Dinky安装和部署
概述
Dinky 是一个开箱即用、易扩展,以 Apache Flink 为基础,连接 OLAP 和数据湖等众多框架的一站式实时计算平台,致力于流批一体和湖仓一体的探索与实践。
官网:http://www.dlink.top/
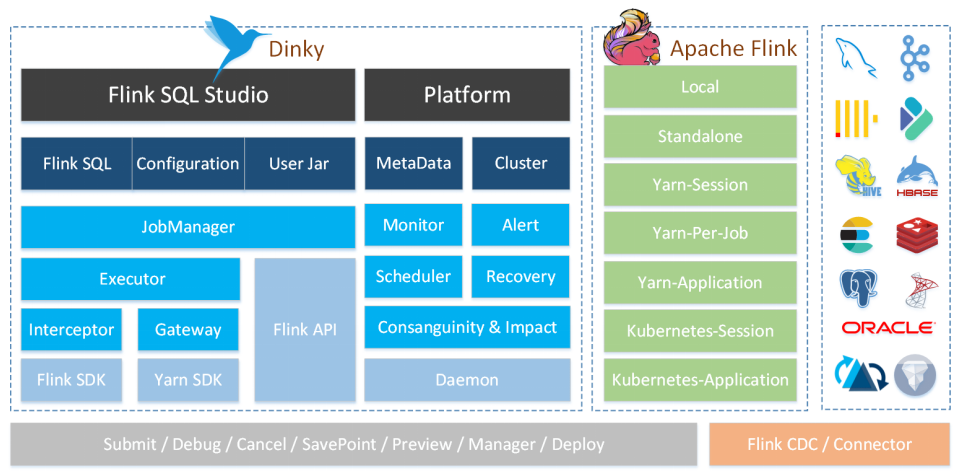
核心特性
沉浸式
提供专业的 DataStudio 功能,支持全屏开发、自动提示与补全、语法高亮、语句美化、语法校验、 调试预览结果、全局变量、MetaStore、字段级血缘分析、元数据查询、FlinkSQL 生成等功能。
易用性
Flink 多种执行模式无感知切换,支持 Flink 多版本切换,自动化托管实时任务、恢复点、报警等, 自定义各种配置,持久化管理的 Flink Catalog。
增强式
兼容且增强官方 FlinkSQL 语法,如 SQL 表值聚合函数、全局变量、CDC 整库同步、执行环境、 语句合并、共享会话等。
一站式
提供从 FlinkSQL 开发调试到上线下线的运维监控及 SQL 的查询执行能力,使数仓建设及数据治理一体化。
易扩展
源码采用 SPI 插件化及各种设计模式支持用户快速扩展新功能,如连接器、数据源、报警方式、 Flink Catalog、CDC 整库同步、自定义 FlinkSQL 语法等。
无侵入
Spring Boot 轻应用快速部署,不需要在任何 Flink 集群修改源码或添加额外插件,无感知连接和监控Flink 集群。
功能
?沉浸式 FlinkSQL 数据开发:自动提示补全、语法高亮、语句美化、在线调试、语法校验、执行计划、MetaStore、血缘分析、版本对比等
?支持 FlinkSQL 多版本开发及多种执行模式:Local、Standalone、Yarn/Kubernetes Session、Yarn Per-Job、Yarn/Kubernetes Application
?支持 Apache Flink 生态:Connector、FlinkCDC、Table Store 等
?支持 FlinkSQL 语法增强:表值聚合函数、全局变量、执行环境、语句合并、整库同步等
?支持 FlinkCDC 整库实时入仓入湖、多库输出、自动建表、模式演变
?支持 Flink Java / Scala / Python UDF 开发与自动提交
