深度学习基础知识整理
自动编码器
Auto-encoders是一种人工神经网络,用于学习未标记数据的有效编码。它由两个部分组成:编码器和解码器。编码器将输入数据转换为一种更紧凑的表示形式,而解码器则将该表示形式转换回原始数据。这种方法可以用于降维,去噪,特征提取和生成模型。
自编码器的训练过程是无监督的,因为它不需要标记数据。它的目标是最小化重构误差,即输入数据与解码器输出之间的差异。这可以通过反向传播算法和梯度下降等优化方法来实现。
自编码器有多种变体,包括稀疏自编码器,去噪自编码器,变分自编码器等。这些变体旨在强制学习到的表示具有某些有用的属性,例如稀疏性或噪声鲁棒性。
自动编码器作为一种前馈神经网络,由编码器和解码器两个阶段组成。编码器获取输入x,并通过如下非线性映射将其转换为隐藏表示
h
=
φ
(
W
x
+
b
)
h=φ(Wx+b)
h=φ(Wx+b)
其中φ是非线性激活函数,然后解码器通过如下方法将隐藏表示映射回原始表示
z
=
φ
(
W
′
h
+
b
′
)
z=φ(W'h+b')
z=φ(W′h+b′)
对包括θ=[W,b,W′,b′]在内的模型参数进行优化,以最小化
z
=
f
θ
(
x
)
z=f_{θ}(x)
z=fθ?(x)和x之间的重建误差。N个数据样本集合上平均重建误差的一个常用度量是平方误差,相应的优化问题可以写成
m
i
n
θ
1
N
∑
i
N
(
x
i
?
f
θ
(
x
i
)
)
2
min_θ \frac{1}{N} \sum^{N}_{i}(x_i - f_θ(x_i))^2
minθ?N1?i∑N?(xi??fθ?(xi?))2
其中
x
i
x_i
xi?是第i个样本。这清楚地表明,AE可以以无监督的方式进行训练。隐藏表示h可以被视为数据样本x的一种更抽象、更有意义的表示。通常,隐藏大小应该设置为大于AE中的输入大小,这是经过经验验证的。
稀疏自编码器
在自编码器中,稀疏性是指编码器的输出中只有少量的非零元素。这可以通过向损失函数添加一个惩罚项来实现,以鼓励编码器生成更少的非零元素。这个惩罚项通常是L1正则化项,它是编码器输出向量中所有元素的绝对值之和。这个技巧被称为“稀疏自编码器”。 稀疏自编码器的目标是学习到一组稀疏的特征,这些特征可以更好地表示输入数据。这种方法可以用于特征提取和降维。相应的优化函数更新为
m
i
n
θ
1
N
∑
i
N
(
x
i
?
f
θ
(
x
i
)
)
2
+
∑
j
m
K
L
(
p
∣
∣
p
j
)
min_θ \frac{1}{N} \sum^{N}_{i}(x_i - f_θ(x_i))^2+\sum_{j}^{m}KL(p||p_j)
minθ?N1?i∑N?(xi??fθ?(xi?))2+j∑m?KL(p∣∣pj?)
其中m为隐藏层大小,第二项是隐藏单元上KL发散的总和。第j个隐藏神经元上的KL散度为
K
L
(
p
∣
∣
p
j
)
=
p
l
o
g
(
p
p
j
)
+
(
1
?
p
)
l
o
g
(
1
?
p
1
?
p
j
)
KL(p||p_j)=plog(\frac{p}{p_j})+(1-p)log(\frac{1-p}{1-p_j})
KL(p∣∣pj?)=plog(pj?p?)+(1?p)log(1?pj?1?p?)
