浅谈 Raft 分布式一致性协议|图解 Raft
前言
大家好,这里是白泽。本文是一年多前参加字节训练营针对 Raft 自我整理的笔记。
本篇文章将模拟一个KV数据读写服务,从提供单一节点读写服务,到结合分布式一致性协议(Raft)后,逐步扩展为一个分布式的,满足一致性读写需求的读写服务的过程。
其中将配合引入Raft协议的种种概念:选主、一致性、共识、安全等,通篇阅读之后,将帮助你深刻理解什么是分布式一致性协议。
一、 单机KV数据读写服务

DB Engine这里可以简单看成对数据的状态进行存储(比如B+树型的组织形式),负责存储KV的内容 ,并假设这个KV服务将提供如下接口:
- Get(key) —> value
- Put([key, value])
思考此时KV服务的可靠性:
- 容错:单个数据存储节点,不具备容错能力。
- 高可用:服务部署在单节点上,节点宕机将无法提供服务。
思考此时KV服务的正确性:
- 单进程,所有操作顺序执行,可以保证已经存储的数据是正确的
数据规模不断增加,我们需要扩大这个KV服务的规模,将其构建成一个分布式的系统
二、一致性与共识算法
2.1 从复制开始
既然一个节点会挂,那么我们就多准备一个节点!
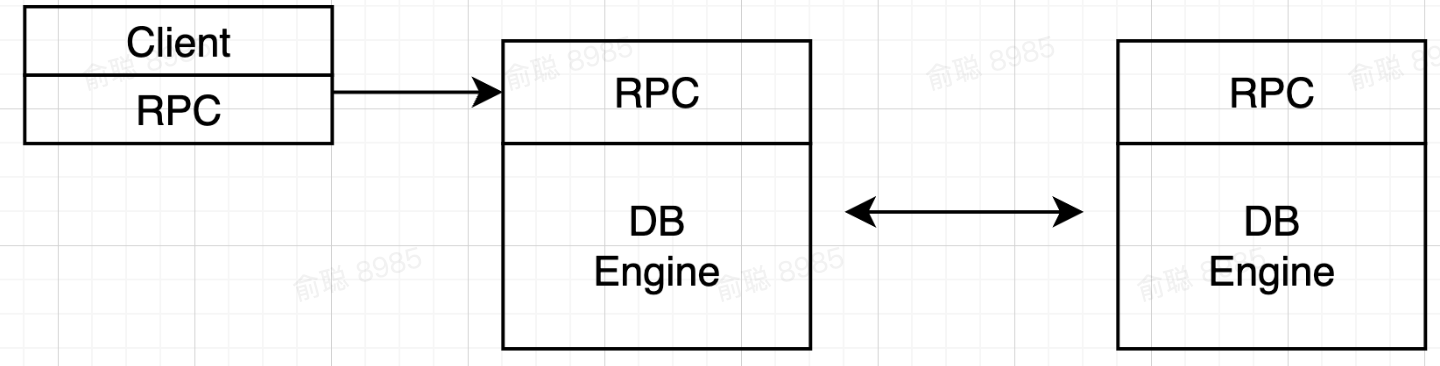
我们这里只考虑主副本负责接收数据,而从副本只负责同步接收主副本数据的模式,如果主从都开放数据接收能力,将要考虑更多高可用和数据一致性的问题。
2.2 如何复制
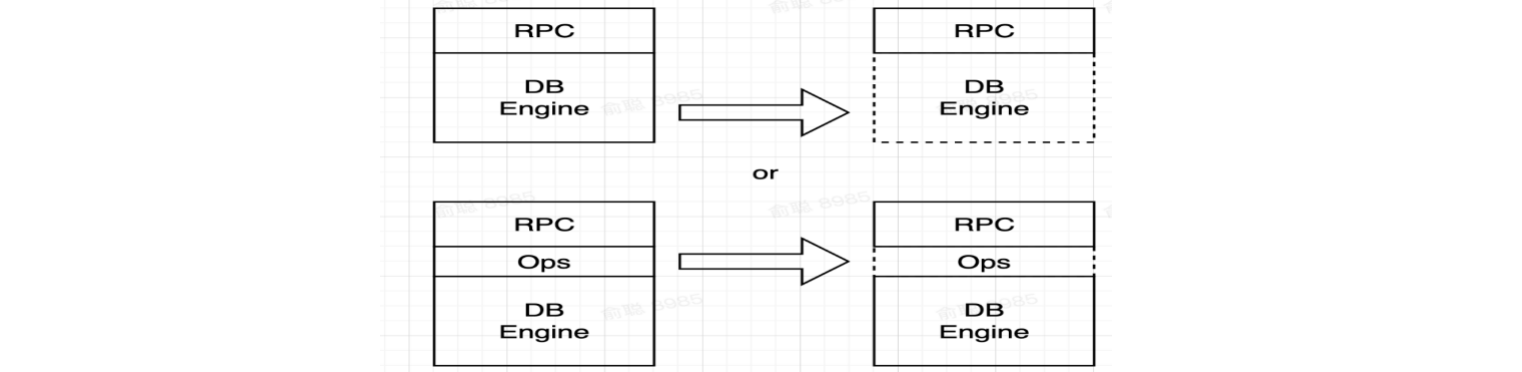
- 主副本定期拷贝全量数据到从副本(代价太高)
- 主副本拷贝操作日志到从副本:如果你了解MySQL的主从同步,你就会想起它也是通过从副本监听主副本当中的
bin log操作日志变化,进行集群数据同步的,因此这种方式也是更主流的选择。
2.3 具体的写流程
