基于Spark个性化图书推荐系统
介绍
该系统基于Spark,结合了协同过滤算法和个性化推荐技术,实现了一款个性化的书籍推荐系统。
在该系统中,用户可以通过登陆注册后进入系统,查找和筛选自己喜欢的图书信息,同时也能够获得基于用户历史浏览、评分等数据的协同过滤推荐算法推荐的10本与其兴趣相关的优质图书信息。
此外,系统还实现了基于物品的协同过滤算法,根据用户浏览记录、评分记录以及其他相关信息,向用户推荐5本与其当前正在浏览的图书相关的书籍。同时,系统支持图书分类、分页查询、高分书榜等功能,方便用户体验。
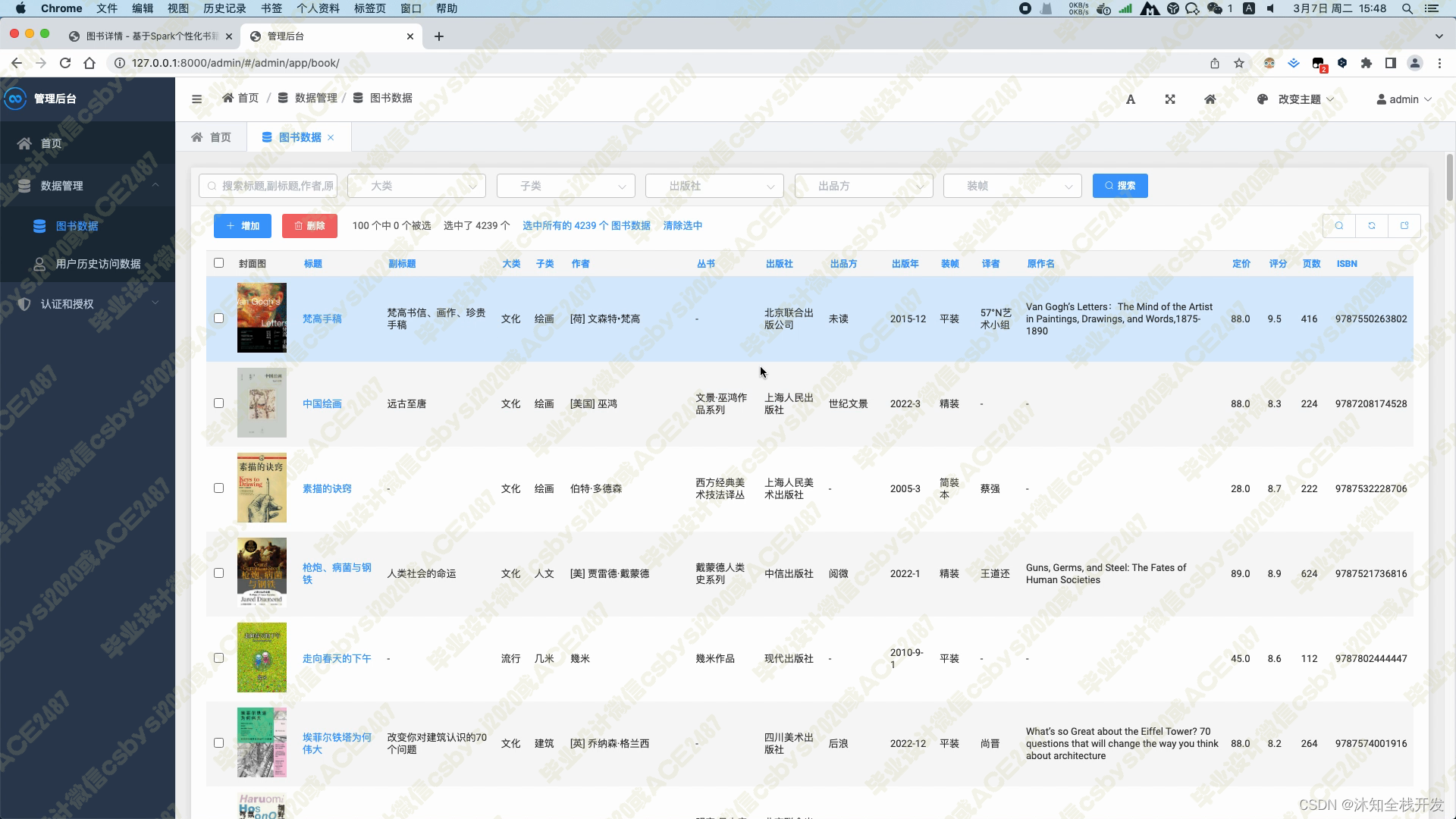
管理员还可以在后台管理所有抓取到的图书数据,为用户提供更加丰富的图书资源。
总之,该系统能够为用户提供个性化、多样化的图书推荐服务,帮助用户快速找到自己喜欢的图书,提高阅读体验,实现更好的知识传递和分享。
技术栈
python pyspark hadoop django scrapy vue element-plus 协同过滤算法
通过scrapy爬虫框架抓取“豆瓣读书”网站上的书籍数据
前台用户通过登陆注册后进入系统
