P38 自注意力机制
针对输入为大小可变的多维向量,怎么处理?
输入为一堆向量,可以是文字, 可以是语音,可以是graph
输出也是多样的。
输入
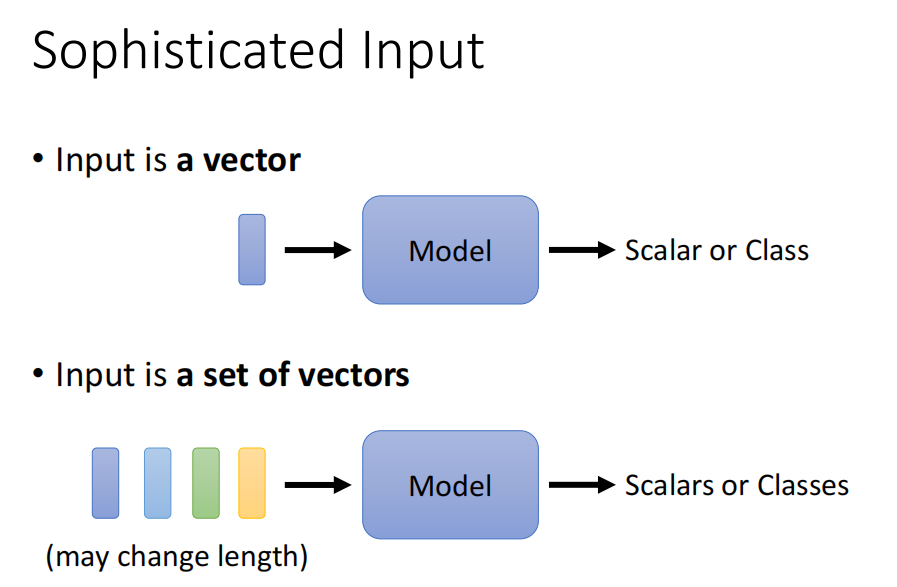
输出
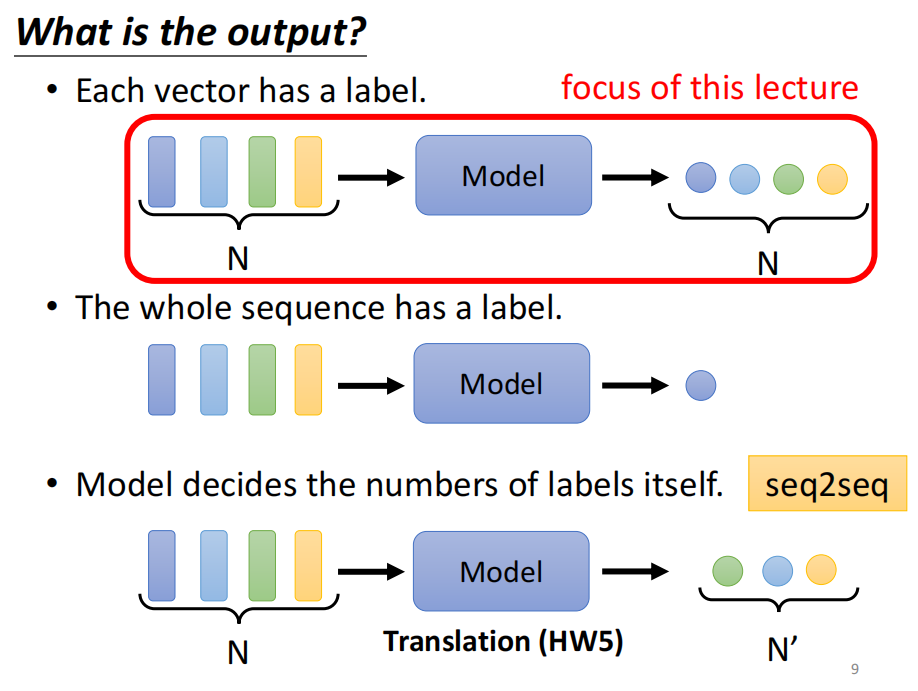
输入输出一样: Sequence Labeling
方法一:
一对一的输入输出, 缺点: 没有考虑前后关联性,如下面的 I saw a saw 盛情网络也没法辨别前后两个saw 的区别。
方法二:
使用window frame, 以部分sequence作为输入
问题?