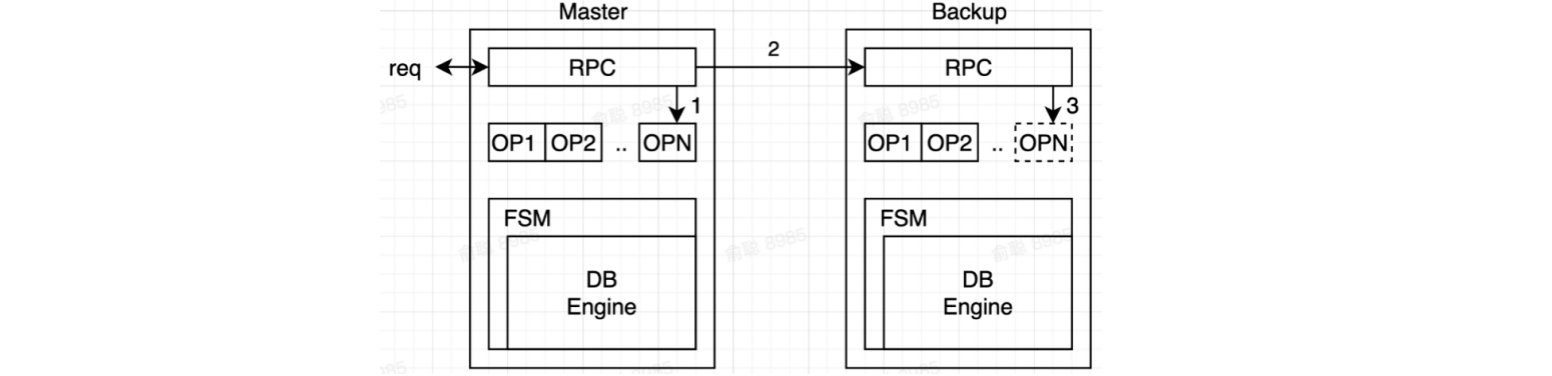
-
主副本把所有的操作打包成
Log- 所有的
Log写入都是持久化的,保存在磁盘上
- 所有的
-
应用包装成状态机(也就是DB Engine部分),只接收
Log作为Input -
主副本确认
Log已经成功写入到从副本机器上,当状态机apply后,返回客户端(关于写入之后,请求返回客户端的时机,是可以由应用控制的,可以是Log写入从副本之后,就从主副本机器返回,也可以等Log完成落盘之后,再返回)
2.4 具体的读流程
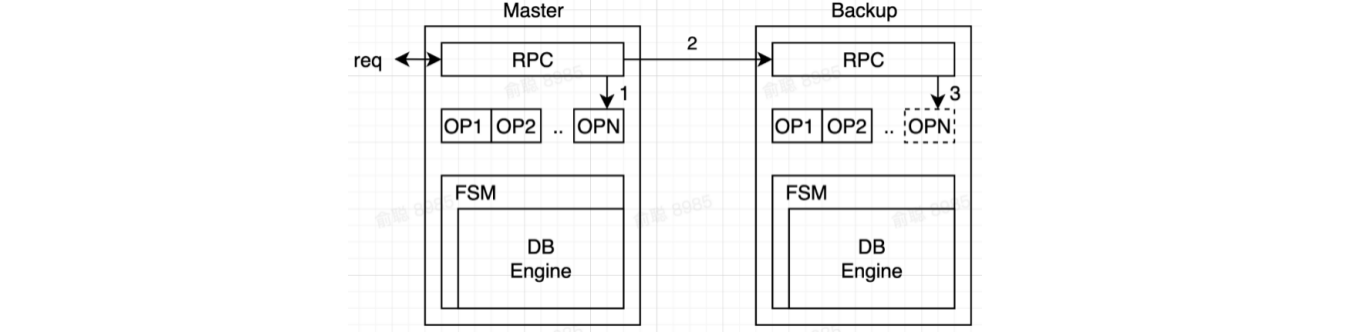
- 方案一:直接读状态机(这里指的是DB),要求上一步写操作进入状态机后再返回client(数据已落盘)
- 方案二:写操作复制
Log完成后直接返回,读操作Block等待所有pending log进入状态机
- 如果不遵循上述两种方案:可能存在刚刚写入的值读不到的情况(在Log中)
2.5 什么是一致性
对于我们的KV服务,要像操作一台机器一样,对用户来说在写入成功后,就应该能读到最近写入的值,而不关心具体底层是如何分布式实现。
一致性是一种模型(或语义),约定一个分布式系统如何向外界提供服务,KV服务中常见的一致性模型有以下两种:
- 最终一致性:读取可能暂时读不到但是总会读到
- 线性一致性:最严格,线性时间执行(写完KV确保就能读到),是最理想中的状态
2.6 复制协议-当失效发生
上述用到的添加了一个从副本节点的方式,我们暂且将其称为山寨版分布式一致性协议——复制协议(因为它依赖于主从副本间的复制操作)
那么当主副本失效时,以这个复制协议为基础的KV服务的运行情况如何呢:
- 容错能力:没有容错能力,因为主副本停了,KV服务就停了
- 高可用:或许有,取决于我们发现主副本宕机后多快将从副本切换为主副本(手动切换)
