亚信安慧AntDB数据并行加载工具的实现(一)
1.概述
数据加载速度是评判数据库性能的重要指标,能否提高数据加载速度,对文件数据进行并行解析,直接影响数据库运维管理效率。基于此,AntDB分布式数据库提供了两种数据加载方式:
一是类似于PostgreSQL的Copy命令,二是通过AntDB提供的并行加载工具。Copy命令是大家都比较熟悉的,但Copy命令导入数据需要通过CN节点,制约了数据的导入性能,无法实现并行、高效的加载。而AntDB并行加载工具可以绕过CN节点,直连数据节点,大大提高了加载的速率。
2.实现原理
2.1并行加载工具整体流程
并行加载工具有两种线程,一种是文本处理线程,另外一种是数据处理线程。文本处理线程只有1个,用来读取文件,并按行进行拆分,拆分后将行数据发送到数据处理线程。数据处理线程是多个,并行分析行数据,并加载到相应数据节点。

图1 并行加载工具架构
2.2文本处理
并行加载工具支持Text和Csv两种格式的文件,下面简要说明下。Text和Csv文件都是以纯文本形式存储表格数据的,文件的每一行都是一个数据记录。每个记录由一个或多个字段组成,用分隔符分隔。文本处理线程的任务就是从文件中提取一行完整的记录,然后发送给数据处理线程。
文件中每一行数据以字符’\n’或者’\r\n’结尾。当是Csv文件是,由于Csv文件支持引用字符,当‘\n’、’\r\n’出现在引用字符中间时,作为普通字符处理,不能作为行结尾。Csv的引用字符为单字节字符,用户可以根据需要自己指定,未指定的话默认是双引号。
2.3行数据处理
数据处理线程用来分析文本处理线程发来的行数据,行数据由一个或多个字段组成,用分隔符分隔,分隔符可以指定。
数据处理线程从CN获取数据库及表相关信息,包括数据库编码方式,表分片方式,表的分片键等。
AntDB数据库中的表支持以下4中分布方式:
- 复制表
- Hash分片表
- 取模分片表
- 随机分片表
并行加载工具会根据表的分布方式生成相应的导入策略。以下以不同的表分布方式说明并行加载工具的导入策略。
- 复制表在每个DN数据节点都保留完整的数据,复制表的数据导入时,需要将行数据插入到所有DN节点。
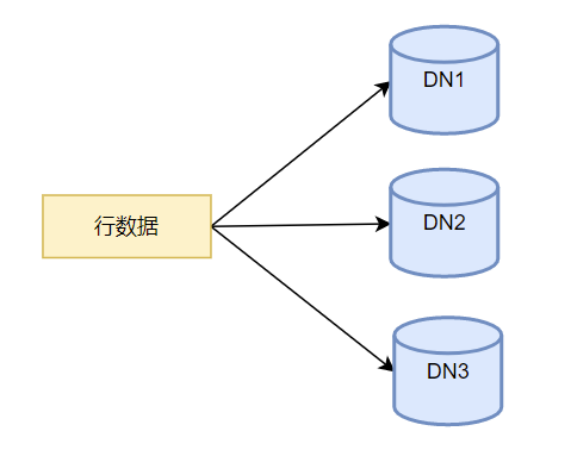
图2 复制表数据加载流程
- Hash分片表将表数据分散到各DN节点,通过对分片键进行Hash,确定行数据属于哪个DN节点。并行加载工具的行处理线程,通过CN节点获取Hash分片表的分片健,对其进行Hash,然后将该行数据插入对应的DN节点,并行加载工具中的Hash分片的算法需要和CN节点的Hash算法一致。

图3 hash分配表数据加载流程
- 取模分片表也是将表数据分散到各DN节点,通过对分片键进行取模确定行数据所属DN节点,并行加载工具导入的处理策略与Hash分片表相同,只是将Hash计算换成了取模的方式。
- 随机分片表没有分片键,而是将数据根据随机分配到各DN节点。并行加载工具在每行数据导入前执行各随机函数,根据函数的返回值确定应该导入哪个节点。
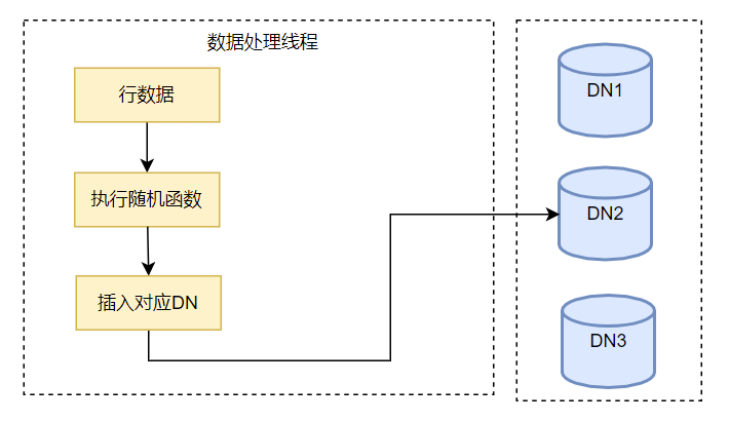
图4 随机分片表数据加载流程
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 众和策略小资大变身:穷人炒股的技巧有哪些?
- 测试工具Jmeter:设置中文界面
- 【计算机四级(网络工程师)笔记】操作系统运行机制
- DshanMCU-R128s2 R128 模组
- Python与人工智能
- 怎么在PDF添加文本框?6种快速向PDF添加文字教程
- Java网络编程原理与实践--从Socket到BIO再到NIO
- C++八股2
- 【Vue3+Ts项目】硅谷甄选 — 品牌管理+平台属性管理+SPU管理+SKU管理
- 开源预约挂号平台 - 从0到上线