高级分布式系统-第15讲 分布式机器学习--分布式机器学习算法
高级分布式系统汇总:高级分布式系统目录汇总-CSDN博客
分布式机器学习算法
按照通信步调,大致可以分为同步算法和异步算法两大类。
同步算法下,通信过程中有一个显式的全局同步状态,称之为同步屏障。当工作节点运行到同步屏障 ,就会进入等待状态,直到其工作节点均运行到同步屏障为止。接下来不同工作节点的信息被聚合并分发回来,然后各个工作节点据此开展下一轮的模型训练。
异步算法下,各个工作节点不再需要等待,而是以一个或多个全局服务器为作为中介,实现对全局模型的更新和读取。这样可以显著减少通信时间,从而获得更好的多机扩展性。

同步算法--同步SGD算法(SSGD)
同步算法--同步SGD算法(SSGD)最基础的同步算法,将SGD套用到同步的BSP框架中。
实际上就是将各个工作节点依据本地训练数据所得到的梯度叠加起来,整个过程等价于一个批量大小增加K倍的单机SGD算法。
特点:由于在每一个小批量更新之后都有一个同步过程,通信频率较高。

同步SGD算法优点与缺点
优点:在每个小批量计算的计算量很大,模型规模不大的情况下,可以获得理想的加速性能。
缺点:小批量中样本较少,模型规模较大时,可能会花费数倍于计算时间的代价进行通信。
解决方法:
? 在通信环节加入时空滤波,减少通信量
? 扩大本地学习时的批量大小,拉长本地训练时间
启发:
随着批量大小的增加,随机梯度的方差变小,会降低算法跳出某些局部最优解的可能。
? 当批量大小较大,模型比较容易收敛到优化曲面比较尖锐的局部最优;当批量大小较小时,会收敛到优化曲面
相对平缓的的局部最优点。
? 考虑到小批量中的样本较多时求得的梯度更加准确,我们可以相应地增加习率使得每步更新得更多一些,从而
解决收敛变慢的问题。