有没有可能 一个window 覆盖一整个序列
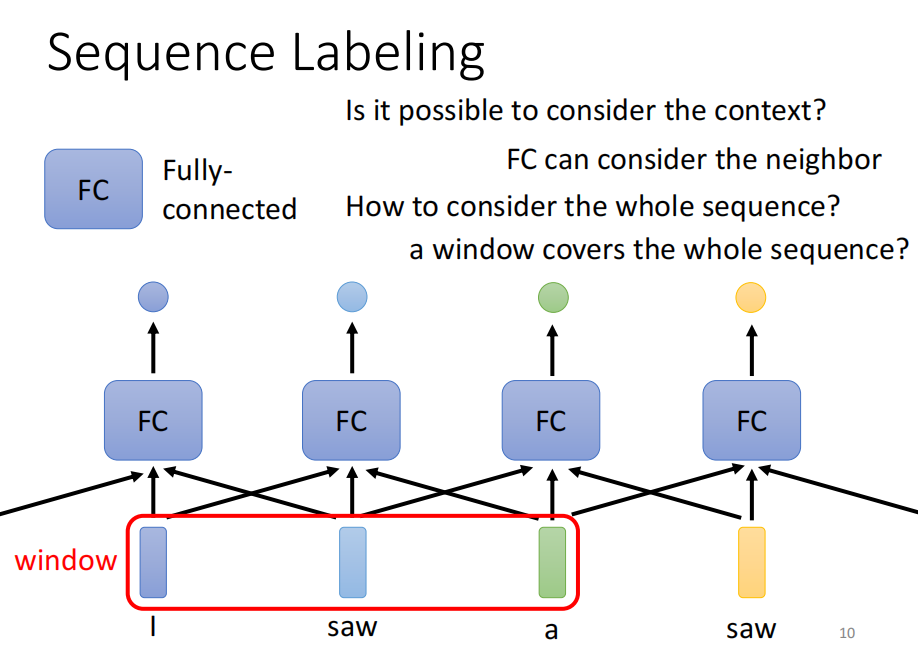
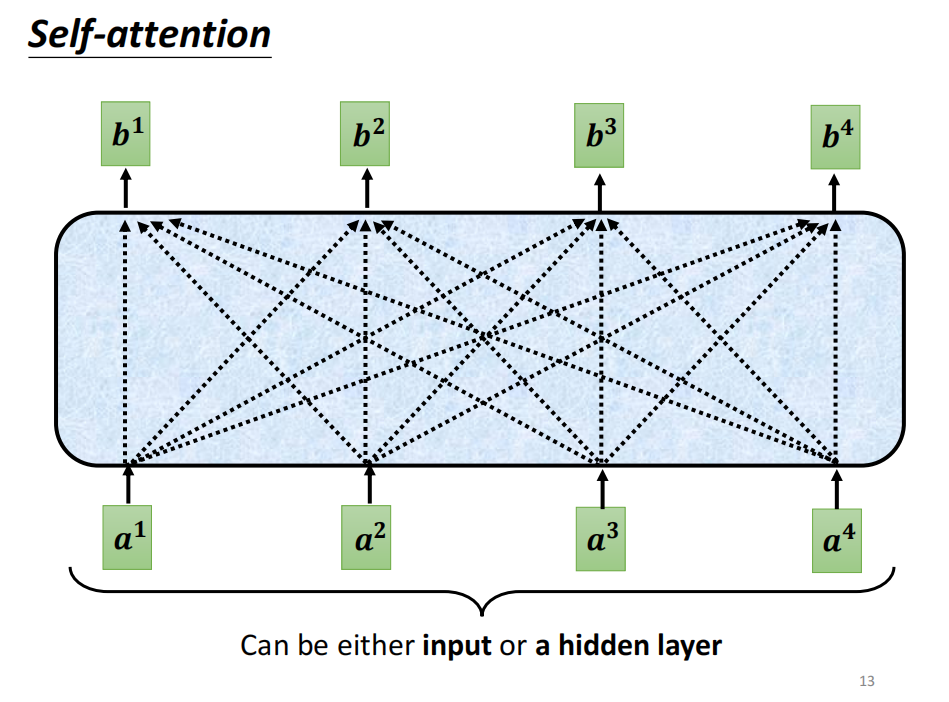
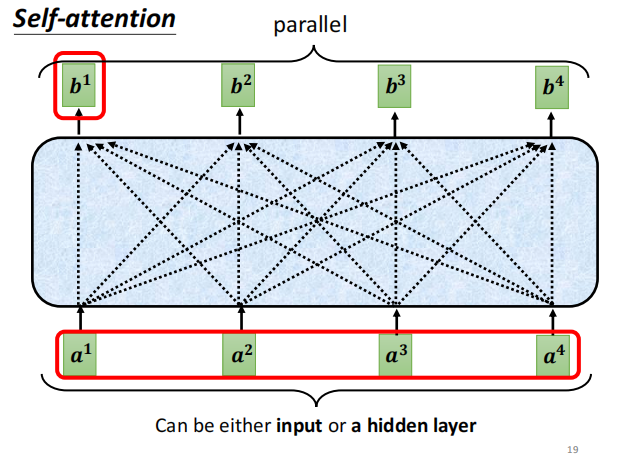
self-attention
输入几个vector, 输出几个vector
