阿里云SLS日志服务之数据导入与加工处理
发布时间:2023年12月18日
一、背景
采集vm虚拟机上的Log日志文本,如果需要经过特殊的加工处理,在本文主要讲述如何在SLS把kafka采集上来的数据经导入并加工后存储。
二、数据流转图
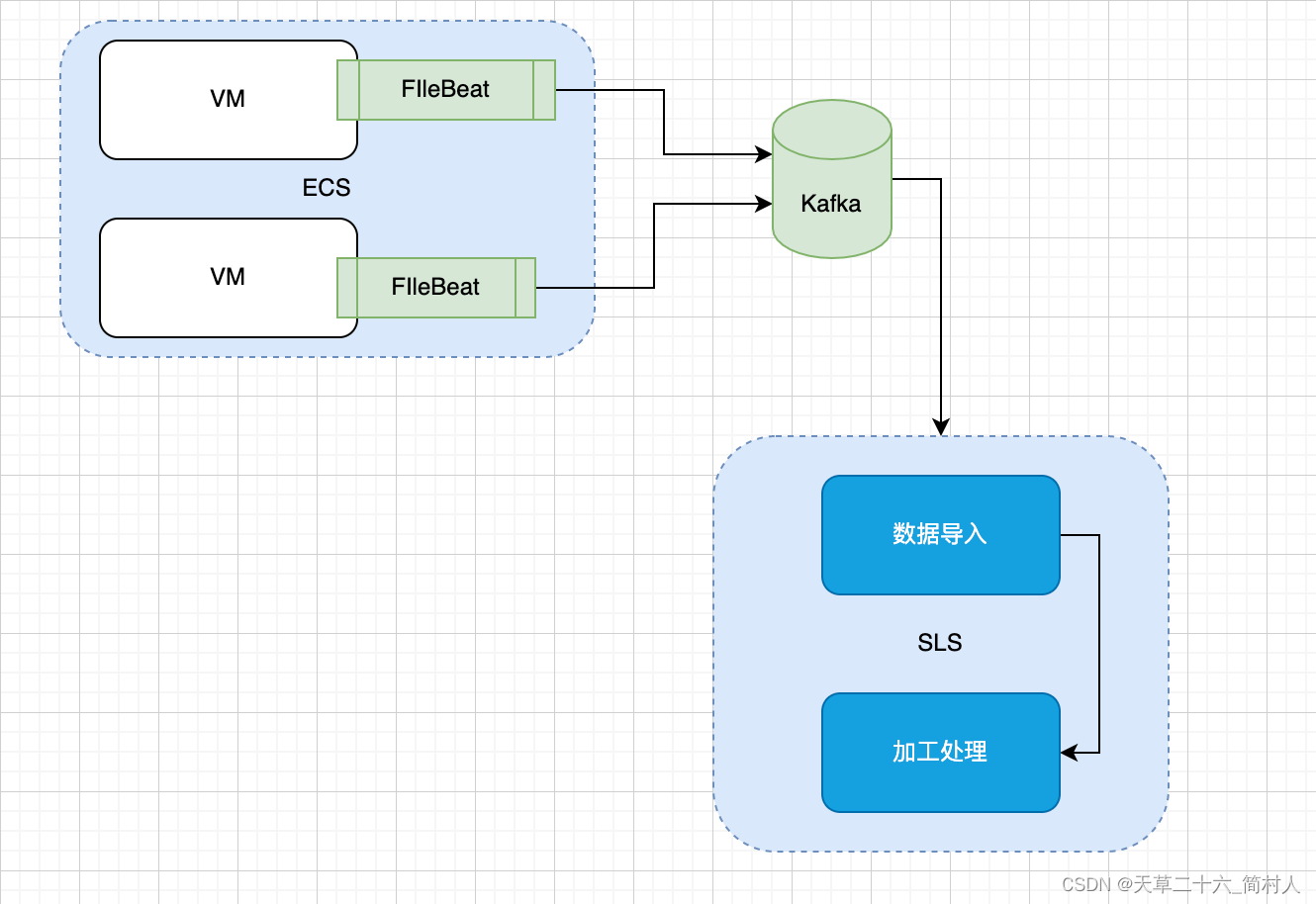
三、数据导入
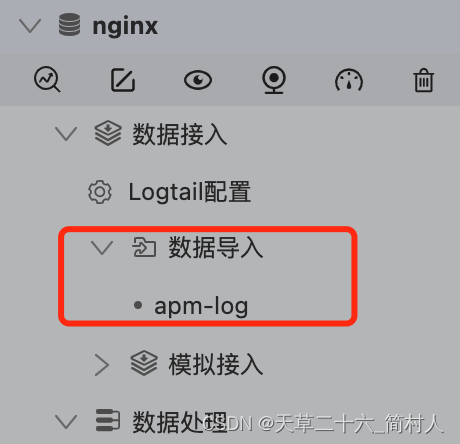
