HDFS基于动态代理的客户端运行逻辑
前言
在我的上一片文章《Hadoop UnknownHostException事故解析》这篇文章中,分析了我们客户端由于一个HDFS的BUG导致HDFS客户端无法从短暂的域名解析失败中恢复的问题。
本文以此拓展开,详细解析整个HDFS客户端基于动态代理的、从上而下的调用逻辑。本文关注的重点是动态代理的层层封装,以及基于动态代理实现的统一的重试逻辑。
一个简单的动态代理的例子
动态代理的基本概念
动态代理的文章其实网上非常多,在本文最后引用了一些动态代理的相关文章。这里只是简单讲一下动态代理,然后分析一下Java客户端大量使用的动态代理。
关于动态代理和静态代理、动态代理的不同实现方式,网上的文章很多,读者可以自行阅读,比如:《 Java动态代理详解》,本文只简单描述Hadoop客户端使用的基于JDK Proxy的动态代理。
做过Java web开发的一定会对Spring的面向切面编程有所了解,面向切面编程就是在已有的代码运行逻辑基础上,动态定义一些切面(Aspect),这些切面可以在某个运行逻辑之前运行(比如,鉴权等),或者在某个运行逻辑之后运行(比如性能统计,日志,异常处理)等。这就是动态代理的最典型使用场景。所以,总的来说,通过动态代理,JVM会根据当前的基于某个接口(抽象主题角色)的具体实现(真实主题角色),通过反射机制,任意重写这个接口的实现,生成对应的代理类字节码(代理主题角色),并且刚好这个代理主题角色类也是抽象主题角色的实现类,只不过具体实现已经被修改。
在Hadoop中,动态代理主要用来在基本的RPC调用的基础上,通过动态代理,来添加重试逻辑。这样,重试逻辑和具体业务代码解耦合,即,在客户端,RPC调用本身的代码逻辑无需关心重试逻辑,而重试逻辑本身无需关心具体。
动态代理的简单例子
一个简单的动态代理的例子如下:
- 首先创建一个接口和这个接口的基本实现,用来模拟HDFS客户端。我们假如这个HDFS客户端只有一个方法,
mkdir():
public interface HDFSClientProtocol {
void mkdir();
}
public class HDFSClientProtocolImpl implements HDFSClientProtocol {
public void mkdir() {
System.out.println("Try to make dir in HDFS");
}
}
- 我们创建对应的调用处理器(
InvocationHandler),即对代理的逻辑进行处理,这个InvocationHandler只做一件事情,就是为基本的客户端方法mkdir()在外面添加异常以后的重试逻辑。InvocationHandler是JVM中基于JDK Proxy实现动态代理必须要实现的接口。
InvocationHandler接口的实现类(InvocationHandlerForRetry)不需要实现抽象主题角色接口(HDFSClientProtocol),而是在它实现InvocationHandler.invoke()的时候,统一对被代理的方法进行重写和侵入。
public class InvocationHandlerForRetry implements InvocationHandler {
Object target; // 被代理的对象实例
public InvocationHandlerForRetry(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try{
Object result = method.invoke(target, args); // 调用 target 的 method 方法
return result; // 返回方法的执行结果
}catch (Exception e){ // 添加重试逻辑
return method.invoke(target, args);
}
}
}
- 客户端调用
public class Client {
public static void main(String[] args){
// 1. 创建被代理的对象,HDFSClientProtocol接口的实现类
HDFSClientProtocolImpl hdfsClientProtocolImpl = new HDFSClientProtocolImpl();
// 2. 获取对应的 ClassLoader
ClassLoader classLoader = hdfsClientProtocolImpl.getClass().getClassLoader();
// 3. 获取所有接口的Class,这里的HDFSClientProtocolImpl只实现了一个接口UserService,
Class[] interfaces = hdfsClientProtocolImpl.getClass().getInterfaces();
// 4. 创建一个将传给代理类的调用请求处理器,处理所有的代理对象上的方法调用
// 这里创建的是一个自定义的重试处理逻辑,须传入实际的执行对象 userServiceImpl
InvocationHandler invocationHandlerForRetry = new InvocationHandlerForRetry(hdfsClientProtocolImpl);
// 创建代理类proxy
HDFSClientProtocol proxy = (HDFSClientProtocol) Proxy.newProxyInstance(classLoader, interfaces, invocationHandlerForRetry);
// 调用代理的方法,自动有了重试逻辑
proxy.mkdir();
}
}
所以,动态代理的最核心过程就是定义好InvocationHandler,这个InvocationHandler定义了代理的具体逻辑,然后,通过Proxy.newProxyInstance()来生成对应的Proxy。Hadoop中也是这样做的。
客户端对重试逻辑的抽象
RetryPolicy的定义
RetryPolicy是一个接口,从接口方法就可以看到它的功能:根据当前的失败上下文,决定下一步的重试策略(包括不重试)。它有两个内部类,RetryAction和RetryDecision。下文讲解。
注意,这一部分代码在hadoop-common这个sub module中,因此,RetryPolicy是给Yarn和HDFS共同使用的。我们下面在介绍不同的RetryPolicy的实现的时候会一起介绍。
RetryAction 和 RetryDecision
RetryAction是RetryPolicy.shoudlRetry()的返回结果,即重试的具体细节,比如,重试的方式(封装在RetryDecision中),重试需要delay的时间,以及最后的一个reason信息。RetryDecision则封装了重试的决定,即是否重试。包括1)放弃重试(即失败),2)通过FAILVOER的方式重试以及3)普通重试。
关于 RetryPolicy,RetryAction和RetryDecision的关系如下图-1所示。
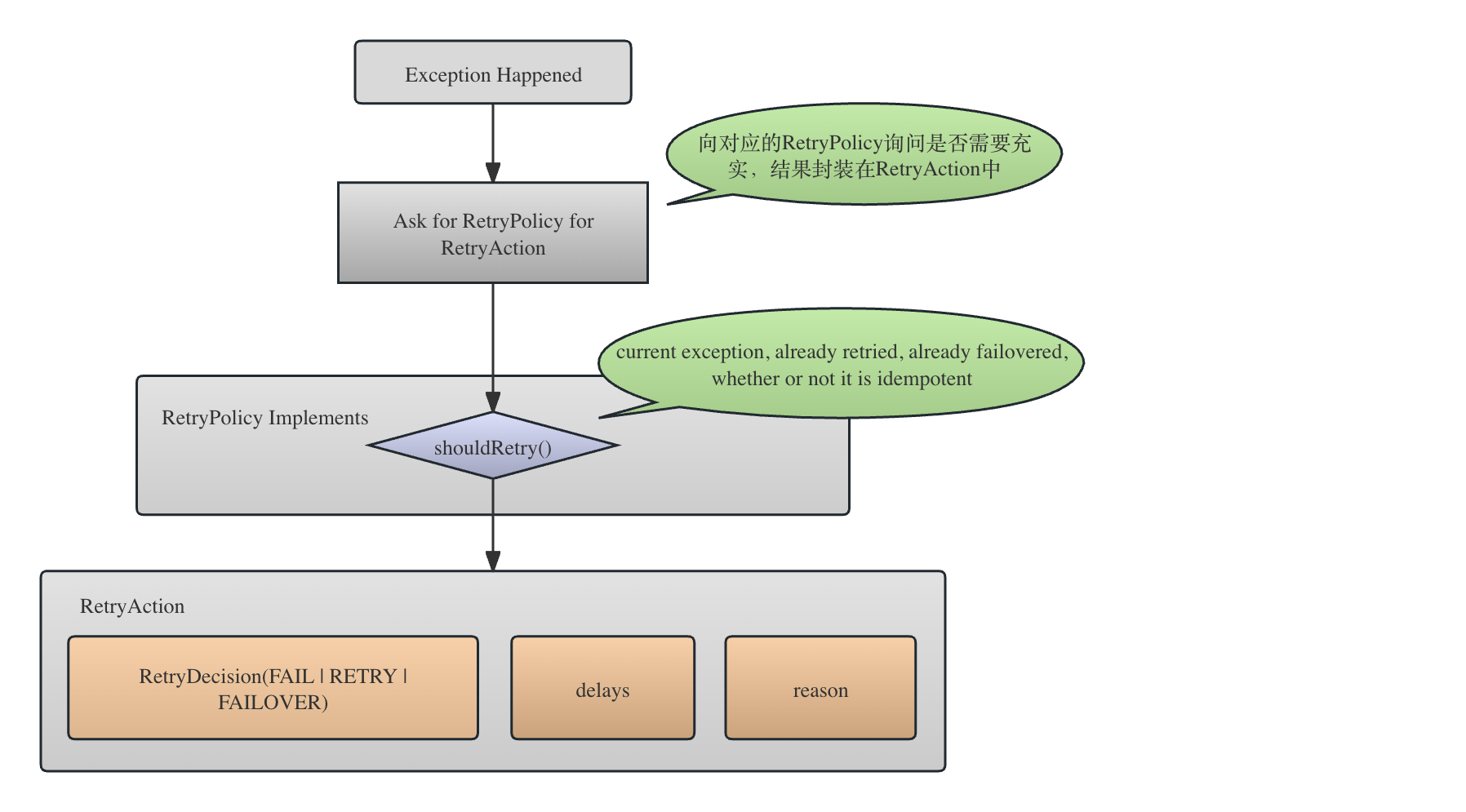
------------------------------------------RetryPolicy------------------------------------------
public interface RetryPolicy {
public static class RetryAction {
// A few common retry policies, with no delays.
public static final RetryAction FAIL =
new RetryAction(RetryDecision.FAIL);
public static final RetryAction RETRY =
new RetryAction(RetryDecision.RETRY);
public static final RetryAction FAILOVER_AND_RETRY =
new RetryAction(RetryDecision.FAILOVER_AND_RETRY);
public final RetryDecision action;
public final long delayMillis;
public final String reason;
public RetryAction(RetryDecision action, long delayTime, String reason) {
this.action = action;
this.delayMillis = delayTime;
this.reason = reason;
}
public enum RetryDecision {
// Ordering: FAIL < RETRY < FAILOVER_AND_RETRY.