- 正确性:正确,因为操作只从一台机器发起,可以控制所有操作返回前都已经复制到另一台机器了
衍生出的一些的问题:
- 如何保证主副本是真的失效了,切换的过程中如果主副本又开始接收
client请求,则会出现Log覆盖写的情况 - 如果增加到3个乃至更多的节点,每次PUT数据的请求都等待其他节点操作落盘性能较差
- 能否允许少数节点挂了的情况下,仍然可以保持服务能工作(具备容错能力)
2.7 共识算法
什么是共识:一个值一旦确定,所有人都认同
共识协议不等于一致性:
-
应用层面不同的一致性,都可以用共识算法来实现
- 比如可以故意返回旧的值(共识算法只是一个彼此的约定,只要数据存储与获取符合需求,达成共识即可)
-
简单的复制协议也可以提供线性一致性(虽然不容错)
一般讨论共识协议时提到的一致性,都指线性一致性
- 因为弱一致性往往可以使用相对简单的复制算法实现
三、一致性协议案例:Raft
3.1 Ratf概述

-
2014年发表
-
易于理解作为算法设计的目标
- 使用了RSM、Log、RPC的概念
- 直接使用RPC对算法进行了描述
- Strong Leader-based(所有操作都是Leader发起的)
- 使用了随机的方法减少约束(比如选主时Follower谁先发现Leader失联就发起选主)
3.2 复制状态机(RSM)

-
RSM(replicated state machine)
- Raft中所有的共识机制(consensus)都是直接使用Log作为载体:简单说就是client将Log提供给Raft(也就是上图的Consensus Module),Raft确定这个Log已经Commit之后(写入Log文件),将Log提供给用户的状态机
- 注意此时状态机是一个内存中的存储概念,当然后续每个节点数据还涉及到落盘持久化,这是具体应用层面的问题了,这里讨论的更多是Raft协议的原理概念,使用状态机对此进行抽象
-