每个vector 输出,都考虑了整个sequence的输入
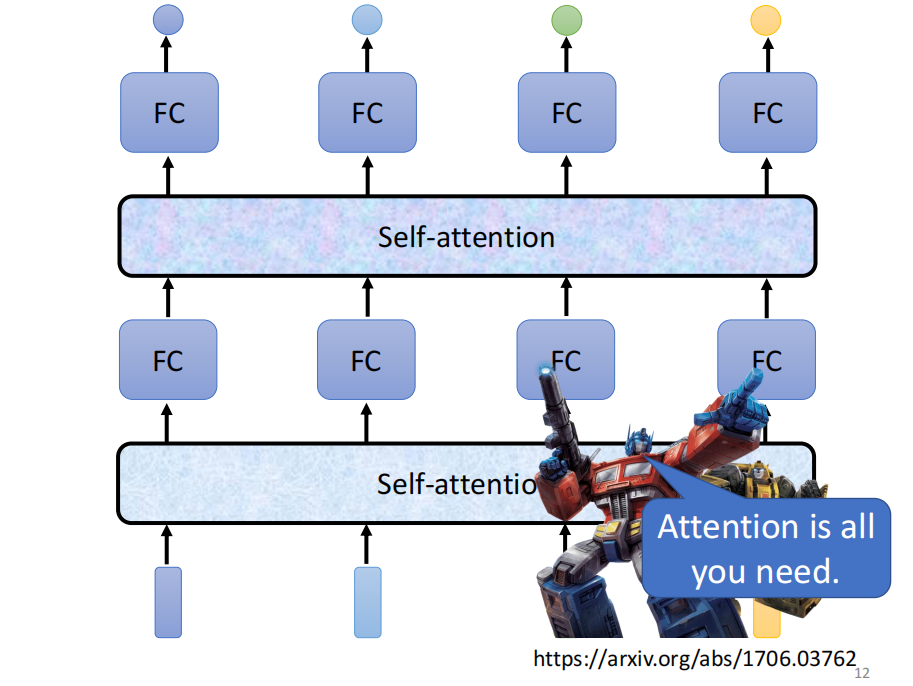
self -attention 可以叠加
交替使用FC 和 self-attention 交互叠加
-
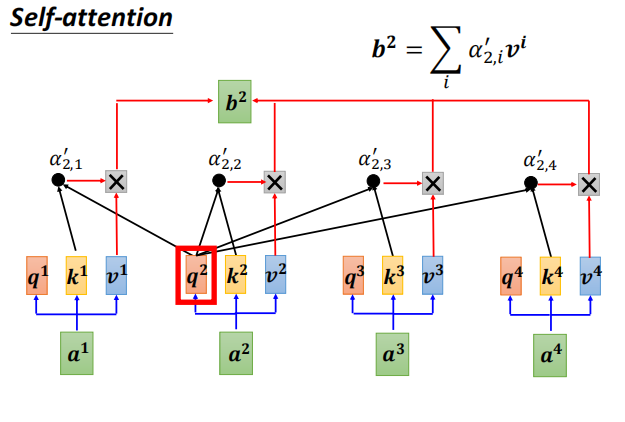
如何产生b1?
