k8s---pod控制器
前言
Pod 是 Kubernetes 集群中能够被创建和管理的最小部署单元。所以需要有工具去操作和管理它们的生命周期,这里就需要用到控制器了。
Pod 控制器由 master 的 kube-controller-manager 组件提供,常见的此类控制器有 Replication Controller、ReplicaSet、Deployment、DaemonSet、StatefulSet、Job 和 CronJob 等,它们分别以不同的方式管理 Pod 资源对象。
?
pod相关知识
pod控制器:工作负载,workload。用来实现管理pod的中间层,确保pod资源符合预期的状态。
pod控制器的多种类型?
(1)ReplicaSet: 代用户创建指定数量的pod副本,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet主要三个组件组成:
? ?1)用户期望的pod副本数量
? ?2)标签选择器,判断哪个pod归自己管理
? ?3)当现存的pod数量不足,会根据pod资源模板进行新建
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment。
(2)Deployment:工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
ReplicaSet 与Deployment 这两个资源对象逐步替换之前RC的作用。
(3)DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如ELK服务
特性:服务是无状态的
服务必须是守护进程
(4)StatefulSet:管理有状态应用
(5)Job:只要完成就立即退出,不需要重启或重建
(6)Cronjob:周期性任务控制,不需要持续后台运行
?
pod与控制器的关系
1.controllers:管理控制器。
pod通过label---->selector进行关联。
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
这是deployment的默认更新策略
rollingUpdate:滚动更新。
maxSurge: 25%:升级过程种,新启动的pod数量不能超过期望pod数的25%。
maxUnavailable: 25% 升级过程中,新的pod启动好后,销毁的旧的pod的数量不能超过期望pod的25%。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx1
name: nginx1
spec:
replicas: 3
selector:
matchLabels:
app: nginx1
strategy:
type: Recreate
每次有更新,都会把旧的pod全部停止,然后再启动新的实例。服务可能会短暂的中断。
template:
metadata:
labels:
app: nginx1
spec:
containers:
- image: nginx:1.22
name: nginx
resources: {}
status: {}
2.无状态应用:
pod的名称是无序的,任务所有pod都是一体的。共享存储NFS。
所有deployment下的pod共享一个存储。
pod容器中的有状态和无状态的对比
?
(1)有状态实例?
- 实例之间有差别,每个实例都有自己的独特性,元数据不同,例如etcd,zookeeper
- 实例之间不对等的关系,以及依靠外部存储的应用?
(2)无状态实例?
- deployment认为所有的pod都是一样的
- 不用考虑顺序的要求
- 不用考虑在哪个node节点上运行
- 可以随意扩容和缩容
statfulSet
有状态应用。pod的名称是有序的,所有pod都是独立的。存储卷也是独立的。
顺序0-n,delete删除也不会改变pod的序号。扩缩容也是有序扩缩容
headless service:无头服务,没有clusterIP。
必须要有动态的pvc。
StatefulSet 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和扩缩。
- 有序的、自动的滚动更新。
实验展示:
?
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx2
name: nginx-web
spec:
ports:
- port: 80
targetPort: 80
clusterIP: ""
selector:
app: nginx2
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
labels:
app: nginx2
spec:
replicas: 3
selector:
matchLabels:
app: nginx2
serviceName: "nginx-web"
template:
metadata:
labels:
app: nginx2
spec:
containers:
- name: nginx
image: nginx:1.22
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: html
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "nfs-client-storageclass"
resources:
requests:
storage: 2Gi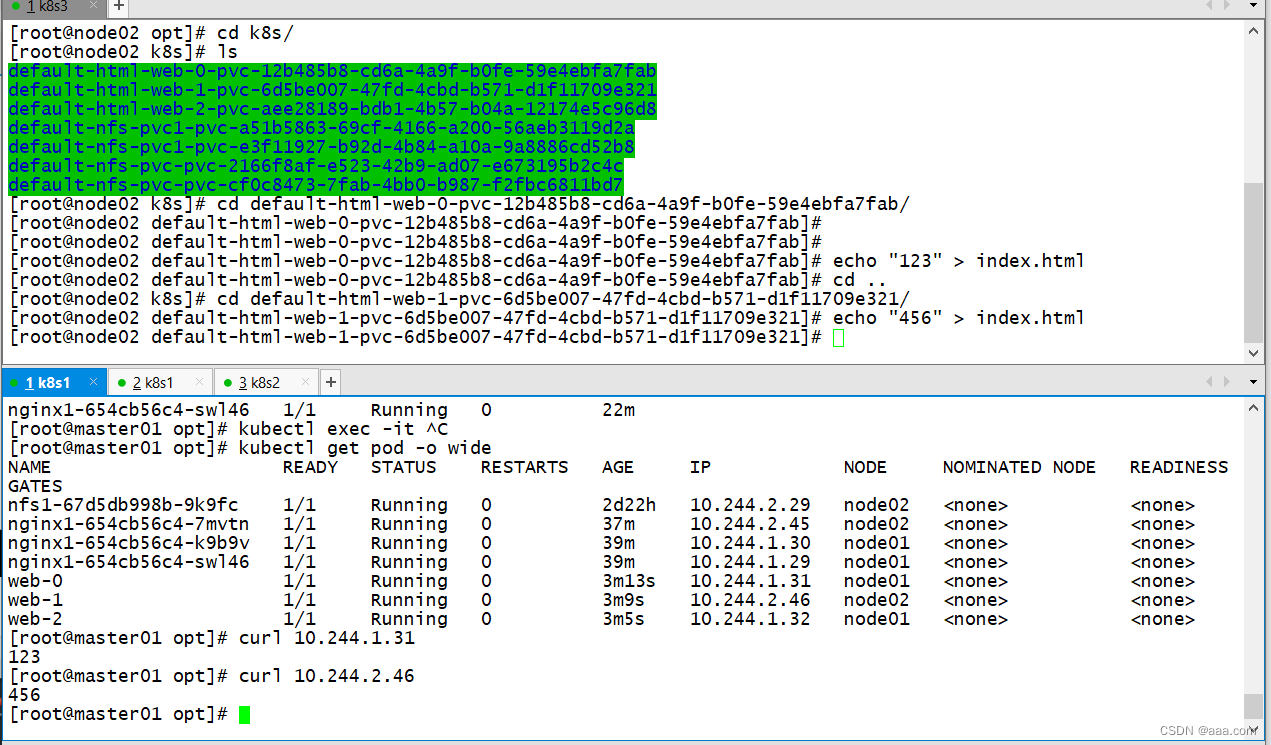
进行扩缩容演示
kubectl edit sts按照序号升序创建

