这就需要selenium。使用python+selenium来定位网页上的html标签,实现自动化登录。
使用selenium进行元素定位
使用selenium进行元素定位主要有2种方法,一种是直接定位法,也就是直接通过标签的id、class名、tag名、name、link文字、CSS等定位元素。
| 1 2 3 4 5 6 7 8 |
|
比如对应上面的一个html代码片段,如果想定位输入,要怎么定位呢?
- 使用id进行定位:一个页面的id是唯一的(只要id不是动态的)
标准形式:find_element_by_id("id_vaule")
对应上面代码也就是:find_element_by_id("kw")
- 使用class名进行定位:class名可能重复
标准形式:find_element_by_class_name("class_name")
对应上面代码也就是:find_element_by_class_name("s_ipt")
- 使用标签名定位:最容易重复
标准形式:find_element_by_tag_name("tag_name")
对应上面代码也就是:find_element_by_class_name("input")
- 使用name定位:name可能重复
标准形式:find_element_by_name("name")
对应上面代码也就是:find_element_by_name("wd")
- 使用link文字定位:(以上文百度的代码为例)
标准形式:find_element_by_link_text("text_value")
对应上面代码也就是:find_element_by_link_text("百度一下")
除了直接定位,还有一种方法更万能,但是也更复杂,它就是find_element_by_xpath()方法,它有很多种定位方式。
属性定位
find_element_by_xpath("//标签名[@属性='属性值']")
| 属性 | 实例 |
|---|---|
| id属性 | find_element_by_xpath("//input[@id='kw']") |
| class属性 | find_element_by_xpath("//input[@class='s_ipt']") |
| name属性 | find_element_by_xpath("//input[@name='wd']") |
| maxlength属性 | find_element_by_xpath("//input[@maxlength='255']") |
标签定位
如指所有input标签元素:find_element_by_xpath("//input")
内容定位
| 1 2 3 4 5 |
|
组合定位
find_element_by_xpath("//input[@class='s_ipt' and @name='wd']") 指的是input标签下id属性为kw且name属性为wd的元素
自顶向下路径选择
xpath()顾名思义,它是一个path,有的时候你不能直接定位到一个元素的标签,你就要从一个可以定位的根节点一路定位下来。比如//input[@name='wd']/li[3]/input/a,这个路径指的是你先定位到name属性为wd的input标签,在定位到它的第3个li子节点,接着是下面的input子节点,最后是input下的a子节点。通过这样的一种方式来最终定位到需要的元素,值得注意的是,标号是从1开始计数,不是从0开始计数。
代码编写
学习完基础知识,下面以一个实例的方式来介绍如何进行自动化登录:“自动化登陆北航vpn网站并进入任意网页”(原理都是一致的,大家可以选择自己学校的校园网或一些其他网站来练习)
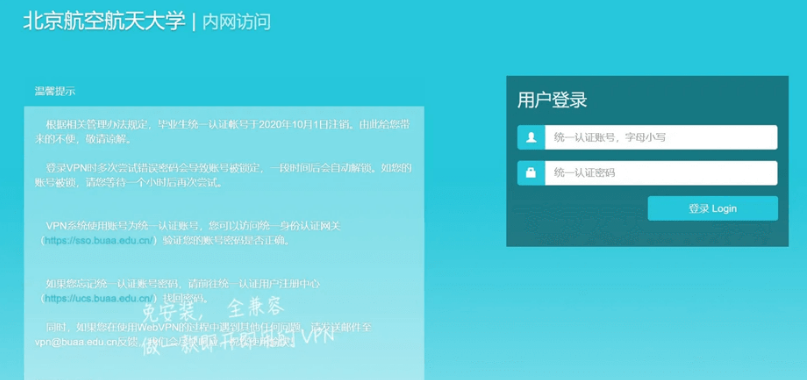
首先我们获得北航vpn的登录网页:
| 1 2 |
|
这样我们就打开了登陆界面,是这样子的:
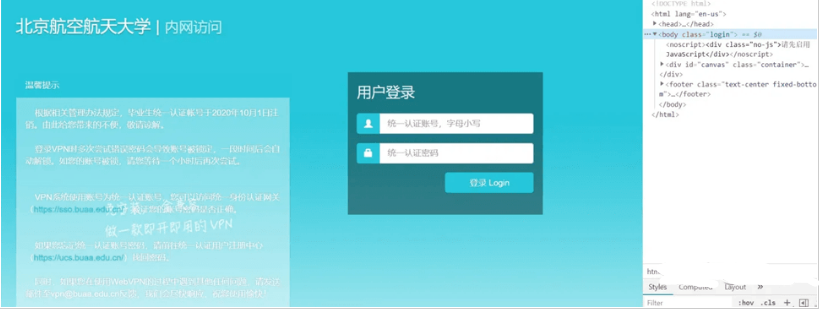
点击chrome浏览器右上角,更多工具——选择“开发者工具”。我们就得到了下面的页面。
 ?