FAIL, // 最终失败
RETRY, //重试但是不Failover
FAILOVER_AND_RETRY // 以failover的方式重试
}
}
public RetryAction shouldRetry(Exception e, int retries, int failovers,
boolean isIdempotentOrAtMostOnce) throws Exception;
通过RetryPolicy.shouldRetry()方法可以看到,重试决定所依赖的上下文情况包括:
- 当前发生的异常:重试肯定是发生了异常才会重试,重试的决定会考虑异常的类型等信息做出;
- 已经重试的次数;
- 已经failover,即在主备NameNode节点之间切换的次数;
- 当前需要重试的操作是否是幂等(idempotent)操作。因为如果是幂等操作,显然重试不会带来任何逻辑错误或者数据不一致,如果非幂等,假如我们不知道上一个失败的请求是否已经到达NameNode,或者到达NameNode以后是否全部没做,那么failover retry就不可以再进行,因为有可能会破坏一致性。
最终的重试操作封装在RetryAction中,一个重试操作包括重试的决定(RetryDecision,重试的延迟时间,以及重试的原因)。
最终做出的重试决定放在RetryDecision中,同时,
可以看到,重试决定RetryDecision分成三种:
FAIL最终失败,即不会再进行重试的失败;RETRY重试,即基于当前的连接进行重试;FAILOVER_AND_TRY换到其他NameNode上进行重试。
关于 RetryPolicy,RetryAction和RetryDecision的关系如上图-1所示。
RetryInfo
RetryInfo其实和RetryAction的含义相同,都包含了重试操作的具体信息,比如是否重试,重试间隔等,但是RetryInfo是对RetryAction的封装,这是因为,假如异常是一个MultiException,那么RetryPolicy会解开MultiException中的每一个Exception生成对应的RetryAction。由于是多个RetryAction,每一个action可能含有不同的重试间隔、RetryDecision等,必须综合当前的多个RetryAction决定出一个最终的重试细节,这个最终的决定就封装在RetryInfo中。
什么时候会抛出MultiException:
我们查看代码可以知道,MultiException只发生在RequestHedgingProxyProvider这个ConfiguredFailoverProxyProvider的一个子类上。我们想起了Hedged Read,即read操作同时发送给多个DataNode,最先受到的成功相应将会被采用,其他晚到的请求被取消。同样的,与ConfiguredFailoverProxyProvider不同的是,RequestHedgingProxyProvider会把请求发送给多个NameNode,先到者得,剩下的并行请求会被取消。
下面是RetryInfo的代码片段:
private static class RetryInfo {
private final long retryTime; // sleep的时间,这是根据一个或者多个RetryAction中的最大sleep时间
private final long delay; // 根据当前时间和retryTime,计算得到的下次attemp进行的timestmap
private final RetryAction action; // 一个或者多个RetryAction中选中的最终的action
private final long expectedFailoverCount; // 当前期待的failover的次数,主要用来多线程防止多次无意义的Failover
private final Exception failException; // 异常
RetryInfo(long delay, RetryAction action, long expectedFailoverCount,
Exception failException) {
我们这里只是在概念上理解各个不同的类的作用,从而对整个重试的设计有所了解。
下文会详细介绍整个重试的处理逻辑,这里暂不做描述。
几种常见的RetryPolicy实现和使用场景
FailoverOnNetworkExceptionRetry
这是HDFS Client在最上层的重试实现逻辑,即在与某个NameNode通信失败以后,通过Failover的方式与另外一个NameNode进行尝试连接的通信方式。
我们下面还会讲,在failover到下一个NameNode以前,都会与当前的NameNode进行基于重试的多次通信,如果建立连接的过程中发生比如IOException,会基于RetryUpToMaximumCountWithFixedSleep进行下层连接层的重试。也就是说,有不同的RetryPolicy的实现类在不同层面控制者整个连接过程。
TryOnceThenFail
-
这也是
RetryPolicy的一种实现,但是这种策略的特殊之处就是,它代表的是,不重试。它主要用于在FailoverOnNetworkExceptionRetry中,如果根据当前的上下文,我们无法做出明确的重试决定(比如,重试次数也没有超,抛出的异常类型也不在我们规定的一些case),那么就使用TryOnceThenFail,它返回的RetryAction永远都是FAIL:static class TryOnceThenFail implements RetryPolicy { @Override public RetryAction shouldRetry(Exception e, int retries, int failovers, boolean isIdempotentOrAtMostOnce) throws Exception { return new RetryAction(RetryAction.RetryDecision.FAIL, 0, "try once " + "and fail."); }
RetryForever
-
这是
TryOnceThenFail的另一个极端,就是永远重试,因此,它的shouldRetry()方法永远返回的是RetryAction.RETRYstatic class RetryForever implements RetryPolicy { @Override public RetryAction shouldRetry(Exception e, int retries, int failovers, boolean isIdempotentOrAtMostOnce) throws Exception { return RetryAction.RETRY; }
RetryLimited
从名字可以看到,这是进行有限次重试。根据具体有限次重试的方式(比如,每次重试sleep时间的策略),它有以下几个子类:
-
RetryUpToMaximumCountWithFixedSleep
- 重试次数有限但是每次重试都固定sleep时间的重试。
- 这个重试主要用于和某一个NameNode进行连接的过程中,如果发生了
IOException所采取的针对这个NameNode进行重连的重试策略。只有这个重试失败了,才会尝试进行failover重试。 - 查看
Client.setupConnection()方法可以看到RetryUpToMaximumCountWithFixedSleep的对应逻辑:
---------------------------------- Client ---------------------------------- private synchronized void setupConnection( UserGroupInformation ticket) throws IOException { .... while (true) { try { ....... NetUtils.connect(this.socket, server, bindAddr, connectionTimeout); this.socket.setSoTimeout(soTimeout); return; } catch (ConnectTimeoutException toe) { ...... } catch (IOException ie) { // 在这里调用RetryUpToMaximumCountWithFixedSleep重试逻辑进行重试 handleConnectionFailure(ioFailures++, ie);决定 } private void handleConnectionFailure(int curRetries, IOException ioe ) throws IOException { closeConnection(); final RetryAction action; try { //这里的connectionRetryPolicy的实现是RetryUpToMaximumCountWithFixedSleep action = connectionRetryPolicy.shouldRetry(ioe, curRetries, 0, true); } catch(Exception e) {在和对应的NameNode 创建连接的时候,这个链接信息会保存在 `ConnectionId`类中,对应的重试逻辑就是在构造`ConnectionId`的时候创建的:---------------------------------- Client ---------------------------------- static ConnectionId getConnectionId(InetSocketAddress addr, Class<?