?支持 SQL 作业开发:ClickHouse、Doris、Hive、Mysql、Oracle、Phoenix、PostgreSql、Presto、SqlServer、StarRocks 等
?支持实时在线调试预览 Table、 ChangeLog、统计图和 UDF
?支持 Flink Catalog、数据源元数据在线查询及管理
?支持自动托管的 SavePoint/CheckPoint 恢复及触发机制:最近一次、最早一次、指定一次等
?支持实时任务运维:上线下线、作业信息、集群信息、作业快照、异常信息、数据地图、数据探查、历史版本、报警记录等
?支持作为多版本 FlinkSQL Server 以及 OpenApi 的能力
?支持实时作业报警及报警组:钉钉、微信企业号、飞书、邮箱等
?支持多种资源管理:集群实例、集群配置、Jar、数据源、报警组、报警实例、文档、系统配置等
?支持企业级管理功能:多租户、用户、角色、命名空间等
安装部署
Flink安装包下载:
https://flink.apache.org/zh/downloads
Dinky安装包下载:
http://www.dlink.top/download/download
解压到指定目录并重命名
[zhangflink@flinkv2 package]$ tar -zxvf dlink-release-0.7.3.tar.gz -C ../software/

初始化MySQL数据库
Dinky 采用 mysql 作为后端的存储库,部署需要 MySQL5.7 以上版本,这里我们使用的MySQL是8.0。
在 Dinky 根目录 sql 文件夹下分别放置了初始化的dinky.sql文件、升级使用的upgrade/${version}_schema/mysql/ddl 和 dml。如果第一次部署,可以直接将 sql/dinky.sql 文件在 dinky 数据库下执行。(如果之前已经部署,那 upgrade 目录下 存放了各版本的升级 sql ,根据版本号按需执行即可)。
在MySQL中操作如下:
#创建数据库
mysql>
CREATE DATABASE dinky;
#创建用户并允许远程登录
mysql>
create user 'dinky'@'%' IDENTIFIED WITH mysql_native_password by 'dinky';
#授权
mysql>
grant ALL PRIVILEGES ON dinky.* to 'dinky'@'%';
mysql>
flush privileges;