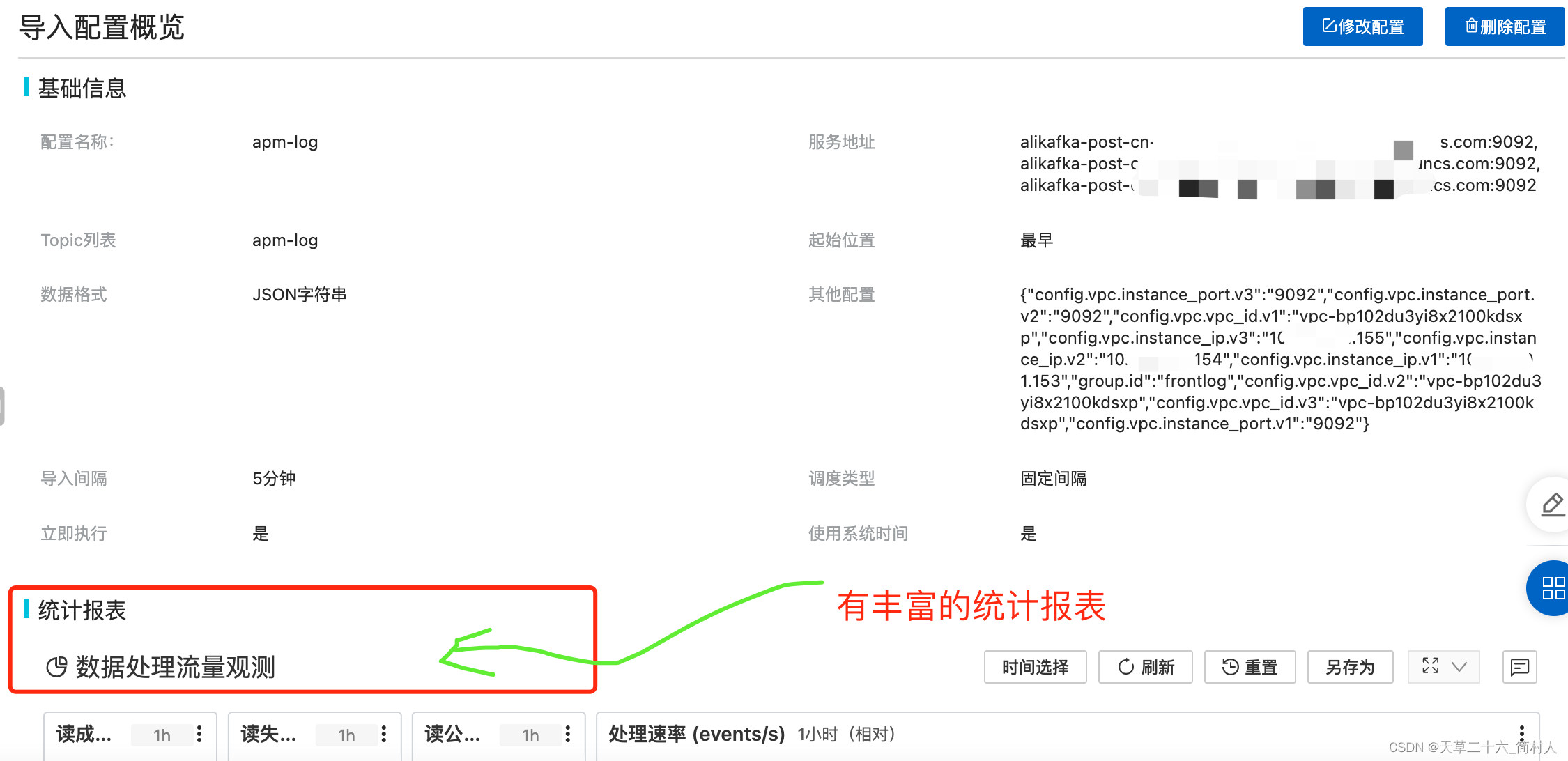
- 服务地址:填写kafka集群的地址
- 数据格式:json字符串(这是因为我们每行的数据格式是json格式存储在本地)
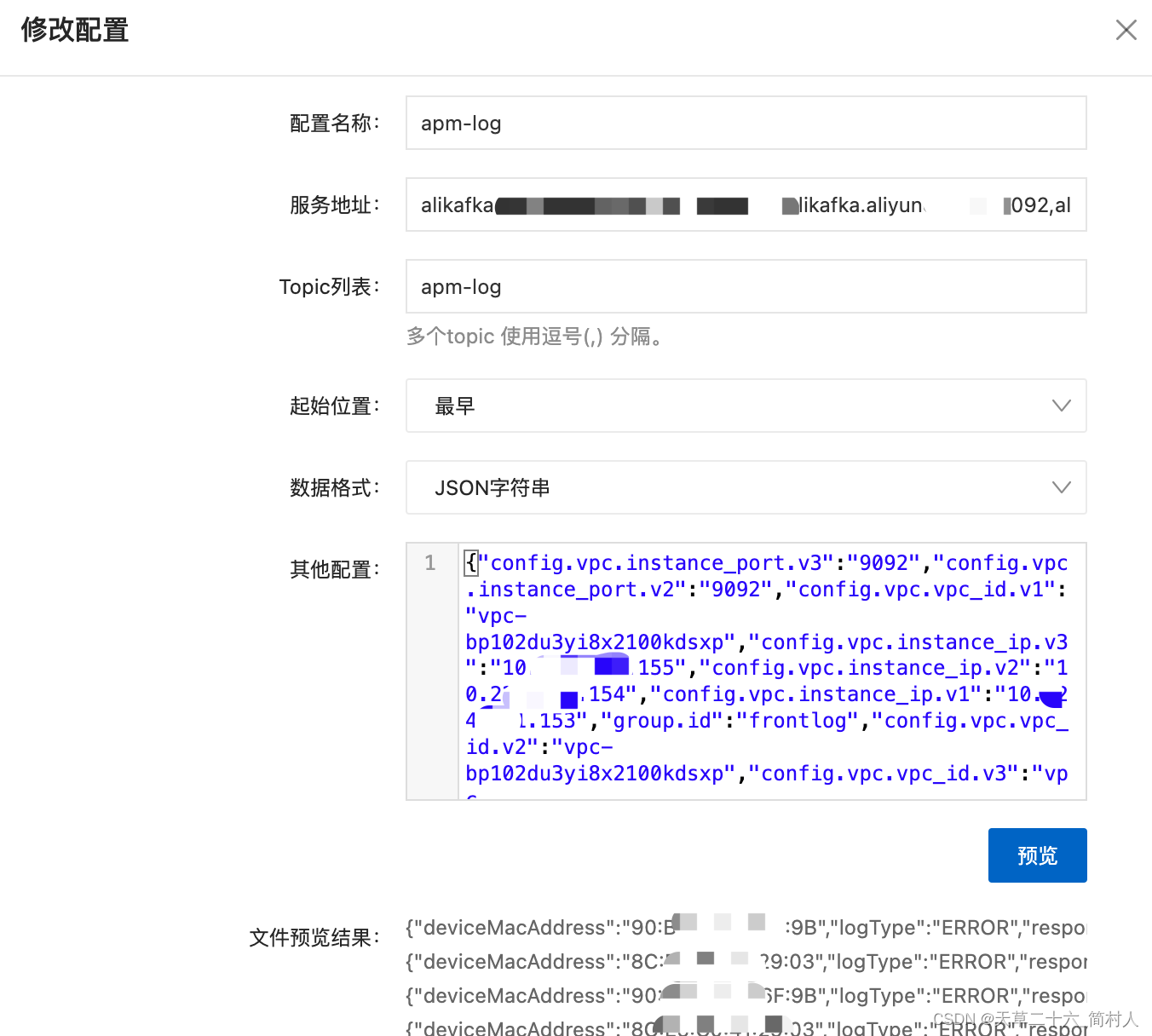
其他配置:
153/154/155三个Kafka集群节点
{"config.vpc.instance_port.v3":"9092","config.vpc.instance_port.v2":"