Commited Index(这里先有个概念,用于标识Log中哪些数据可以提交给状态机)
- 一旦Raft更新Commited Index,意味着这个Index前所有的Log都可以提交给状态机了
- Commited Index是不持久化的,状态机也是volatile的(断电清空),重启后从第一条Log开始恢复状态机,Raft协议工作过程中每个节点的Commited Index可能是不一致的,但是Ratf可以保证最终所有节点都是一致的
3.3 Raft角色

- Leader是所有操作的发起者,会把Log同步给Follower,确定哪个Log已经Commit了
- 接受Leader的请求,并且在发现Leader消失,则转换为Candidate,向其他Follower申请投票,如果获得票数过半,则晋升为Leader
3.4 Raft日志复制
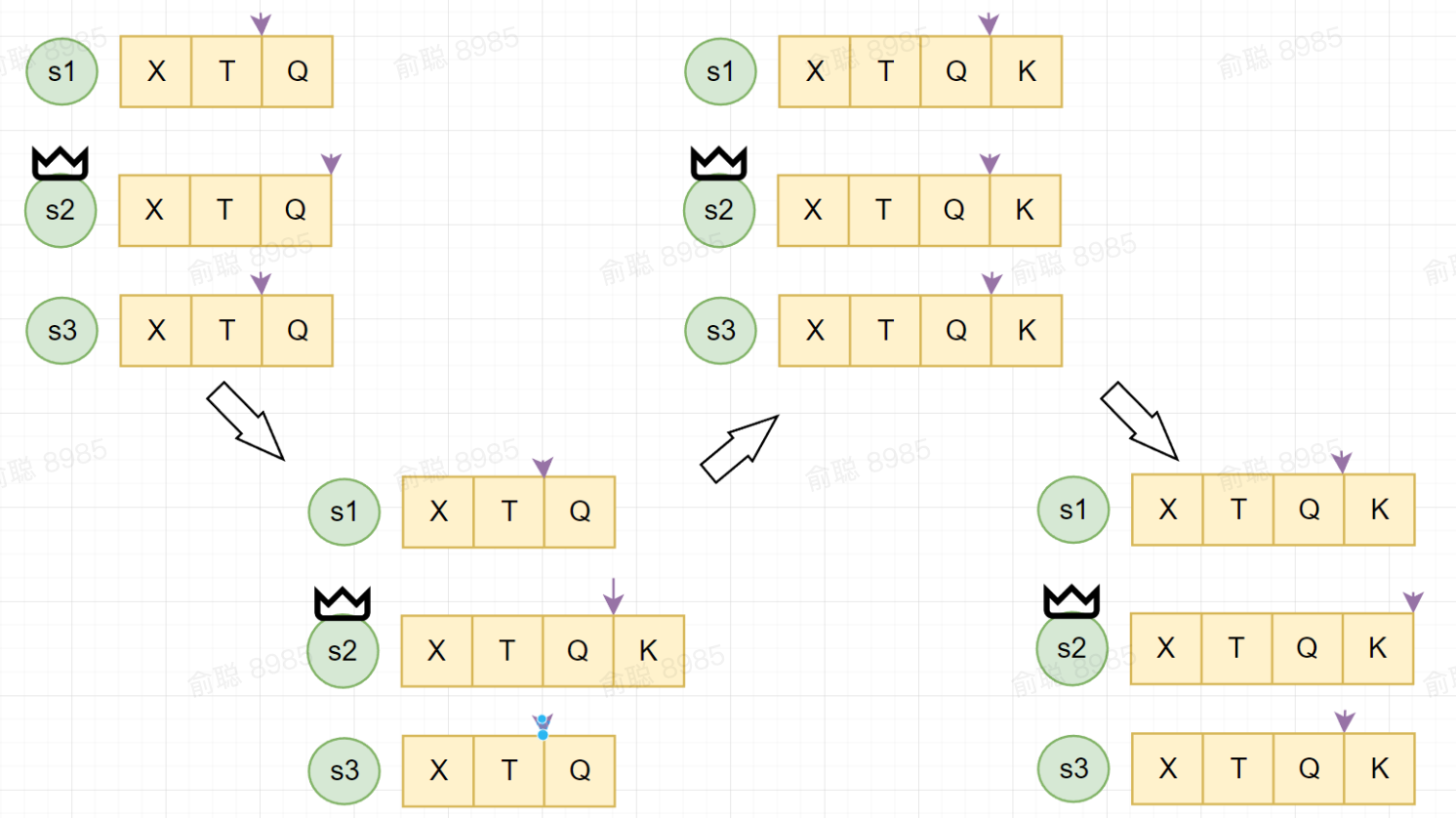
接下来讲解一下Raft协议中Log是如何在节点间同步的:
- 第一张图s2是当前Leader,紫色的小箭头指向每个节点已经确认commit的Log位置
- 第二张图s2又append了一条新的Log,用K标识
- 第三张图表示,s2将自己收到的K以及自己的Commited Index发送给所有Follower节点。Follower都同步Leader的Log以及Commited Index,并且Follower的状态机检测到自己的Commited Index又向前推进了,说明有新的Log值达成了共识,就会把Commited Index没读取的Log值应用给状态机
- 第四张图,当Follower完成步骤三的操作之后,会告诉Leader自己已经拿到这个Log值了,Leader在收到多数派的确认消息后,就可以确定这个K已经永远的持久化,也就是已经Commit了,因此将Commited Index向后推一位