> protocol, UserGroupInformation ticket, int rpcTimeout, RetryPolicy connectionRetryPolicy, Configuration conf) throws IOException { if (connectionRetryPolicy == null) { final int max = conf.getInt( // 最大的重试次数 CommonConfigurationKeysPublic.IPC_CLIENT_CONNECT_MAX_RETRIES_KEY, CommonConfigurationKeysPublic.IPC_CLIENT_CONNECT_MAX_RETRIES_DEFAULT); final int retryInterval = conf.getInt( // 固定的重试时间间隔 CommonConfigurationKeysPublic.IPC_CLIENT_CONNECT_RETRY_INTERVAL_KEY, CommonConfigurationKeysPublic .IPC_CLIENT_CONNECT_RETRY_INTERVAL_DEFAULT); connectionRetryPolicy = RetryPolicies.retryUpToMaximumCountWithFixedSleep( max, retryInterval, TimeUnit.MILLISECONDS); }可以看到,
RetryUpToMaximumCountWithFixedSleep通过ipc.client.connect.max.retries配置最大重试次数,默认是10,通过ipc.client.connect.retry.interval配置每次重试的时间间隔,默认是1s
从代码可以看到这个重试策略也用于跟S3的连接,但是本文不做详细讲解。 -
RetryUpToMaximumTimeWithFixedSleep
- 这个Policy是
RetryUpToMaximumCountWithFixedSleep的子类,即它也是sleep固定的时间和最大的某个次数,只不过这个Policy的最大重试次数是根据传入的最大总共等待时间除以相邻重试的时间间隔所间接计算得来的。 - 这个Policy主要用来
- Yarn中NodeManager向ResourceManager发送心跳时候的重试逻辑(查看
NodeStatusUpdateImpl), - ResourceManager同NodeManager通信以在上面启动某个Application的ApplicationMaster(
AMLauncher)以及 - 其他跟ResourceManager通信的时候,比如,Yarn客户端(
YarnClient)同ResourceManager通信,ApplicationMaster(AMRMClientServiceImpl)同ResourceManager通信,NodeManager中的AggregatedLogDeletionService同ResourceManager通信。 - 我们看它的构造方法就能够看到它的重试构造逻辑:
static class RetryUpToMaximumTimeWithFixedSleep extends RetryUpToMaximumCountWithFixedSleep { private long maxTime = 0; private TimeUnit timeUnit; public RetryUpToMaximumTimeWithFixedSleep(long maxTime, long sleepTime, TimeUnit timeUnit) { super((int) (maxTime / sleepTime), sleepTime, timeUnit); this.maxTime = maxTime; this.timeUnit = timeUnit; } - 这个Policy是
-
ExponentialBackoffRetry
- 重试次数有限,并且重试时间指数递增。
- 这个重试策略用于HDFS Client在非HA模式下的重试,比如,我们在没有配置相应的
FailoverProxyProvider的情况下,就会走非HA的重试策略,并使用该重试策略,请参考NameNodeProxies.createNNProxyWithNamenodeProtocol()。 - 下面的代码显示了在重试次数没有到达最大允许重试次数的情况下,下一次的Sleep时间的计算。可以看到,基于重试的基本时间单位(默认为
200ms),当前的重试次数retries,最大允许的基础时间cap,然后加上一定的随机性,获取下一次的重试时间。每次调用calculateExponentialTime(),都会通过1L << retries进行指数递增。
---------------------------------- RetryPolicies ---------------------------------- /* * @param time 重试的基本事件单元 * @param retries 当前已经进行的重试次数 * @param cap 基础时间的最大允许值 * @return 下次重试前需要sleep的时间 */ private static long calculateExponentialTime(long time, int retries, long cap) { long baseTime = Math.min(time * (1L << retries), cap); return (long) (baseTime * (ThreadLocalRandom.current().nextDouble() + 0.5)); } -
RetryUpToMaximumCountWithProportionalSleep
- 重试次数有限,并且重试时间线性递增。
- 这个重试策略也主要用于S3的写数据过程,本文不做具体讲解。
- 从计算重试sleep时间可以看到其相邻重试的时间间隔的计算逻辑
@Override protected long calculateSleepTime(int retries) { return sleepTime * (retries + 1); }
-
MultipleLinearRandomRetry
- 这个重试规则来源于用户自定义,用户通过
dfs.client.retry.policy.enabled来enable自定义的Retry策略文本,默认是false,并通过dfs.client.retry.policy.spec来定义策略文本,即n对sleep时间和重试次数的文本T_1, n_1, t_2, n_2, ...,其含义是,前n_1次重试,每次重试间隔时间是t_1,然后接下来的n_2次重试的重试时间间隔是t_2,以此类推。但是我们从MultipleLinearRandomRetry的代码可以看到,每次的时间间隔并不是标准的t_i,而是位于[t_i * 0.5, t_i * 1.5]之间的一个随机值。当dfs.client.retry.policy.enabled=true,这个文本的默认值是POLICY_SPEC_DEFAULT = "10000,6,60000,10",即前6次,每次大概sleep的时间在10s前后,后面10次,sleep的时间大概是60s左右。 - 这个重试策略主要用来在非HA模式下、或者HA模式下针对每一台NameNode的重试策略。可以查看
NameNodeProxiesClient.createNonHAProxyWithClientProtocol()查看使用该RetryPolicy的逻辑。
- 这个重试规则来源于用户自定义,用户通过
HDFS客户端使用动态代理
在解释完了RetryPolicy,我们就知道了Hadoop客户端关于重试规则的设计逻辑和要素比如最大重试次数、重试时间间隔等。基于配置好的重试逻辑,Hadoop使用了两层的动态代理,在两个层面分别对重试进行控制。
第一层是Failover层面的代理,如果连接失败抛出到这一层,客户端就会进行failover操作到另外一台NameNode再试。很有可能,在两台NameNode之间来回反复重试,直到最终按照RetryPolicy失败。
第二层是针对某一天NameNode的RPC连接的代理,即针对某一台NameNode的连接失败,在触发上层Failvoer重试以前,会再试几次,如果失败才会抛出到上层的Failover层的重试逻辑。
图-2的堆栈截图很清晰地展示了两层代理的调用层次结构。
图-3描绘了两层动态代理的调用过程。
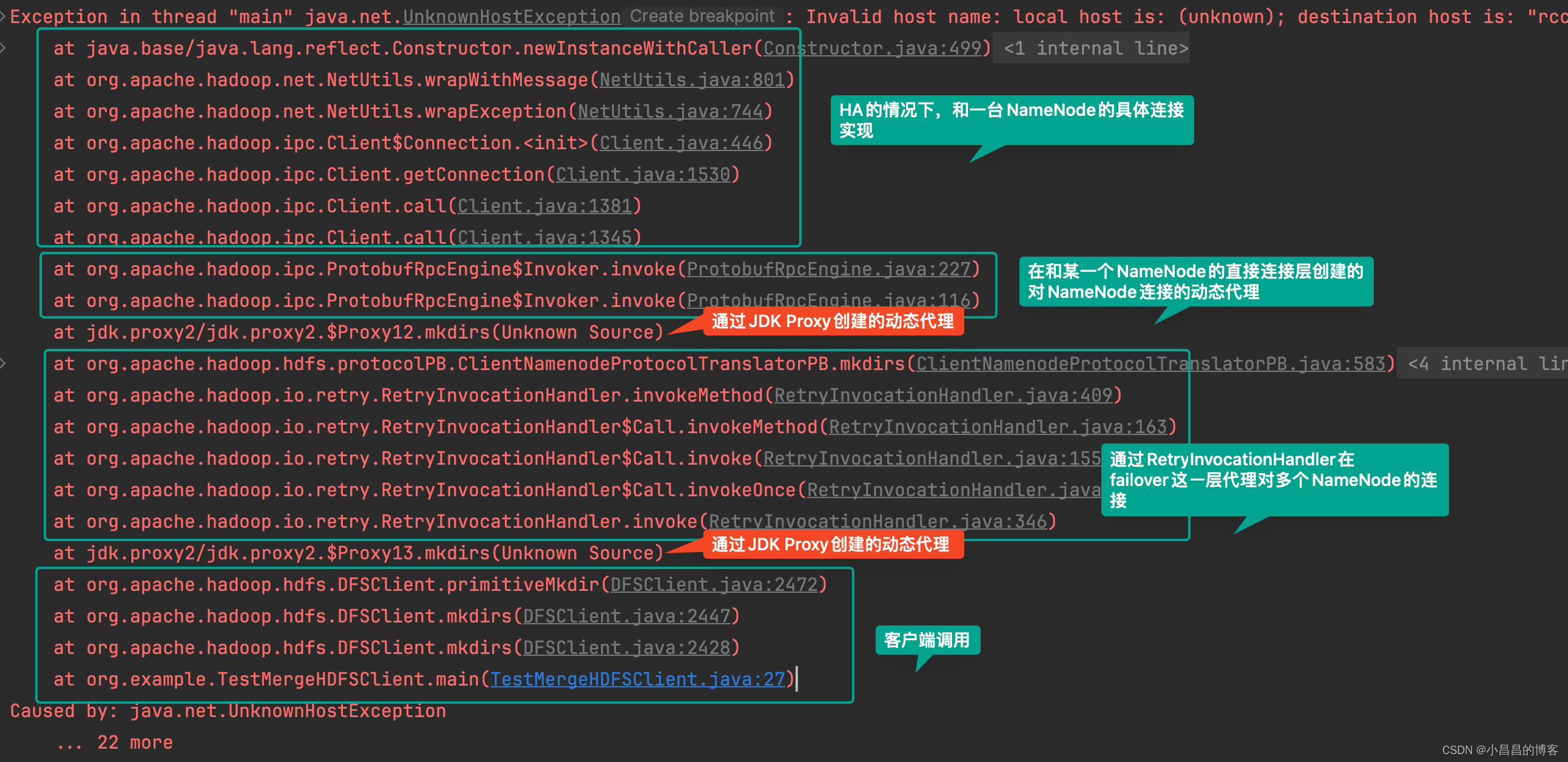
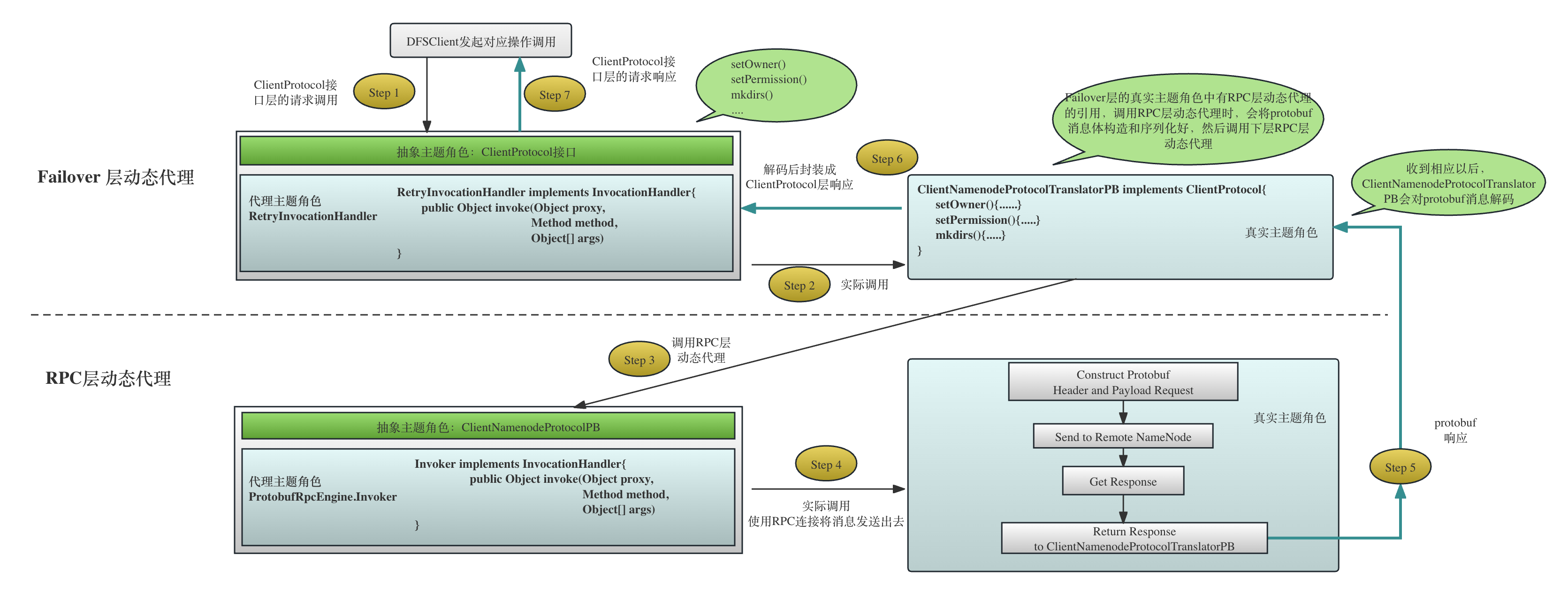
参考图-3,我们将分别详细讲解两层动态代理的调用流程。
Failover层面的代理
在这一层,动态代理的接口(抽象主题角色)是接口ClientProtocol, 而对应的代理主题角色是RetryInvocationHandler,真实主题角色(从上图的堆栈中也能看出来)是ClientNamenodeProtocolTranslatorPB,根据动态代理的要求,真实主题角色必须是抽象主题角色的实现类。
