MySQL数据库:复合查询
目录
前置说明:本文主要oracle 9i的经典雇员信息测试表为例,进行示例演示。
该表有三个子表构成,分别为:(1). dept -- 部门信息表、(2). emp -- 雇员信息表 、(3). salgrade -- 薪资等级表,下面是每张表的desc字段及属性信息:
- dept的字段信息包括:deptno -- 部门编号、dname -- 部门名称、loc -- 部门地点。
- emp的字段信息包括:empno -- 员工编号、ename -- 员工姓名、job -- 工种、mgr -- 直属领导工号、hiredate -- 雇佣时间、sal -- 薪资、comm -- 绩效奖金、deptno -- 所属部门号。
- salgrade的字段信息:grade -- 薪资等级、losal -- 最低薪资、hisal -- 最高薪资。
mysql> desc dept;
+--------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------------------+------+-----+---------+-------+
| deptno | int(2) unsigned zerofill | NO | | NULL | |
| dname | varchar(14) | YES | | NULL | |
| loc | varchar(13) | YES | | NULL | |
+--------+--------------------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
mysql> desc emp;
+----------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------------------+------+-----+---------+-------+
| empno | int(6) unsigned zerofill | NO | | NULL | |
| ename | varchar(10) | YES | | NULL | |
| job | varchar(9) | YES | | NULL | |
| mgr | int(4) unsigned zerofill | YES | | NULL | |
| hiredate | datetime | YES | | NULL | |
| sal | decimal(7,2) | YES | | NULL | |
| comm | decimal(7,2) | YES | | NULL | |
| deptno | int(2) unsigned zerofill | YES | | NULL | |
+----------+--------------------------+------+-----+---------+-------+
8 rows in set (0.00 sec)
mysql> desc salgrade;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| grade | int(11) | YES | | NULL | |
| losal | int(11) | YES | | NULL | |
| hisal | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
3 rows in set (0.00 sec)一. 多表查询
多表查询,就是在由多张表组合而成的大表中,检索符合条件的数据。
语法:select ... from 表1,表2,... [where ...];
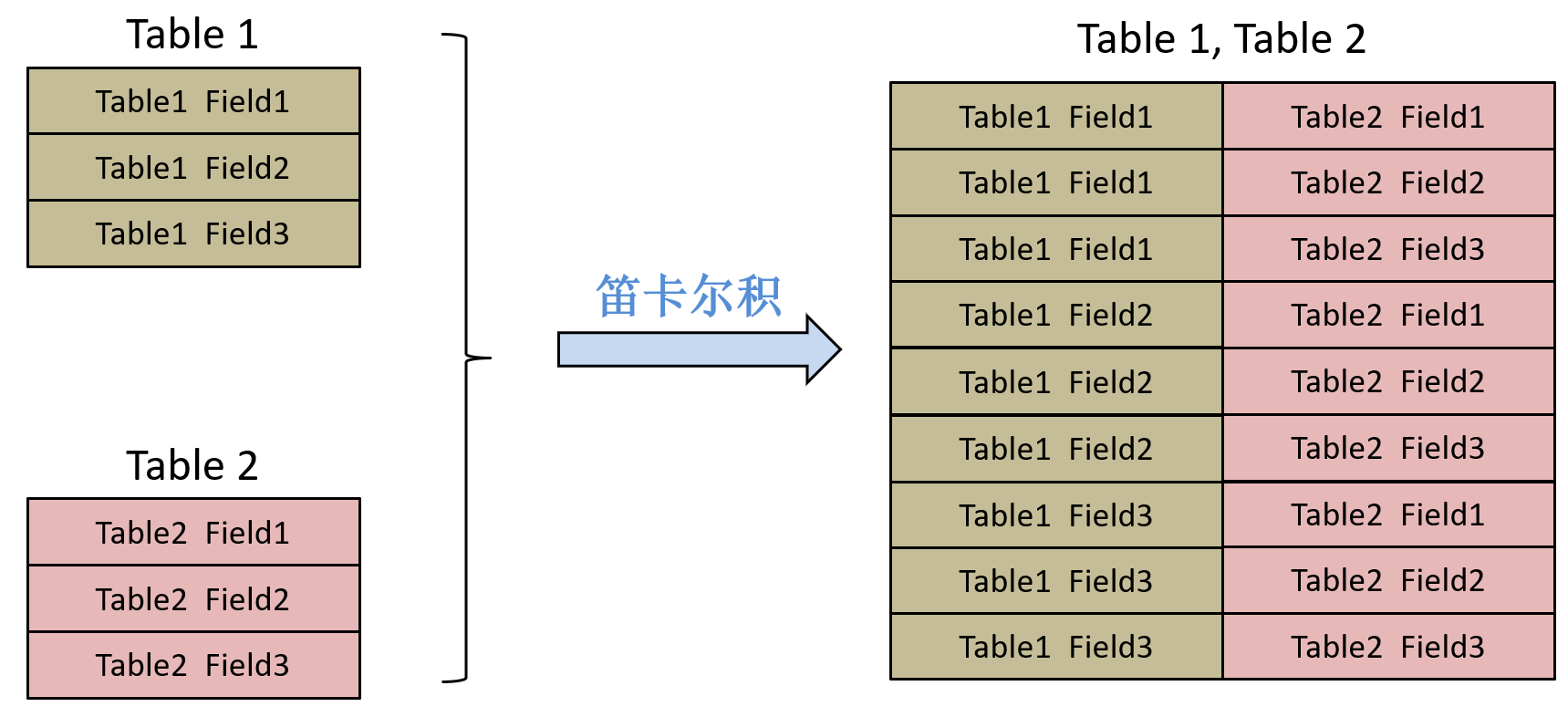
多张表进行组合,就是在对表进行笛卡尔积,图1.1为双表笛卡尔积运算的规则。由于实际项目中多张表之间可能会存在相互关联的字段,要对多表组合结果进行筛选去除非法组合,比如:对emp和dept表进行笛卡尔积组合运算时,emp表中的deptno字段和dept表中的deptno字段相同才有意义,因此要通过适当的where条件,将无效的组合去除。
MySQL还支持表的自连接,所谓自连接,就是同一张表连接其自身,图1.2为自连接的示意图,可以理解为两张完全相同的表做笛卡尔积。

- 显示部门号为20的部门名、员工姓名以及员工编号
部门名在表dept中,员工姓名和员工编号在表emp中,emp中还存有员工所属的部门编号,因此需要将表emp和dept进行组合,并通过emp.deptno=dept.deptno排除不正确的组合项。
mysql> select empno,ename,emp.deptno from emp,dept where emp.deptno=dept.deptno and emp.deptno=20;
+--------+-------+--------+
| empno | ename | deptno |
+--------+-------+--------+
| 007369 | SMITH | 20 |
| 007566 | JONES | 20 |
| 007788 | SCOTT | 20 |
| 007876 | ADAMS | 20 |
| 007902 | FORD | 20 |
+--------+-------+--------+
5 rows in set (0.00 sec)- 显示每个员工的姓名、薪资和薪资级别?
员工姓名和薪资在表emp中,薪资等级信息在表salgrade中,需要将表emp和salgrade进行组合查询。在salgrade表中存有每种薪资等级的最高薪资hisal和最低薪资losal,筛选满足条件losal <= sal <= hisal的行即可。
