自动驾驶中大火的AI大模型中有哪些研究方向,与Transformer何干?
摘要:
本文将针对大模型学习中可能遇见的问题进行分析梳理,以帮助开发者在利用大模型在自动驾驶场景处理中学习更好的策略,利用有关大模型性能评价的问题,制定一个科学的标准去判断大模型的长处和不足。
随着自动驾驶行业发展对于大数据量处理的强大需求,其要求处理数据的模型需要不断积累丰富的处理经验。自动驾驶中的大模型处理作为当前 AI 领域最为火热的前沿趋势之一,可赋能自动驾驶领域的感知、标注、仿真训练等多个核心环节。同时,也可以有效的提升感知精确度,有利于后续规划控制算法的实施,促进端到端自动驾驶框架的发展。
实际上,要想在自动驾驶中应用好大模型训练和学习,就必须为其建立夯实的理论基础,尽量规避其所带来的负面效应。因为,大模型建得越来越大,结构种类、数据源种类、训练目标种类也越来越多,这些模型的性能提升到底有多少?在哪些方面我们仍需努力?
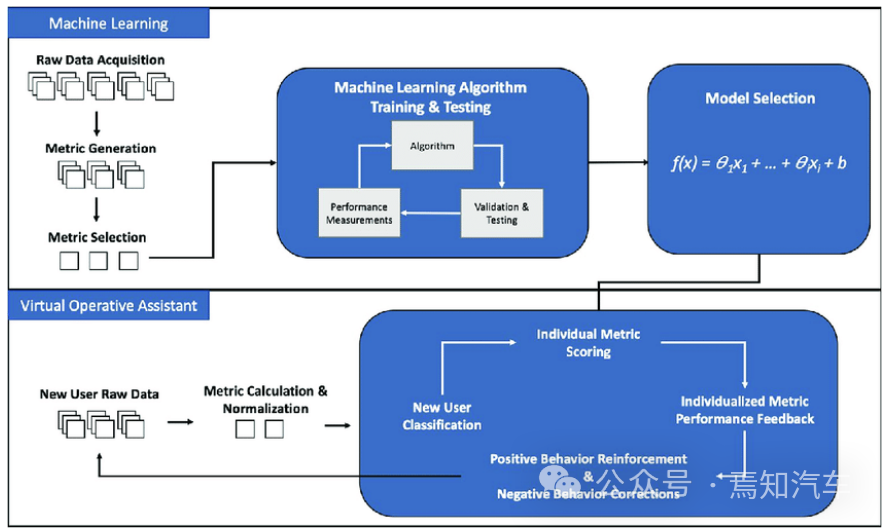
本文将针对大模型学习中可能遇见的问题进行分析梳理,以帮助开发者在利用大模型在自动驾驶场景处理中学习更好的策略,利用有关大模型性能评价的问题,制定一个科学的标准去判断大模型的长处和不足。比如可以通过逐层汇集模型在不同指标、数据集、任务和能力上的得分系统地评估模型在不同方面的表现,在大模型应用中择优避短。
要讲清楚这些问题,首先我们需要从“what”、“how”、“why”三个层面做引导分析。
大模型为何是智驾AI发展的必然?
为了讲清楚这个问题,我们这里以最早且应用最好的特斯拉为例说明整个技术变迁过程中如果利用大模型进行有效训练和学习的。
实际上,特斯拉在整个研发领域上经历了4个阶段的技术变迁:
第一阶段:使用常规的骨干网结构,采用2D检测器进行特征提取,训练数据为人工标注。这是一种相对比较原始和传统的模型学习和训练方式;
第二阶段:采用了HydraNet结构,加入特征提取网络BiFPN,将处理图像从图像空间直接转化为向量空间。这种方式能够有效的能执行多任务并行处理,相较于FPN,BiFPN能够更加充分的进行特征融合并且赋予不同特征权重,这样就在很大程度上避免了图像到向量空间中映射偏差。
第三阶段:为了更好的应用AI处理模型,主张去掉雷达,而使用纯视觉方案进行环境感知。并且在图像处理中加入Transformer,骨干网结构中加入了RegNet,同时数据标注中引入自动标注算法。这样更加简单、易理解,不仅解决了CNN算法在BEV遮挡区域的预测问题,保证在降低高复杂计算
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 云卷云舒:【实战篇】云主机/虚拟机迁移
- 9 Spring集成Mybatis
- SpringBoot配置多数据源
- HCIA-Cloud Computing H13-511题库(41~60)
- BUUCTF 喵喵喵 1
- python关闭windows进程的方法
- R语言实现文献计量分析(1)——bibliometrix
- springboot快速开始
- (四)STM32F407 cubemx定时器PWM驱动tb6612
- Spring Security 优化鉴权注解:自定义鉴权注解的崭新征程