按照序号降序创建

headless service:k8s集群中一种特殊的服务类型,不分配clusterIP给service。也不会负载均衡到后端的pod。
DNS来提供服务的发现和访问。
由于clusterip是空的,k8s集群会给每个headless service中的Pod创建一个dns记录。
格式:pod-name。headless-service-name.namespace.svc.cluster.local
web-0 nginx-web defaults 本地地址(pod的IP)
通过dns直接解析访问pod的IP地址
为什么要用headless:
在deployment中,pod是没有名称,随机字符。而statefulset是要求有序的,每一个pod的名称必须是固定的。因此需要一个集中的clusterip来集中统一为pod提供网络。系统可以直接通过pod名称直接解析IP地址。
为什么要有vloumeClaimTemplates:
有状态的副本集群都会涉及持久化存储,每个pod是独立个体,每个pod都有一个自己专用的存储点。
statefulSet在定义的时候就规定了每个pod是不能同一个存储卷,所以才需要动态pv。
statefulset应用场景
不是固定节点的应用,不是固定IP的应用。
更新发布比较频繁。
支持自动伸缩,节点资源不够,可以自动扩缩容
删除statefulset
不需要clusterIP。没有clusterIP的就是无头服务headless
daemonse
确保每个节点上都运行一个pod副本。当node加入集群,也会为他新增一个pod。
当node节点从集群当中移除时,pod也会被回收。
kubectl explain daemonset
实验展示:
?
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: nginx-1
name: nginx-daemon
#提高代码可读性,不同业务可以通过namespace隔离。
spec:
selector:
matchLabels:
app: nginx-1
template:
metadata:
labels:
app: nginx-1
spec:
containers:
- image: nginx:1.22
name: nginx
daemonset不能指内副本数。

