C++代码入门03 字符串

图源:文心一言
上机题目练习整理,本篇作为字符串的代码补充,提供了2种解法以及函数的详细解释,供小伙伴们参考~🥝🥝
- 第1版:在力扣新手村刷题的记录~🧩🧩
- 方法一:常规暴力解,采用两次循环的解法~
- 方法二:文心一言老师 提供的建议,两轮遍历的解法~
编辑:梅头脑🌸
审核:文心一言
题目:1422. 分割字符串的最大得分 - 力扣(LeetCode)
📇目录
🧵分割字符串的最大得分
🧩题目
给你一个由若干 0 和 1 组成的字符串?
s?,请你计算并返回将该字符串分割成两个?非空?子字符串(即?左?子字符串和?右?子字符串)所能获得的最大得分。「分割字符串的得分」为?左?子字符串中?0?的数量加上?右?子字符串中?1?的数量。
示例 1:
输入:s = "011101" 输出:5 解释: 将字符串 s 划分为两个非空子字符串的可行方案有: 左子字符串 = "0" 且 右子字符串 = "11101",得分 = 1 + 4 = 5 左子字符串 = "01" 且 右子字符串 = "1101",得分 = 1 + 3 = 4 左子字符串 = "011" 且 右子字符串 = "101",得分 = 1 + 2 = 3 左子字符串 = "0111" 且 右子字符串 = "01",得分 = 1 + 1 = 2 左子字符串 = "01110" 且 右子字符串 = "1",得分 = 2 + 1 = 3示例 2:
输入:s = "00111" 输出:5 解释:当 左子字符串 = "00" 且 右子字符串 = "111" 时,我们得到最大得分 = 2 + 3 = 5示例 3:
输入:s = "1111" 输出:3提示:
2 <= s.length <= 500- 字符串?
s?仅由字符?'0'?和?'1'?组成。
🌰方法一:两次for循环
📇算法思路
- 算法思想:使用两次for循环,
- 外循环 i 用于寻找分割点,将数组分为两部分[0, i-1],[i , n-1];
- 内循环 j 用于分别统计两个部分的得分,如果左侧遍历到字符0,右侧遍历到字符1,则增加得分值;
- 时间复杂度:O(n^2)。
- 空间复杂度:O(1)。
??算法代码1
class Solution {
public:
int maxScore(string s) {
int score = 0;
int left = 0;
int right = 0;
int len = s.length();
for (int i = 1; i < len; i++) { // 注意,此处是从第1位开始分割
for (int j = 0; j < i; j++) // 左侧累加积分
if (s.at(j) == '0')
left++;
for (int j = i; j < len; j++) // 右侧累加积分
if (s.at(j) == '1')
right++;
if (score < left + right) // 更新最大值
score = left + right;
left = 0;
right = 0;
}
return score;
}
};??算法代码2
class Solution {
public:
int maxScore(string s) {
int ans = 0;
int n = s.size();
for (int i = 1; i < n; i++) {
int score = 0;
for (int j = 0; j < i; j++) {
if (s[j] == '0') {
score++;
}
}
for (int j = i; j < n; j++) {
if (s[j] == '1') {
score++;
}
}
ans = max(ans, score);
}
return ans;
}
};作者:力扣官方题解
链接:https://leetcode.cn/problems/maximum-score-after-splitting-a-string/solutions/1743691/fen-ge-zi-fu-chuan-de-zui-da-de-fen-by-l-7u5p/
?备注:算法代码1与2在思路上几乎没有区别,只是语法的细节有些不同,以下详细解释。
??函数解释
C++ 统计字符串的长度
- 在C++中,统计字符串的长度通常使用