9092","config.vpc.vpc_id.v1":"vpc-bp102du3yi8x2100kdsxp","config.vpc.instance_ip.v3":"10.xx.xx.155","config.vpc.instance_ip.v2":"10.xx.xx.154","config.vpc.instance_ip.v1":"10.xx.xx.153","group.id":"frontlog","config.vpc.vpc_id.v2":"vpc-bp102du3yi8x2100kdsxp","config.vpc.vpc_id.v3":"vpc-bp102du3yi8x2100kdsxp","config.vpc.instance_port.v1":"9092"}
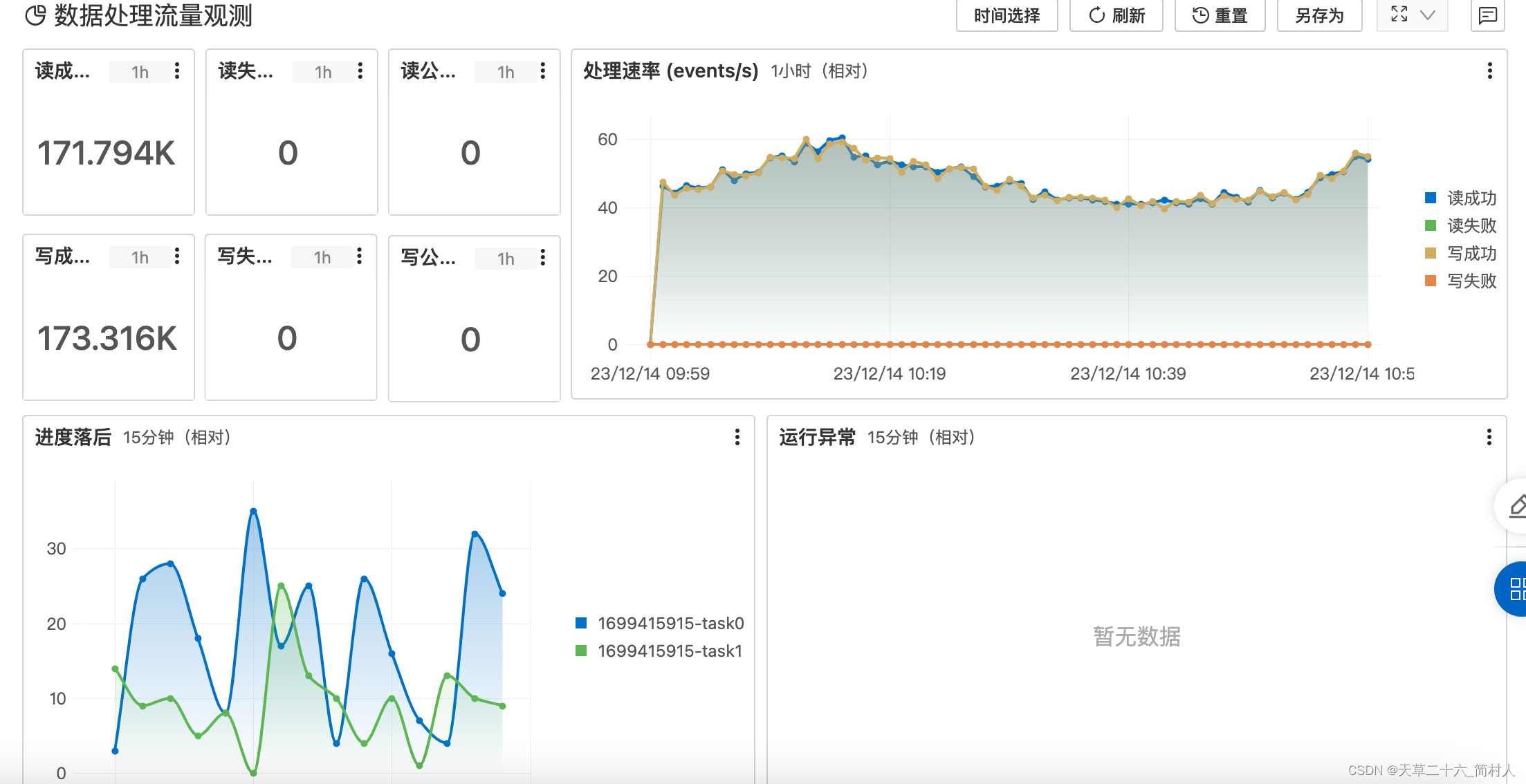
- 丰富的报表
四、加工处理
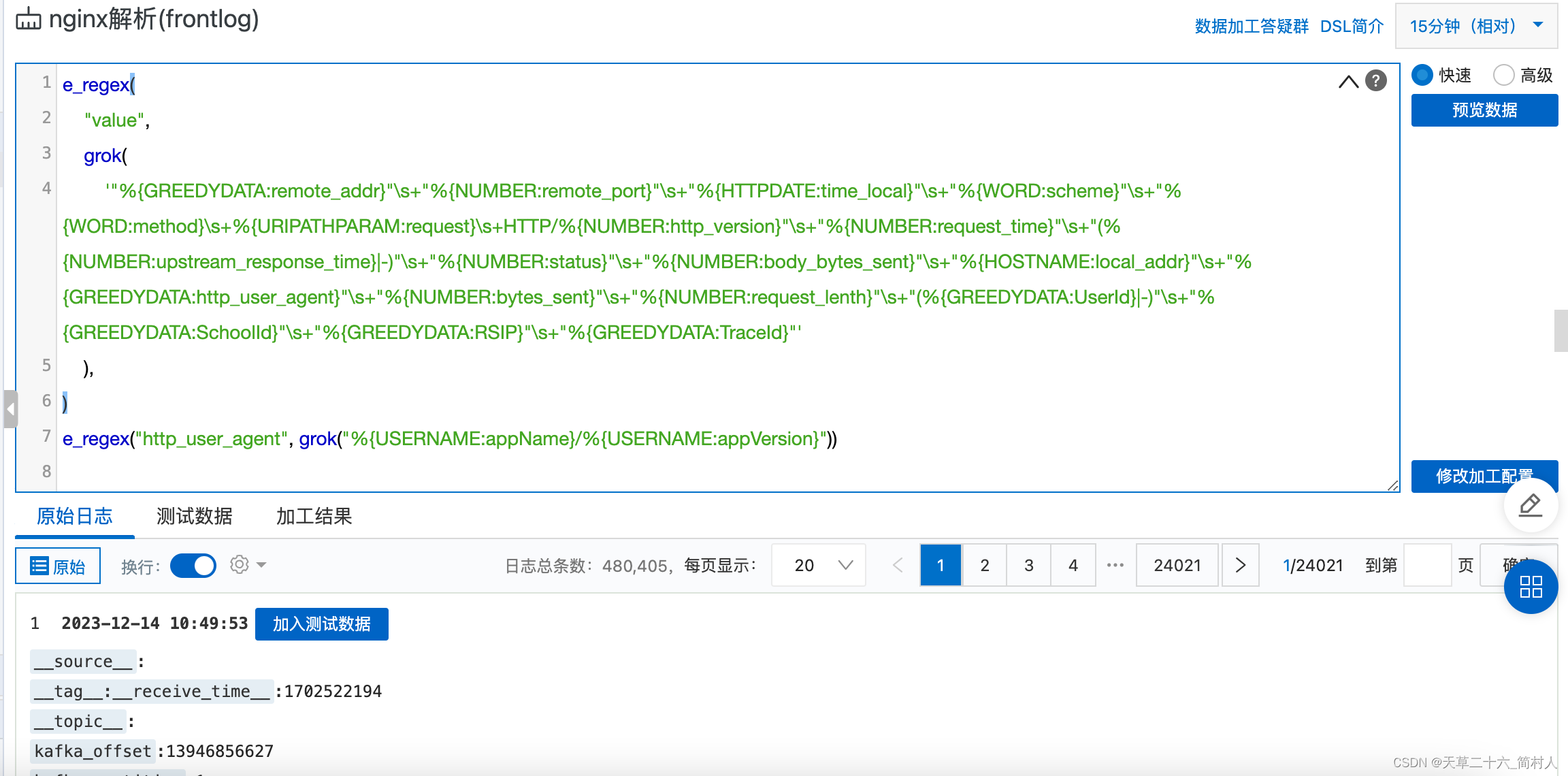