登录创建好的dinky用户,执行初始化sql文件(可以把sql粘贴到控制台批量执行)
mysql -udinky -pdinky
mysql>
use dinky;
mysql> source /opt/software/dinky/sql/dinky.sql
修改配置文件
修改 Dinky 连接 mysql 的配置文件。
spring:
datasource:
url: jdbc:mysql://${MYSQL_ADDR:flinkv3:3306}/${MYSQL_DATABASE:dinky}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: ${MYSQL_USERNAME:dinky}
password: ${MYSQL_PASSWORD:dinky}
driver-class-name: com.mysql.cj.jdbc.Driver
application:
name: dinky
mvc:
pathmatch:
matching-strategy: ant_path_matcher
format:
date: yyyy-MM-dd HH:mm:ss
#json格式化全局配置
jackson:
time-zone: GMT+8
date-format: yyyy-MM-dd HH:mm:ss
main:
allow-circular-references: true
# 默认使用内存缓存元数据信息,
# dlink支持redis缓存,如有需要请把simple改为redis,并打开下面的redis连接配置
# 子配置项可以按需要打开或自定义配置
cache:
type: simple
## 如果type配置为redis,则该项可按需配置
# redis:
## 是否缓存空值,保存默认即可
# cache-null-values: false
## 缓存过期时间,24小时
# time-to-live: 86400
# flyway:
# enabled: false
# clean-disabled: true
## baseline-on-migrate: true
# table: dlink_schema_history
# Redis配置
#sa-token如需依赖redis,请打开redis配置和pom.xml、dlink-admin/pom.xml中依赖