mysql> select ename,sal,grade from emp,salgrade -- 组合表
-> where sal>=losal and sal<=hisal; -- 筛选条件
+--------+---------+-------+
| ename | sal | grade |
+--------+---------+-------+
| SMITH | 800.00 | 1 |
| ALLEN | 1600.00 | 3 |
| WARD | 1250.00 | 2 |
| JONES | 2975.00 | 4 |
| MARTIN | 1250.00 | 2 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| KING | 5000.00 | 5 |
| TURNER | 1500.00 | 3 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| FORD | 3000.00 | 4 |
| MILLER | 1300.00 | 2 |
+--------+---------+-------+
14 rows in set (0.00 sec)二. 子查询
子查询,就是在where条件中,嵌入select语句来作为判断条件的一部分。
2.1 单行子查询
单行子查询,就是通过select筛选出来的条件为单行数据,通过where将特定字段的值与select结果进行比较,得到满足要求的结果。
语法:select ... from TableName where [... (select ...)];
- 查询薪资比CLARK高的员工姓名与薪资
在where条件中通过select子查询获取CLARK的薪资,筛选出sal大于CLARK薪资的行即可。
mysql> select ename,sal from emp where sal > (select sal from emp where ename='CLARK');
+-------+---------+
| ename | sal |
+-------+---------+
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| FORD | 3000.00 |
+-------+---------+
5 rows in set (0.00 sec)- 查询与SMITH属于同一部门的员工的工号、姓名和所属部门
mysql> select empno,ename,deptno from emp
-> where deptno = (select deptno from emp where ename='SMITH');
+--------+-------+--------+
| empno | ename | deptno |
+--------+-------+--------+
| 007369 | SMITH | 20 |
| 007566 | JONES | 20 |
| 007788 | SCOTT | 20 |
| 007876 | ADAMS | 20 |
| 007902 | FORD | 20 |
+--------+-------+--------+
5 rows in set (0.00 sec2.2 多行子查询
首先介绍in、all、any三个关键字:
- in:语法为in(选项1, 选项2, ... ),如果字段与in中选项之一完全匹配,那么返回结果为真,如:job in('MANAGER', 'CLERK', 'SALESMAN')的含义是,如果job是MANAGER、CLERK或者SALESMAN其中之一,就返回真。
- all:将特定关键字与all内的所有行进行比较,如果与所有行的比较都满足条件,那么返回真,否则返回假。如:sal!=all(30,40,50),sal不是30、40、50其中之一返回真,否则返回假。
- any:将特定关键字与any内的所有行进行比较,如果与其中某一行的比较为真,那么就返回真,否则返回假。如:sal = any(1000,2000),表示sal是1000或2000返回真,否则返回假。
下面三个案例,分别使用in、all、any进行多行子查询。
案例1:查询与10号部门工作岗位相同的员工工号、姓名、部门和岗位,但不包含10号部门员工
通过 in关键字 + select 子查询,将每个员工的job与10号部门具有的岗位进行比较,同时排除10号部门员工即可。
mysql> select empno,ename,deptno,job from emp where job in(select job from emp where deptno=10) and deptno!=10;
+--------+-------+--------+---------+
| empno | ename | deptno | job |
+--------+-------+--------+---------+
| 007566 | JONES | 20 | MANAGER |
| 007698 | BLAKE | 30 | MANAGER |
| 007369 | SMITH | 20 | CLERK |
| 007876 | ADAMS | 20 | CLERK |
| 007900 | JAMES | 30 | CLERK |
+--------+-------+--------+---------+
5 rows in set (0.00 sec)案例2:查询比30号部门所有员工工资都高的员工姓名、部门和工资
mysql> select ename,deptno,sal from emp where sal > all(select sal from emp where deptno=30);