同步和异步的融合
同步和异步算法有各自的优缺点和适用场景,如果可以把它们结合起来应用,取长补短,或许可以更好地达到收敛速率与收敛精度的平衡。
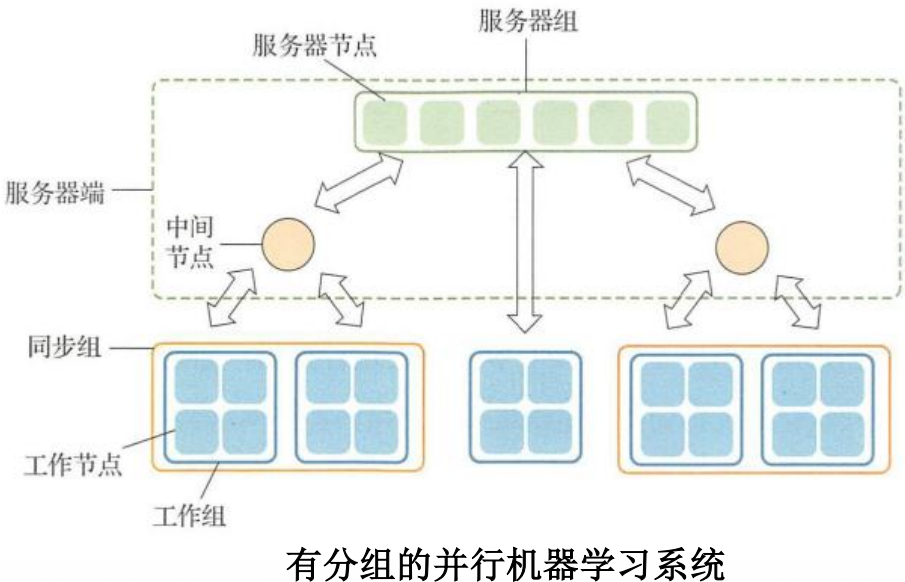
分布式机器学习理论
分布式机器学习的目标:适用大规模计算资源,充分利用大数据来训练数据,从而加速训练速度或者实现训练规模的突破。
? 收敛性:具有良好的收敛性质,能够以可接受的收敛速率收敛到(正则化)经验风险的最优模型;
? 加速比:相比与对应的单机优化算法,达到同样的模型精度所需要的时间明显降低,甚至随着工作节点的增加,需要的时间以线性的阶数减少;
? 泛化性:不出现过拟合现象,不仅训练性能好,测试性能也好。
为了达到更好的加速比,会人为的减少工作节点之间的通信量。
分布式机器学习系统
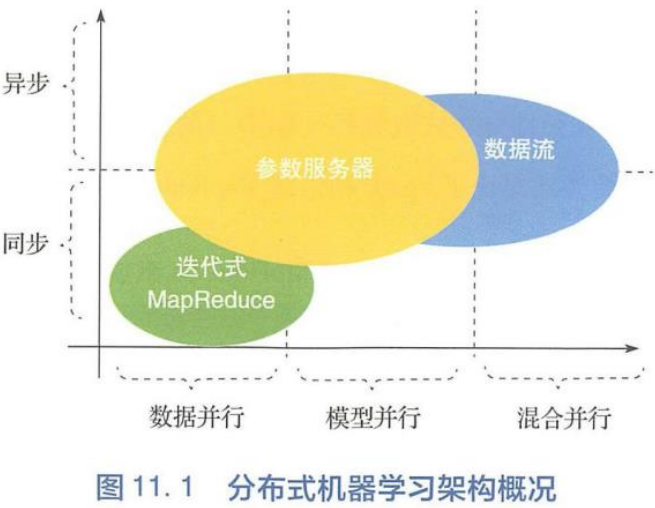
目前使用的分布式机器学习系统大多可以被三种架构所覆盖,可分为三种:基于IMR的系统、基于参数服务器的系统和基于数据流的系统。
基于IMR的系统主要的适用场景是“同步数据并行。它从大数据处理平台演化而来,运行逻辑比较简单。
基于参数服务器的系统可以同时支持同步和异步的并行算法。它的接口简单明了、逻辑清晰,可以很方便、灵活地与单机算法相结合。
基于数据流的系统由一个有向无环图定义,可以灵活地描述复杂地并行模式。
基于参数服务器的系统--Multiverso参数服务器
采用数据表的结构存储参数。依据模型的不同,数据有不同的具体形式:可以是简单向量,也可以是矩阵、张量或哈希表;可以使稠密的形式,也可以稀疏的形式。
Multiverso系统使用消息驱动的服务模式,也就是用一个消息队列接收并保存来向工作节点的请求。服务器端会监听队列中的消息,并按照请求的类别由相应的消息响应函数完成服务。为了提高服务器端处理的效率,Multiverso系统采用线程池对请求并行处理。
Multiverso系统实现同步和异步算法

Multiverso系统的客户端逻辑
包含的功能:用户接口(API),客户端的存储逻辑和客户端的发送逻辑。
? 客户端的存储逻辑
包含两个部分:一是用来存储从参数服务器端获得的全局参数,二是用来保存本地产生的模型。
? 客户端的发送逻辑
在网络传输前对数据进行分包和聚合。在接受参数服务器端传来的最新参数时,客户端也需要将来自不同服务器的信息汇总,然后把信息存储到本地模型容器之中。


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何在ubuntu18.04安装python3.8.6
- 03.jsp复习错题
- Manage Your Package Requests
- MD5算法的简述
- 自动化测试面试题及答案大全(上)
- 自定义shell工具函数之echo_red()和prepare_check_required_pkg()
- XXE漏洞概念
- swift 多线程锁(一) NSLock
- HFish蜜罐搭建及简单使用
- 2024最新ChatGPT网站源码/支持用户付费套餐+赚取收益