管理员可在后台管理所有抓取到的图书数据
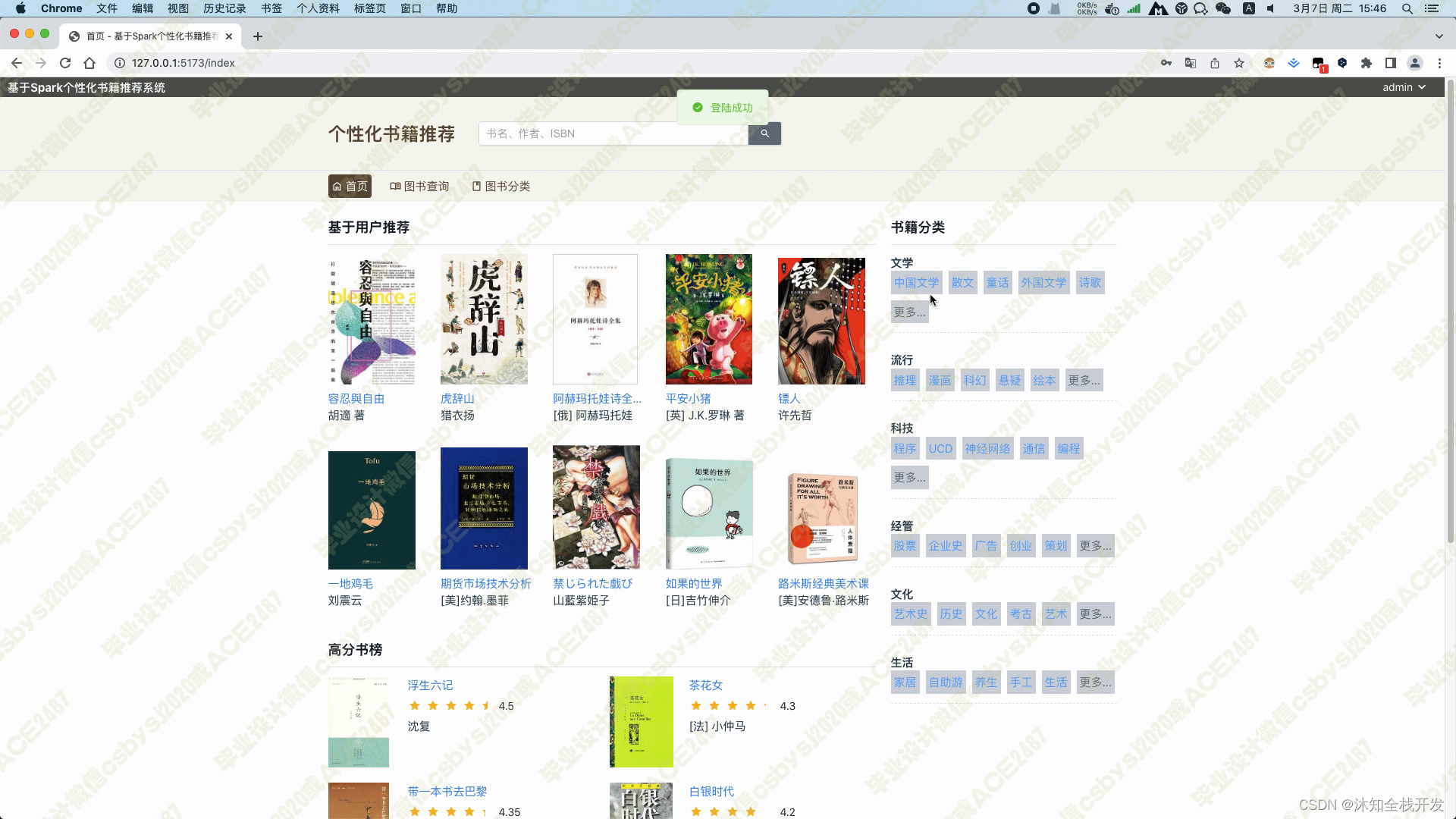
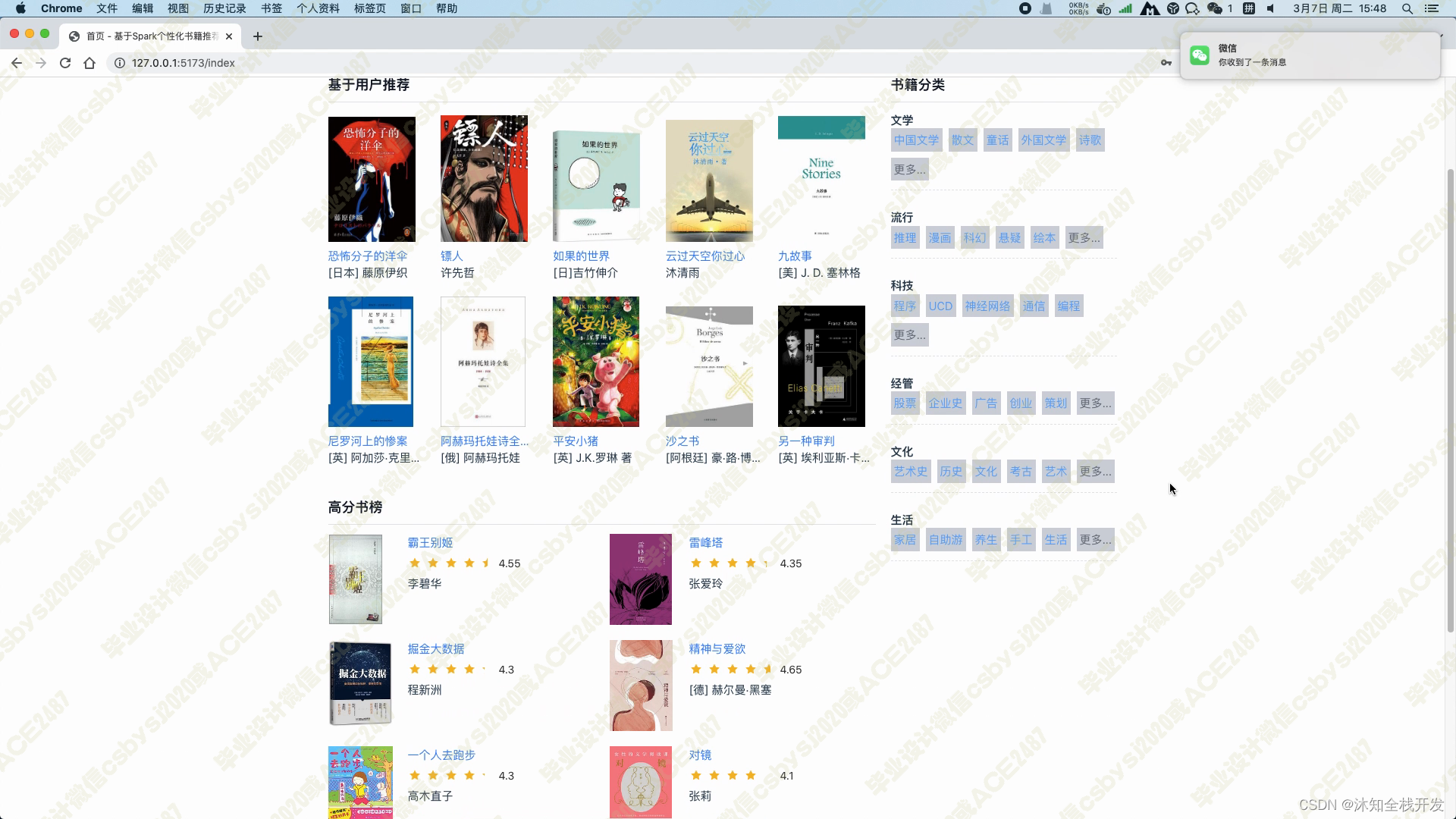
首页分为左右两侧,右侧展示所有图书的分类,比如文学、流行、科技、经管、文化、生活等大类,大类下亦有许多小类;左侧展示基于用户的协同过滤推荐算法给用户推荐的10个图书数据,下方是根据图书评分推荐的高分书榜
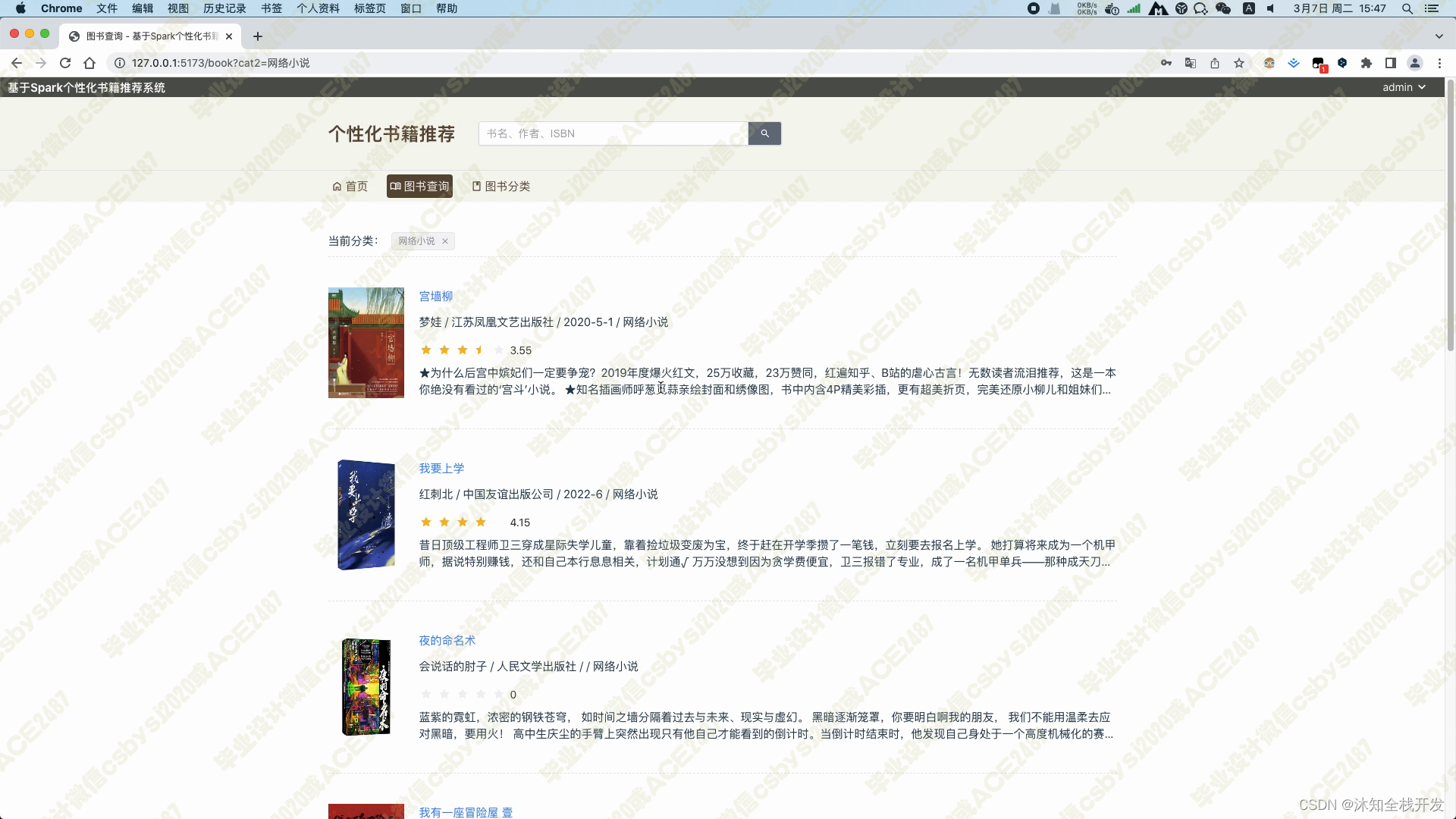