我们可以看下代码,的确如此。
ConfiguredFailoverProxyProvider的构造和基本功能
在HDFS端,动态代理的接口(抽象主题角色)叫做ClientProtocol,就是定义了客户端可以进行的所有HDFS操作,如下所示:
----------------------------------------ClientProtocol------------------------------------
public interface ClientProtocol {
void setOwner(String src, String username, String groupname)
throws IOException;
void setPermission(String src, FsPermission permission)
throws IOException;
boolean rename(String src, String dst)
throws IOException;
boolean delete(String src, boolean recursive)
throws IOException;
boolean mkdirs(String src, FsPermission masked, boolean createParent)
throws IOException;
.......
}
可以看到,ClientProtocol的接口定义和参数都是常规的Java类型,与具体的通信编码都还无关。 ClientProtocol接口是客户端的垒比如DFSClient直接调用的类。
代理ClientProtocol接口的代理类Proxy的创建是在NameNodeProxiesClient中进行的:
-------------------------------------NameNodeProxiesClient-------------------------------------
public static ProxyAndInfo<ClientProtocol> createProxyWithClientProtocol(
Configuration conf, URI nameNodeUri, AtomicBoolean fallbackToSimpleAuth)
throws IOException {
AbstractNNFailoverProxyProvider<ClientProtocol> failoverProxyProvider =
createFailoverProxyProvider(conf, nameNodeUri, ClientProtocol.class,
true, fallbackToSimpleAuth); // 判断是否配置了FailoverProxyProvider
if (failoverProxyProvider == null) {
InetSocketAddress nnAddr = DFSUtilClient.getNNAddress(nameNodeUri);
Text dtService = SecurityUtil.buildTokenService(nnAddr);
ClientProtocol proxy = createNonHAProxyWithClientProtocol(nnAddr, conf,
UserGroupInformation.getCurrentUser(), true, fallbackToSimpleAuth);
return new ProxyAndInfo<>(proxy, dtService, nnAddr);
} else {
return createHAProxy(conf, nameNodeUri, ClientProtocol.class,
failoverProxyProvider);
}
}
从上面的代码可以看到,如果客户端配置了对应的failoverProxyProvider,那么就会通过createHAProxy()创建一个具有Failover功能的Proxy,否则,通过createNonHAProxyWithClientProtocol()创建不具备failover功能的、只能指向一台NameNode的客户端的Proxy。
如果要实现基于HA的Proxy,客户端必须提供FailoverProxyProvider的对应实现类。先来看接口FailoverProxyProvider:
-------------------------------------FailoverProxyProvider----------------------------------
public interface FailoverProxyProvider<T> extends Closeable {
public static final class ProxyInfo<T> {
public final T proxy;
public final String proxyInfo;
....
}
....
public ProxyInfo<T> getProxy(); //
public void performFailover(T currentProxy);
public Class<T> getInterface();
}
getProxy()方法返回当前针对某一个NameNode的连接Proxy。performFailover()就是将当前针对某一个NameNode的Proxy切换到另外一个NameNode,这时候getProxy()就会返回另外一个NameNode RPC连接的Proxy。
对应的Proxy封装在ProxyInfo类中,这个类中存放了具体的代理类Proxy和代理的相关信息。
FailoverProxyProvider接口没有默认实现类,我们在HDFS Client端的配置文件里必须通过dfs.client.failover.proxy.provider.{{name service}}来配置FailoverProxyProvider的具体实现。但是Hadoop的代码中为我们提供了内置的两种FailoverProxyProvider实现,ConfiguredFailoverProxyProvider和RequestHedgingProxyProvider。上文简单说了RequestHedgingProxyProvider,我们这里只关注ConfiguredFailoverProxyProvider。
我们通过ConfiguredFailoverProxyProvider的构造方法可以看到它的基本处理逻辑,即通过HAProxyFactory来创建针每一台NameNode的、以ClientProtocol作为抽象主题角色的Proxy,即底层的针对NameNode的Proxy。基于底层代理,上层在封装为可以进行Failover的Proxy,这样封装完成,最终就是包装给客户端使用的、自动实现HA重试的Proxy。
下面的代码显示了ConfiguredFailoverProxyProvider类的构造过程:
--------------------------------ConfiguredFailoverProxyProvider---------------------------------
public ConfiguredFailoverProxyProvider(Configuration conf,
URI uri, //在HA模式下,这里的uri其实是一个逻辑uri,而不是某一个具体NameNode的URI,比如hdfs://nameservice-01
Class<T> xface, // 定义抽象主题角色的接口,这里是ClientProtocol
HAProxyFactory<T> factory) // 创建连接到每一个NameNode的Proxy
{
this.xface = xface; //需要代理的接口,即抽象主题角色类,在HDFS客户端,它是ClientProtocol
this.conf = new Configuration(conf);
int maxRetries = this.conf.getInt( //
HdfsClientConfigKeys.Failover.CONNECTION_RETRIES_KEY,
HdfsClientConfigKeys.Failover.CONNECTION_RETRIES_DEFAULT);
......
int maxRetriesOnSocketTimeouts = this.conf.getInt(
HdfsClientConfigKeys.Failover.CONNECTION_RETRIES_ON_SOCKET_TIMEOUTS_KEY,
HdfsClientConfigKeys.Failover.CONNECTION_RETRIES_ON_SOCKET_TIMEOUTS_DEFAULT);
......
Map<String, Map<String, InetSocketAddress>> map =
DFSUtilClient.getHaNnRpcAddresses(conf);
Map<String, InetSocketAddress> addressesInNN = map.get(uri.getHost()); // 创建每一个NameNode对应的InetSocketAddress对象。下文将会详细讲解InetSocketAddress的含义
.......