# redis:
# host: localhost
# port: 6379
# password:
# database: 10
# jedis:
# pool:
# # 连接池最大连接数(使用负值表示没有限制)
# max-active: 50
# # 连接池最大阻塞等待时间(使用负值表示没有限制)
# max-wait: 3000
# # 连接池中的最大空闲连接数
# max-idle: 20
# # 连接池中的最小空闲连接数
# min-idle: 5
# # 连接超时时间(毫秒)
# timeout: 5000
servlet:
multipart:
max-file-size: 524288000
max-request-size: 524288000
enabled: true
server:
port: 8888
mybatis-plus:
mapper-locations: classpath:/mapper/*Mapper.xml
#实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: com.dlink.model
global-config:
db-config:
id-type: auto
configuration:
##### mybatis-plus打印完整sql(只适用于开发环境)
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
log-impl: org.apache.ibatis.logging.nologging.NoLoggingImpl
# Sa-Token 配置
sa-token:
# token名称 (同时也是cookie名称)
token-name: satoken
# token有效期,单位s 默认10小时, -1代表永不过期
timeout: 36000
# token临时有效期 (指定时间内无操作就视为token过期) 单位: 秒
activity-timeout: -1
# 是否允许同一账号并发登录 (为true时允许一起登录, 为false时新登录挤掉旧登录)
is-concurrent: false
# 在多人登录同一账号时,是否共用一个token (为true时所有登录共用一个token, 为false时每次登录新建一个token)
is-share: true
# token风格
token-style: uuid
# 是否输出操作日志
is-log: false