这里有一个细节就是,虽然Raft协议使节点间的数据最终达成了一致,但是节点Log数据落盘时间是有先后的(因为Commited Index在各节点之间存在差异,所以Log与状态机是有时差的)
3.5 Raft从节点失效
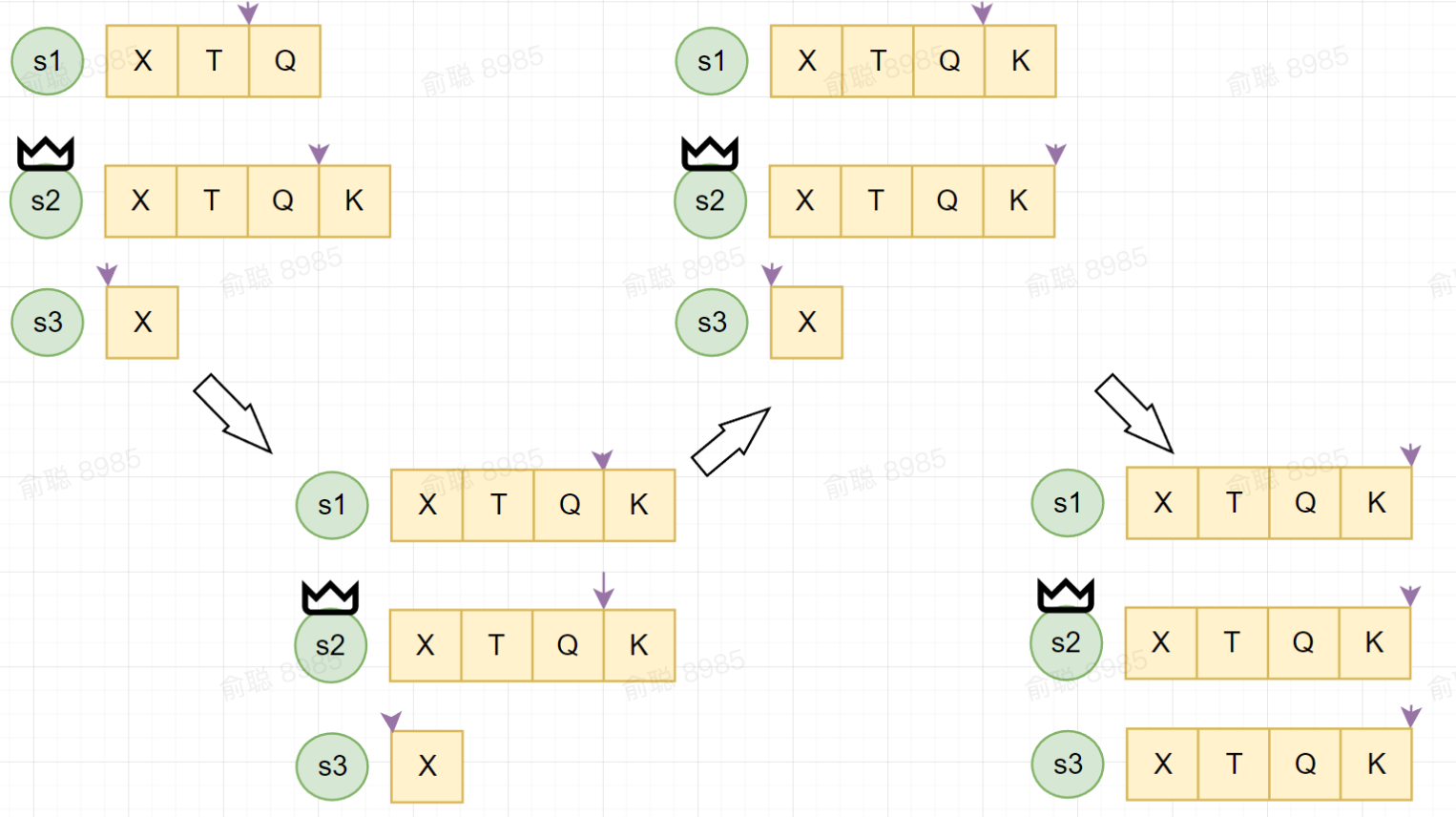
- 图一假设s3失效了很久,Log有很多数据没有同步
- 图二表示此时的Leader是s2,将自己Log中的K和自己的Commited Index复制给s1
- 图三中s2的K完成了commit(流程参考Raft日志复制),因为s1、s2共两个节点已经形成了多数派(此时已经有容错能力了)
- 图四中,s3尝试重新同步数据,在Raft协议中,s3会向s2逆向迭代的去获取Log数据(K、QK、TQK、XTQK),直到与s3当前Log相对齐则完成数据同步(当然Raft具体实现中应用对此过程进行了优化)
3.6 Raft Term
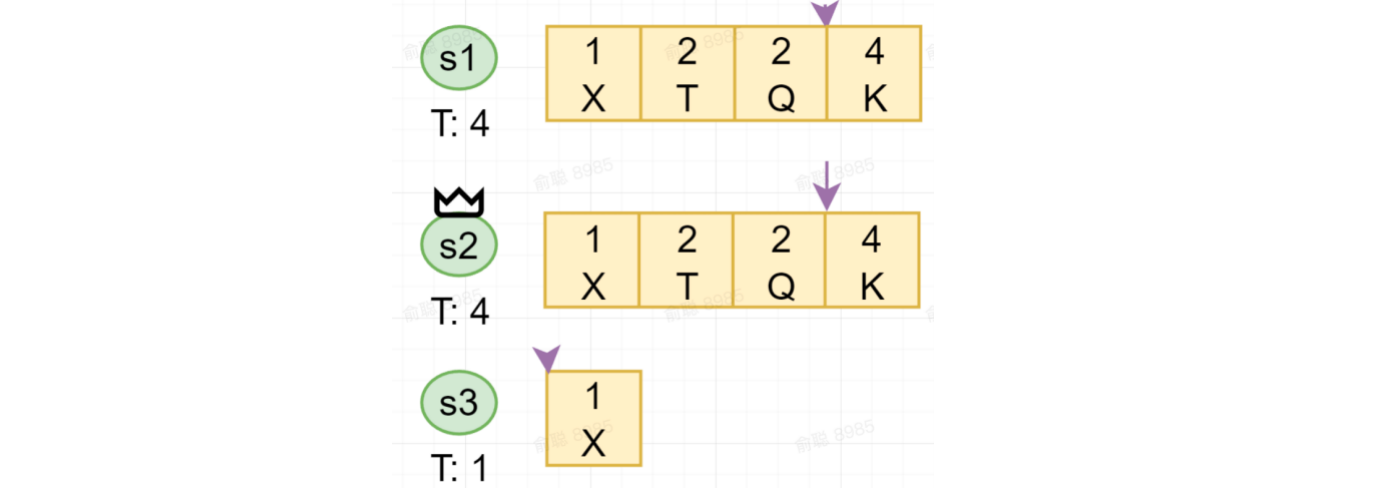
Term(周期的概念),在Raft中相当于一个逻辑的时钟,下面介绍:
- 每个Leader服务于一个term:一旦发现更高的term,那么表示我已经不是Leader了
- 每个term至多只有一个leader:选出新的Leader,会使得term增加
- 每个节点存储当前的term
- 每个节点term从一开始,只增不减
- 所有的rpc的request response 都携带term
- 只commit本term内的log
3.7 Raft主节点失效
-
Leader定期发送AppendEntries RPCs 给其余所有的节点
-
如果Follower 有一段时间没有收到Leader的AppendEntries,则转换身份为Candidate
-
Candidate自增自己的term,同时使用RequestVote PRCs 向剩余节点请求投票