- 下面看一看加工的细节:
对原始的value字段进行加工,这里使用的是grok语法。
配置了两个解析,第二个解析是在第一个解析的基础上,进行二次进一步解析。
上一步解析出字段http_user_agent,
第二个解析,把http_user_agent进一步解析出字段appName和appVersion
由此可见,加工还是比较方便且灵活的。
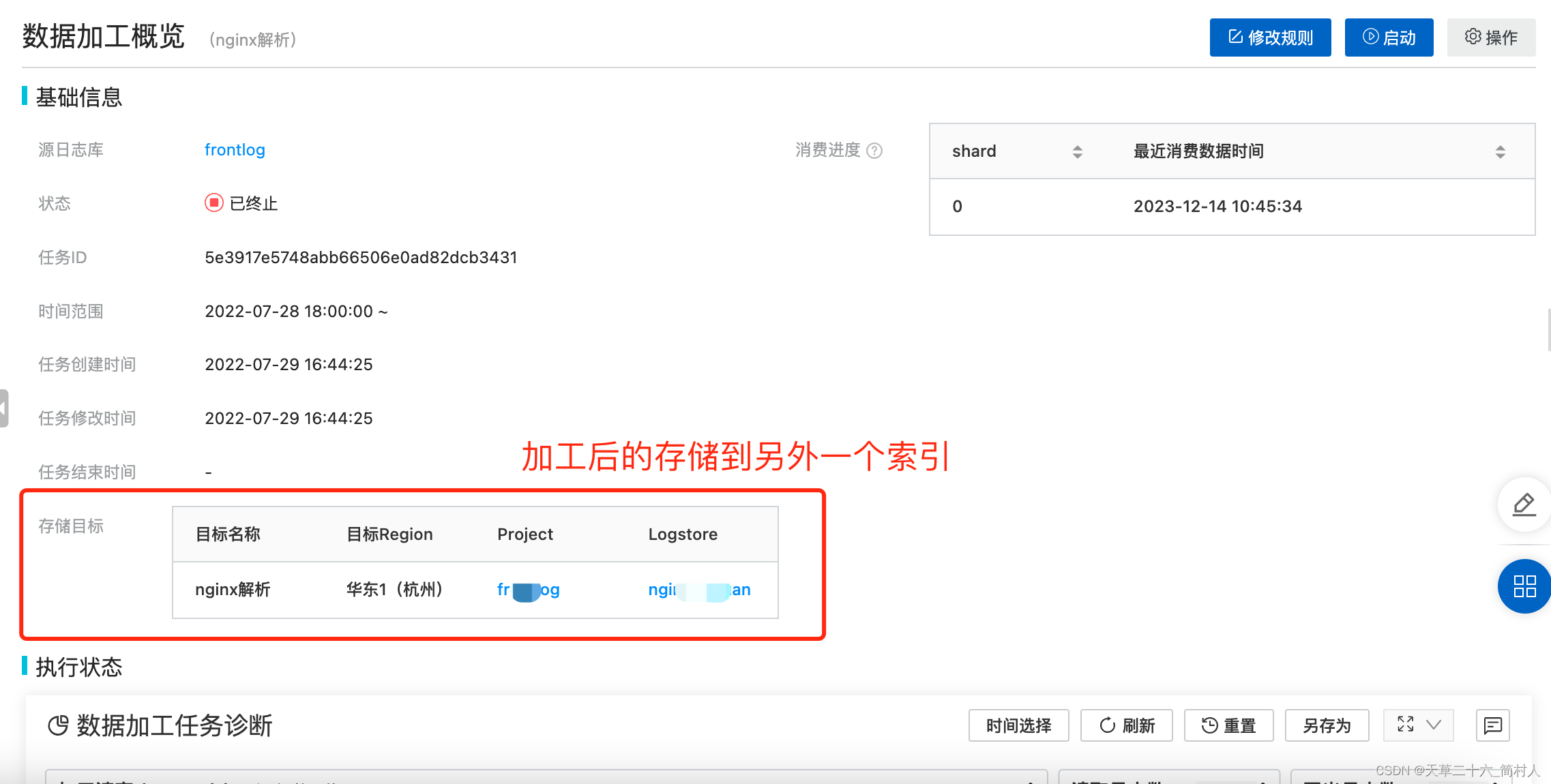