knife4j:
enable: true
dinky:
dolphinscheduler:
enabled: false
# dolphinscheduler 地址
url: http://127.0.0.1:5173/dolphinscheduler
# dolphinscheduler 生成的token
token: ad54eb8f57fadea95f52763517978b26
# dolphinscheduler 中指定的项目名不区分大小写
project-name: Dinky
# Dolphinscheduler DinkyTask Address
address: http://127.0.0.1:8888
# python udf 需要用到的 python 执行环境
python:
path: python
加载依赖
加载Flink依赖
Dinky 需要具备自身的 Flink 环境,该 Flink 环境的实现需要用户自己在 Dinky 根目录下 plugins/flink${FLINK_VERSION} 文件夹并上传相关的 Flink 依赖。当然也可在启动文件中指定 FLINK_HOME,但不建议这样做。
cp /opt/software/flink-1.17.0/lib/* /opt/software/dink/plugins/flink1.17

加载Hadoop依赖
Dinky 当前版本的 yarn 的 perjob 与 application 执行模式依赖 flink-shade-hadoop ,需要额外添加 flink-shade-hadoop-uber-3 包。对于 dinky 来说,Hadoop 3 的uber依赖可以兼容hadoop 2。
将flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar上传到/opt/module/dinky/plugins目录下。
上传jar包
使用 Application 模式时,需要将flink和dinky相关的包上传到HDFS。
创建HDFS目录并上传dinky的jar包
hadoop fs -mkdir -p /dinky/jar/
hadoop fs -put /opt/software/dinky/jar/dlink-app-1.17-0.7.3-jar-with-dependencies.jar /dinky/jar