- 计算一个序列的相关性 尓发

- 计算一个序列的相关性 尓发
-
计算attention 的模组
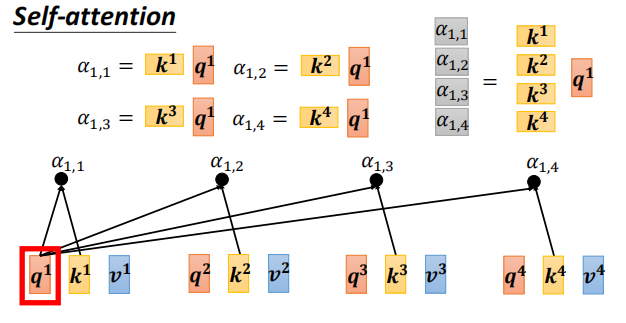
把两个向量作为输入,输出的 尓法 为两个向量的关联程度
计算关联程度的方法有很多,常见方法为 dot product
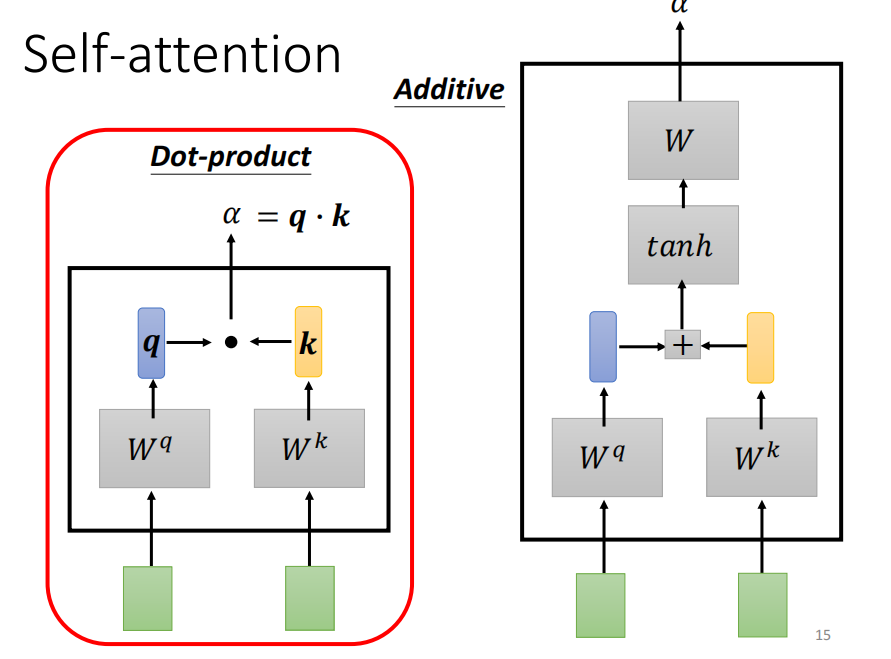
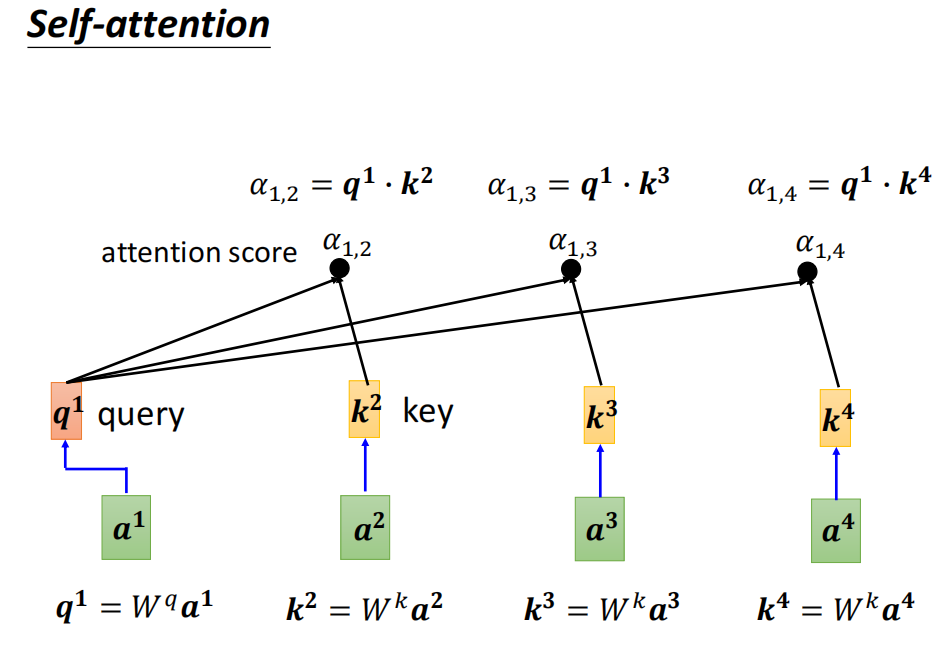
尓法又称之为 attention score -
计算softmax 做归一化
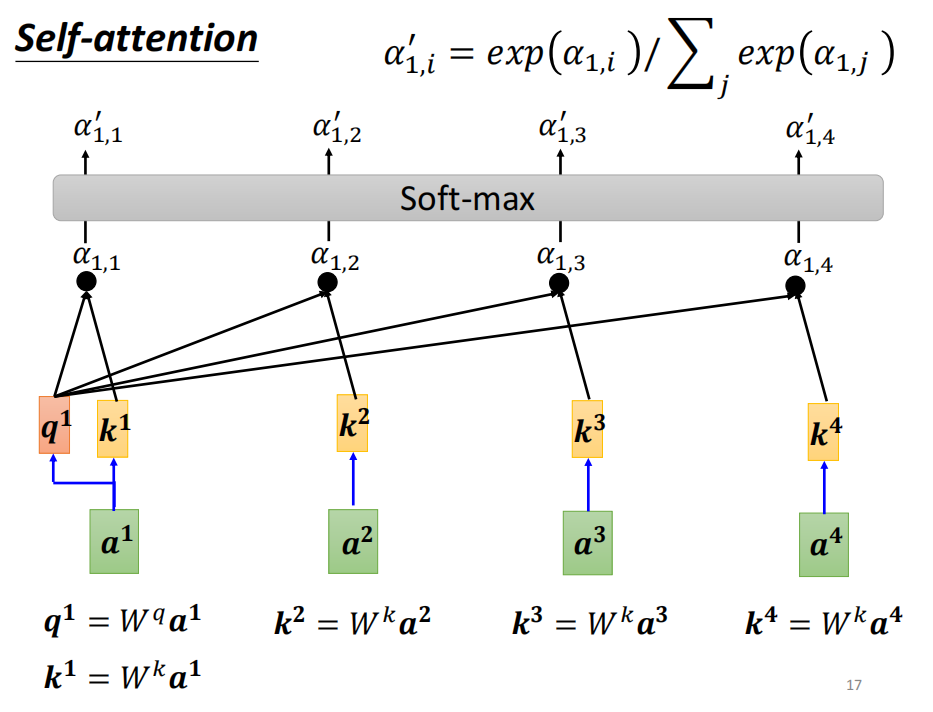
