一次TCP TIME_WAIT连接数过多告警处理
更多技术文章,快来关注微信公众号“运维之美”,不定期更新领取IT学习资料
1、前言
客户环境上在业务高峰期的时候,突然收到主机的TCP time_wait连接数告警过多的告警。运维侧及时介入分析,通过本文的处理方式和思路,希望给你在问题处理过程中提供灵感。
2、问题回顾
客户反馈收到如下告警,主机TCP timewait连接数过多
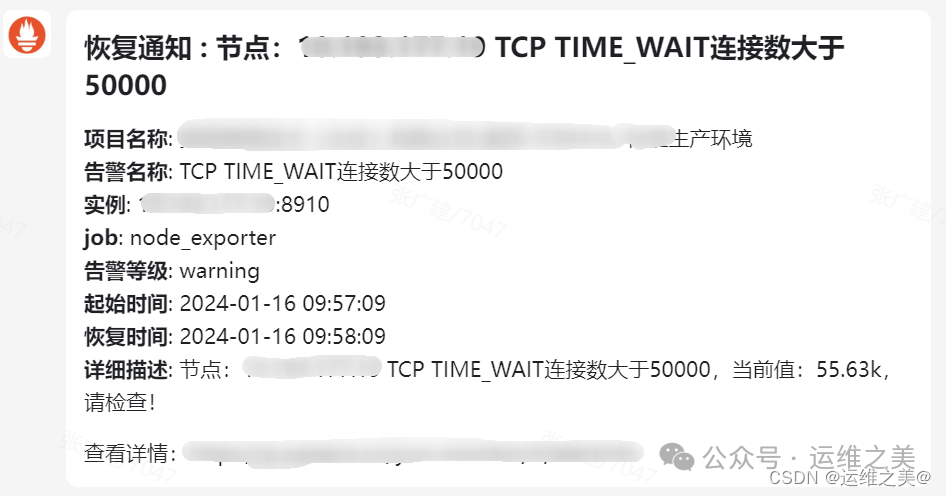
prometheus告警表达式
node_sockstat_TCP_tw > 50000
收到连接数过多的告警并不代表一定会产生生产问题,此时要关注负载是否直线上升,连接数一直无法释放,如果出现此情况,则需要及时处理,避免造成生产环境宕机。
连接数数据来源:/proc/net/sockstat
线上场景中,持续的高并发场景
一部分 TIME_WAIT 连接被回收,但新的 TIME_WAIT 连接产生,新产生的连接数超过释放的速度;
一些极端情况下,会出现大量的 TIME_WAIT 连接。
Think:上述大量的 TIME_WAIT 状态 TCP 连接,有什么业务上的影响吗?
Nginx 作为反向代理时,大量的短链接,可能导致 Nginx 上的 TCP 连接处于 time_wait 状态:
每一个 time_wait 状态,都会占用一个「本地端口」,上限为 65535
当大量的连接处于 time_wait 时,新建立 TCP 连接会出错,address already in use : connect 异常
Tips:TCP 本地端口数量,上限为 65535(6.5w),这是因为 TCP 头部使用 16 bit,存储「端口号」,因此约束上限为 65535。
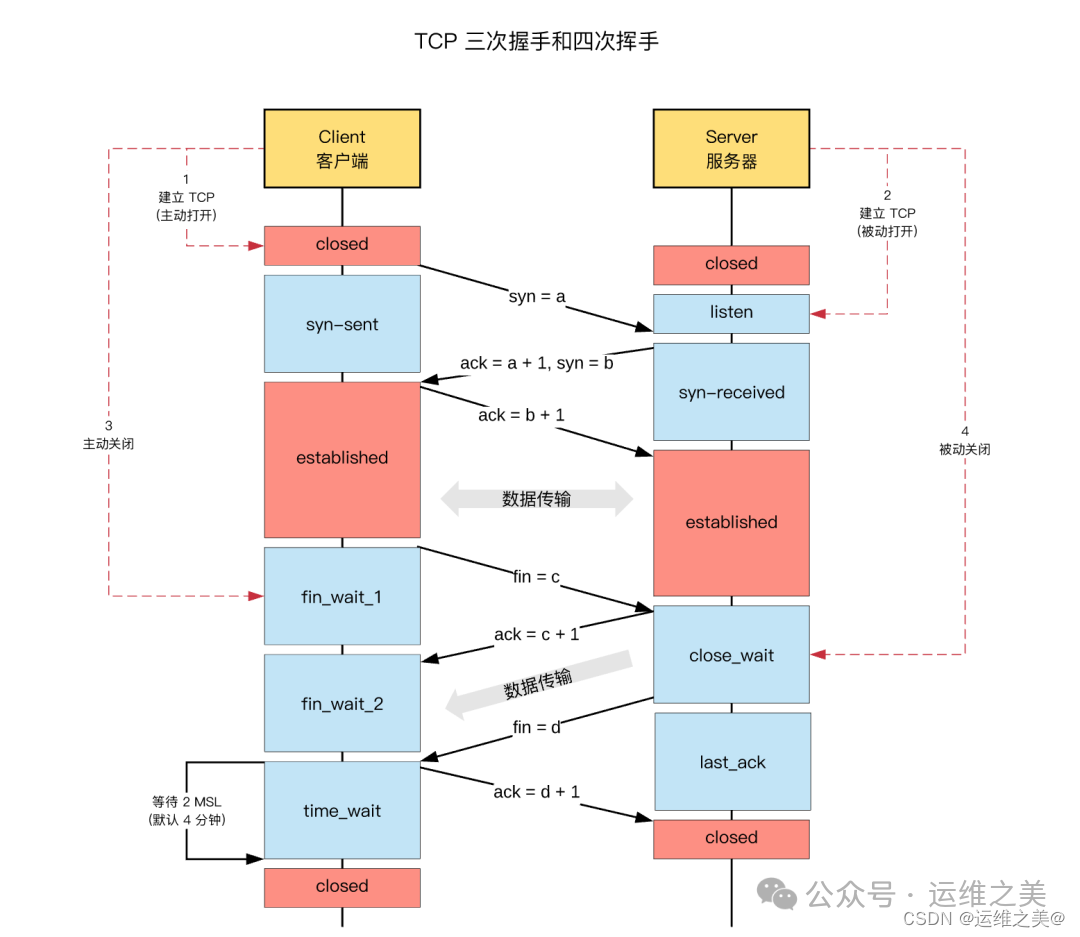
time_wait 状态的影响
TCP 连接中,「主动发起关闭连接」的一端,会进入 time_wait 状态
time_wait 状态,默认会持续 2 MSL(报文的最大生存时间)
time_wait 状态下,TCP 连接占用的端口,无法被再次使用
TCP 端口数量,上限是 6.5w(65535,16 bit)
net.ipv4.ip_local_port_range = 1024 65000 #端口数和这个参数有关系
大量 time_wait 状态存在,会导致新建 TCP 连接会出错,address already in use : connect 异常
大量的连接会导致服务器资源使用上升
现实场景
服务内部调用过多,优化业务模式,也可以是连接关闭方式需要优化