会在所有节点上都布置一个。但daemonset本身不能指定副本数。
指定标签 ingress=true的节点上部署,如果没有匹配的标签,则不会创建。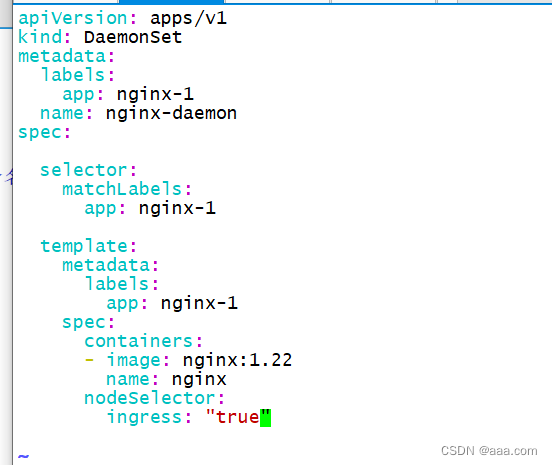
由此看来,daemonset不需要指定调度策略,默认会在每个节点创建一个pod。除非设置了污点。
我们可以通过指定的方式,只把daemonset部署在指定的节点。
没有副本数选择,不需要设置。
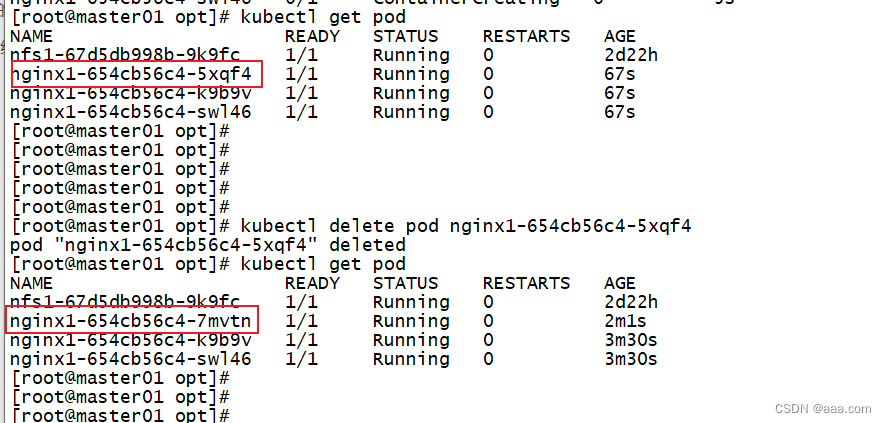
控制器类型的资源创建方式:基于控制器创建的pod,delete只是相当于重启,要彻底删除pod,必须删除控制器。
job
job分为两类
job:普通任务
cronjob:定时任务
job的作用
执行只需要一次性的任务
脚本需要执行,数据库迁移,视频解码等业务
对于k8s系统来说,既然定义了是job,你只需要执行一次,或者指定次数即可,不能一直允许。
第一个:必须要指定的容器策略 onfailure never
第二个:执行失败的次数也是受限的。默认是6次。
第三点:更新yaml文件,先删除任务,再更新,不能动态更新。
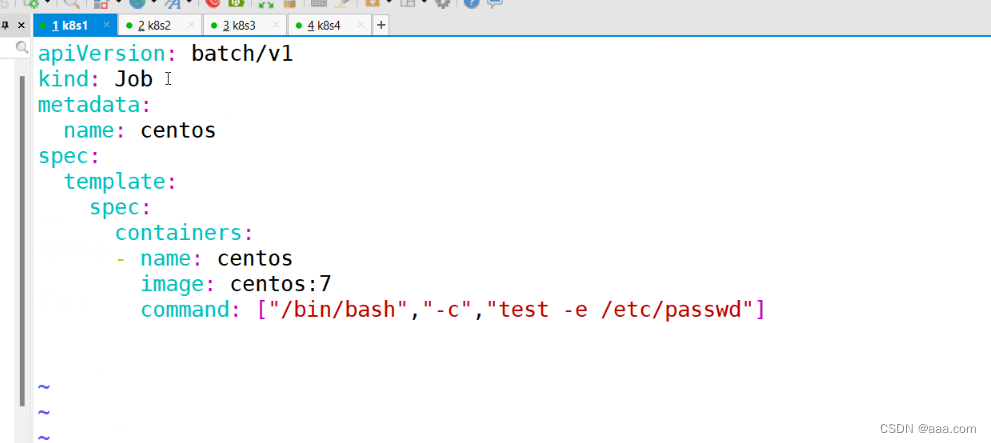
apiVersion: batch/v1
kind: Job
metadata:
name: centos
spec:
template:
spec:
containers:
- image: centos:7
name: centos
command: ["/bin/bash","-c","test -e /etc/passwd"]
restartPolicy: Never
backoffLimit: 4
允许任务失败的次数是4次,4次到了之后,restartPolicy的策略,来进行容器的重启或者不重启。
cronjob
周期性任务,定时执行,和linux的crontab一模一样,语法一样
分 时 日 月 周
应用场景:定时备份,通知作用。定时任务(结合探针一起做)

apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
concurrencyPolicy: Allow
#如果执行失败的任务的保留的个数,默认是1个。
startingDeadlineSeconds: 15
#pod启动后必须在一定的时间内开始执行,如果超过15秒没有运行,任务将不会运行,任务也会标记失败。
successfullJobHistoryLimit: 3
#保留成功的任务数,默认值是3个
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: centos:7
command: ["/bin/bash","-c","date; echo 123"]
restartPolicy: OnFailure


如果超过的次数 get pod不会保存
超过次数,会滚动更新
总结:
五个都是控制器创建的pod。都是依赖于控制器
deployment:无状态应用,最好用,也是最多的类型
statefulSet:有状态应用,有序的,独立的pod。
daemonset:无状态应用,不能定义副本数,每个节点都运行一个pod,也可以指定节点
job:执行一次性的任务,必须要有重启策略。同时默认失败次数是6次,只有失败次数达到,容器的重启策略才会生效
cronjob:定时任务
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- XTU-OJ-1436-礼物-笔记
- 模糊数学在处理激光雷达的不确定性和模糊性问题中的应用
- 01.03
- 通信原理 | link11 M系列消息格式仿真数据生成(基于python的M.0仿真数据)
- 中国ESG的新故事:主动、常态与变革
- Learning Vision from Models Rivals Learning Vision from Data
- 如何用MetaGPT帮你写一个贪吃蛇的小游戏项目
- 从事涉密测绘业务的人员应当具有中华人民共和国国籍,签订保密责任书,接受保密教育。
- 栈与队列part03
- 算法通关村第十八关-黄金挑战回溯困难问题