【数据结构入门精讲 | 第十一篇】一文讲清树
在上一篇中我们进行了排序算法的专项练习,现在让我们开始树的知识点讲解。

树
树是一种非线性的数据结构,也是一种表示一对多关系的数据结构,它由若干个节点(Node)和连接这些节点的边(Edge)组成。树有很多应用,如用于实现文件系统、数据库索引和编译器等。
下面是树的一些常见概念及其相关知识点:
1.根节点(Root):树的最顶层节点,它没有父节点。
2.叶子节点(Leaf):没有子节点的节点。
3.父节点(Parent):如果一个节点有子节点,则该节点称为其子节点的父节点。
4.子节点(Child):一个节点的直接后继节点称为其子节点。
5.节点的度(Degree):一个节点拥有的子节点数称为其度。
6.树的度(Degree):树中所有节点度的最大值。
7.深度(Depth):根节点到该节点的路径长度。
8.高度(Height):该节点到叶子节点的最长路径长度。
9.子树(Subtree):以一个节点为根节点的子树是由该节点及其所有后代节点组成的树。
10.兄弟节点(Sibling):拥有同一个父节点的节点互为兄弟节点。
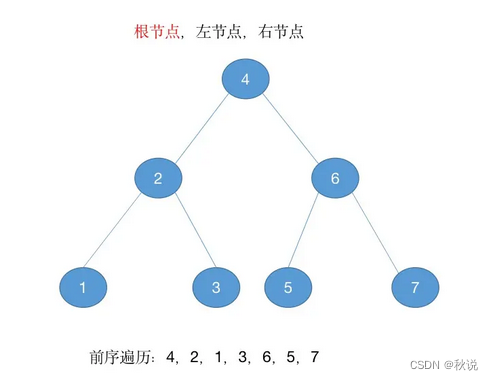
11.前序遍历(Pre-order Traversal):首先访问根节点,然后依次递归遍历左子树和右子树。
可以每个节点的左侧画一个点,然后逆时针画一条线,经过点就输出点对应的节点(推荐)
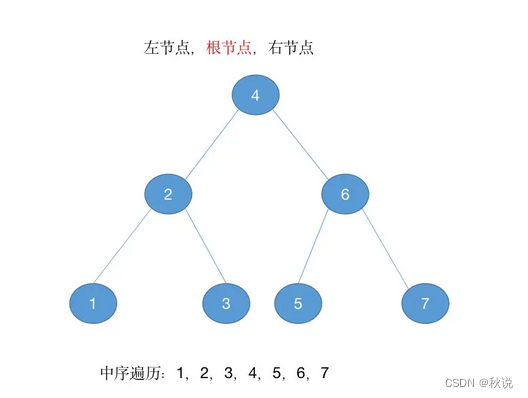
中序遍历(In-order Traversal):先递归遍历左子树,然后访问根节点,最后递归遍历右子树。
可以每个节点的下方画一个点,然后逆时针画一条线,经过点就输出点对应的节点(推荐)
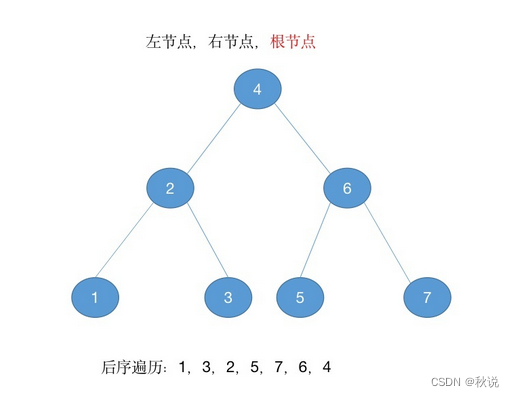
后序遍历(Post-order Traversal):先递归遍历左子树和右子树,然后访问根节点。
可以每个节点的右侧画一个点,然后逆时针画一条线,经过点就输出点对应的节点(推荐)
12.层序遍历(Level-order Traversal):从上到下,从左到右依次访问每一层的所有节点。
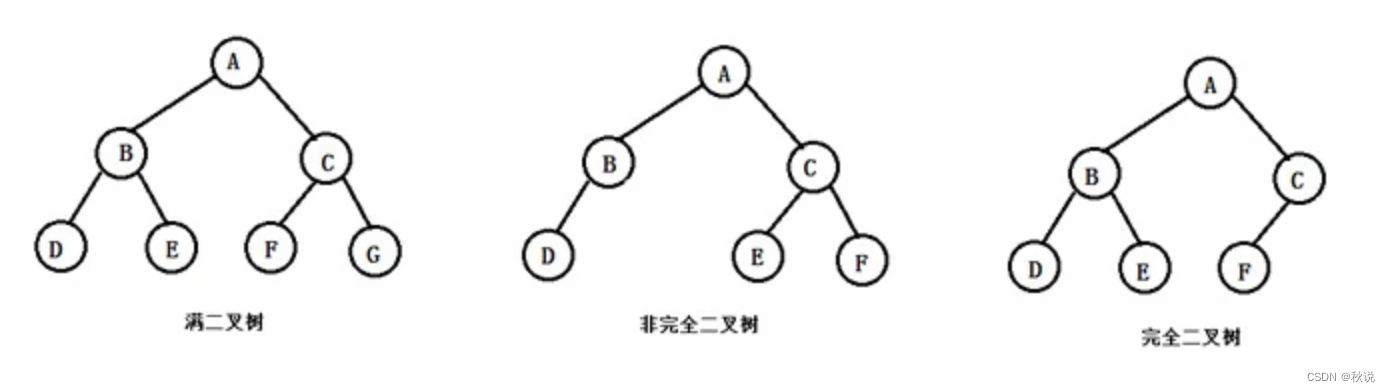
13.二叉树(Binary Tree):每个节点最多只有两个子节点的树。
