DENet:用于可见水印去除的Disentangled Embedding网络笔记
1 Title
????????DENet: Disentangled Embedding Network for Visible Watermark Removal(Ruizhou Sun、Yukun Su、Qingyao Wu)[AAAI2023 Oral]
2 Conclusion
????????This paper propose a novel contrastive learning mechanism to disentangle the high-level embedding semantic information of the images and watermarks, driving the respective network branch more oriented. The proposed mechanism is leveraged for watermark image decomposition, which aims to decouple the clean image and watermark hints in the high-level embedding space.This can guarantee the learning representation of the restored image enjoy more task-specific cues.?In addition, this paper?introduce a self-attention-based enhancement module, which promotes?the network’s ability to capture semantic information among different regions, leading to further improvement on the contrastive learning mechanism
3 Good Sentences
? ? ? ? 1、These uncertain cues are then fed into the decoder for further image reconstruction, which may harm the network to model the useful information, explicitly. With this in mind, our goal is to disentangle their semantic embeddings in the high-dimensional space, driving the network focusing on different parts of the watermarks and clean image.(The motivation of this paper to proposed DENet)
? ? ? ? 2、Although the above mechanism provides additional supervision for disentangling network learning, it is hard to achieve ideal embedding with only conventional convolution layers,we adopt multi-head attention to capture information from different regions(Why need self-Attension Block)
? ? ? ? 3、we first conduct sensitivity analysis experiments of the parameters. Then, we remove
all modules and add them back incrementally to explore their effectiveness.(The necessity of the Ablation Study)