其中p为预定义的平均激活目标,
p
j
p_j
pj?是整个数据集上第j个隐藏神经元的平均激活。
Addition of Denoising
在自编码器中,去噪是指通过自动编码器去除输入数据中的噪声。这可以通过向损失函数添加一个惩罚项来实现,以鼓励编码器生成更少的非零元素。这个惩罚项通常是L1正则化项,它是编码器输出向量中所有元素的绝对值之和。这个技巧被称为“去噪自编码器”。
去噪自编码器的目标是学习到一组稀疏的特征,这些特征可以更好地表示输入数据。这种方法可以用于特征提取和降维。
Stacking Structure
几个降噪自编码器可以堆叠在一起形成深度网络,通过将第l层输出作为输入提供给第(l+1)层来学习高级表示,训练是贪婪地一层一层完成的。
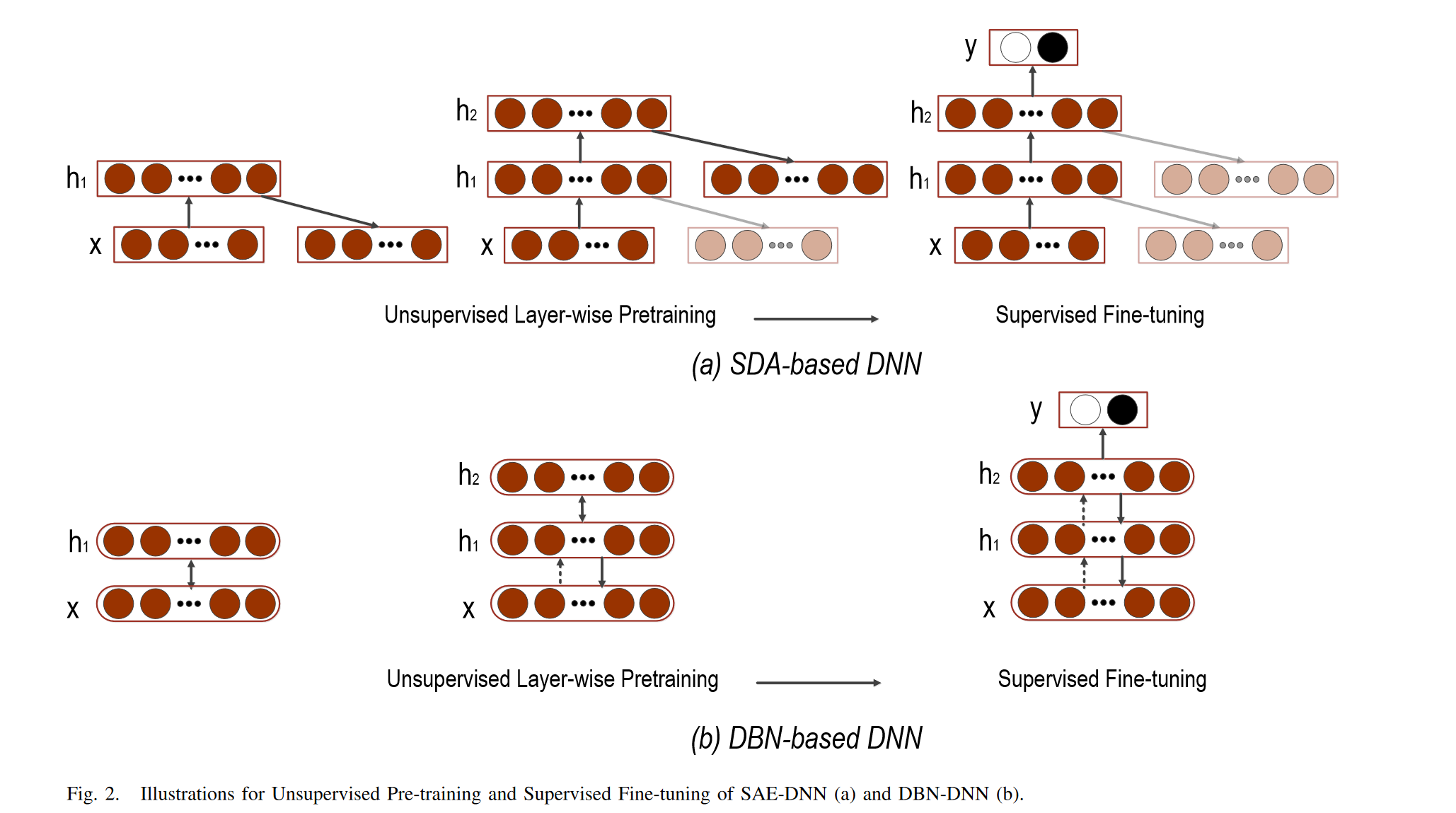
由于自动编码器可以以无监督的方式进行训练,因此自动编码器,特别是堆叠去噪自动编码器(SDA),可以通过初始化深度神经网络(DNN)的权重来训练模型,从而提供有效的预训练解决方案。在SDA的逐层预训练之后,可以将自动编码器的参数设置为DNN的所有隐藏层的初始化。然后,执行有监督的微调以最小化标记的训练数据上的预测误差。通常,在网络顶部添加一个softmax/回归层,以将AE中最后一层的输出映射到目标。与任意随机初始化相比,基于SDA的预训练协议可以使DNN模型具有更好的收敛能力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- android 13.0 Hotseat 添加allapp button功能实现
- 微信小程序封装vant 下拉框select 单选组件
- springboot集成swagger
- Python数据科学视频讲解:Python数据读取、合并、写入
- 智慧营业厅AI智能视频监控预警系统-商超类连锁店监控解决方案---豌豆云
- concrt140.dll丢失修复方法分享,concrt140.dll下载方法修复教程
- GAMES101-LAB1
- IPv6静态路由
- 高精度算法--大数加法
- 3.RHCSA脚本配置及通过node2改密码