14.满二叉树(Full Binary Tree):除叶子节点外,每个节点都有两个子节点的二叉树。
15.完全二叉树(Complete Binary Tree):除了最后一层外,其他层的节点数都是满的,最后一层的节点全部靠左排列的二叉树。
16.平衡二叉树(Balanced Binary Tree):左右子树的高度差不超过1的二叉树。
二叉搜索树
二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。
AVL树(平衡二叉树/二叉查找树)
AVL树是一种自平衡的二叉搜索树,它得名于其发明者G. M. Adelson-Velsky和E. M. Landis。AVL树的特点是任何节点的两个子树的高度最多相差1,这使得AVL树在插入和删除节点时能够保持较好的平衡性,从而保证了查找操作的效率。
在AVL树中,每个节点都会存储一个平衡因子,该平衡因子是其左子树的高度与右子树的高度之差。对于任何AVL树中的每个节点,其平衡因子的值只可能是-1、0或1。如果在进行插入或删除操作后,任何节点的平衡因子的绝对值超过1,则需要通过旋转操作来恢复树的平衡。旋转操作主要有以下几种:
- 单右旋(LL旋转):当某个节点的左子树比右子树高2个单位,并且左子树的左子树比左子树的右子树高时进行。
- 单左旋(RR旋转):当某个节点的右子树比左子树高2个单位,并且右子树的右子树比右子树的左子树高时进行。
- 左-右双旋转(LR旋转):当某个节点的左子树比右子树高2个单位,并且左子树的右子树比左子树的左子树高时进行。这个操作是先对问题节点的左子树进行单左旋,然后对问题节点进行单右旋。
- 右-左双旋转(RL旋转):当某个节点的右子树比左子树高2个单位,并且右子树的左子树比右子树的右子树高时进行。这个操作是先对问题节点的右子树进行单右旋,然后对问题节点进行单左旋。
通过这些旋转操作,AVL树在每次插入或删除后都能迅速恢复平衡,从而保证了最坏情况下的操作时间复杂度为O(log n),其中n是树中节点的数量。这使得AVL树在需要频繁插入或删除的场景中表现良好,如数据库索引和内存中的查找表。
性质:任何二叉搜索树中同一层的结点从左到右是有序的(从小到大)。
二叉搜索树每个结点的值均大于其左子树上任一节点的值
二叉搜索树每个结点的值均小于其右子树上任一节点的值
如何构建AVL树呢?