为什么要用 softmax ? 没啥道理可言。 其他方法可以尝试。 不过 softmax 最常见 -
extra information
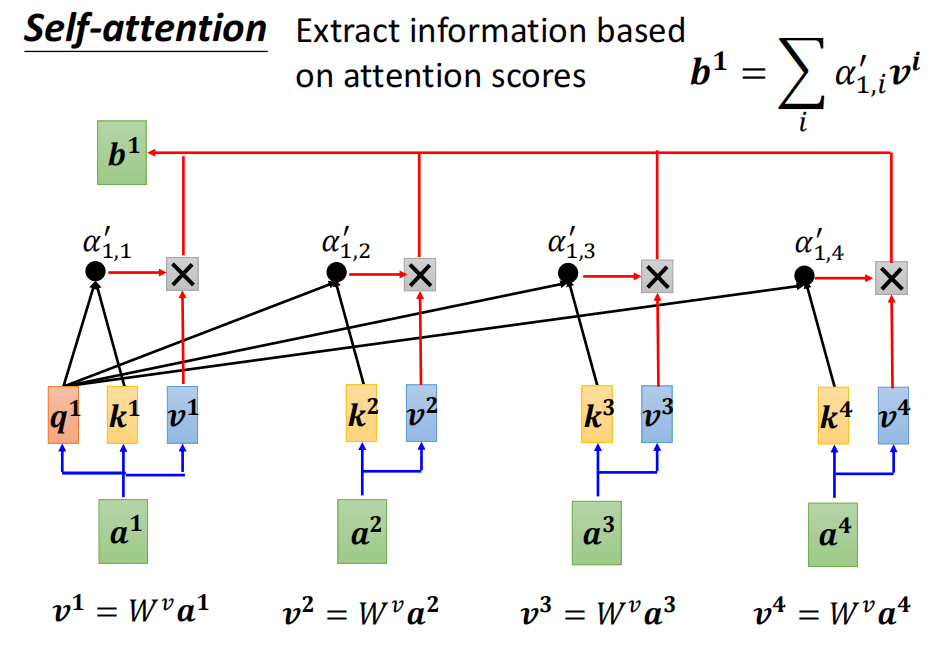
在这里插入图片描述
-
I --> Q K V
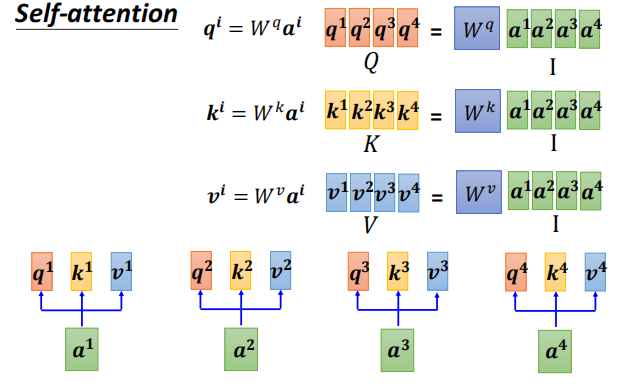
输入I --> 计算得 Q K V
然后计算attention score
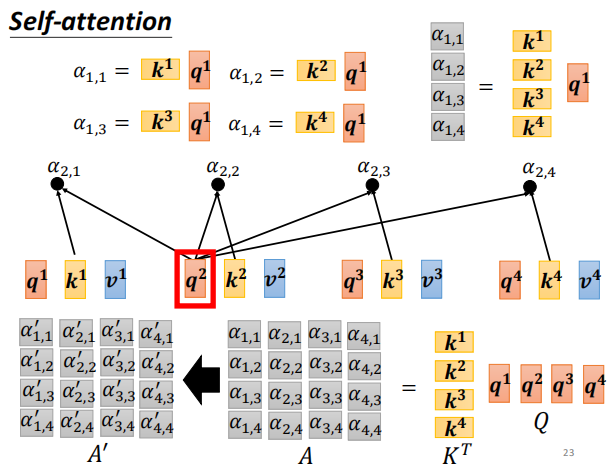
A – A’ 进行 softmax 归一化 -
计算b 矩阵O
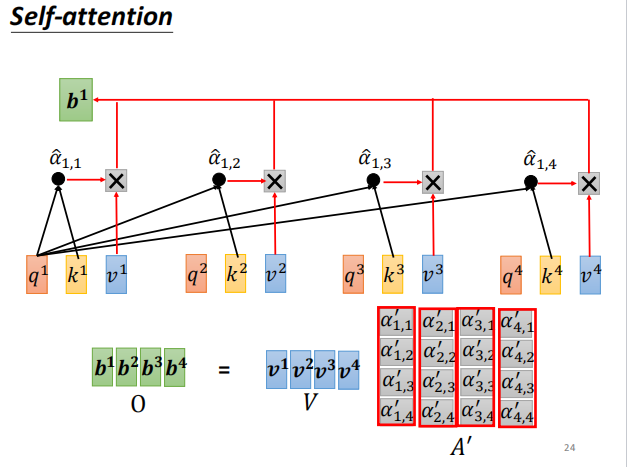
