Spring如何解决循环依赖
前言
我们在介绍中《Spring中Bean的生命周期》一文中发现了一个方法:addSingletonFactory(),它是处理Spring中的循环依赖问题的。
在那里我们没有具体详讲,主要是想单独的开一个循环依赖章节,来具体说明。
了解循环依赖前,我们先来聊一个概念:Spring的三级缓存
- singletonObjects:一级缓存,存放已经经历了完整生命周期的bean对象
- earlySingletonObjects:二级缓存,存放原始的bean对象(尚未填充属性)
- singletonFactories:三级缓存,存放bean工厂对象
Spring 默认情况下是禁止循环引用的,如果要使用,需要在application.yml配置文件中设置为true。
spring:
main:
allow-circular-references: true
我们来搭建一个简单的demo
@Service
public class UserServiceImpl{
@Autowired
private UserServiceImpl2 userServiceImpl2;
public Map getUserById(String userId){
Map map=new HashMap<>();
map.put("userId","guoguo");
return map;
}
public Map getUserById2(String userId) {
return userServiceImpl2.getUserById(userId);
}
}
@Service
public class UserServiceImpl2{
@Autowired
private UserServiceImpl userServiceImpl;
public Map getUserById(String userId) {
Map map = new HashMap<>();
map.put("userId", "guoguo2");
return map;
}
public Map getUserById2(String userId) {
return userServiceImpl.getUserById(userId);
}
}
启动SpringBoot项目,我们来具体看下:
1.循环依赖
