Hive基础知识(十):Hive导入数据的五种方式
发布时间:2024年01月12日
1. 向表中装载数据(Load)
1)语法
hive> load data [local] inpath '数据的 path'[overwrite] into table student [partition (partcol1=val1,…)];(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
2)实操案例
(0)创建一张表
create table student(id string, name string) row format delimited fields terminated by '';(1)加载本地文件到 hive
hive (hive3)> load data local inpath '/home/atguigu/student.txt' into table hive3.student;
Loading data to table hive3.student
OK
Time taken: 1.007 seconds查询结果:
hive (hive3)> select * from student;
OK
student.id student.name
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
1001 zzz
1002 ddd
1111 ccc(2)加载 HDFS 文件到 hive 中
上传文件到 HDFS
hive (default)> dfs -put /opt/module/hive/data/student.txt /user/atguigu/hive; 加载 HDFS 上数据
hive (default)> load data inpath '/user/atguigu/hive/student.txt' into ?table default.student;(3)加载数据覆盖表中已有的数据
上传文件到 HDFS
hive (default)> dfs -put /opt/module/data/student.txt /user/atguigu/hive; 加载数据覆盖表中已有的数据
hive (hive3)> load data local inpath '/home/atguigu/student.txt' overwrite into table hive3.student;查询覆盖后的信息:
hive (hive3)> select * from student;
OK
student.id student.name
1001 zzz
1002 ddd
1111 ccc
Time taken: 0.747 seconds, Fetched: 3 row(s)2. 通过查询语句向表中插入数据(Insert)
1)创建一张表
hive (default)> create table student_par(id int, name string) row format delimited fields terminated by '';
OK
Time taken: 3.124 seconds2)基本插入数据,插入数据会生成MR任务,这样插入的数据会放在最前面
hive (default)> ?insert into table student_par ?values(1,'wangwu'),(2,'zhaoliu');
Automatically selecting local only mode for query
Query ID = atguigu_20211217144118_3d15bc1c-c822-41f3-a62b-62e1e57fa3a2
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2021-12-17 14:41:21,668 Stage-1 map = 0%, reduce = 0%
2021-12-17 14:41:22,688 Stage-1 map = 100%, reduce = 0%
2021-12-17 14:41:23,694 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1983525660_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop100:8020/user/hive/warehouse/student_par/.hive-staging_hive_2021-12-17_14-41-18_153_8125208710986864882-1/-ext-10000
Loading data to table default.student_par
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 82823431 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
col1 col2
Time taken: 8.727 seconds3)基本模式插入(根据单张表查询结果)
下面将hive3里面的student表的内容overwrite到student_par表格里面
hive (default)> insert overwrite table student_par select id, name from hive3.student;
OK
id name
Time taken: 5.391 seconds
hive (default)> select * from student_par;
OK
student_par.id student_par.name
1001 zzz
1002 ddd
1111 ccc
Time taken: 0.275 seconds, Fetched: 3 row(s)insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
注意:insert 不支持插入部分字段
4)多表(多分区)插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';3. 查询语句中创建表并加载数据(As Select)
详见4.5.1 章创建表。根据查询结果创建表(查询的结果会添加到新创建的表中)
hive (default)> create table if not exists student1 as select id,name from hive3.student;
OK
id name
Time taken: 3.2 seconds
hive (default)> select * from student1;
OK
student1.id student1.name
1001 zzz
1002 ddd
1111 ccc
Time taken: 0.231 seconds, Fetched: 3 row(s)4. 创建表时通过 Location 指定加载数据路径
1)上传数据到 hdfs 上
hive (default)> dfs -mkdir /student;
hive (default)> dfs -put /home/atguigu/student.txt /student;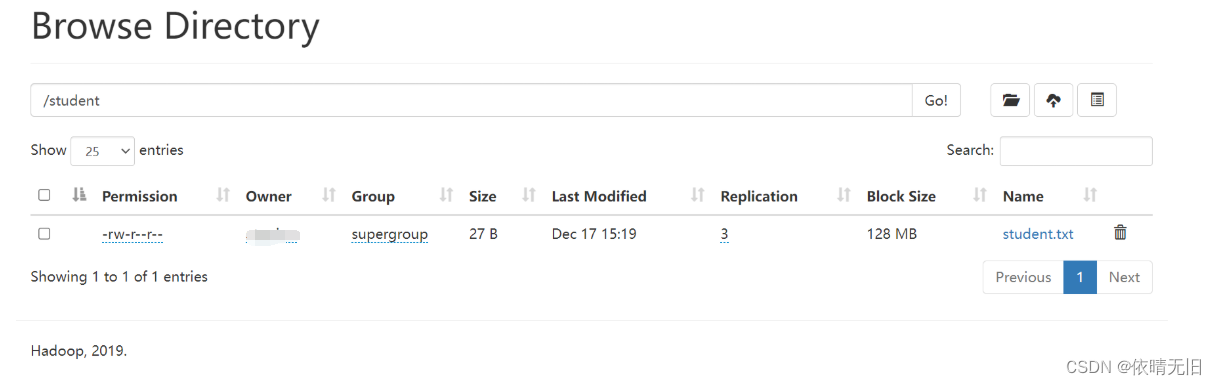
2)创建表,并指定在 hdfs 上的位置(最好使用外部表)
hive (default)> create external table if not exists student5(id int, name string) row format delimited fields terminated by "" location '/student';
OK
Time taken: 0.482 seconds3)查询数据
hive (default)> select * from student5;
OK
student5.id student5.name
1001 zzz
1002 ddd
1111 ccc
Time taken: 0.45 seconds, Fetched: 3 row(s)5. Import 数据到指定 Hive 表中
注意:先用 export 导出后,再将数据导入(不然会报非法路径的错误)。
hive (default)> import table student5 from '/user/hive/warehouse/student/student.txt';
文章来源:https://blog.csdn.net/zuodingquan666/article/details/135543731
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- jQuery选择器(二) 过滤选择器及可见性过滤选择器的使用
- 基于SpringBoot和微信小程序的农场信息管理系统
- 电脑安装 Python提示“api-ms-win-crt-process-l1-1-0.dll文件丢失,程序无法启动”,快速修复方法,完美解决
- 【笔记】Helm-3 主题-2 Chart Hook
- 国科大图像处理2023速通期末——汇总2017-2019
- Windows10下 tensorflow-gpu 配置
- 1.2 虚拟环境
- QT基础篇(7)QT5图形视图框架
- 快快销ShopMatrix 分销商城多端uniapp可编译5端 - 最早推荐的两个会员的团队业绩最小值
- 【UML】第13篇 序列图(2/2)——建模的方法