-
小结
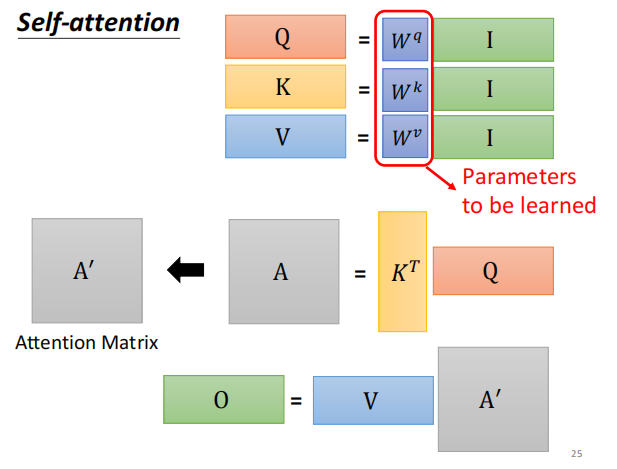
WQ WK WV 为需要训练得参数
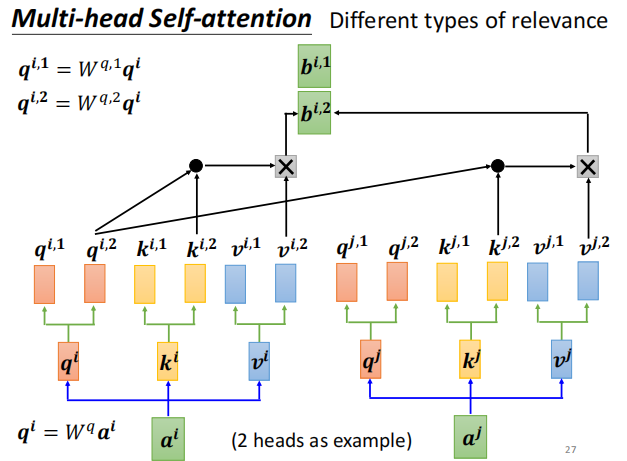
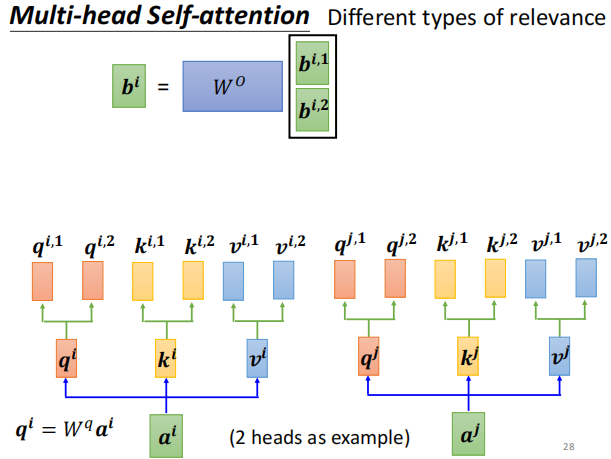
进阶版本 Multi-head self-attention
不同的q 代表不同的相关性, 生成两种q ,两种head 。 其他计算方式与上同。
q 乘上两个矩阵 ,得到两个不同的head
算score 时,下标1 跟下标1 算, 2 跟2 算
Positional Encoding
如果位置的咨询是很重要的信息,加上位置的咨询