遵循如下原则:
1. 从根节点开始查找插入位置。
2. 如果插入元素小于当前节点值,则在当前节点的左子树中查找插入位置;如果插入元素大于当前节点值,则在当前节点的右子树中查找插入位置。
3. 沿着插入路径更新每个节点的平衡因子,并检查是否需要进行旋转操作来恢复平衡。
比如说有34 23 15 98 115 107
先插入
34
23
15
此时左子树高度为2,右子树高度为0,二者相差超过1
所以把第二个大的(即23)往上提
得到
23
15 34
再加98
得到
23
15 34
98
再加115
得到
23
15 34
98
115
此时高度差又大于1,所以以34 98 115为单元再把第二个大的(即98)往上提
得到
23
15 98
34 115
对于23 98 34又不满足递增序列,因此将第二个大的(即34)作为根节点得到
34
23 98
15 115
加107得到
34
23 98
15 107 115
删除操作
删叶节点之后,再平衡即可
二叉排序树
如何创建二叉排序树
假设
39 11 68 46 75 23 71 8 64 34
先放置39
11比39小,放左边
39
11
68比39大,放右边
39
11 68
46比39大,放39右边,但比68小,放68左边
39
11 69
46
由此最终得到
39
11 68
8 23 46 75
34 71 86
验证:如果排序完的二叉树在中序时是递增的,则说明排序无误
插入一个元素之前需要判断是否存在该元素
比如需要插入23,但23已存在,所以不需要插入23
再比如插入52,还是一样,与根节点做比较
52大于39,放在在39右边;比68小,放在68左边;比46大,放在46右边;比86小,所以是86的左子树
如何删除一个元素
对于删除叶子节点,直接删除就行
对于删除没有左子树的节点,即23,用该节点的右子树的根节点代替
即用34代替23
对于删除没有右子树的节点,用该节点的左子树的根节点代替
对于删除有左右子树的节点,选择它的左子树中最大的或右子树中最小的去替换
哈夫曼树
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
二叉排序树(Binary Search Tree,BST),也称为二叉搜索树或有序二叉树,是一种特殊的二叉树结构。它具有以下性质:
1. 对于二叉排序树的每个节点,其左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。
2. 对于二叉排序树的任意节点,它的左子树和右子树也是二叉排序树。
由于这些性质,二叉排序树可以用于高效地实现查找、插入和删除操作。
对于查找操作,可以按照以下步骤进行:
1. 从根节点开始,比较要查找的值与当前节点的值。
2. 如果要查找的值等于当前节点的值,则查找成功。
3. 如果要查找的值小于当前节点的值,则继续在左子树中查找。
4. 如果要查找的值大于当前节点的值,则继续在右子树中查找。
5. 如果到达叶子节点仍然没有找到,则查找失败。
对于插入操作,可以按照以下步骤进行:
1. 从根节点开始,比较要插入的值与当前节点的值。
2. 如果要插入的值小于当前节点的值,并且当前节点的左子树为空,则将新节点插入为当前节点的左子节点。
3. 如果要插入的值大于当前节点的值,并且当前节点的右子树为空,则将新节点插入为当前节点的右子节点。
4. 如果要插入的值等于当前节点的值,则不进行插入操作(可以根据需求进行处理,如插入重复值的处理)。
5. 如果要插入的值小于当前节点的值,并且当前节点的左子树不为空,则继续在左子树中递归进行插入操作。
6. 如果要插入的值大于当前节点的值,并且当前节点的右子树不为空,则继续在右子树中递归进行插入操作。
对于删除操作,可以按照以下情况进行处理:
1. 如果待删除的节点为叶子节点(没有子节点),则直接删除该节点。
2. 如果待删除的节点只有一个子节点,则将该子节点替代待删除节点的位置。
3. 如果待删除的节点有两个子节点,则找到其右子树中的最小节点(或左子树中的最大节点),将其值赋给待删除节点,然后再递归地删除该最小节点。
比如给定
19 21 2 3 6 7 10 32
求如何构造哈夫曼树
解:
先找最小的两个,即2 3,合并为5
5
2 3
现在序列变为19 21 5 6 7 10 32
再找最小的两个,即5,6,合并为11
11
5 6
2 3
现在序列变为19 21 11 7 10 32
由此不断循环得到
100 第0层
40 60 第1层
19 21 28 32 第2层
11 17 第3层
5 6 7 10 第4层
2 3 第5层
要计算WPL值,只需要将每个叶节点的值乘以层数再相加就行了
(19+21+32)*2+(6+7+10)*4+(2+3)*5=261
哈夫曼编码是什么呢?