Nginx 反向代理场景中,可能出现大量短链接,服务器端可能存在
解决思路
1、服务器端允许 time_wait 状态的 socket 被重用
2、缩减 time_wait 时间,设置为 1 MSL(即,2 mins)
3、解决方案
TCP连接数统计脚本
#!/bin/sh
for i in /proc/* ;
do
if [ -d $i/fd ];then
echo $i $(ls $i/fd -l | grep socket: |wc -l)
fi
done
通过这个脚本可以统计出当前分配连接数的进程,通过进程可以找到对应的服务,如果是服务关闭连接的姿势不对,业务方优化即可
在业务侧解决此问题之前,我们可以通过操作系统的内核参数缓解此问题
方案
修改配置文件/etc/sysctl.conf
1、允许将TIME_WAIT状态的socket重新用于新的TCP连接
net.ipv4.tcp_tw_reuse = 1 #默认为0,表示关闭,如果为0,修改为1
2、快速回收TIME_WAIT状态的socket
net.ipv4.tcp_tw_recycle = 1 #修改为1,默认为0
3、修改time_wait连接数的回收时间
cat /proc/sys/net/ipv4/tcp_fin_timeout #查看默认的MSL值
net.ipv4.tcp_fin_timeout = 30 #如果为60,修改为30s回收
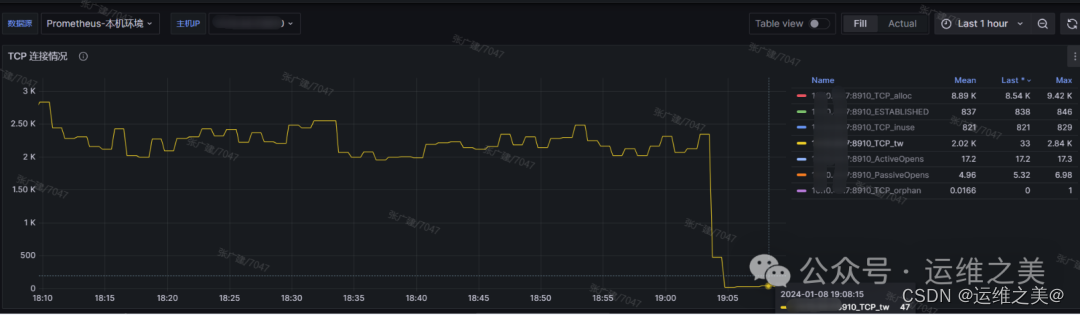
最后sudo sysctl -p 使配置生效即可,从修改前后的效果上可以看到,timewait的回收明显加快了
最近,我们建立了一个技术交流微信群。有兴趣的同学可以加入和我们一起交流技术,在 「运维之美」 公众号直接回复 「加群」 邀请你入群,QQ群:947473916。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- leetcode第 381 场周赛最后一题 差分,对称的处理
- 行业归宿之路:明理信息科技教你如何打造知识付费平台
- 区块链实验室(32) - 下载arm64的Prysm
- 算法实战(二)
- 功能强大且易于使用的视频转换软件—Avdshare Video Converter for Mac/win
- 设计模式详解---模板方法模式
- angular_indexedDb的用法_ngx-indexed-db
- 《数据库概论》 第八章 数据库编程
- 算法题中常用数学概念、公式、方法汇总(其一:数列)
- JAVA_ArrayList添加元素时的源码分析(jdk17)