为每一个咨询,加一个位置vector e
将e 加到 尓法 上
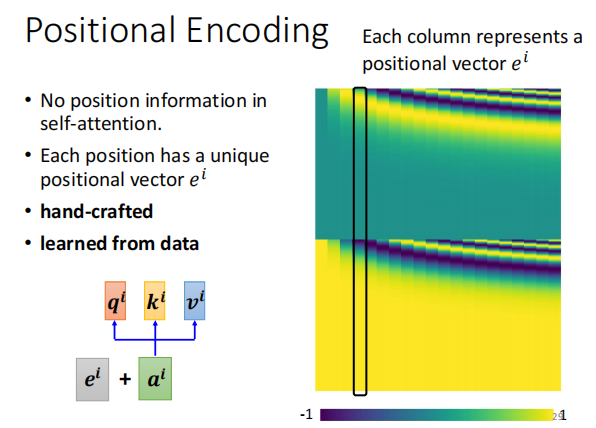
positional encoding 是一个尚在研究的问题
可以由很多方法生成positional encoding
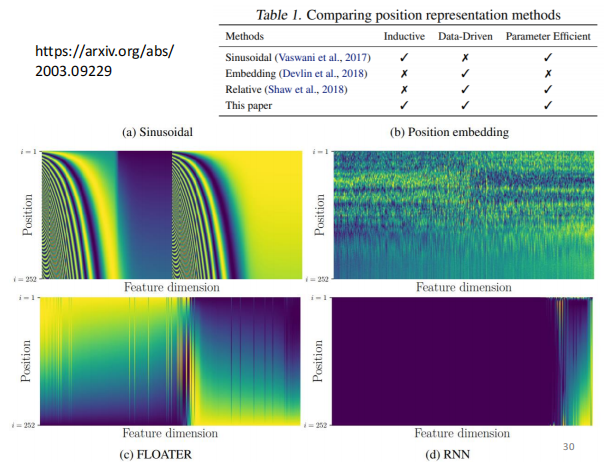
应用领域
NLP
Speech (语音太长时,要分段,看一小范围)

影像
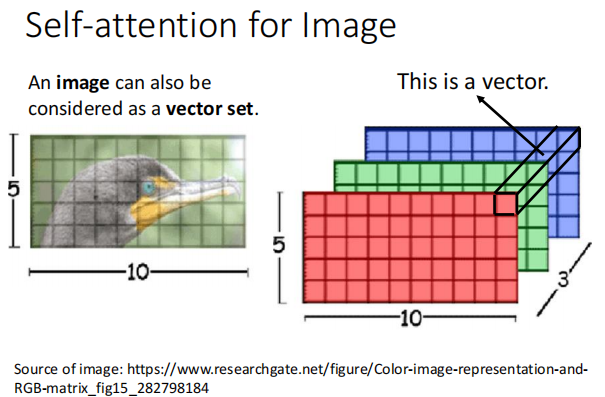
self attention vs cnn
同

异
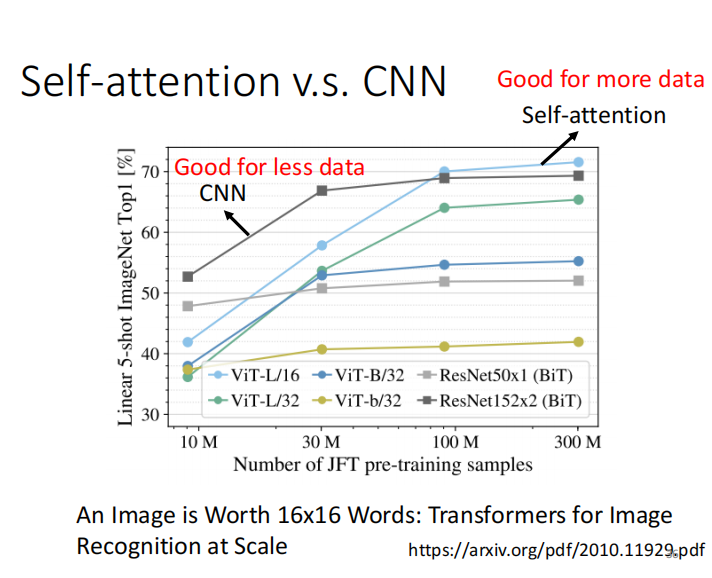