Collection<InetSocketAddress> addressesOfNns = addressesInNN.values();
for (InetSocketAddress address : addressesOfNns) { // 为每一个NameNode创建对应的AddressRpcProxyPair
proxies.add(new AddressRpcProxyPair<T>(address)); // 为每一个NameNode
}
ConfiguredFailoverProxyProvider实现了FailoverProxyProvider的getProxy()方法,用来获取当前针对某一个NameNode的proxy:
--------------------------------ConfiguredFailoverProxyProvider-------------------------------
@Override
public synchronized ProxyInfo<T> getProxy() {
AddressRpcProxyPair<T> current = proxies.get(currentProxyIndex);
if (current.namenode == null) {
try {
current.namenode = factory.createProxy(conf,
current.address, xface, ugi, false, getFallbackToSimpleAuth());
}
.....
return new ProxyInfo<T>(current.namenode, current.address.toString());
}
从上面的代码可以看到,通过当前的currentProxyIndex拿到当前针对某一个namenode的Proxy。如果Proxy还没创建,就通过HAProxyFactory.createProxy()来创建。
这个currentProxyIndex是指当前所使用的NameNode的这个namenode数组中的索引。显然,客户端failover的过程就是修改currentProxyIndex。的确是这样的,我们看ConfiguredFailoverProxyProvider.failover()的代码,很简单:
--------------------------------ConfiguredFailoverProxyProvider-------------------------------
@Override
public void performFailover(T currentProxy) {
incrementProxyIndex(); // failover就是将当前proxy的指向在多个NameNode之间切换
}
synchronized void incrementProxyIndex() {
currentProxyIndex = (currentProxyIndex + 1) % proxies.size(); //加1取模
}
基于ConfiguredFailoverProxyProvider构建Failover层面的代理
Failover层面的代理是客户端代理的上层代理。
上文讲过,JDK Proxy创建的过程有两个关键要素,一个是被代理的接口(即抽象主题角色),和代理类(需要实现InvocationHandler接口)。下面的代码看到了这个层面的代理的创建,iface即抽象主题角色是接口ClientProtocol,对应的InvocationHandler接口实现是RetryInvocationHandler。
-----------------------------------------RetryProxy---------------------------------------
public static <T> Object create(Class<T> iface,
FailoverProxyProvider<T> proxyProvider, RetryPolicy retryPolicy) {
return Proxy.newProxyInstance(
proxyProvider.getInterface().getClassLoader(),
new Class<?>[] { iface }, // 这里的iface接口是ClientProtocol类
new RetryInvocationHandler<T>(proxyProvider, retryPolicy) // 这是InvocationHandler接口实现
);
}
所以,RetryInvocationHandler代理了Failover层面的方法调用,这些方法定义在接口ClientProtocol中,从而用来对这些被代理的方法进行一些统一的处理。其中最重要的处理,是重试。
我们先不看RetryInvocationHandler的具体代码,从上面ConfiguredFailoverProxyProvider的构造函数,看到有两个参数,1) 一个是ConfiguredFailoverProxyProvider proxyProvider,即负责提供对多个NameNode的具体连接的切换,2) 以及retryPolicy,即切换时候的重试逻辑,比如,切换多少次,每次切换需要等待多久等。
代理的过程是在InvocationHandler.invoke()方法中实现的:
----------------------------------RetryInvocationHandler-----------------------------------
// 将FailoverProxyProvider的调用进行了封装,添加了异步和同步的处理逻辑
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
final boolean isRpc = isRpcInvocation(proxyDescriptor.getProxy());
final int callId = isRpc? Client.nextCallId(): RpcConstants.INVALID_CALL_ID;
final Call call = newCall(method, args, isRpc, callId);
while (true) {
final CallReturn c = call.invokeOnce();
final CallReturn.State state = c.getState();
if (state == CallReturn.State.ASYNC_INVOKED) {
return null; // return null for async calls
} else if (c.getState() != CallReturn.State.RETRY) { // 只有当state是State.RETRY的时候才会重试
return c.getReturnValue();
}
}
}
从上面代码可以看到,RetryInvocationHandler将调用过程封装到Call call中,然后调用Call.invokeOnce()。最关键的对异常的护理逻辑,和重试逻辑,就发生在invokeOnce()中:
/** Invoke the call once without retrying. */
synchronized CallReturn invokeOnce() {
try {
final long failoverCount = retryInvocationHandle
r.getFailoverCount();
try {
return invoke();
} catch (Exception e) { // 发生异常,处理异常
retryInfo = retryInvocationHandler.handleException(
method, callId, retryPolicy, counters, failoverCount, e);
return processWaitTimeAndRetryInfo();
.....
}
invokeOnce()会根据当前失败的情况,调用handleException()来对异常进行处理(这就是为什么要用代理,因为使用动态代理,对异常的处理逻辑和调用可以解耦合)。
Failover层面对异常的处理逻辑
从上面的代理主题角色的代码,可以看到对异常的统一处理入口:
retryInfo = retryInvocationHandler.handleException(
method, callId, retryPolicy, counters, failoverCount, e);
return processWaitTimeAndRetryInfo();
异常处理统一在代理主题角色类RetryInvocationHandler中进行:
---------------------------------RetryInvocationHandler----------------------------------------
private RetryInfo handleException(final Method method, final int callId,
final RetryPolicy policy, final Counters counters,
final long expectFailoverCount, final Exception e) throws Exception {
final RetryInfo retryInfo = RetryInfo.newRetryInfo(policy, e,
counters, proxyDescriptor.idempotentOrAtMostOnce(method),
expectFailoverCount); // 构造RetryInfo
if (retryInfo.isFail()) {
// fail.
....
throw retryInfo.getFailException(); // 如果是fail,那么直接抛出异常
}
....
return retryInfo;
}
从上面的逻辑可以看到,处理异常的流程就是
- 构造对应的
RetryInfo对象 - 如果
RetryInfo中的RetryAction是Fail,那就很简单,直接抛出异常 - 而如果是
RetryDecision.RETRY或者RetryDecision.FAILOVER_RETRY,就返回这个RetryInfo对象,由上层的调用者来执行RetryInfo中的策略,比如,是否要failover,要sleep多久等等。
我们来看看RetryInfo的构造过程。这个复杂性主要在发生在基于Hedged Request的情况下抛出了MultiException的情况下,怎样基于这多个exception决策出最终的RetryAction。
其基本逻辑是:
dfs.client.failover.proxy.provider.[nameservice ID]配置为ConfiguredFailoverProxyProvider的情况下,会抛出对应的Exception,调用RetryPolicy.shouldRetry()获取对应的RetryAction,然后封装为RetryInfodfs.client.failover.proxy.provider.[nameservice ID]配置为RequestHedgingProxyProvider的情况下,不同的节点抛出的异常封装成了MultiException, 需要拆开其封装的多个Exception,然后分别决定RetryAction,然后对于这多个RetryAction,构造最终的RetryInfo。原则为:
- 最终决定的sleep时间选择其中最长的sleep时间
- 最终决定的action的优先级是
FAILOVER_AND_RETRY>RETRY>FAIL,比如有一个RetryDecision.FAIL,另一个是RetryDecision.Retry,那么我们最终的决定应该是RetryDecision.RETRY,因为这个RetryDecision.RETRY是有可能让这个操作最终成功的。 - 只要有一个Exception的
RetryAction是RetryDecision.FAIL(最后封装在RetryInfo的RetryAction不一定是RetryDecision.FAIL,这要根据上一步来决定),就将这个Exception封装在RetryInfo。因为导致FAIL的Exception需要打印出来让用户知道,尽管在MultiException中,最终决定的RetryAction可能依然是重试。
static RetryInfo newRetryInfo(RetryPolicy policy, Exception e,
Counters counters, boolean idempotentOrAtMostOnce,
long expectedFailoverCount) throws Exception {
RetryAction max = null;
long maxRetryDelay = 0;
Exception ex = null;
final Iterable<Exception> exceptions = e instanceof MultiException ?
((MultiException) e).getExceptions().values()
: Collections.singletonList(e);
for (Exception exception : exceptions) { //遍历每一个Exception,根据Policy决定出当前的RetryAction
final RetryAction a = policy.shouldRetry(exception,
counters.retries, counters.failovers, idempotentOrAtMostOnce);
if (a.action != RetryAction.RetryDecision.FAIL) {
// must be a retry or failover
if (a.delayMillis > maxRetryDelay) { // 获取一个最大的delay时间,作为最后决定的delay时间
maxRetryDelay = a.delayMillis;
}
}
// 顺序: FAIL < RETRY < FAILOVER_AND_RETRY.
if (max == null || max.action.compareTo(a.action) < 0) {
max = a;
if (a.action == RetryAction.RetryDecision.FAIL) {
ex = exception;// 有一个exception是fail,保存这个FAIL的exception
}
}
}
// 最终的RetryInfo
return new RetryInfo(maxRetryDelay, max, expectedFailoverCount, ex);
}
}
刚才说过,如果RetryDecision.FAIL,handleException()方法就直接把异常抛出去了,而当RetryDecision是RETRY或者FAILOVER_RETRY,则需要进行下一次重试,从invokeOnce()方法可以看到,对重试的处理在方法processWaitTimeAndRetryInfo()中:
---------------------------------RetryInvocationHandler---------------------------------
synchronized CallReturn invokeOnce() {
.....
try {
return invoke();
} catch (Exception e) {
......
retryInfo = retryInvocationHandler.handleException( // 如果是FAIL,这里会抛出异常
method, callId, retryPolicy, counters, failoverCount, e);
return processWaitTimeAndRetryInfo(); // 这里会处理RETRY和FAILOVER_RETYR两种Action
CallReturn processWaitTimeAndRetryInfo() throws InterruptedIOException {
if (waitTime != null && waitTime > 0) {
.........