- raft在检查是否可以投票时,会检查log是否outdated,至少不比本身旧才会投票给对应的Candidate
-
如果多数派投给它,则成为该term的leader
3.8 Raft Leader failure
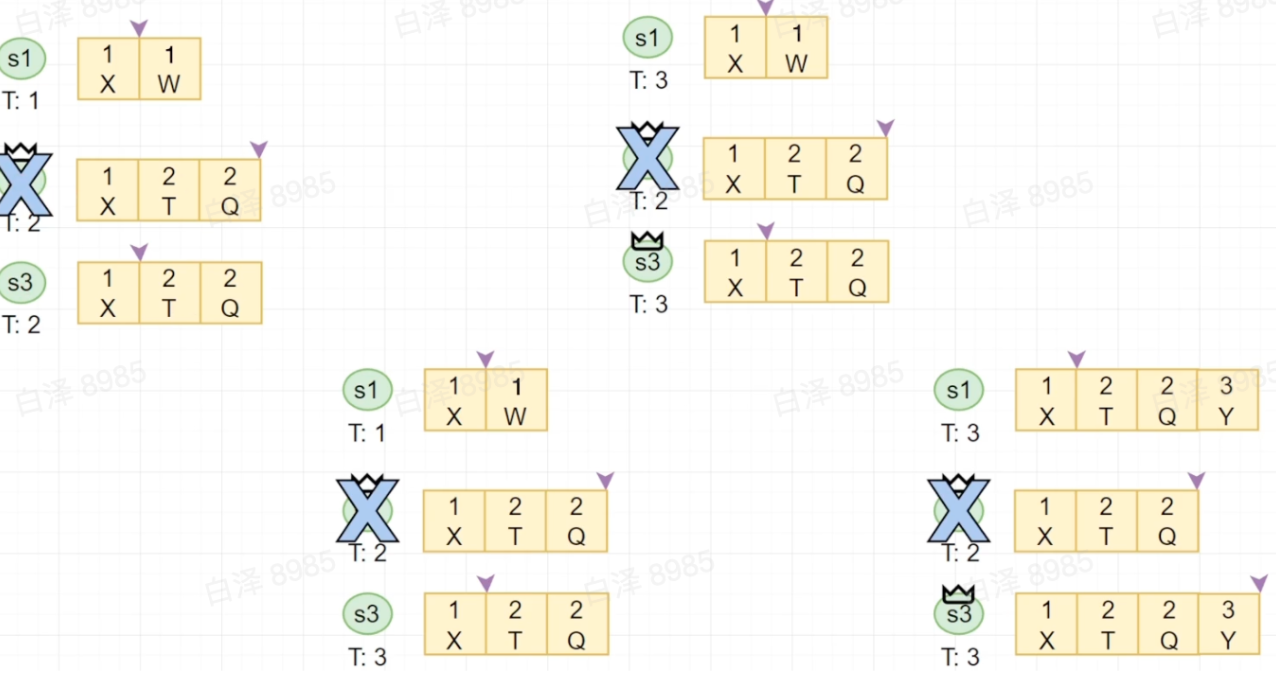
接下来模拟一下主节点失效后的流程,并且注意此时图一当中,s1的Log内容比较特殊,为XW,这个场景是可以实现的,比如一开始有s1、s2、s3,其中s1是Leader,首先将X同步给了s2和s3,并且接受到了新的W,但是突然s1节点卡死了,s2和s3重新开始选举Leader为s2,最终s2和s3的Log变成了XTQ(这只是一种情况,一切皆有可能),然后s1又恢复了。
关于为什么s3落后s2两条Commited Index,有可能是s2一次同步了两条Log给s3,而s3的状态机还没来得及同步数据,但是s3接收到在标识TQ的Log后,将其commit到自己的Log之中,就返回确认响应给了s2,s2将自己的Commited Index向后推进到Q的位置。
- 从图二开始,s3发现s2挂了,没有Leader,则将自己的term+1变为3,并且向s1请求Vote
- 图三中,s1发现RequestVote是来自term等于3的,大于自己的term,因此将自己的term也更新为3,同时答应给s3投票,达成多数派条件,s3成为新的Leader
- 图四,s3开始同步自己的Log给s1,但是发现s1中的Log起初为XW,而s3中为XTQY,因此还是会按照从后往前迭代的方式将数据同步给s1(Y、QY、TQY、XTQY),最后s1虽然与同步状态发生了冲突,但是由于Raft是
Strong Leader-based的,会完全按照Leader的内容覆盖自己的Log
3.9 Raft 安全性 - 同 Term
-
对于Term内的安全性
