动手学深度学习二:关于熵和损失函数的理解
发布时间:2024年01月11日
李沐动手学深度学习
课程网址:https://courses.d2l.ai/zh-v2/
包含教材和视频网址链接
关于熵,教材中的描述非常形象,那就是描述信息量多少。当我们根据一些数据去预测一个结果,如果这些数据都单一的指向结果,那么这些数据对结果的预测没有信息量。但如果这些数据不能直接指向预测的结果,我们会感到很诧异,相比下来这些数据包含了更多的信息量。(感觉类比于程序员修bug,越是输出不符合预期,这个bug的信息量就越多。)
我们对于模型的最终表现期望,就是对于已知数据集的分布,预测出来的概率分布趋近于实际的分布,也就是模型在训练的过程中,熵是不断减小的过程。
交叉熵损失函数的表达是:
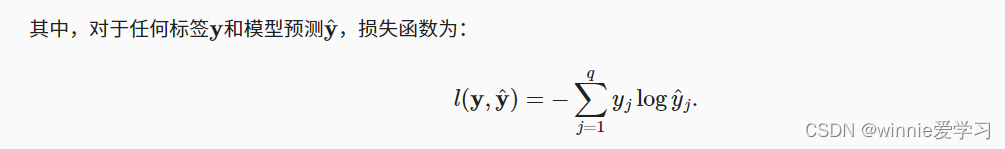
其中y_hat是softmax函数,保证输出的类别概率在0-1之间,并且概率总和为1,相当于对输出做了规范。将softmax函数带入上式求导


神奇的一幕出现了,损失函数对于未规范化的估计值梯度,表示的就是观测值和估计值的差,模型训练过程中,随着梯度的减小(随机梯度下降),观测值和估计值的差也会减小。
如果理解有误,欢迎交流讨论!
文章来源:https://blog.csdn.net/qq_35668469/article/details/135516011
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android Studio开发工具:解决 gradle构建项目太慢了的方案,使用 华为的服务器,不需要镜像,直接快速安装
- 力扣(leetcode)第35题搜索插入位置(Python)
- 【解决方法】zip文件压缩后还是太大,怎么办?
- Simply简洁博客主题源码 | EmlogPro主题模版
- 【已解决】namespace “Ui“没有成员 xxx
- 【中危】IoTDB 存在远程代码执行漏洞
- 【算法题】68. 文本左右对齐
- RuntimeError: Torch is not able to use GPU; 解决方案
- Linux操作系统( YUM软件仓库技术 )
- 下载 SQL Server Management Studio (SSMS)