Thread.sleep(retryInfo.delay); // 执行RetryInfo中的delay
.........
}
processRetryInfo(); //处理Retry,其实就是检查是否failover,如果failover,就执行一个failover
return CallReturn.RETRY;
}
synchronized void processRetryInfo() {
counters.retries++;
if (retryInfo.isFailover()) {
retryInvocationHandler.proxyDescriptor.failover(
retryInfo.expectedFailoverCount, method, callId); // 执行failover
counters.failovers++;
}
retryInfo = null;
}
所以,从上面的代码可以看到对RETRY和FAILOVER_RETRY的处理逻辑:
- 先按照
RetryInfo的延迟时间进行sleep - 如果是failover,那么就执行客户端的failover,这样,下层的连接就选择到了另外一个NameNode
- 然后真对当前连接的NameNode,进行统一的重试
所以,RETRY和FAILOVER_RETRY在执行时候的区别仅仅是在重试之前是否进行failover。我以前一直以为它们是包含关系,即只要是可以retry的异常,都会先进行RETRY而不进行FAILOVER_RETRY,当针对单台NameNode的RETRY到达了一定的次数,才会执行一次FAILOVER_RETRY,接续失败的情况下,就在新的NameNode上执行RETRY,次数达到了再failover·。。但是其实RETRY和FAILOVER_RETRY不是包含关系,从下文的FailoverOnNetworkExceptionRetry.shouldRetry()方法可以看到,有些Exception,就是直接FAILOVER_RETRY,有些Exception就直接RETRY。
FailoverOnNetworkExceptionRetry的处理细节
前面讲过,客户端连接 NameNode在Failover层面的重试逻辑默认使用的RetryPolicy是FailoverOnNetworkExceptionRetry。我们看一下这个RetryPolicy的关键方法shouldRetry()的处理细节:
下面的代码显示了具体的
-----------------------------------FailoverOnNetworkExceptionRetry--------------------------------------
@Override
public RetryAction shouldRetry(Exception e, int retries,
int failovers, boolean isIdempotentOrAtMostOnce) throws Exception {
if (failovers >= maxFailovers) { // 超过了Policy的最大failover,直接失败
return new RetryAction(RetryAction.RetryDecision.FAIL, 0,
"failovers (" + failovers + ") exceeded maximum allowed ("
+ maxFailovers + ")");
}
if (retries - failovers > maxRetries) {//除去failover的重试次数超过了最大允许的非failover的重试次数
return new RetryAction(RetryAction.RetryDecision.FAIL, 0, "retries ("
+ retries + ") exceeded maximum allowed (" + maxRetries + ")");
}
if (e instanceof ConnectException ||
e instanceof EOFException ||
e instanceof NoRouteToHostException ||
e instanceof UnknownHostException ||
e instanceof StandbyException ||
e instanceof ConnectTimeoutException ||
isWrappedStandbyException(e)) { //如果是以上异常(都是跟连接相关),那么会尝试进行failover retry
return new RetryAction(RetryAction.RetryDecision.FAILOVER_AND_RETRY,
getFailoverOrRetrySleepTime(failovers));
} else if (e instanceof RetriableException
|| getWrappedRetriableException(e) != null) {// 如果是以上异常,则会尝试进行retry
// RetriableException or RetriableException wrapped
return new RetryAction(RetryAction.RetryDecision.RETRY,
getFailoverOrRetrySleepTime(retries));
} else if (e instanceof InvalidToken) { //token异常,没必要重试
return new RetryAction(RetryAction.RetryDecision.FAIL, 0,
"Invalid or Cancelled Token");
} else if (e instanceof SocketException //socket异常,或者是IOException(但是并不是
|| (e instanceof IOException && !(e instanceof RemoteException))) {
if (isIdempotentOrAtMostOnce) { // 是幂等的异常
return RetryAction.FAILOVER_AND_RETRY; RemoteException),那么进行failover
} else { //不是幂等的
return new RetryAction(RetryAction.RetryDecision.FAIL, 0,
"the invoked method is not idempotent, and unable to determine "
+ "whether it was invoked"); // 除此以外的,一律直接失败
}
} else { //除此以外,一律交给fallbackPolicy进行处理
return fallbackPolicy.shouldRetry(e, retries, failovers,
isIdempotentOrAtMostOnce);
}
}
}
从上面的FailoverOnNetworkExceptionRetry.shouldRetry()方法可以看到,决定RetryAction的过程其实是对不同的异常的枚举过程。
- 针对一些连接异常,往往通过failover的方式进行重试,
- 如果异常本身就是
RetriableException,那么就是不failover的重试。 - 是否能够重试也考虑到操作的幂等性,如果是非幂等操作,为了避免不一致,不可以再重试。而如果是幂等操作,那么诸如
SocketException,或者非RemoteException的IOException,可以进行Failover然后重试。
HAProxyFactory负责创建对具体NameNode的Proxy
工厂接口HAProxyFactory的具体实现类是NameNodeHAProxyFactory。HAProxyFactory的目的是将代理的创建过程从ConfiguredFailoverController中解耦合出来,即ConfiguredFailoverController委托HAProxyFactory来创建针对每一台NameNode的连接,而ConfiguredFailoverController则只负责通过诸如performFailover()方法和getProxy()方法对外提供不断切换的指向某个NameNode的Proxy。
我们从factory.createProxy()方法的代码可以看到,NameNodeHAProxyFactory就是创建连接到某一个NameNode的non-ha的Proxy(虽然名字中有HA,但是它的一个Proxy对象是指向某一个NameNode的,HA是它的管理类ConfiguredFailoverController负责的):
------------------------------------NameNodeHAProxyFactory----------------------------------
public class NameNodeHAProxyFactory<T> implements HAProxyFactory<T> {
@Override
public T createProxy(Configuration conf, InetSocketAddress nnAddr,
Class<T> xface, UserGroupInformation ugi, boolean withRetries,
AtomicBoolean fallbackToSimpleAuth) throws IOException {
return NameNodeProxies.createNonHAProxy(conf, nnAddr, xface,
ugi, withRetries, fallbackToSimpleAuth).getProxy();
}
我们在下一节会专门讲解创建非HA Proxy的基本流程,非HA的Proxy用在两种情况下:
- HDFS客户端本身没有配置针对这个
NameService的FailoverProxyProvider,只有一台NameNode,这时候会通过方法createNonHAProxyWithClientProtocol()创建非HA的ClientProtocol协议的代理。 - HDFS客户端配置了针对这个
NameService的FailoverProxyProvider, 那么下层针对每一个NameNode的proxy,也是通过createNonHAProxyWithClientProtocol()创建非HA的ClientProtocol协议的代理。即,HA模式下,底层针对每一个NameNode的连接为非HA 的。HA的Proxy是在上层封装的。
这样,ConfiguredFailoverController的基本逻辑就清楚了,通过performFailover()来切换当前proxy的指向,在通过getProxy()方法获取当前指向的Proxy,从而实现基于HA的Proxy。
下一节将讲解非HA-Proxy的创建,当非HA-Proxy创建完成,上层的HA Proxy就可以用来创建HA的Proxy了。
RPC层面的代理
RPC层面的代理位于Failover层面的代理下层,即直接跟某个NameNode直接RPC连接的连接代理。我们从图-2: 两层动态代理的堆栈截图中可以清晰看到两层代理的层次逻辑:
这个层面的代理的抽象主题角色是ClientNamenodeProtocolPB,代理主题角色是ProtobufRpcEngine.Invoker类。但是,真实主题角色跟Failover层不同,它并没有某一个独立的真实主题角色类去一一实现每一个抽象主题角色中的接口比如mkdirs()、setPermissions()方法,而是根据上层传入的方法名称比如mkdirs、setPermissions等和请求的消息体,组装成为具体的Protobuf格式的Request Body,然后通过RPC发送给远程的客户端,然后对应的invoke()方法返回对应的Response。
我们查看ClientNamenodeProtocolPB发现它继承了ClientNamenodeProtocol.BlockingInterface, 因此我们需要编译整个Hadoop才能看到ClientNamenodeProtocolPB的接口方法。
这个层面的代理相对简单,上文讲过,代理的创建就是通过NameNodeProxies.createNonHAProxy()完成的:
----------------------------------------NameNodeProxiesClient-----------------------------
public static ClientProtocol createNonHAProxyWithClientProtocol(
InetSocketAddress address, Configuration conf, UserGroupInformation ugi,
boolean withRetries, AtomicBoolean fallbackToSimpleAuth)
throws IOException {
....