- 目标:对于所有已经commited的<term, index>位置上至多只有一条log
-
由于Raft的多数派选举,我们可以保证在一个term中只有一个leader
- 我们可以证明一条更严格的声明:在任何<term, index>位置上,至多只有一条log
3.10 Raft 安全性 - 跨 Term
-
对于跨Term的安全性
- 目标:如果一个log被标记commited,那这个log一定会在未来所有的leader中出现
-
可以证明这个property:
- Raft选举时会检查Log是否outdated,只有最新的才能当选Leader
- 选举需要多数派投票,而commited log也已经在多数派当中(必有overlap)
- 新Leader一定持有commited log,且Leader永远不会overwrite log
四、回到KV
4.1 重新打造KV服务
结合Raft算法,更新一下我们的KV
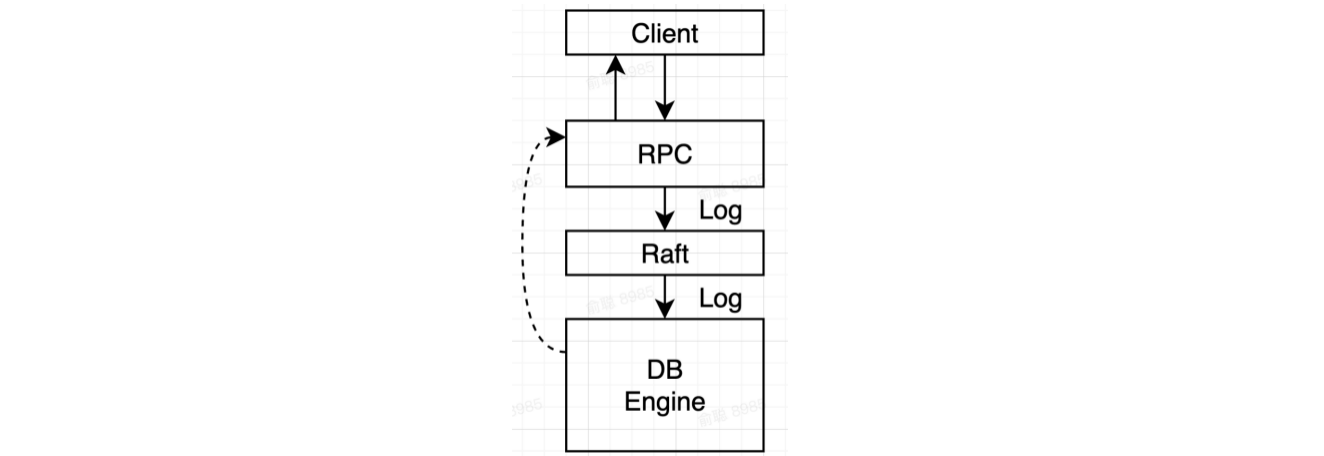
回顾一下一致性读写的定义:
-
方案一:
- 写log被commit了,返回客户端成功
- 读操作也写入一条log(因为读的数据可能还没从Log写入状态机,无法读取状态机数据),状态机apply log后返回client
- 增加Log量
-
方案二:
- 写log被commit了,返回客户端成功
- 读操作先等待所有commited log apply,再读取状态机
- 优化写时延
-
方案三:
- 写log被状态机apply,返回给client
- 读操作直接读状态机
- 优化读时延
多个副本只有单个副本可以提供服务(一个Leader万一忙不过来怎么办)
-
服务无法水平扩展
-
增加更多Raft组(不多展开)
- 如果操作跨Raft组(对key进行分组,每一个Raft负责读写一个range的key)
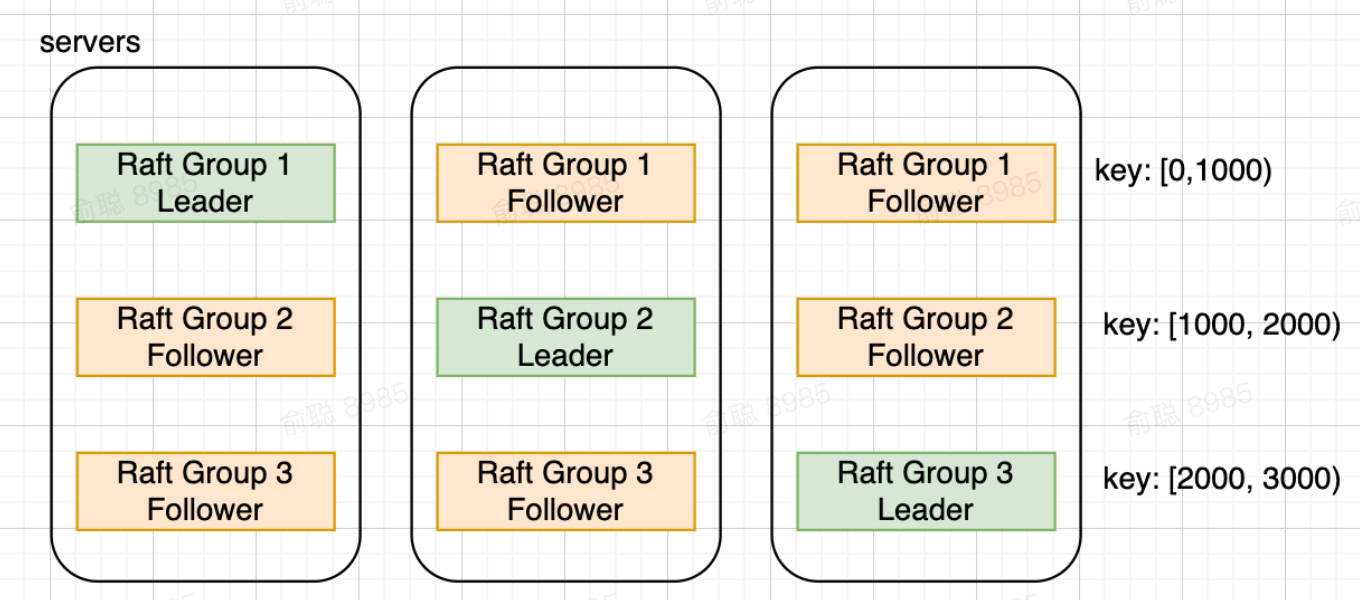