? ? ? ? 简介:本文提出了一种新的对比学习机制来解开图像和水印的高级嵌入语义信息,从而使相应的网络分支更加定向。此外,本文还引入了一个基于自注意的增强模块,该模块提高了网络在不同区域之间捕获语义信息的能力,从而进一步改进了对比学习机制。
? ? ? ? 介绍:水印去除方法作为一种对抗技术推动数字水印的发展。而随着深度学习的蓬勃发展,目前,人们将水印去除任务视为图像到图像的一个翻译问题,然而,目前的方法忽略了水印和无水印图像特征的高级语义嵌入。
????????以前的方法在单个编码器内捕获水印图像的语义信息,这将使它们的学习表示不那么具有鉴别性和分离性,这些不明确的线索被送到解码器中用于进一步的图像重建,在网络对有用信息进行明确建模时可能导致损害。
????????而本文提出的DENet,在高维空间中解开水印和无水印图像的语义嵌入,这可以为解码器重建图像提供更明确的提示。水印图像的解耦嵌入具有潜在内容的更加独立的分布。具体来说,本文提出了一种对比学习机制来解耦水印和无水印图像的语义信息。在本文中组织了两组对比度损失约束,并构造了一个暹罗网络来获得正负对。还引入了一个基于自我注意的增强模块,旨在增强对不同区域特征的感知。
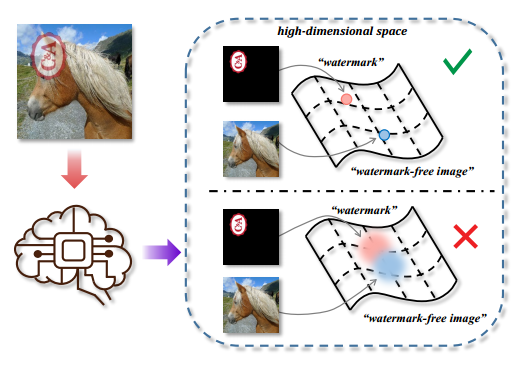
本文的主要贡献有三:
? ? ? ? 1、第一次尝试探索在高维空间中干净的图片和水印的不同嵌入的影响,并实验性地拉动正对,推开负对。
? ? ? ? 2、提出了一种用于水印去除的Disentangled Embedding网络,旨在通过对比学习机制在高级嵌入空间中解耦图像和水印表示,以获得更具定向的特征进行重建。以及提出了一个基于自注意的网络增强模块,用于捕获来自不同区域的信息。
? ? ? ? 3、?在不同数据集上进行的广泛实验评估验证了我们提出的方法的优越性和有效性。
? ? ? ? 相关工作:1、水印去除:随着深度学习的发展,出现了许多数据驱动的神经网络方法。其中一些仅将水印去除视为图像到图像的翻译任务。其他具有更好性能的替代方法在多任务学习框架内考虑了水印定位和水印去除。然而,上述方法都没有意识到解开不同任务之间的高级语义嵌入的重要性,并且仍然只是逐步接近不同的目标。
? ? ? ? ? ? ? ? ? ? ? ? ? ?2、对比学习:对比学习是一种在无监督视觉表示学习领域广泛应用的有效方法。对比学习的核心思想是构建正对和负对,并采用Info-NCE等损失函数来缩小正对之间的距离,扩大负对之间的差距。
? ? ? ? 方法:本文的目标是在高级空间中解开水印和无水印图像的嵌入,从而明确地向网络提供有价值的定向解耦信息。以下是提出的DENet的模型。
????????整体架构:第一阶段:包括带水印图片、无水印图片、水印三重输入,输入后提取的特征构成正对和负对,目标是最大化负对距离,最小化正对距离,以分解水印和无水印图像之间的分布。然后,这些特征被馈送到解码器中,并产生粗略的结果。
???????????????????????????????? 第二阶段:第一阶段的结果是输入,最终产生细化的输出。
???????????????????????????????????????????????测试阶段,只给定带水印的图像,它将经过预训练的网络,最终重建为无水印图像。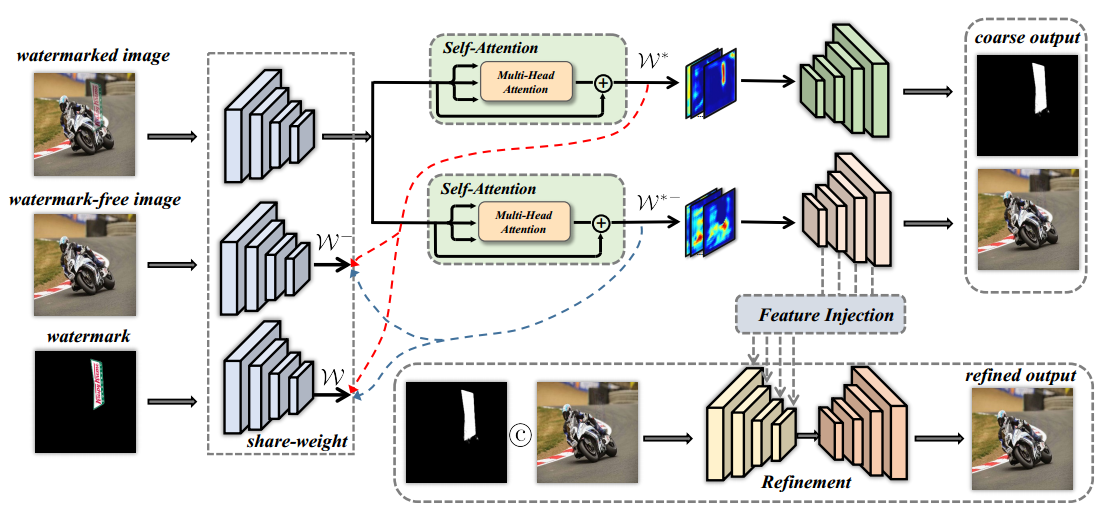
????????具体地说,在给定数据集中存在三种输入,包括带水印图像、无水印图像和水印,它们首先被送到共享权重编码器中以捕获语义信息。这样可以获得与无水印图像的特征和水印的特征相对应的语义嵌入和
。随后,将带水印图像的特征进一步发送到自注意力模块,对不同像素区域之间的语义信息进行建模,这将产生两个不同的嵌入
和
。如图中蓝色虚线和红色虚线所示,可以分别构建两个三元组,分别是{
,
,
}和{
,
,
},而对于每个三元组,目标是最小化正对距离,同时最大化负对距离。这样,可以在高维空间中解耦其的语义嵌入,获得更具定向的语义特征,这有利于后续的解码器网络分支。
????????随后,两个不同的解缠嵌入线索被送到相应的解码器中用于水印去除和水印定位,这分别产生粗的无水印图像和水印掩模。然后,将粗略结果连接在一起,并通过Unet架构中的细化网络。具体是对相同分辨率下的两个特征图采用张量元素相加运算。最后,细化网络将产生细化的重构无水印图像。
解缠嵌入机制(Disentangled Embedding Mechanism):
????????为了理清不同学习特征的嵌入,本文引入了对比学习机制。