final RetryPolicy defaultPolicy = // 创建默认的RetryPolicy
RetryUtils.getDefaultRetryPolicy(
conf,
HdfsClientConfigKeys.Retry.POLICY_ENABLED_KEY,
HdfsClientConfigKeys.Retry.POLICY_ENABLED_DEFAULT,
HdfsClientConfigKeys.Retry.POLICY_SPEC_KEY,
HdfsClientConfigKeys.Retry.POLICY_SPEC_DEFAULT,
SafeModeException.class.getName());
// 创建RPC层面的、针对和某台机器的RPC连接的代理,这里的抽象主题角色是底层的ClientNamenodeProtocolPB
final long version = RPC.getProtocolVersion(ClientNamenodeProtocolPB.class);
ClientNamenodeProtocolPB proxy = RPC.getProtocolProxy(
ClientNamenodeProtocolPB.class, version, address, ugi, conf,
NetUtils.getDefaultSocketFactory(conf),
org.apache.hadoop.ipc.Client.getTimeout(conf), defaultPolicy,
fallbackToSimpleAuth).getProxy();
// 是否需要针对当前NameNode的重试,如果需要,就在外面封装一个针对单台NameNode的重试
if (withRetries) { // 上层要求创建针对单台机器的重试规则,则在这个代理再封装一层
Map<String, RetryPolicy> methodNameToPolicyMap = new HashMap<>();
ClientProtocol translatorProxy =
new ClientNamenodeProtocolTranslatorPB(proxy);
return (ClientProtocol) RetryProxy.create(
ClientProtocol.class,
new DefaultFailoverProxyProvider<>(ClientProtocol.class,
translatorProxy),
methodNameToPolicyMap,
defaultPolicy);
} else { //不需要基于单台NameNode的重试,即如果当前NameNode失败,就直接通过Failover去尝试另一台NameNode
// 这里将创建好的基于Protobuf接口ClientNamenodeProtocolPB的代理,封装为上层的基于ClientProtocol的代理ClientNamenodeProtocolTranslatorPB
return new ClientNamenodeProtocolTranslatorPB(proxy);。
}
从上面的代码可以看到,其基本处理逻辑是:
- 通过
RetryUtils.getDefaultRetryPolicy()获取默认的RetryPolicy,默认的RetryPolicy的创建方式是:- 如果用户设置
dfs.client.retry.policy.enabled=true并且配置了dfs.client.retry.policy.spec配置了具体的重试规则文本,那么就按照用户配置的重试规则文本来设置针对单台NameNode的连接重试,这个用户自定义的重试规则被解析并且封装在MultipleLinearRandomRetry中,上文已经讲过MultipleLinearRandomRetry这个RetryPolicy的基本逻辑。 - 否则,就使用
TRY_ONCE_THEN_FAIL这个RetryPolicy,即针对单台NameNode的失败,在RPC层不进行重试。
- 如果用户设置
- 根据withRetries,在当前的
ClientNamenodeProtocolPBproxy上面继续进行代理封装:-
如果
withRetries=true,那么通过RetryProxy.create()在ClientNamenodeProtocolPB的上层再封装一次代理。我们从RetryProxy.create()的代码可以看到,它可以根据传入的methodNameToPolicyMap来针对每一个方法定义不同的重试策略。withRetries=true发生在上层不会再封装FailoverProxyProvider的情况,即本身系统就只有一个NameNode,或者根本没有针对当前的nameservice配置对应的FailoverProxyProvider实现类,这时候这个RPC层的Proxy需要直接封装成用户端接口ClientPrototol返回给客户端(上文讲过,客户端直接使用ClientPrototol接口作为代理主题角色),因为不会再经过Failover层的封装了。 -
如果
withRetries=false,那么直接进行一层简单封装,封装为ClientNamenodeProtocolTranslatorPB,这一层封装没有添加额外的重试,然后返回给failover层,进一步封装为以ClientProtocol作为代理主题角色的代理层,供客户端使用。 -
上文说过,通过
createNonHAProxyWithClientProtocol()创建非HA的Proxy有两种情况-
在第一种情况下,即本身就没有HA或者没有配置
FailoverProxyProvider,这时候withRetries=true,这里的考虑是,上层本来就没有FailoverProxyProvider,下层针对单个的NameNode就得有Retry。但是实际上看上面的代码,在这种系统只有单节点的情况,默认也没有进行重试,因为默认dfs.client.retry.policy.enabled=false,并且看上面的代码,针对每一个method的重试策略methodNameToPolicyMap也是刚创建的。因此这种系统的单节点情况,就没有重试策略。如下面的代码所示,在failoverProxyProvider没有创建的时候,withRetries设置成了True---------------------------------------NameNodeProxies------------------------------------- public static <T> ProxyAndInfo<T> createProxy(Configuration conf, URI nameNodeUri, Class<T> xface, AtomicBoolean fallbackToSimpleAuth) throws IOException { AbstractNNFailoverProxyProvider<T> failoverProxyProvider = NameNodeProxiesClient.createFailoverProxyProvider(conf, nameNodeUri, xface, true, fallbackToSimpleAuth, new NameNodeHAProxyFactory<T>()); // 如果没有HA,则直接创建针对单台节点的non-ha proxy, 否则,需要委托FailoverProxyProvider来创建基于HA的Proxy,上文已经讲过FailoverProxyProvider的创建过程 if (failoverProxyProvider == null) { return createNonHAProxy(conf, DFSUtilClient.getNNAddress(nameNodeUri), xface, UserGroupInformation.getCurrentUser(), true, // withRetries=true fallbackToSimpleAuth); } -
在第二种情况下,即HA的模式下针对每一个NameNode创建的non-ha的proxy,我们从上层调用者的代码可以看到,
withRetries=false,即上层认为重试可以交给Failover来进行,单台节点默认TRY_ONCE_THEN_FAIL,即单台节点连接失败不重试,直接抛向上层,让FailoverProxy来进行Failover的重试。如下面的代码所示,ConfiguredFailoverController.getProxy()方法创建针对单台NameNode的proxy的时候,withRetries=false
------------------------------------ConfiguredFailoverController--------------------- public synchronized ProxyInfo<T> getProxy() { AddressRpcProxyPair<T> current = proxies.get(currentProxyIndex); if (current.namenode == null) { try { current.namenode = factory.createProxy(conf, current.address, xface, ugi, false, //withRetries=false getFallbackToSimpleAuth()); } } -
-
为了创建针对单台节点的、基于RPC的连接代理,是通过RPC.getProtocolProxy()方法创建的。这里的Proxy是RPC层面的Proxy,对应的代理的概念中的抽象主题角色是对应的Protobuf层面的接口ClientNamenodeProtocolPB,而不是上层的ClientPrototol接口。
public static <T> ProtocolProxy<T> getProtocolProxy(Class<T> protocol, //客户端通过proto文件编译成的协议接口,这里是ClientNamenodeProtocolPB
long clientVersion,
InetSocketAddress addr, //解析好的针对单台机器的host
UserGroupInformation ticket,
Configuration conf,
SocketFactory factory,
int rpcTimeout,
RetryPolicy connectionRetryPolicy, // 重试策略
AtomicBoolean fallbackToSimpleAuth)
throws IOException {
return getProtocolEngine(protocol, conf)
.getProxy(protocol, clientVersion,
addr, ticket, conf, factory, rpcTimeout, connectionRetryPolicy,
fallbackToSimpleAuth);
}
Class<T> protocol是Hadoop中预先定义的、与编译.proto之后形成的接口文件相对应的接口。通过编译ClientNamenodeProtocol.proto文件,就会生成对应的ClientNamenodeProtocol.java类。ClientNamenodeProtocolPB接口继承了ClientNamenodeProtocol.BlockingInterface,就是继承了该接口的所有方法。很显然,ClientNamenodeProtocol.BlockingInterface接口中的方法都在ClientNamenodeProtocol.proto中描述了。
----------------------------------ClientNamenodeProtocolPB------------------------------------
public interface ClientNamenodeProtocolPB extends
ClientNamenodeProtocol.BlockingInterface { // ClientNamenodeProtocol.BlockingInterface是对protobuf文件编译生成的
}
对应的protobuf描述文件如下:
-------------------------------ClientNamenodeProtocol.proto----------------------------------
message MkdirsRequestProto {
required string src = 1;
required FsPermissionProto masked = 2;
required bool createParent = 3;
}
message MkdirsResponseProto {
required bool result = 1;
}
rpc mkdirs(MkdirsRequestProto) returns(MkdirsResponseProto);
getProtocolEngine(protocol, conf)返回了针对这个ClientNamenodeProtocolPB接口的处理引擎,比如旧版Hadoop的WritableRpcEngine,以及现在默认的ProtobufRpcEngine。因此,RPC.getProtocolProxy()其实是调用ProtobufRpcEngine.getProxy()来创建以ClientNamenodeProtocolPB作为抽象主题角色的接口定义。我们看一下ProtobufRpcEngine.getProxy()方法:
--------------------------------------ProtobufRpcEngine------------------------------------
public <T> ProtocolProxy<T> getProxy(Class<T> protocol, long clientVersion,
InetSocketAddress addr, UserGroupInformation ticket, Configuration conf,
SocketFactory factory, int rpcTimeout, RetryPolicy connectionRetryPolicy,
AtomicBoolean fallbackToSimpleAuth) throws IOException {
// 创建对应的InvocationHandler的实现类ProtobufRpcEngine.Invoker,ProtobufRpcEngine.Invoker是ProtobufRpcEngine的内部类
final Invoker invoker = new Invoker(protocol, addr, ticket, conf, factory,
rpcTimeout, connectionRetryPolicy, fallbackToSimpleAuth);
return new ProtocolProxy<T>(protocol, (T) Proxy.newProxyInstance(
protocol.getClassLoader(), new Class[]{protocol}, invoker), false);
}
从上面的代码可以看到,它主要做了三件事情:
-
先创建对应的
InvocationHandler类的实现ProtobufRpcEngine.Invoker对象。下面的代码显示了ProtobufRpcEngine.Invoker的构造和对应的invoke()方法的调用过程:--------------------------------------ProtobufRpcEngine.Invoker------------------------------------ private Invoker(Class<?> protocol, Client.ConnectionId connId, // Invoker的构造方法 Configuration conf, SocketFactory factory) { this.remoteId = connId; this.client = CLIENTS.getClient(conf, factory, RpcWritable.Buffer.class); this.protocolName = RPC.getProtocolName(protocol); this.clientProtocolVersion = RPC .getProtocolVersion(protocol); }这里最核心的,是通过
CLIENTS.getClient()创建了对应的org.apache.hadoop.ipc.Client对象,即创建了对应的socket连接。这里的SocketFactory factory是通过hadoop.rpc.socket.factory.class.default配置的,默认配置是org.apache.hadoop.net.StandardSocketFactory -
然后通过调用
Proxy.newProxyInstance()创建出对应的代理主题角色。刚刚说过,这里的protocol是ClientNamenodeProtocolPB,这里的Invoker就是刚刚创建好的InvocationHandler的实现类ProtobufRpcEngine.Invoker(T) Proxy.newProxyInstance( protocol.getClassLoader(), new Class[]{protocol}, invoker) -
最后将创建好的代理主题角色封装在对象
ProtocolProxy中public ProtocolProxy(Class<T> protocol, T proxy, boolean supportServerMethodCheck) { this.protocol = protocol; this.proxy = proxy; this.supportServerMethodCheck = supportServerMethodCheck; }
这样,我们完成了针对某一个NameNode的底层代理的创建,这个代理已经构建好了同NameNode的socket连接,同时有了针对RPC协议ClientNamenodeProtocolPB的代理主题角色,这样,当一个请求过来,比如,本文中的mkdirs()请求,根据动态代理的规则,就会调用对应的InvocationHandler.invoke()方法来通过动态代理的方式执行对应的方法:
--------------------------------------ProtobufRpcEngine.Invoker------------------------------------
// ˙方法调用
public Message invoke(Object proxy, final Method method, Object[] args)
throws ServiceException {
.....
RequestHeaderProto rpcRequestHeader = constructRpcRequestHeader(method);
final Message theRequest = (Message) args[1];
final RpcWritable.Buffer val;
try {
val = (RpcWritable.Buffer) client.call(RPC.RpcKind.RPC_PROTOCOL_BUFFER,
new RpcProtobufRequest(rpcRequestHeader, theRequest), remoteId,
fallbackToSimpleAuth);
} catch (Throwable e) {
........
}
.......
return getReturnMessage(method, val);
}
}
这里的invoke()是ClientNamenodeProtocolPB定义的各个接口的统一放到这里去动态执行,这样,各个接口方法所需要的一些公共处理逻辑,就不需要在每个方法中去重复写,而是放在这里,比如,对异常的统一的、相同的处理逻辑,对请求和响应消息的统一的、相同的封装逻辑就放在这里就可以了,而不是放在每一个方法中,从而将异常处理和方法调用解耦合。
当RPC.getProtocolProxy()调用完成,就创建完成了基于ClientNamenodeProtocolPB这个接口作为抽象主题角色的代理,但是我们上文说过,上层客户端是基于ClientProtocol接口作为抽象主题角色的Proxy,那么,两层接口怎么连接在一起呢?
这是通过将下层创建的基于ClientNamenodeProtocolPB这个接口作为抽象主题角色的代理封装成ClientNamenodeProtocolTranslatorPB来实现到ClientProtocol接口的转换的。
ClientNamenodeProtocolTranslatorPB相当于一个连接器,它也是ClientProtocol的实现类,将ClientProtocol中的每一个方法连接到底层的ClientNamenodeProtocolPB的每一个方法,上层的Failover Proxy的代理只关心ClientProtocol,通过这个translator,调用到底层ClientNamenodeProtocolPB的每一个方法。
比如,mkdirs()方法在ClientNamenodeProtocolTranslatorPB中如下所示。将上层的Java类型的相关参数转换成protobuf的相关参数,调用下层的ClientNamenodeProtocolPB的代理。
-------------------------------ClientNamenodeProtocolTranslatorPB---------------------------
@Override
public boolean mkdirs(String src, FsPermission masked, boolean createParent)
throws IOException {
MkdirsRequestProto req = MkdirsRequestProto.newBuilder()
.setSrc(src)
.setMasked(PBHelperClient.convert(masked))
.setCreateParent(createParent).build();
return rpcProxy.mkdirs(null, req).getResult(); //这里的rpcProxy就是刚刚创建的基于`ClientNamenodeProtocolPB`这个接口作为抽象主题角色的代理
}
相关参数解析
在构造ConfiguredFailoverProxyProvider的时候,设置了底层Client在建立RPC连接是的相关重试参数:
- ipc.client.connect.max.retries.on.timeouts(默认
0),发生ConnectTimeoutException时最大允许的重试次数。参考构造方法ConfiguredFailoverProxyProvider()和方法Client.Connection.setupConnection()。 - dfs.client.failover.connection.retries(默认
0): 和远程的NameNode建立连接发生IOException的时候,使用RetryUpToMaximumCountWithFixedSleep重试策略中的最大重试次数。参考构造方法ConfiguredFailoverProxyProvider()和方法Client.ConnectionId.setupConnection()。RetryUpToMaximumCountWithFixedSleep是每次sleep固定时间的重试策略。 - ipc.client.connect.retry.interval(默认
1000):和远程的NameNode建立连接发生IOException的时候,使用RetryUpToMaximumCountWithFixedSleep重试策略中的重试时间间隔。
在NameNodeProxiesClient.createHAProxy()中,设置了构建FailoverOnNetworkExceptionRetry的所需要的相关重试参数,如下:
- dfs.client.failover.retry.max.attempts(默认
15):最大的failover_retry的次数。上文已经讲过RetryDecision.FAILOVER_RETRY发生的情况,这时会先performFailover(),然后进行重试。从代码可以看到,这时候除了对failover的次数进行计数加1,也同时对retry的次数进行计数加1,因为无论FAILOVER_RETRY还是RETRY,都是一次重试。参考FailoverOnNetworkExceptionRetry.shouldRetry() - dfs.client.retry.max.attempts(默认10):
FailoverOnNetworkExceptionRetry的最大非Failover重试的次数。我们从FailoverOnNetworkExceptionRetry.shouldRetry()可以看到,这里的精确含义是,非Failover重试的最大重试次数。 - dfs.client.failover.sleep.base.millis(默认
500) 第一次重试前的基础时间间隔基数。以后的重试时间间隔每次都按照指数翻倍,参考FailoverOnNetworkExceptionRetry.calculateExponentialTime() - dfs.client.failover.sleep.max.millis(默认
15000) 最大允许的重试时间间隔基数。基数时间间隔翻倍后的最大允许值。参考FailoverOnNetworkExceptionRetry.calculateExponentialTime()
引用
结语
本文主要介绍了基于动态代理实现的Hadoop客户端实现。动态代理的使用让整个客户端代码变得层次十分清晰,从Failover层,到下面的RPC层。异常处理逻辑作为一个独立单元完全从调用流程中抽象出来。
可以看到,好的设计模式的引用可以让我们的代码耦合度降低,同时有利于后期的扩展和维护。
希望本文能够对那些对Hadoop客户端代码感兴趣的读者提供帮助。
转载时注明出处即可。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JavaScript-jQuery1-笔记
- 使用RFC跳过权限校验的方法
- 请你来了解一下Mysql-InnoDB中事务的两段式提交
- 【DKELM回归预测】基于灰狼算法改进深度核学习极限学习机GWO-DKELM实现数据回归预测附matlab代码
- PYTHON通过跳板机巡检CENTOS的简单实现
- 系列二、Spring Security核心类
- 基于java的飞机大战游戏系统设计与实现
- VMware workstation平台下配置Fedora-Server-39-1.5虚拟机网络
- 疫情防控医护人员派遣系统(源码+开题报告)
- Android Studio安卓读写NFC Ntag标签源码