4.2 回到共识算法
-
Raft:关于log
- 论文中就给出的方案,当过多的Log产生后,启动snapshot,替换掉Log
- 如果对于持久化的状态机,如何快速的产生Snapshot(略)
- 多组Raft的应用中,Log如何合流(略)
-
关于configuration change(节点规模变化)
- 论文中就给出的joint-consensus以及单一节点变更两种方案(很复杂,略)

4.3 共识算法的未来
-
Raft Paxos相互移植
-
Raft有很多成熟的实现
-
研究主要关注在Paxos上
-
如何关联两种算法:
- On the Parallels between Paxos and Raft, and how to Port Optimizations[1]
- Paxos vs Raft: Have we reached consensus on distributed consensus?[2]
-
感兴趣可以关注公众号 「白泽talk」,白泽目前也打算打造一个氛围良好的行业交流群,文章的更新也会提前预告,欢迎加入:622383022。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HTTP数据请求
- YHZ001 Python 简介
- sonarqube api调用
- SketchUp各版本安装指南
- 搭建网站环境(IIS+php+mysql)
- 4.qml 3D-Light、DirectionalLight、PointLight、SpotLight、AxisHelper类深入学习
- 算法训练第五十九天|503. 下一个更大元素 II、42. 接雨水
- 第二天,数据类型和变量!
- JWT 实现登录认证功能及Cookie、Session 和 Token的区别
- 11、可扩展的Mysql