? ? ? ? 下面将以为例,介绍该解缠嵌入机制。
????????给定无水印的图像嵌入∈
以及编码特征
,
∈
。
? ? ? ? 首先,对数据集中给定的水印掩码进行下采样(Downsample),得到∈
,并且能够将嵌入重新表达如下:
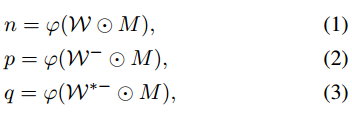 其中⊙表示逐元素乘法,φ表示全局平均池,查询q应该与其正密钥p相似,而与负密钥n不同。
其中⊙表示逐元素乘法,φ表示全局平均池,查询q应该与其正密钥p相似,而与负密钥n不同。
????????在实际应用中,不能直接将水印图像输入共享权重编码器。相反,要在水印的黑色区域填充与无水印图像相同的内容,否则 0 的无用信息会对编码器造成损害。在本文中,通过使用公式(3) 可以删除之前填充的内容。
? ? ? ? 朴素距离(?)(Naive Distance):可以只考虑正对,并尝试使它们的嵌入距离随着损失而更近,这可以如下执行:
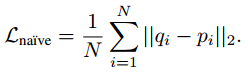 。这种方法效果不太好。
。这种方法效果不太好。
? ? ? ? 三元距离(Triplet Distance):上个距离的问题在于没有考虑负对,这里综合考虑正对和负对的距离,把损失定义为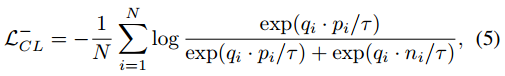 ,
,是控制权重的参数。
与上述相反,把
视作查询,{
}是正密钥和负密钥。
????????自注意力模块(Self-Attention Block):仅用传统的卷积层很难实现理想的嵌入。因此,本文采用多头注意力来捕捉来自不同地区的信息。给定输入X,对于第i个头,函数公式化如下: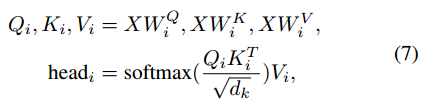
,
,
是三个投影矩阵,
是特征维度,最后将来自不同头的所有特征连接起来作为输出。
? ? ? ? 端到端训练(End-to-end Training):本文所提出的框架是一个端到端网络,所有模块都在一次反向传播中更新。训练阶段使用的损失函数如下。根据Hertz et al. 2019的方法,二进制交叉熵损失应用于监督具有ground truth:的水印掩码
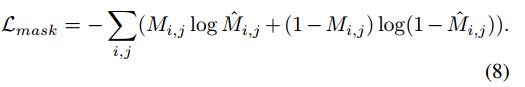
而给定无水印的ground truth:,粗略输出图像
和精细化的输出图像
,使用L1损失来压缩ground truth和预测输出之间的差距:
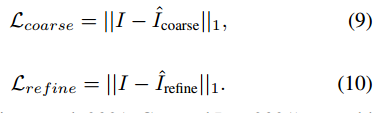
再添加额外的深度感知损失,以获得更高质量的输出,其中表示预训练的VGG16中第k层的激活图
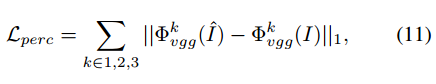
最后,将上述所有损失函数进行组合,得到具有可控超参数的最终损失函数
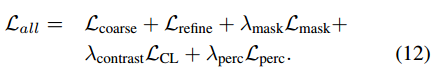
实验部分:
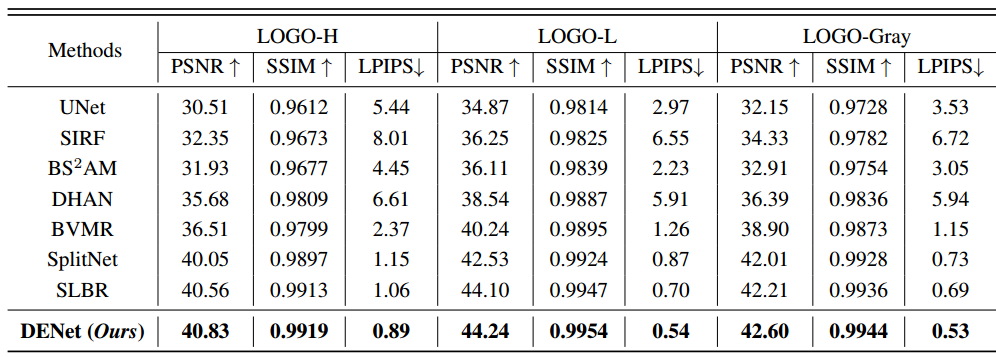
? ? ? ? 数据集介绍:所有实验都是在LOGO系列数据集上进行的。LOGO-L包含12151张用于训练的水印图像和2025张用于测试的图像。在该数据集中,水印透明度范围在35%到60%之间,水印大小也被调整为原始图像的35%到60%。LOGO-H包含与LOGO-L相同数量的图像,但该数据集中的水印大小占60%至80%,透明度设置为60%至85%。因此,由于缺少纹理和较大的水印区域,与LOGO-L相比,这是一个更难实现去水印的数据集。LOGO-Gray:该数据集还包括12151张用于训练的图像和2025张用于测试的图像。与上述两个数据集不同,嵌入的水印只包含灰度图像。
? ? ? ? 实现细节:本文提出的方法通过pytorch实现,训练200个epoches,输入的图像分辨率为256*256,选择Adam作为优化器,学习率为1e-3,批量大小为16,公式7中的超参数为=1,
=0.25,
=0.25,实验在几个流行的指标上评估了该方法,如峰值信噪比(PSNR)、结构相似性(SSIM)和深度感知相似性(LPIPS)。
本文还对这个方法做了消融实验以及对应的可视化。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!