我们创建bean,在真正populateBean填充属性前,如果满足了循环依赖的条件,则会调用addSingletonFactory方法,先暴露bean给三级缓存singletonFactories。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
接下来,开始赋值逻辑:populateBean()方法
处理属性注入的时候,AutowiredAnnotationBeanPostProcessor.resolveFieldValue方法会调入:DefaultListableBeanFactory.doResolveDependency()。
在这个方法里,我们需要调用resolveCandidate获取我们依赖的bean。
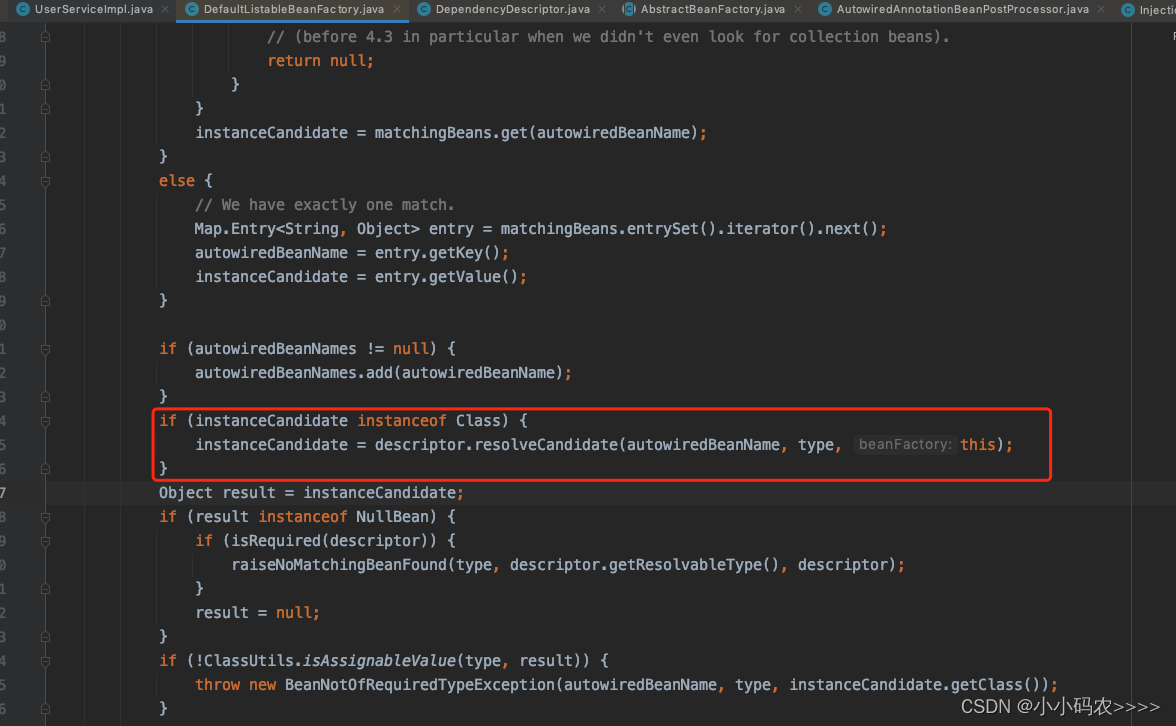
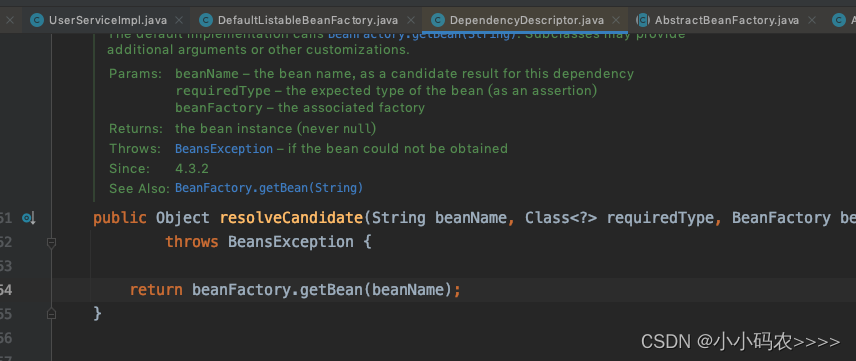
我们看到了熟悉的beanFactory.getBean(beanName)方法,继续进入debug,我们进入AbstractBeanFactory.doGetBean()获取bean的时候,会调用getSingleton方法,需要先从缓存中获取的bean,具体逻辑:
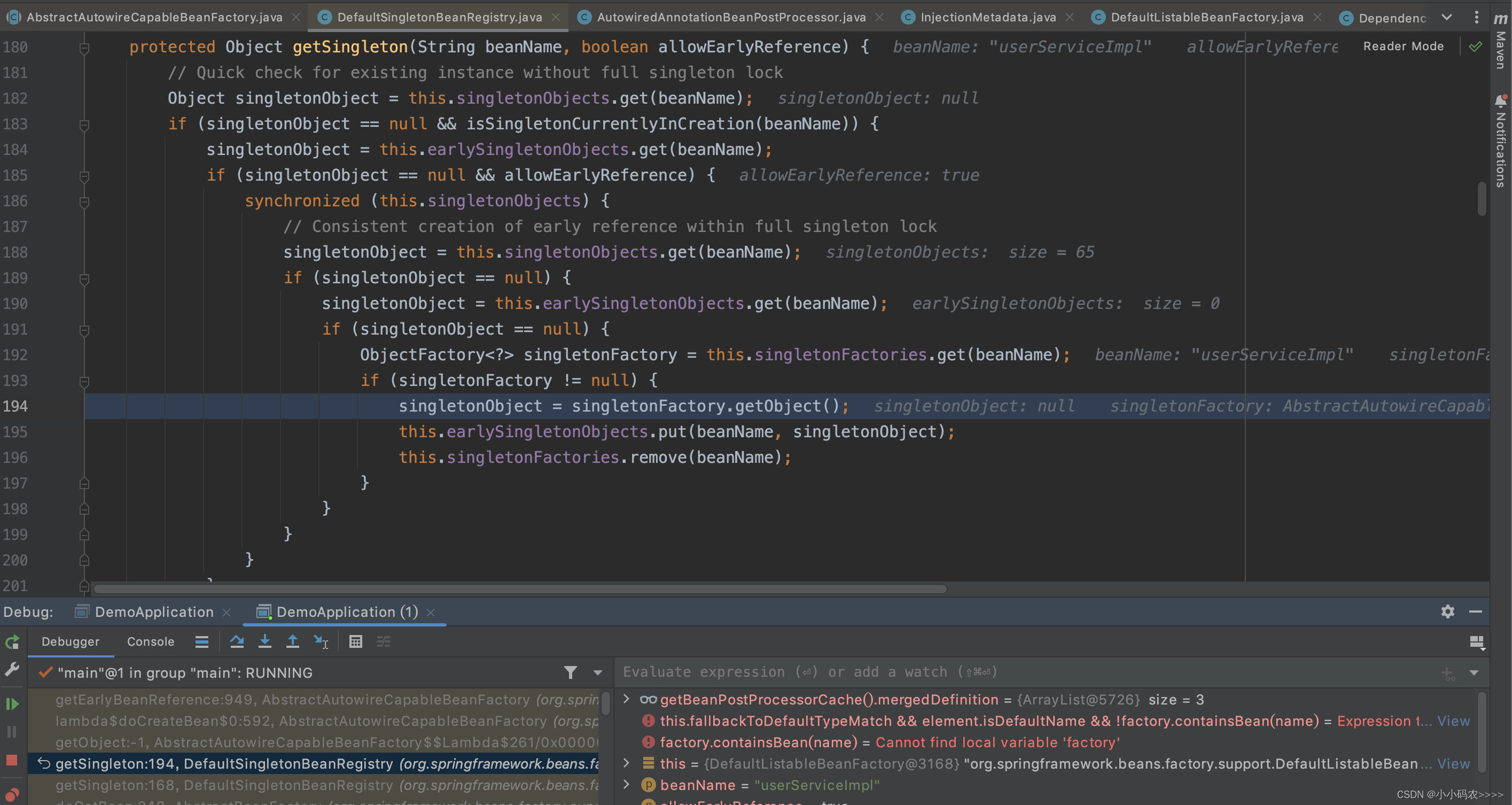
先从一级缓存singletonObjects 中获取,有就返回,没有就找二级缓存;从二级缓存earlySingletonObjects中获取,有就返回,没有就找三级缓存;从三级缓存singletonFactories 中获取,找到了,就获取对象,放到二级缓存,从三级缓存中移除。
从singletonFactories三级缓存中获取对象的方法是:singletonFactory.getObject()
底层调用AbstractAutowireCapableBeanFactory类中的getEarlyBeanReference方法获取,然后存入earlySingletonObjects二级缓存中,返回给对象进行属性注入。
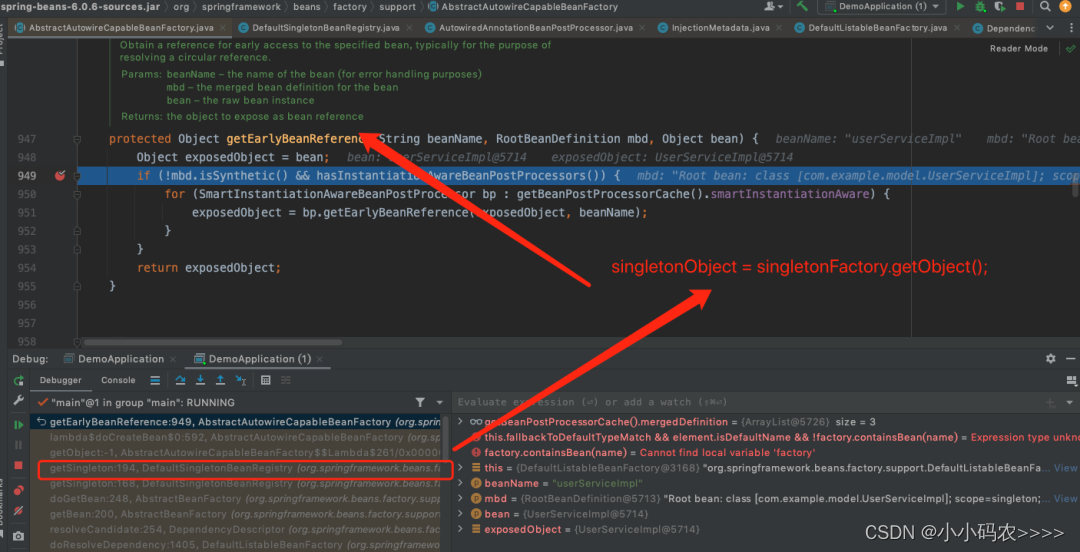
如果缓存中未获取到,则调用createBean() 创建bean。
属性注入成功后,则对象bean初始化成功,finally逻辑里,会将bean放入一级缓存。
DefaultSingletonBeanRegistry.addSinglton():一级缓存的赋值逻辑
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
