MobileNet
发布时间:2023年12月28日
时间:2017 2018
背景

传统卷积神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行。
MobileNet v1
概念

网络中的亮点:
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数α,β
传统卷积
输入深度为3的特征矩阵,使用4个卷积核进行卷积。每个卷积核的深度都和输入特征矩阵的深度是相同的。这里的输入特征矩阵的深度是3,所以卷积核的深度也是3。输出特征矩阵的的深度是由卷积核的个数所决定的。我们采用四个卷积核,所以我们输出特征矩阵的个数为4。
总结下来就是
- 卷积核channel = 输入特征矩阵channel
- 输出特征矩阵channel=卷积核个数
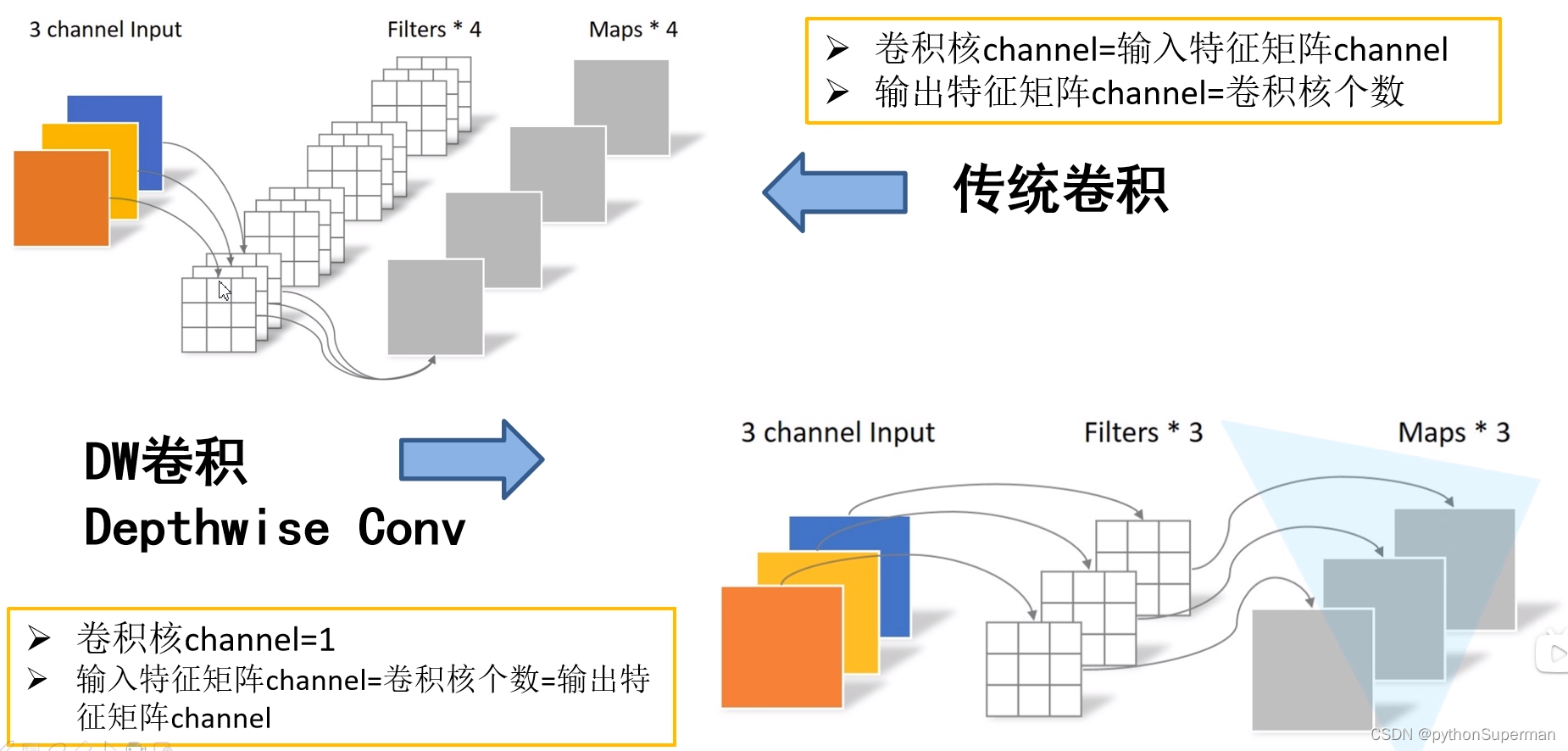
DW卷积 Depthwise Conv
每个卷积核的深度都是为1的,并不像我们传统卷积一样,卷积核的深度等于特征矩阵的深度。这里的每一个卷积核只负责与我们输入特征矩阵的一个channel进行卷积运算,然后再得到相应的输出特征矩阵的一个channel。既然我们每一个卷积核负责一个channel,那么我们所采用的卷积核的个数应该与输入特征矩阵的深度相同,这样能保证每一个卷积核负责一个channel。又由于我们每一个卷积核与我们的输入特征矩阵的一个channel进行卷积后得到一个输出特征矩阵的channel。我们输出特征矩阵的深度也就与我们卷积核的个数相同,进一步与我们输入特征矩阵的深度相同。记性总结如下两点:
- 卷积核channel = 1
- 输入特征矩阵channel=卷积核个数=输出特征矩阵channel
PW卷积 Pointwise Conv
PW卷积就是普通的卷积,只不过我们卷积核的大小是等于1而已。通过图中可以看到,我们每一个卷积核,他的深度同样与我们输入特征矩阵的深度相同,输出特征矩阵的深度与我们卷积核的个数是相同的。所以它就是一个普通的卷积,只不过卷积核大小为1而已。

通常我们的PW和DW?是放在一起使用的,使用的深度可分卷积相比与我们普通的卷积而言到底能节省多少参数呢。

?α和β
α
代表卷积核个数的倍率,控制我们卷积过程中所采用的卷积核的个数。
β
分辨率的参数,输入的图像尺寸。
 ?
?
MobileNet v2

?
?
文章来源:https://blog.csdn.net/llf000000/article/details/135276223
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【C#】知识点实践序列之UrlEncode在线URL网址编码、解码
- 目前最好用的AI写作软件有哪些,这5款写作效率高
- 想做好私域,数字化基础要打好!
- 数据可视化|Python之Pyecharts将“爬虫数据”绘制饼状图
- 【接口窥探】
- shell实现折线图
- 14.1 virtual sequence and virtual sequencer
- 基于java的企业员工信息管理系统设计与实现
- RuoYi-Vue分离版集成MQTT客户端,超详细版
- Binary Tree Level Order Traversal