左为0.右为1
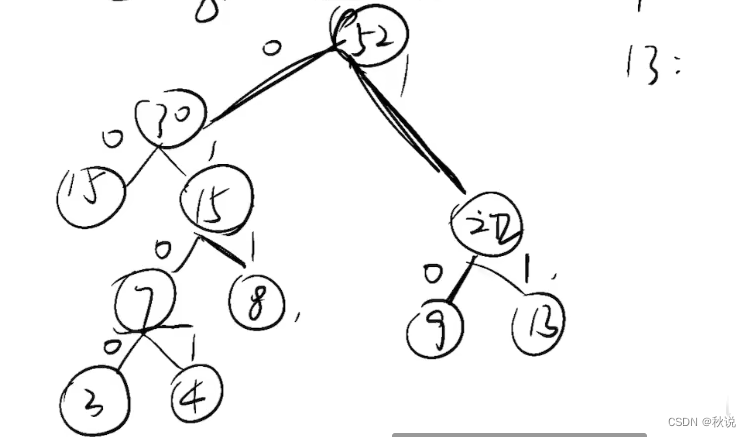
对于9而言,它的哈夫曼编码就是10;对于15而言,它的哈夫曼编码就是01。
哈夫曼树是不唯一的,可能有多种构造形态,但是哈夫曼树的WPL一定是唯一且最小的。
折半查找判定树
如何构建呢?
比如给出3 4 5 7 24 30 42 54 63 72 95
先给他们编号
3 4 5 7 24 30 42 54 63 72 95
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11)
接着将(1+11)/2=6.5-》向下取整为6
将编号为6的30作为根节点
接下来如何找左节点和右节点呢?
对于6的左边
(1+5)/2=3
将编号为3的5作为左节点,同理将编号为9的63作为右节点
得到
30
5 63
同理对5的左边处理,将(1+2)/2=1.5-》1
故将编号为1的3作为5的左节点
同理将(4+5)/2=4.5-》4
故将编号为4的7作为5的右节点
30
5 63
3 7
当3和5之间只有4时,因为4在3的右边,所以将其作为3的右子树
30
5 63
3 7
4
同理24作为7的右子树
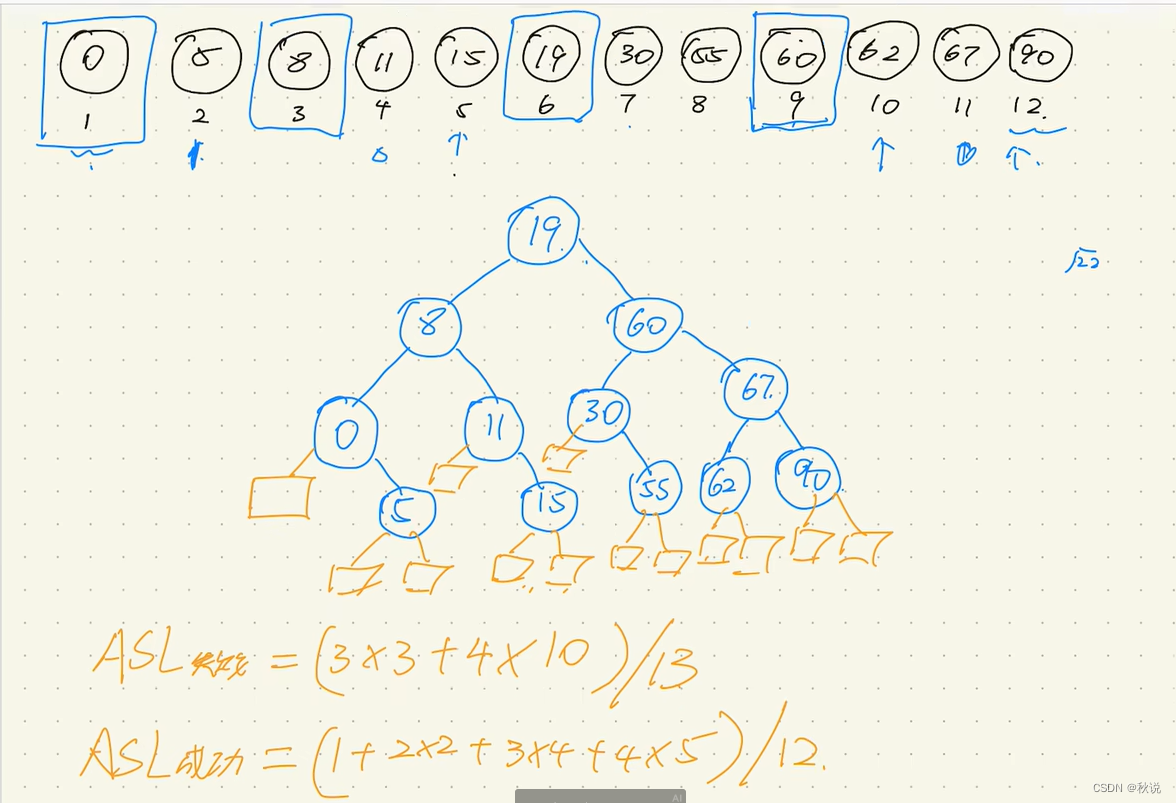
黄色的为失败节点,比如说要查找-1,查找到第三层0的时候,0左边没节点,所以查找不到0。
所以要查找-1,只要查找3次
而查找8,只要查找两次就行
折半查找判定树的判断
-
如果根节点左子树和右子树的节点个数一样,则左子树和右子树的结构一样
所以下图就不是折半查找判定树
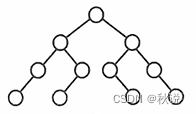
-
如果根节点左边少、右边多(比如1 2 3(根节点) 4 5 6)
则对于任意的根节点,都是左边少右边多
或者根节点左边多右边少:则对于任意的根节点,都是左边多右边少
比如
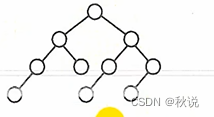
此时根节点左边节点少,右边节点多。对于根节点的左节点,它的左边多右边少,所以这就不是折半查找判定树。
下图的根节点都满足左边多右边少,所以下图是折半查找判定树。