以上是属性注入的大致源码流程,那Spring中的循环依赖注入是如何实现的呢?
源码解析到这里,其实实现循环依赖的个中缘由已经逐渐明朗了。
我们就拿UserServiceImpl(别名A)和UserServiceImpl2(别名B)举例,具体说明:
1、创建bean过程中,先获取A的bean,如果没有就去创建,然后把A放入singletonFactories三级缓存中;然后在赋值populateBean阶段,A又依赖了B,获取B。
2、获取B的bean的过程中,先调用getSingleton从缓存中获取,如果没有,则创建B,同样在赋值populateBean阶段 发现B又依赖了A,则去获取A。
3、获取A的bean的过程中,先调用getSingleton从缓存中获取,因为步骤一,三级缓存中已经存储过A,所以可以直接获取到,则放入earlySingletonObjects二级缓存中,并清除三级缓存。
4、回到步骤二,现在有了A的对象,则可以完成B对象中的A属性注入,B初始化成功,将B放入一级缓存singletonObjects。
5、回到步骤一,现在B初始化成功,则可以完成A对象中的B属性注入,A初始化成功,将A放入一级缓存中singletonObjects。
面试回答:
- 首先 A 完成初始化第一步并将自己提前曝光出来(通过 ObjectFactory 将自己提前曝光),在
初始化的时候,发现自己依赖对象 B,此时就会去尝试 get(B),这个时候发现 B 还没有被创建
出来; - 然后 B 就走创建流程,在 B 初始化的时候,同样发现自己依赖 C,C 也没有被创建出来;
- 这个时候 C 又开始初始化进程,但是在初始化的过程中发现自己依赖 A,于是尝试 get(A)。这
个时候由于 A 已经添加至缓存中(一般都是添加至三级缓存 singletonFactories),通过
ObjectFactory 提前曝光,所以可以通过 ObjectFactory#getObject() 方法来拿到 A 对象。C 拿
到 A 对象后顺利完成初始化,然后将自己添加到一级缓存中; - 回到 B,B 也可以拿到 C 对象,完成初始化,A 可以顺利拿到 B 完成初始化。到这里整个链路
就已经完成了初始化过程了。
至此,我们完成了对Spring循环依赖问题的解析。。。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!