Keras多分类鸢尾花DEMO
完整的一个小demo:
pandas==1.2.4
numpy==1.19.2
python==3.9.2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import DataFrame
from scipy.io import loadmat
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from sklearn import preprocessing
from sklearn.datasets import load_iris
# 映射函数iris_type: 将string的label映射至数字label
import os
# data.to_csv('data.csv',index=False) #cvs保存文件不会保存index列
# data = pd.read_csv('data.csv',index_col=0) #读取csv文件的时候选择不读取第一列信息
def downLoad():
path="../httdemo/"
iris = load_iris()
data = iris.data #获取特征数据
target = iris.target#获取目标数据
data_information = DataFrame(data, columns=['bcalyx', 'scalyx', 'length', 'width']) #重新定义特征数据的列名
data_target = DataFrame(target, columns=['target'])#目标数据列名target
data_csv = pd.concat([data_information, data_target], axis=1) #合并特征数据和目标数据到一个DataFrame
if not os.path.exists(path):#把DataFrame数据保存到本地,以.CVS的格式保存
os.makedirs(path)
filename = path + 'iris.csv' #定义保存路径
data_csv.to_csv(filename,index=False) #index==False表示,序号下表列不做保存
# 本地数据保存为excel文件
# outputfile = "iris.xls" # 保存文件路径名
# column = list(data['feature_names'])
# dd = pd.DataFrame(data.data, index=range(150), columns=column)
# dt = pd.DataFrame(data.target, index=range(150), columns=['outcome'])
# jj = dd.join(dt, how='outer') # 用到DataFrame的合并方法,将data.data数据与data.target数据合并
# jj.to_excel(outputfile) # 将数据保存到outputfile文件中
def readData(path):
Data = pd.read_csv(path,names=['bcalyx', 'scalyx', 'length', 'width','target']) #读取本地保存的CVS数据
Data.head(10)#展示前10
# 变量初始化
# 最后一列为y,其余为x
cols = Data.shape[1] # 获取列数 shape[0]行数 [1]列数
X = Data.iloc[1:, 0:cols - 1].astype(float) # 获取得到特征数据,转换为Float的格式,如果输入str,会报错的,取前cols-1列,即输入向量
y = Data.iloc[1:, cols - 1:cols] # 取最后一列,即目标变量
X = np.array(X)
y = np.array(y)
print(y)
return X,y
def startM():
path = "../httdemo/iris.csv"
X,y=readData(path) #加载数据
from sklearn.preprocessing import OneHotEncoder
# 创建独热编码器对象
encoder = OneHotEncoder() #sklearn创建热编码器对象
# 训练独热编码器 (将目标数据进行训练)
encoder.fit(y)
# 转换特征向量 (将目标数据y转换为特征向量[[0,0,1][0,1,0][0,0,1]])格式
encoded_data = encoder.transform(y).toarray()
# shuffle = True 随机打乱后再进行分割数据
X_train, X_test, y_train, y_test = train_test_split(X, encoded_data, test_size=0.3,shuffle=True)
#构建网络模型
model = Sequential()
model.add(Dense(units=1024, activation='relu', input_dim=4)) # 输入层,1024个激活单元,激活函数为relu,输入数据维度为(4,)
model.add(Dense(units=512, activation='relu')) # 隐藏层,512个激活单元,激活函数为relu
model.add(Dense(units=256, activation='relu')) # 隐藏层,256个激活单元,激活函数为relu
model.add(Dropout(0.1)) #丢到10%的数据
model.add(Dense(units=3, activation='softmax')) # 输出层,3个输出单元,激活函数为softmax)
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
#开始训练
model.fit(X_train, y_train, batch_size=30, epochs=32)
#预测测试集的结果
result = model.predict(X_test)
yTest=np.round(result, 2)#保留俩位小数
print(yTest)
#测试机准确率评估
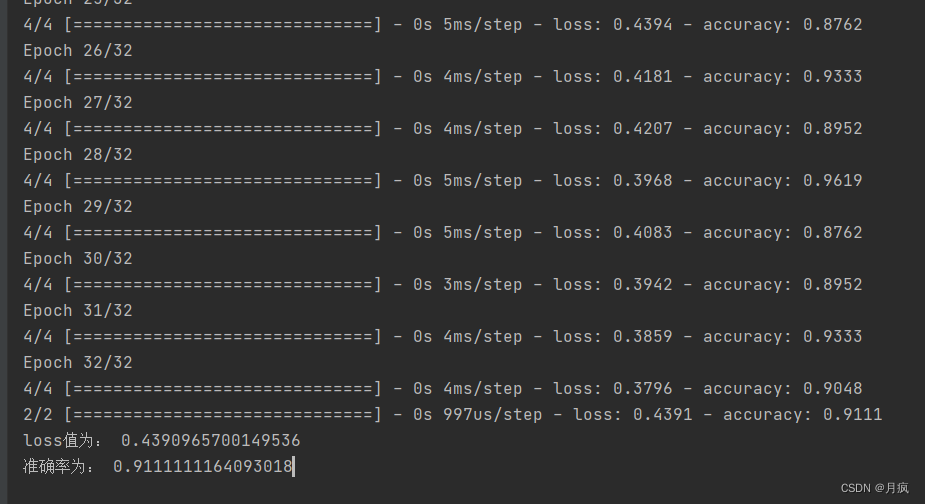
score = model.evaluate(X_test, y_test)
print('loss值为:', score[0])
print('准确率为:', score[1])
if __name__=='__main__':
startM()
# downLoad()
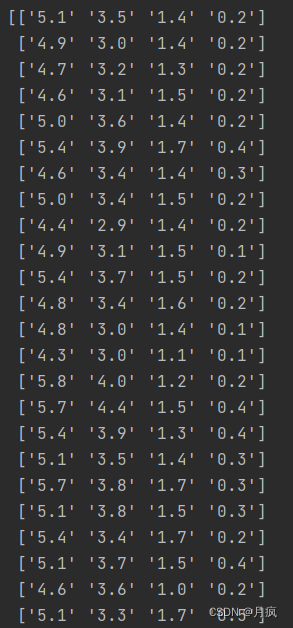
?