std::string类的length()或size()成员函数。这两个函数返回字符串中的字符数(不包括终止的空字符)。#include <iostream> #include <string> int main() { std::string str = "Hello, World!"; std::cout << "字符串长度为: " << str.length() << std::endl; std::cout << "字符串长度也可通过size()获取: " << str.size() << std::endl; return 0; }如果使用的是C风格的字符串(即字符数组以空字符
\0结尾),则可以使用strlen()函数从<cstring>库中来获取字符串长度。#include <iostream> #include <cstring> int main() { char str[] = "Hello, World!"; std::cout << "字符串长度为: " << strlen(str) << std::endl; return 0; }注意:
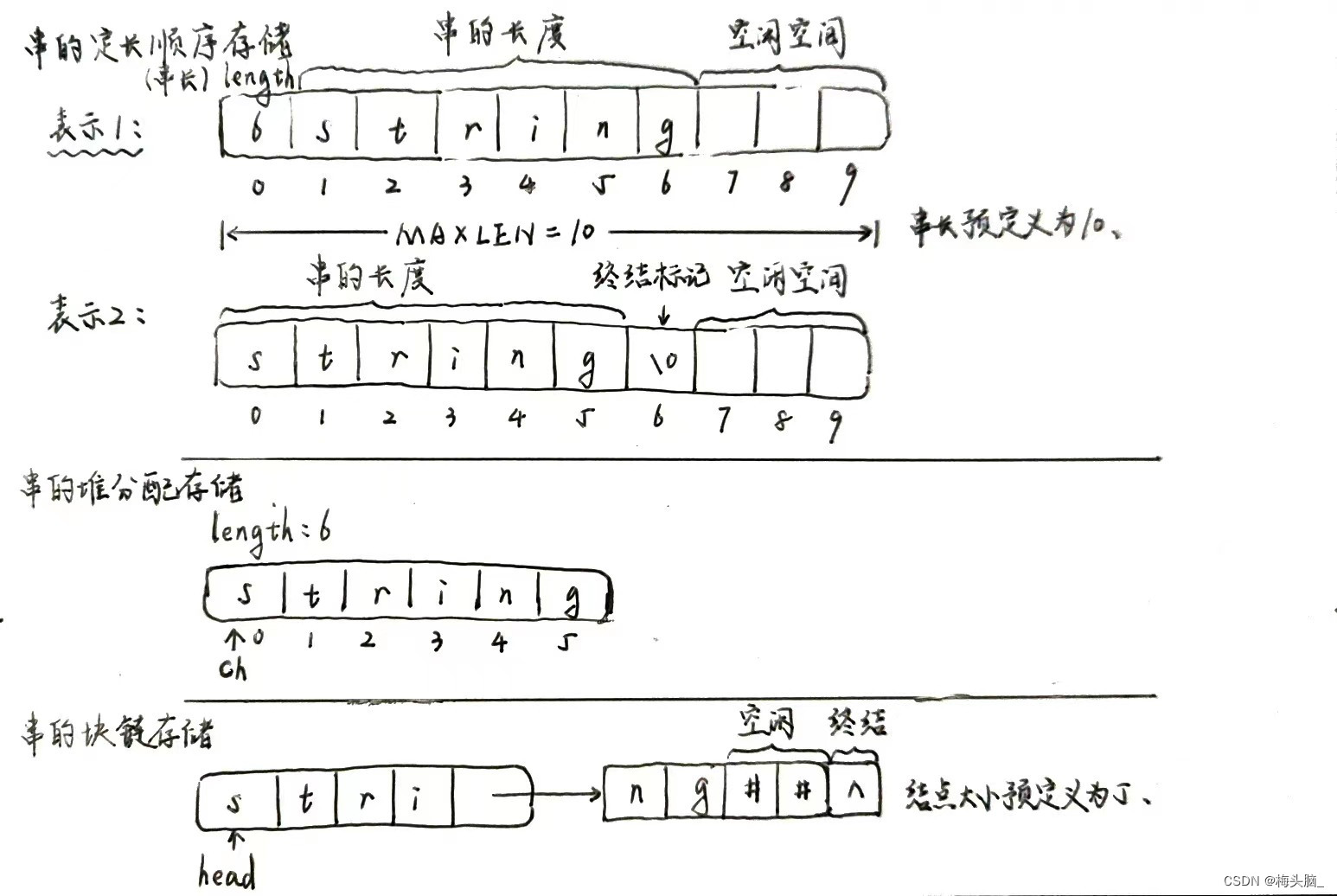
strlen()不会计算终止的空字符。同时,请确保在使用strlen()时,传递给它的确实是一个以空字符结尾的有效C风格字符串,否则可能会导致未定义行为。话说,字符串的存储我以前画过,可以参考下文↓
- 在C语言中,字符串通常是以字符数组的形式存储的,并且以空字符('\0')作为结束标记。这种存储方式被称为C风格的字符串。C风格的字符串是定长的,需要预先分配足够的内存空间来存储整个字符串,包括结束标记。
- 而在C++中,字符串可以使用标准库中的
std::string类来表示和存储。std::string类提供了更多的功能和灵活性,例如自动管理内存、支持字符串的拼接和修改等。C++风格的字符串存储不再依赖于结束标记,而是使用内部的数据结构来记录字符串的长度和内容。原文:🌸数据结构04:串的存储结构与KMP算法_串的三种存储方式-CSDN博客
C++ 查看单个字符
在C++中,要查看
std::string中的单个字符,可以使用数组索引操作符([])或at()成员函数。这两种方法都可以用来访问字符串中特定位置的字符。使用数组索引操作符的示例:
#include <iostream> #include <string> int main() { std::string str = "Hello, World!"; char ch = str[4]; // 访问字符串中索引为4的字符(从0开始计数) std::cout << "第5个字符是: " << ch << std::endl; // 输出:第5个字符是: o return 0; }使用
at()成员函数的示例:#include <iostream> #include <string> int main() { std::string str = "Hello, World!"; char ch; try { ch = str.at(4); // 访问字符串中索引为4的字符(从0开始计数) std::cout << "第5个字符是: " << ch << std::endl; // 输出:第5个字符是: o } catch (const std::out_of_range& e) { std::cerr << "访问越界: " << e.what() << std::endl; } return 0; }注意:
at()函数会进行边界检查,如果索引越界,它会抛出一个std::out_of_range异常。而使用数组索引操作符[]则不会进行边界检查,如果索引越界,行为是未定义的(通常会导致程序崩溃或产生不可预测的结果)。- 在实际编程中,如果你确定索引是有效的,可以使用数组索引操作符以获得更好的性能。如果你不确定索引是否有效,或者想要更安全地访问字符,应该使用
at()函数并进行异常处理。
🌰方法二:两次遍历
📇算法思路
- 算法思想:考虑到提示,字符串只由“0”与“1”组成
- 第一遍遍历:先计算“1”的数量
- 第二遍遍历:从头开始划分数组,如果遍历到0,那么左侧得分+1,如果遍历到1,那么右侧得分-1。左侧得分+右侧得分>=现有最高得分时,更新最高得分;
- 时间复杂度:O(n)。
- 空间复杂度:O(1)。
??算法代码1
class Solution {
public:
int maxScore(string s) {
int maxScore = 0;
int leftZeros = 0; // 左子字符串中0的数量
int totalOnes = 0; // 整个字符串中1的总数
// 预先计算整个字符串中1的数量
for (char c : s) {
if (c == '1') {