数据小时,CNN 效果更好
数据集大时,self attention 效果更好
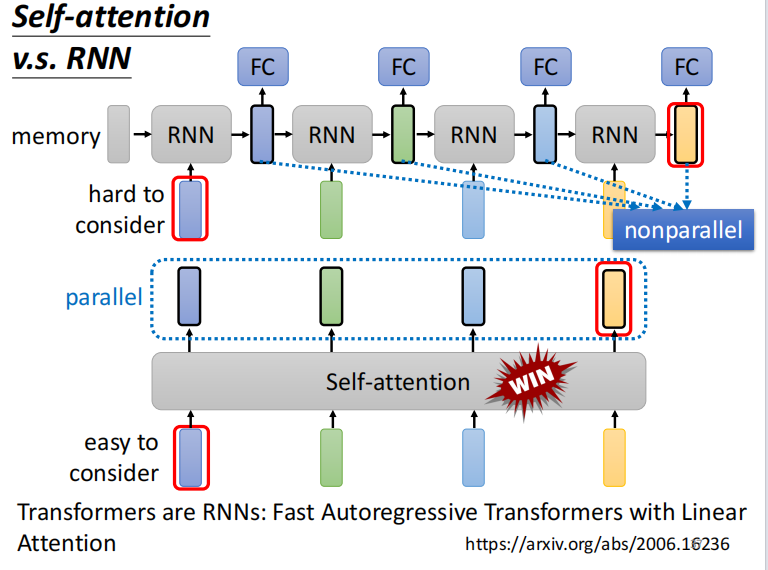
self attention vs RNN
同: 输入都是 sequence
异: RNN,不能平行处理所有的输出
对于最左边的输入,RNN 的输出hatd to consider
越来越多的应用,将RNN 架构改成 self attention 架构
self attention for Graph

- 广义的transformer 就是指 self attention
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!