特征数据是str,需要转换成float?
X = Data.iloc[1:, 0:cols - 1].astype(float)
?
target的数据打印:

热编码转换之后的数据:

测试集预测结果:表示的位概率值,那个数值比较大,就是哪一个类别,每一个数组表示A,B,C
[[0.01 0.28 0.71]
?[0.91 0.06 0.03]
?[0.01 0.28 0.71]
?[0.02 0.33 0.66]
?[0.01 0.28 0.71]
?[0.06 0.51 0.44]
?[0.92 0.05 0.02]
?[0.04 0.43 0.53]
?[0.02 0.38 0.6 ]
?[0.01 0.31 0.67]
?[0.03 0.42 0.55]
?[0.01 0.24 0.76]
?[0.01 0.32 0.67]
?[0.06 0.49 0.45]
?[0.01 0.25 0.74]
?[0.01 0.31 0.68]
?[0.08 0.51 0.42]
?[0.92 0.06 0.02]
?[0.88 0.09 0.04]
?[0.02 0.33 0.65]
?[0.01 0.29 0.7 ]
?[0.01 0.28 0.71]
?[0.04 0.47 0.49]
?[0.9 ?0.07 0.03]
?[0.91 0.06 0.03]
?[0.86 0.1 ?0.04]
?[0.18 0.5 ?0.31]
?[0.89 0.08 0.03]
?[0.91 0.07 0.03]
?[0.06 0.47 0.48]
?[0.02 0.37 0.61]
?[0.04 0.39 0.57]
?[0.87 0.09 0.04]
?[0.05 0.46 0.49]
?[0.01 0.27 0.72]
?[0.02 0.34 0.64]
?[0.05 0.45 0.5 ]
?[0.92 0.06 0.02]
?[0.09 0.53 0.38]
?[0.04 0.48 0.48]
?[0.95 0.04 0.02]
?[0.01 0.26 0.73]
?[0. ? 0.24 0.76]
?[0.78 0.15 0.07]
?[0. ? 0.21 0.79]]
运行结果:
训练完成之后保存模型,然后测试模型:
 ?
?
读取模型,开始预测:
from tensorflow.keras.models import load_model
import numpy as np
# 模型的导入
model = load_model('../httdemo/httmodel.h5')
# 对数据的预测输入分别为[花萼长,花萼宽,花瓣长,花瓣宽]
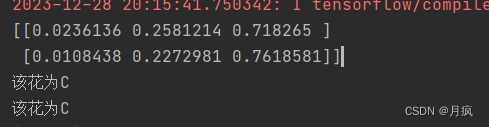
y_pred = model.predict([[2,1,5.5,2],[2.3,4.5,5.2,9]])
print(y_pred)
for i in y_pred:
a = np.argmax(i)
if a == 0 : print('该花为A')
elif a == 1 : print('该花为B')
elif a == 2 : print('该花为C')
测试结果:准确预测出来为C种类?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mapistub.dll文件丢失,软件和游戏无法启动,怎样一键修复
- 【Java 进阶篇】Java会话技术之Cookie的存活时间
- REVIT二次开发万能刷
- 图片直播——互联网时代下的标配工具
- ED UV灯FCC认证的辐射与传导整改实例
- Eplan中如何自定义制造商或供应商的详细数据?
- C++ //练习 1.16 编写程序,从cin读取一组数,输出其和。
- 易点易动:员工自助领用固定资产大幅度提升固定资产管理效率
- 图像分割 分水岭法 watershed
- 通过聚道云软件连接器实现钉钉与自研主数据系统的完美融合