totalOnes++;
}
}
int rightOnes = totalOnes; // 初始化右子字符串中1的数量为总数
for (size_t i = 0; i < s.size() - 1; ++i) { // 遍历到倒数第二个字符,保证右子字符串非空
if (s[i] == '0') {
leftZeros++; // 更新左子字符串中0的数量
} else {
rightOnes--; // 更新右子字符串中1的数量
}
// 计算当前得分并更新最大得分
int score = leftZeros + rightOnes;
maxScore = max(maxScore, score);
}
return maxScore;
}
};??算法代码2
class Solution {
public:
int maxScore(string s) {
int maxScore = 0;
int leftZeros = 0; // 左子字符串中0的数量
int rightOnes = accumulate(s.begin(), s.end(), 0, [](int sum, char c) { return sum + (c == '1'); }); // 字符串中1的总数
// 遍历字符串,找到分割点
for (size_t i = 0; i < s.size() - 1; ++i) { // 注意这里是s.size() - 1,因为要保证右子字符串非空
if (s[i] == '0') {
leftZeros++; // 遇到0,左子字符串0的数量增加
} else {
rightOnes--; // 遇到1,右子字符串1的数量减少
}
// 更新最大得分
maxScore = max(maxScore, leftZeros + rightOnes);
}
return maxScore;
}
};??函数解释
算法代码1:for (char c : s)?
基于范围的for循环(Range-based for loop),是C++11中引入的一种新特性,它允许我们更简洁、更直观地遍历容器(如数组、字符串、向量等)中的元素。
这种循环的基本语法如下:
for (element_type value : container) { // 循环体 }
element_type?是容器中元素的类型,value?是我们为每个元素定义的临时变量名,container?是要遍历的容器。对这个感兴趣可以参考🌸数据结构04附录01:字符串大写转小写[C++]-CSDN博客
算法代码2:accumulate
accumulate?是 C++ 标准库?<numeric>?中的一个算法函数,用于计算一个序列中所有元素的累积和(或其他通过二元操作符定义的累积结果)。函数原型如下:
template<class InputIt, class T> T accumulate(InputIt first, InputIt last, T init); template<class InputIt, class T, class BinaryOperation> T accumulate(InputIt first, InputIt last, T init, BinaryOperation op);其中:
first?和?last?是输入迭代器,指定了要处理的元素范围。init?是累积结果的初始值。op?是一个二元操作符,用于定义如何累积元素。如果不提供?op,则默认使用加法。函数的行为是:从?
first?开始,逐个遍历到?last(不包括?last),将每个元素与当前的累积结果通过?op?进行操作,并将结果作为下一次累积的起始值。最终返回累积结果。下面是一个简单的例子,演示了如何使用?
accumulate?计算一个整数数组中所有元素的和:#include <iostream> #include <numeric> #include <vector> int main() { std::vector<int> nums = {1, 2, 3, 4, 5}; int sum = std::accumulate(nums.begin(), nums.end(), 0); std::cout << "Sum: " << sum << std::endl; // 输出:Sum: 15 return 0; }在这个例子中,
accumulate?会依次将?0(初始值)、1、2、3、4?和?5?相加,最终返回它们的和?15。你还可以提供自定义的二元操作符来改变累积的方式。例如,下面的代码使用?