+-------+--------+---------+
| ename | deptno | sal |
+-------+--------+---------+
| JONES | 20 | 2975.00 |
| SCOTT | 20 | 3000.00 |
| KING | 10 | 5000.00 |
| FORD | 20 | 3000.00 |
+-------+--------+---------+
4 rows in set (0.00 sec)案例三:查询比30号部门任意员工工资高的员工姓名、部门号和薪资,不包括30号部门员工
mysql> select ename,deptno,sal from emp where sal > any(select sal from emp where deptno=30);
+--------+--------+---------+
| ename | deptno | sal |
+--------+--------+---------+
| ALLEN | 30 | 1600.00 |
| WARD | 30 | 1250.00 |
| JONES | 20 | 2975.00 |
| MARTIN | 30 | 1250.00 |
| BLAKE | 30 | 2850.00 |
| CLARK | 10 | 2450.00 |
| SCOTT | 20 | 3000.00 |
| KING | 10 | 5000.00 |
| TURNER | 30 | 1500.00 |
| ADAMS | 20 | 1100.00 |
| FORD | 20 | 3000.00 |
| MILLER | 10 | 1300.00 |
+--------+--------+---------+
12 rows in set (0.00 sec)2.3 多列子查询
多列子查询,就是多个字段与select后的值进行比较,将要进行比较的字段使用圆括号括起来,每个字段之间通过逗号隔开。
语法:
select ...? from Table where (field1, filed2, ...) 运算符 (select field1, filed2, ... from Table)
- 查询与SMITH部门和岗位完全相同的员工的工号、姓名、岗位和部门
mysql> select empno,ename,deptno,job from emp
-> where (job,deptno) = (select job,deptno from emp where ename='SMITH')
-> and ename != 'SMITH';
+--------+-------+--------+-------+
| empno | ename | deptno | job |
+--------+-------+--------+-------+
| 007876 | ADAMS | 20 | CLERK |
+--------+-------+--------+-------+
1 row in set (0.00 sec)2.4 在from语句中使用子查询
在from语句中可以使用select子查询,方式一般为将select后的结果作为一张表,并给一个临时的名称,这张表一般会和其他的表进行组合,在组合后的表中进行查询。通过案例来演示如何在from中使用子查询。
- 获取高于自己部门平均工资的员工姓名、部门工资和平均工资
在表emp中通过group by对部门分组,结合avg(sal)计算每个部门的平均工资,通过select生成一张包含部门号和部门平均工资的临时表tmp,并将avg(sal)重命名为avg_sal,将tmp与emp表组合,通过tmp.deptno=emp.deptno去除错误的组合,通过sal>avg_sal筛选大于部门平均工资的员工。
mysql> select ename,emp.deptno,sal,avg_sal from emp,
-> (select avg(sal) avg_sal,deptno from emp group by deptno) tmp
-> where emp.deptno=tmp.deptno and sal>avg_sal;
+-------+--------+---------+-------------+
| ename | deptno | sal | avg_sal |
+-------+--------+---------+-------------+
| KING | 10 | 5000.00 | 2916.666667 |
| JONES | 20 | 2975.00 | 2175.000000 |
| SCOTT | 20 | 3000.00 | 2175.000000 |
| FORD | 20 | 3000.00 | 2175.000000 |
| ALLEN | 30 | 1600.00 | 1566.666667 |
| BLAKE | 30 | 2850.00 | 1566.666667 |
+-------+--------+---------+-------------+
6 rows in set (0.00 sec)- 获取每个部门工资最低的员工的姓名、部门和工资
创建一张包含部门号deptno和部门最低工资min(sal)的临时表tmp,将tmp和emp进行组合,筛选符合条件的数据。
mysql> select ename,emp.deptno,sal from emp,
-> (select min(sal) minSal,deptno from emp group by deptno) tmp
-> where sal=minSal and emp.deptno=tmp.deptno;