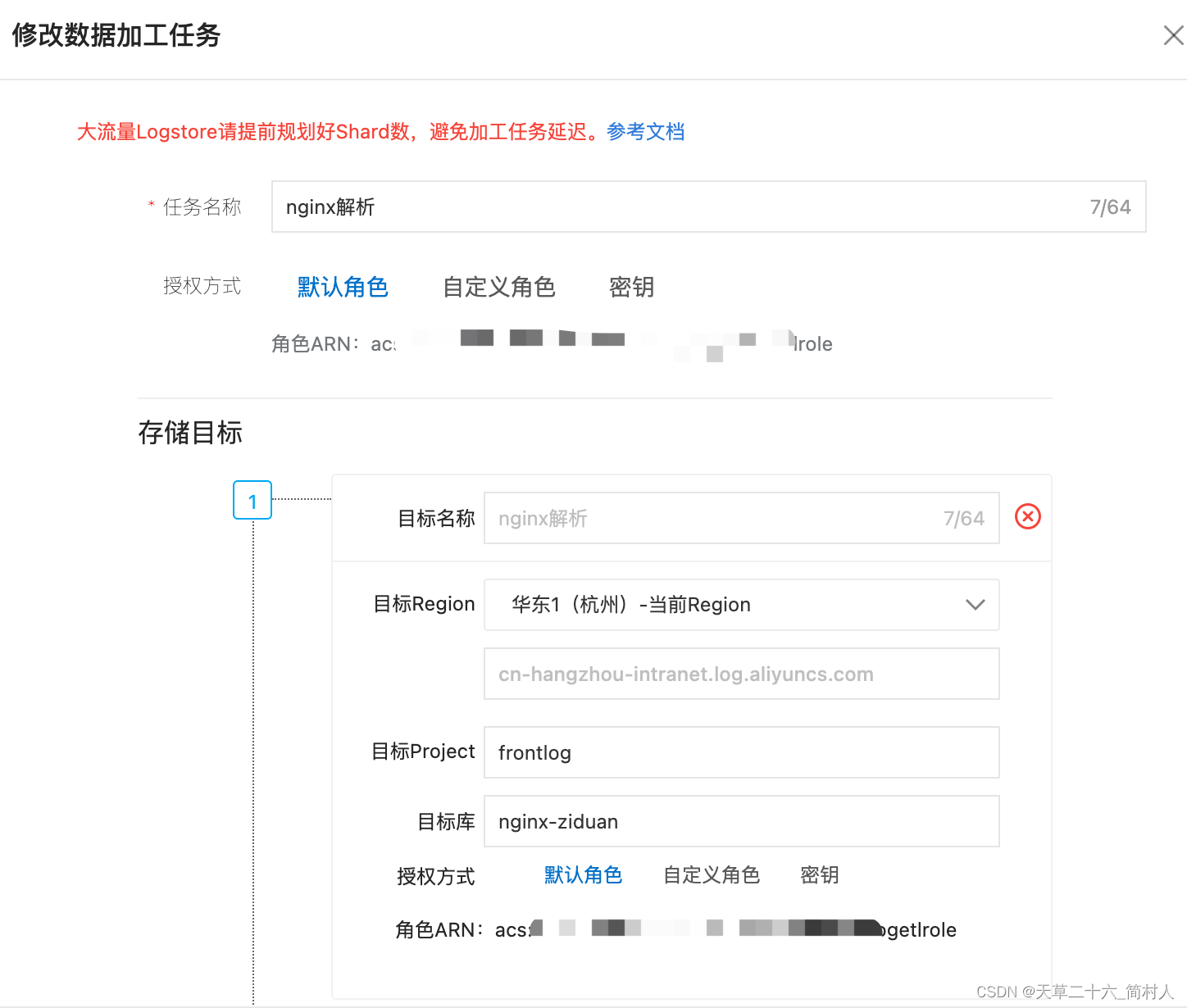
- 加工后的存储目标:
如此,kafka采集上来的Log数据,先经过了导入存储到某个索引,后又加工处理存储到另外一个索引。
所以说,一份数据保存了两份,一份是原始数据,另外一份是加工后的数据。
毫无疑问,会加大你的存储成本。
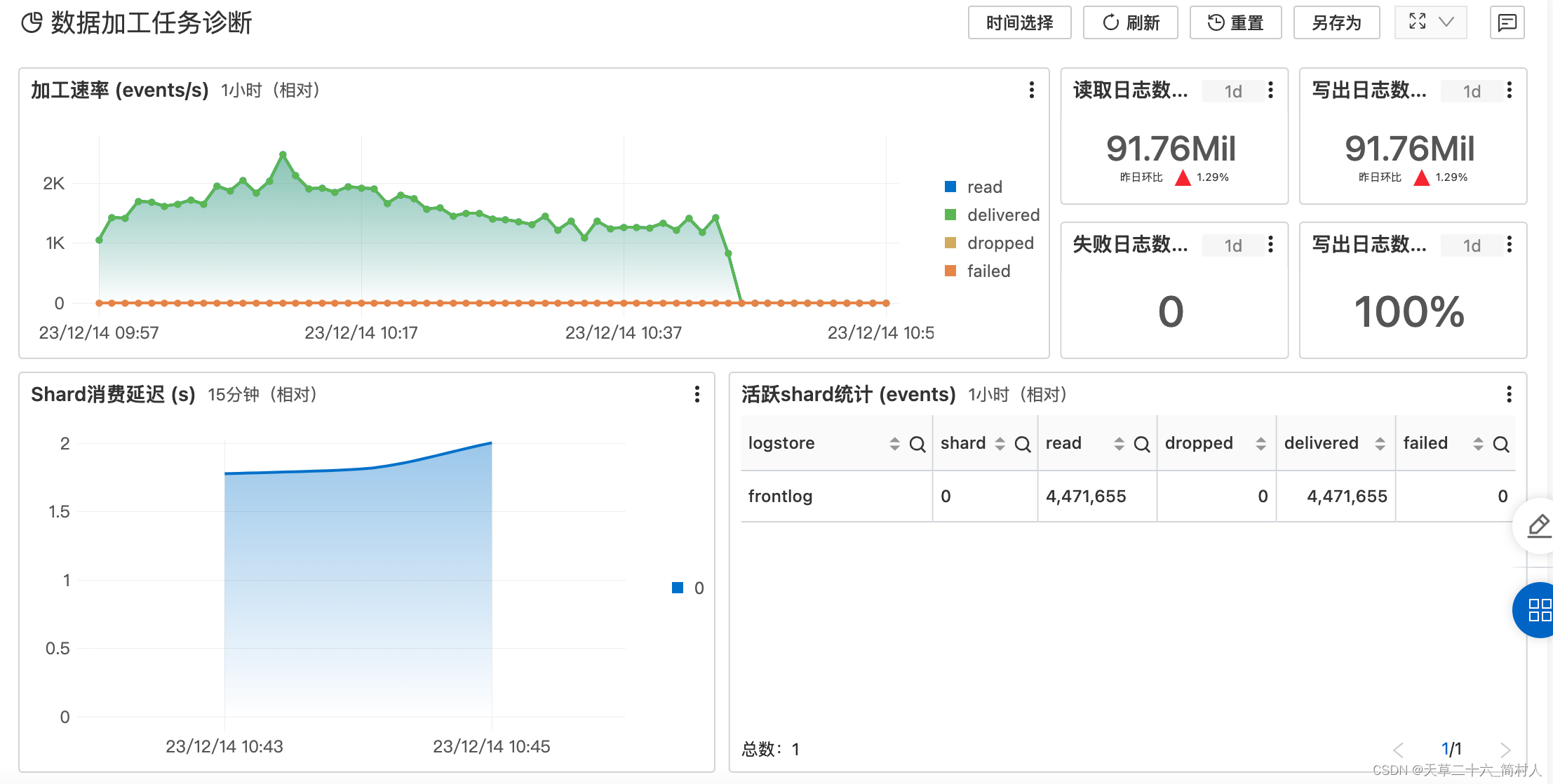
- 加工情况的总体预览:
五、总结
到此,你应该明白,如果不用复杂的加工处理,不建议你使用本文提及的方案。
直接在sls配置Logtail即可。
本方案把采集的步骤拉长不说, 光是存储成本就翻一番。
文章来源:https://blog.csdn.net/zhuganlai168/article/details/134990818
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 尚硅谷web前端知识点补充
- Linux——ls,pwd,cd 基础命令串讲(狠狠爱住)
- 【干货】Windows测试拉流工具及操作步骤大汇总
- 安装vcpkg管理opencv的安装+MFC缺失的解决
- FineBI实战项目一(22):各省份订单个数及订单总额分析开发
- 样式集-发布,发表页面完整代码及示意图
- 基础题总结(三)
- C# OpenCvSharp读取rtsp流录制mp4可分段保存
- 数据分析---SQL(3)
- jsp 互联网劳动教育农场系统Myeclipse开发mysql数据库web结构java编程计算机网页项目