?
下面我们要找到登录的账号输入位置,密码输入位置,以及提交按钮。当我们将鼠标放在右侧代码上时,左侧会出现其多对应的区域,使用这种方法,我们可以一点一点定位如下:
 ?
?
可见右侧input标签就是输入框了,它有一个id是user_login,我们上文讲过,id如果不是动态id那就是独一无二的,可以直接获取,因此可以直接通过如下指令输入账号(密码同理):
| 1 2 3 |
|
那么如何点击登录呢,同样我们找到对应的标签:
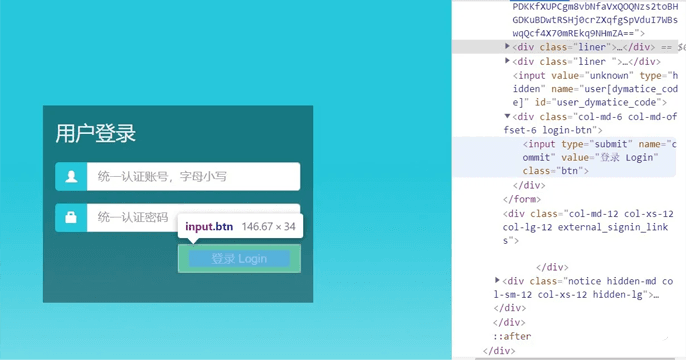
可见有一个name是commit,很幸运,这个界面上只有这一个元素的name是commit,因此可以直接通过name获取,接着调用.click()方法就可以完成点击登录。
| 1 |
|
登录完成后是这个样子:

?
比如这时,我想登录北航图书馆,要怎么做呢?
同样的道理,打开开发者工具,找到北航图书馆对应的标签

我们这次使用find_element_by_xpath()方法来实现。可见如果要定位到该标签,我们先要定位到class为container的div标签,之后定位到其下的ul标签,之后定位到其下的第3个li标签,最后定位到a标签。之后就可以登录到北航图书馆的网站中去。
| 1 |
|
以上就是本文的全部内容,从环境配置、基础知识、代码编写三方面全方位的讲解了如何使用selenium来在chrome浏览器上实现自动化登录。其实,好多的抢课、评教的脚本都是这样写出来的,大家感兴趣可以尝试一下。
?现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!?希望能帮助到你!【100%无套路免费领取】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【python数据分析】北京房租数据分析
- Apache Flink连载(二十三):Flink HA - Flink基于Yarn HA
- VMware16的安装及VMware配置Linux虚拟机
- JAVA 继承
- 深度解析Cron表达式:精确控制任务调度的艺术
- 钡铼S281 LoRa网关在智能畜牧养殖监测中的应用
- 【Java】后端开发语言Java和C#,两者对比注解和属性的区别以及作用
- 【MySQL】数据库之MMM高可用
- Python如何进行内存管理和lambda表达式
- 基于java的合同管理系统设计与实现