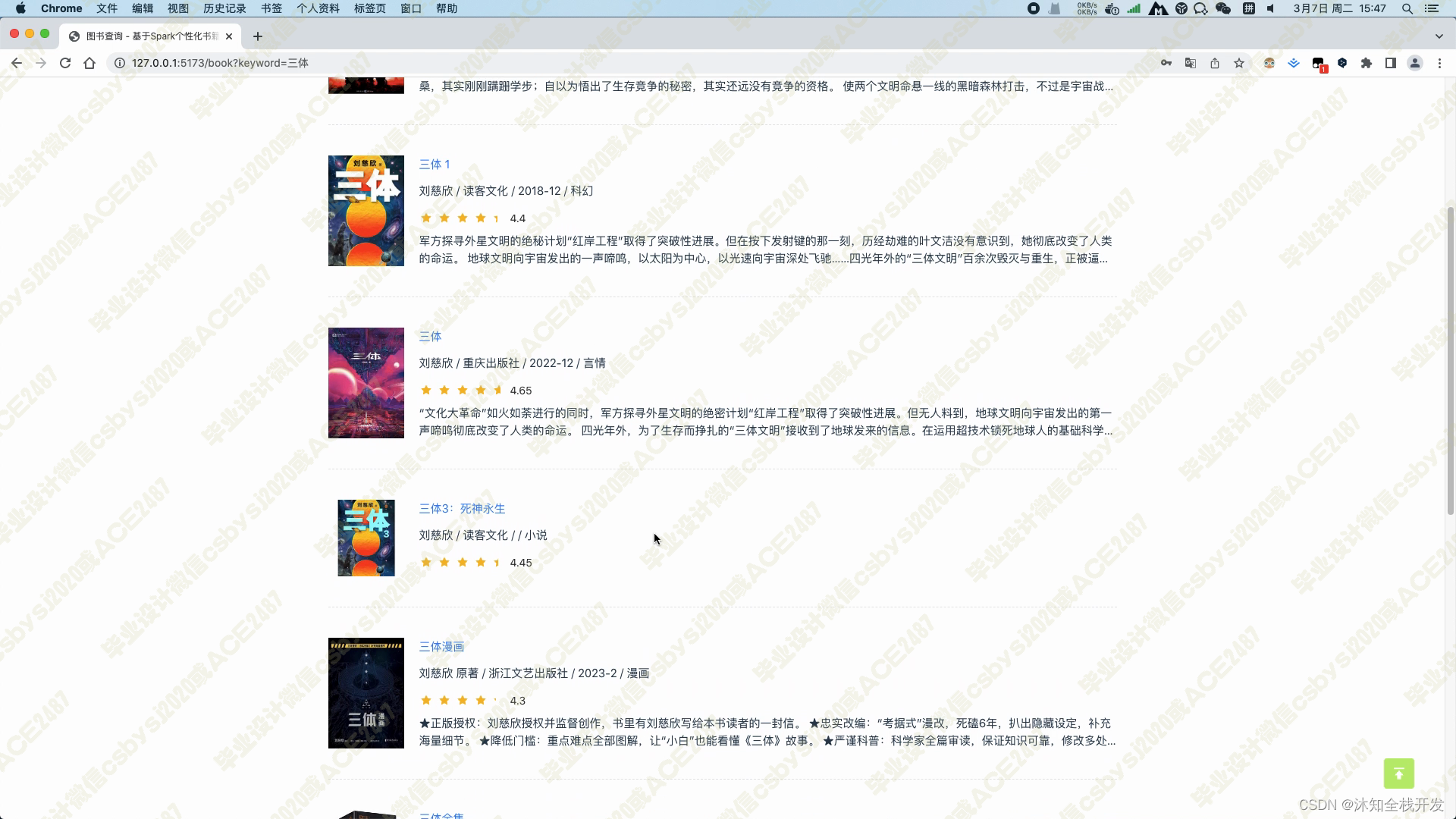
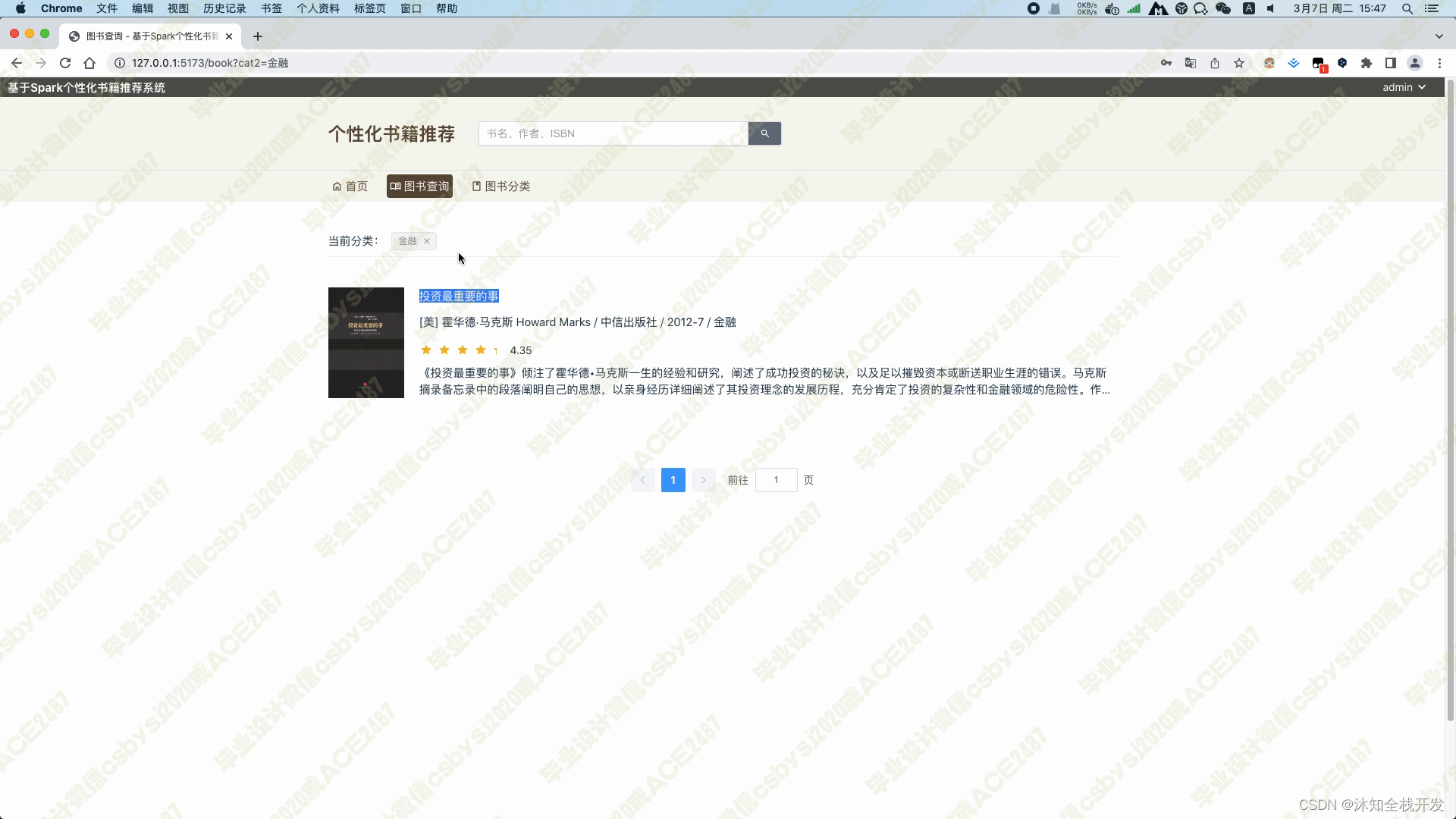
图书查询模块,可以根据书名、书籍分类、作者和ISBN等信息筛选图书,底部带有一个分页器,以10本书籍信息为一页实现分页查询,降低后端数据库的压力
图书分类模块,展示了所有图书的大类小类,用户可以通过点击某一分类,实现快速查找合适自己口味的图书信息
当用户访问某一书籍详情时,页面展示了图书的封面、作者、译者、出版社、出品方、类型、出版年、页数、装帧类型、ISBN等基本信息,还展示了图书的内容简介以及大纲等;在此页面的底部最后部分,我们向用户推荐了5本基于物品的协同过滤算法推荐的图书结果
视频
032 基于Spark个性化图书推荐系统-设计展示
截图








本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 云原生技术专题 | 解密2023年云原生的安全优化升级,告别高危漏洞、与数据泄露说“再见”(安全管控篇)
- 关于Python里xlwings库对Excel表格的操作(二十二)
- 平衡小车——PID控制理论
- Datawhale 强化学习笔记(二)马尔可夫过程,DQN 算法
- HTTP协议编程实战(一)实战一
- Qt6入门教程 7:信号和槽机制(原理和优缺点)
- C++实现增序含头结点的单链例题:现已知单链表L中结点是按整数值递增排列,试写一算法将值为X的结点插入到表L中,使得L任然递增有序
- 【ARM 嵌入式 编译系列 2.1 -- GCC 预处理命令 #error 和 #warning 详细介绍 】
- 2023/12/26 work
- TrustZone之问答