accumulate?来计算一个整数数组中所有元素的乘积:#include <iostream> #include <numeric> #include <vector> int main() { std::vector<int> nums = {1, 2, 3, 4, 5}; int product = std::accumulate(nums.begin(), nums.end(), 1, std::multiplies<int>()); std::cout << "Product: " << product << std::endl; // 输出:Product: 120 return 0; }在这个例子中,
std::multiplies<int>()?产生了一个函数对象,该对象用于将两个整数相乘。因此,accumulate?会依次将?1(初始值)、1、2、3、4?和?5?相乘,最终返回它们的乘积?120。
One more thing
还有两个优秀大佬的代码仅做展示,他们的语法非常华丽,但是我可能作为1个连算法思想都木得有的人,暂时也想不到这种深度。都是学C++的,为什么他们的代码这么秀?
小彩蛋:
话说,一言博文审核到这里甚至还安慰了一下博主,顺便帮我把算法代码3和4的解释补全了(原来是空着的),虽然他对代码的解释我也不甚能看得懂,有点“这是我的母语吗”感觉?
不过还是要感谢一言~~

??算法代码3
class Solution {
public:
int maxScore(string s) {
int cnt = count(s.begin(), s.end(), '1'), ans = 0;
for_each(s.begin(), s.end() - 1, [&](char c){ans = max(ans, cnt += (c == '0' ? 1 : -1));});
return ans;
}
};这段代码使用了C++的
count函数来计算字符串s中'1'的初始数量,并将其存储在cnt中。然后,它使用for_each算法和lambda表达式来遍历字符串(除了最后一个字符,因为要保证右侧子字符串非空)。对于每个字符,如果它是'0',则cnt增加1(因为左侧得分增加),如果是'1',则cnt减少1(因为右侧得分减少)。在每次更新cnt后,它都会检查当前得分ans是否需要更新为新的最大值。这里的关键是理解lambda表达式
[&](char c){ans = max(ans, cnt += (c == '0' ? 1 : -1));}的工作方式。这个表达式捕获了ans和cnt的引用,并对字符串s中的每个字符c执行以下操作:如果c是'0',则cnt加1;如果c是'1',则cnt减1。然后,它比较ans和更新后的cnt,并将ans设置为两者中的较大值。
??算法代码4
class Solution {
public:
int maxScore(string s) {
auto f = [](char c) { return c == '0' ? 1 : -1; };
int cnt = count(s.cbegin(), s.cend(), '1') + f(s[0]);
return accumulate(s.cbegin() + 1, s.cend() - 1, cnt, [&cnt, f](int v, char c) { return max(v, cnt += f(c)); });
}
};这段代码首先定义了一个lambda函数
f,它接受一个字符c并返回1(如果c是'0')或-1(如果c是'1')。这个函数用于计算左侧得分(遇到'0')和右侧得分(遇到'1')的变化。接下来,代码计算字符串
s中'1'的总数,并加上第一个字符通过f函数计算得到的值(如果是'0'则为1,否则为-1)。这是因为我们在计算得分时需要考虑第一个字符对左侧得分的影响。然后,代码使用
accumulate函数来遍历字符串s(从第二个字符开始,到倒数第二个字符结束)。在这个过程中,它使用一个lambda表达式来更新cnt,并返回当前的最大得分。这个lambda表达式捕获了cnt的引用,并使用f函数来计算每个字符对得分的贡献。最终,
accumulate函数返回的是遍历过程中计算得到的最大得分,这个得分就是我们要找的答案。
🔚结语
博文到此结束,写得模糊或者有误之处,欢迎小伙伴留言讨论与批评,督促博主优化内容{例如有错误、难理解、不简洁、缺功能}等,博主会顶锅前来修改~~😶?🌫?😶?🌫?
我是梅头脑,本片博文若有帮助,欢迎小伙伴动动可爱的小手默默给个赞支持一下,感谢点赞小伙伴对于博主的支持~~🌟🌟
同系列的博文:🌸数据结构_梅头脑_的博客-CSDN博客
同博主的博文:🌸随笔03 笔记整理-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 阶段五接口测试第四章接口测试框架开发
- 2024“华数杯”国际大学生数学建模竞赛建模解析,小鹿学长带队指引全代码文章与思路
- 铁路轨道交通智慧(JSP+java+springmvc+mysql+MyBatis)
- 深入理解归并排序与逆序对计算---剑指offer-JZ51 数组中的逆序对
- Verilog 仿真激励
- LCR 145. 判断对称二叉树
- 什么是短视频矩阵系统?效果是怎么样的?
- Unity--自动版面(Layout Element)||Unity--自动版面(Content Size Fitter)
- 如何解决csgo搬砖饰品买了跌价的问题
- 169. 多数元素