+--------+--------+---------+
| ename | deptno | sal |
+--------+--------+---------+
| SMITH | 20 | 800.00 |
| JAMES | 30 | 950.00 |
| MILLER | 10 | 1300.00 |
+--------+--------+---------+
3 rows in set (0.00 sec)- 显示每个部门的部门信息(部门号、部门名、地址)和人员数量
通过select筛选在emp中根据deptno分组统计人员数量,获取一张包括部门编号和部门人员数量的表tmp,将这张表tmp与表dept组合,筛选符合条件的数据即可。
mysql> select dept.deptno,dept.dname,dept.loc,tmp.countEmp from dept,
-> (select deptno,count(*) countEmp from emp group by deptno) tmp
-> where dept.deptno=tmp.deptno;
+--------+------------+----------+----------+
| deptno | dname | loc | countEmp |
+--------+------------+----------+----------+
| 10 | ACCOUNTING | NEW YORK | 3 |
| 20 | RESEARCH | DALLAS | 5 |
| 30 | SALES | CHICAGO | 6 |
+--------+------------+----------+----------+
3 rows in set (0.00 sec)三. 合并查询
3.1 union
union用于合并多个select语句筛选出来的数据(行),合并后的结果会自动去重。
- 筛选出职位是MANAGER或薪资大于2500的员工
mysql> select ename,job,sal from emp where job='MANAGER' union
-> select ename,job,sal from emp where sal>2500;
+-------+-----------+---------+
| ename | job | sal |
+-------+-----------+---------+
| JONES | MANAGER | 2975.00 |
| BLAKE | MANAGER | 2850.00 |
| CLARK | MANAGER | 2450.00 |
| SCOTT | ANALYST | 3000.00 |
| KING | PRESIDENT | 5000.00 |
| FORD | ANALYST | 3000.00 |
+-------+-----------+---------+
6 rows in set (0.00 sec)3.2 union all
union all与union类似,可以用于合并两条select语句的执行结果,与union不同的是,union all合并后的结果不会自动去重。使用union all筛选职位是MANAGER或薪资大于2500的员工,可见执行结果明显没有去重。
mysql> select ename,job,sal from emp where job='MANAGER' union all
-> select ename,job,sal from emp where sal>2500;
+-------+-----------+---------+
| ename | job | sal |
+-------+-----------+---------+
| JONES | MANAGER | 2975.00 |
| BLAKE | MANAGER | 2850.00 |
| CLARK | MANAGER | 2450.00 |
| JONES | MANAGER | 2975.00 |
| BLAKE | MANAGER | 2850.00 |
| SCOTT | ANALYST | 3000.00 |
| KING | PRESIDENT | 5000.00 |
| FORD | ANALYST | 3000.00 |
+-------+-----------+---------+
8 rows in set (0.00 sec)四. 总结
- 多表查询,就是将多个通过笛卡尔积组合的表作为一整张表进行查询,多表查询需要一些条件限制去除非法的组合。
- 子查询就是在查询条件语句中使用select语句充当条件的一部分,可以在where中使用select,也可以在from中使用select。
- union和union all可以合并两条select的结果,union会自动去重,union all不会去重。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AD-FMCOMMS3-EBZ 晶振 & 引脚
- count(*)、count(1)、count(column)的区别
- 一文搞懂系列——DBC数据库信号解析规则及案例
- Windows各版本如何看到文件扩展名,这个帖子很全
- 爱吃芝士的土豆倪-2023年度总结
- Subgraph mining in a large graph: A review(2022 WIREs DMKD)
- HashMap底层原理
- Python如何操作RabbitMQ实现direct关键字发布订阅模式?有录播直播私教课视频教程
- 【RT-DETR改进涨点】MPDIoU、InnerMPDIoU损失函数中的No.1(包含二次创新)
- 【基础篇】十一、JVM方法区