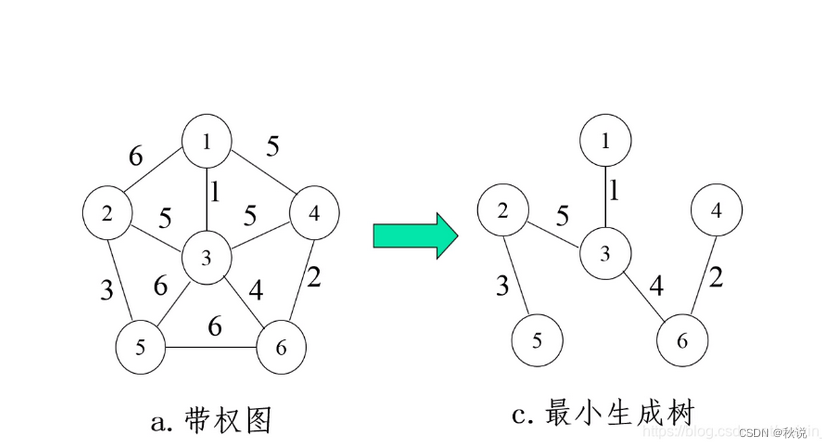
kruskal算法、prim算法、最小生成树
Kruskal算法和Prim算法都是用于求解最小生成树(Minimum Spanning Tree)的经典算法。
1.Kruskal算法:
- Kruskal算法基于贪心策略,按照边的权值从小到大的顺序选择边,并且要求选择的边不形成环路。
- 算法步骤:
- 将图中的所有边按照权值从小到大进行排序。
- 初始化一个空的最小生成树。
- 依次从排好序的边中选取权值最小的边,如果该边的两个端点不在同一个连通分量中,则将该边加入最小生成树中,并将两个端点合并到同一个连通分量中。
- 重复步骤3直到最小生成树中的边数等于总节点数减一,或者所有边都考察完毕。
- 时间复杂度:O(ElogE),其中E是边的数量。
2.Prim算法:
- Prim算法也是一种贪心算法,它从一个初始顶点开始,逐步扩展生成最小生成树的各个部分。每次选择当前最小权值的边,并且使得生成树的顶点集合逐渐增大。
- 算法步骤:
- 随机选择一个顶点作为初始顶点,加入最小生成树中。
- 在所有与最小生成树中的顶点相邻的边中,选择权值最小的边,将其连接的顶点加入最小生成树中。
- 重复步骤2直到最小生成树中的顶点数等于总节点数,或者所有顶点都被考虑完毕。
- 时间复杂度:O(V^2),其中V是顶点的数量。如果使用优先队列来优化选取最小权值边的过程,则时间复杂度可以降低到O((V+E)logV)。
这两种算法都可以用来解决无向连通图的最小生成树问题,但Kruskal算法更适用于稀疏图,而Prim算法更适用于稠密图。在实际应用中,选择合适的算法取决于具体的问题和图的规模。
简要来说
kruskal算法就是将边的权值依次排列
比如
a--b 3
a--c 4
接着按权值由低到高进行连线
但不能形成回路
如果连接该线之后形成回路,则找下一条边
prim算法就是从第一个点开始,找离其最近的点,相连
接着将两个点看作整体,找离该整体最近的点,相连
但不能连成环,如果连成环就找第二近的点
- 最小生成树(Minimum Spanning Tree,简称MST)是在一个连通加权无向图中找到一棵包含图中所有顶点的生成树,使得树的所有边的权值之和最小。
最小生成树具有以下特性:
包含图中的所有顶点。
是一棵树,即没有环路。
权值之和最小。
最小生成树在实际应用中有着广泛的应用,比如在网络设计中用于构建成本最小的通信网络、在电力传输中用于构建最优的输电线路等。
常见的求解最小生成树的算法包括Kruskal算法和Prim算法。这两种算法在前面已经进行了介绍。
最小生成树有可能是不唯一的,但权重和是一样的
完全二叉树
完全二叉树(Complete Binary Tree)是一种特殊的二叉树结构,它除了最后一层外,其他所有层的节点都必须填满,并且最后一层的节点从左到右依次填入,不能有间隔。
完全二叉树具有以下性质:
若完全二叉树的深度为h,则该完全二叉树的节点数目在[2^(h-1),2^h - 1]之间。
对于任意节点i,其左子节点的索引为2i,右子节点的索引为2i+1。
对于任意节点i,如果i > 1,则其父节点的索引为i/2取整。
相比于一般的二叉树,完全二叉树的特殊性在于它的结构更加紧凑。这个特性在某些场景下非常有用,例如构建堆数据结构、优先队列等。
判断一个二叉树是否为完全二叉树可以通过以下方式进行:
层序遍历二叉树,从左到右逐层遍历每个节点。
如果遍历到一个节点为空,则后续遍历的节点都应为空。
如果遍历到一个节点不为空,但其左子节点为空或右子节点为空,则该树不是完全二叉树。
以上就是树的全部知识点,下一篇文章中我们将进行树的专项练习。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 目标检测--02(Two Stage目标检测算法1)
- 分布式之任务调度学习一
- Oracle Vagrant Box 无法登录的2个问题
- 关于java的封装
- 2024全新开发API接口调用管理系统网站源码 附教程
- 酒类销售新模式:用户裂变,利润倍增的秘诀
- 16. 最接近的三数之和
- react-native 配置@符号绝对路径配置和绝对路径没有提示的问题
- 2024年pmp的考试时间是什么时候?
- 2024黑龙江省职业院校技能大赛暨国赛选拔赛应用软件系统开发赛项(高职组)赛题第3套