创建HDFS目录并上传flink的jar包
hadoop fs -mkdir /flink-dist
hadoop fs -put /opt/software/flink-1.17.0/lib /flink-dist
hadoop fs -put /opt/software/flink-1.17.0/plugins /flink-dist
启停命令
启动命令
cd /opt/software/dinky
sh auto.sh start 1.17

服务启动后,默认端口 8888,http://hadoop102:8888 , 默认用户名/密码: admin/admin
停止命令
停止命令不需要携带Flink版本号。
cd /opt/software/dinky
sh auto.sh stop
重启命令
cd /opt/software/dinky
sh auto.sh restart 1.17

Flink设置
使用 Application 模式以及 RestAPI 时,需要修改相关Flink配置:配置中心 >> Flink配置。
将“提交FlinkSQL的Jar文件路径”修改为dlink-app包的路径,点击保存。

执行测试
创建集群
提交 FlinkSQL 作业时,首先要保证安装了 Flink 集群。Flink 当前支持的集群模式包括:
?Standalone 集群
?Yarn 集群
?Kubernetes 集群
对于以上的三种集群而言,Dinky 为用户提供了两种集群管理方式,一种是集群实例管理,一种是集群配置管理。
Flink实例管理
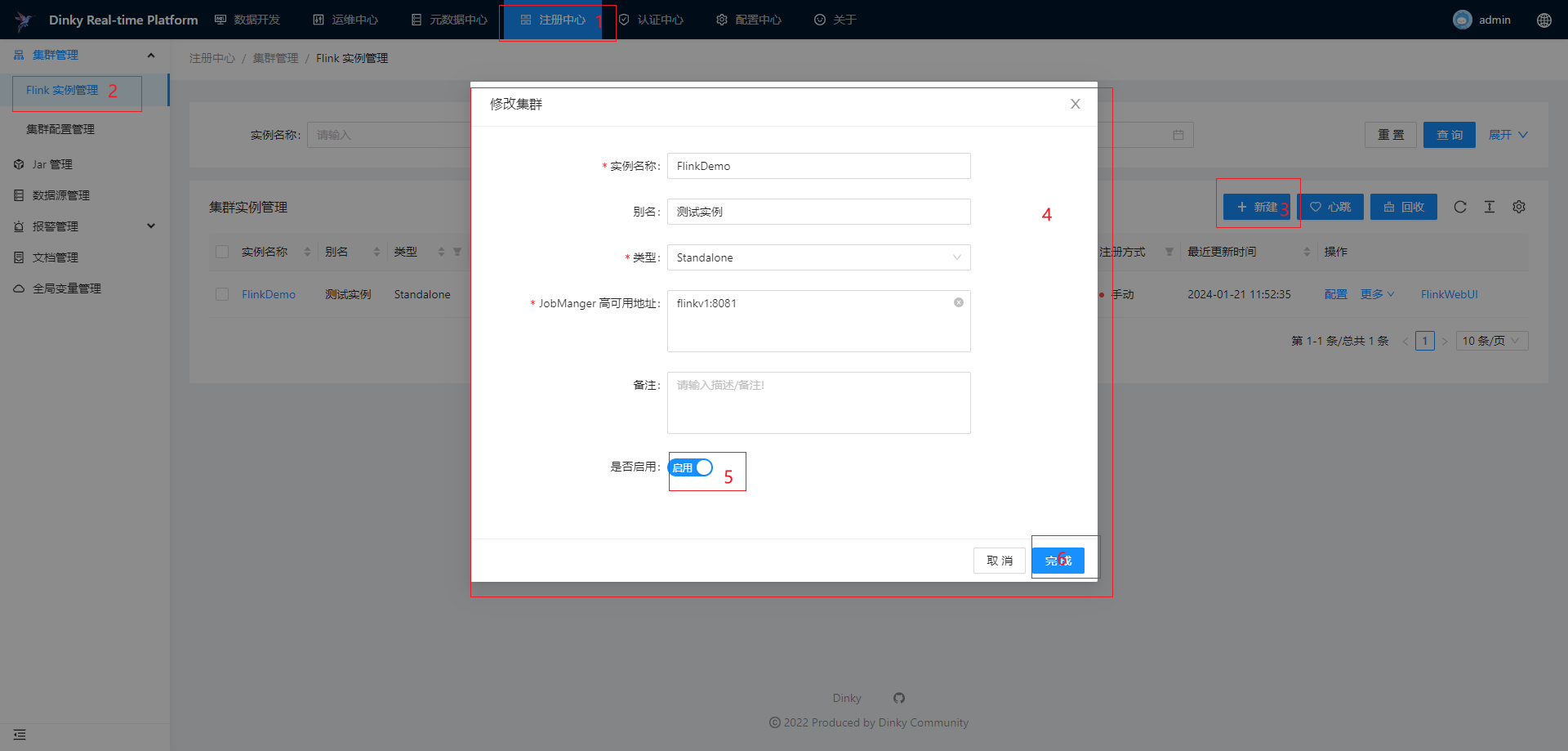
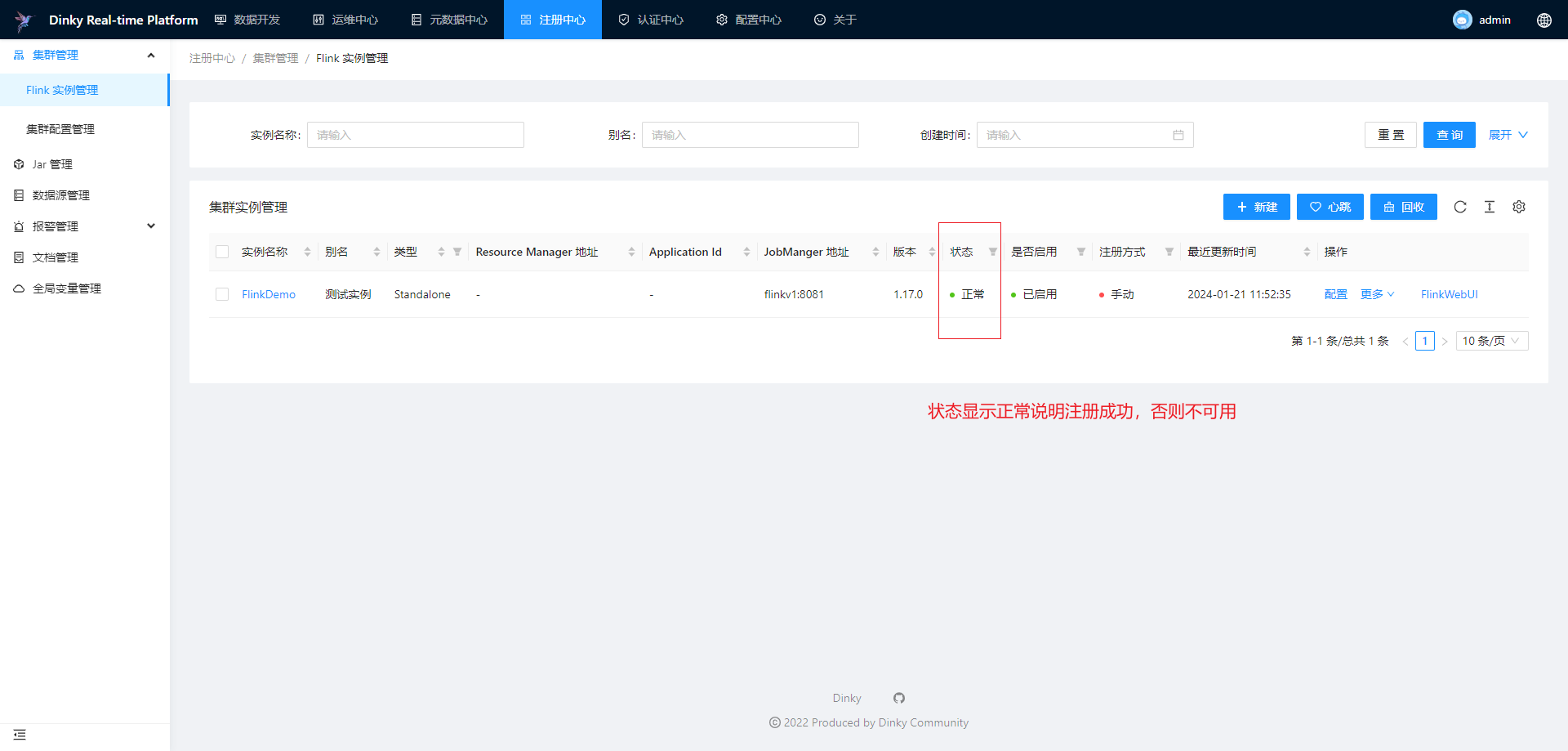
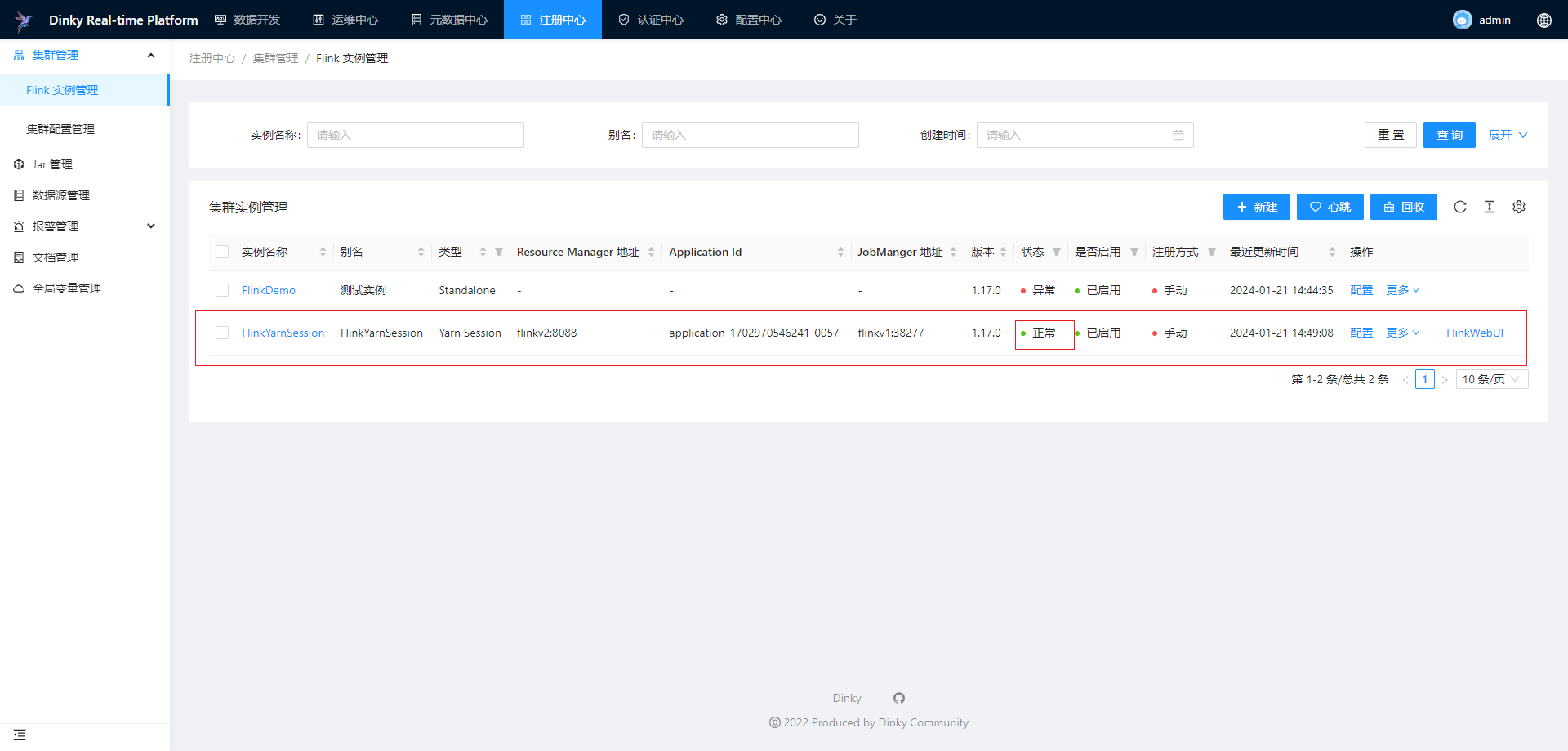
集群实例管理适用于 Standalone,Yarn Session 和 Kubernetes Session 这三种集群实例的注册,其他类型的集群只能查看作业信息。对于已经注册的集群实例,可以对集群实例做编辑、删除、搜索、心跳检测和回收等。
注册Standalone集群
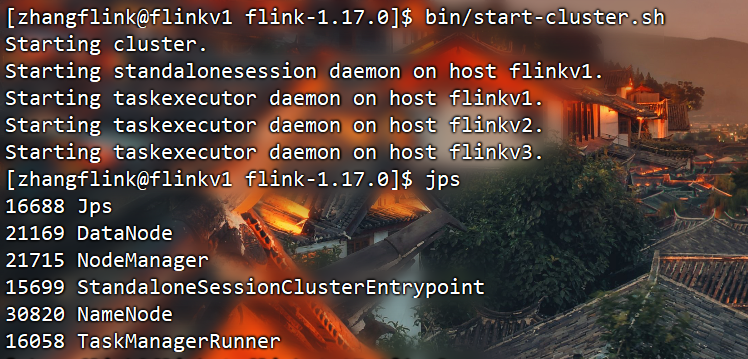
需要先手动启动Standalone集群:
[zhangflink@flinkv1 flink-1.17.0]$ bin/start-cluster.sh
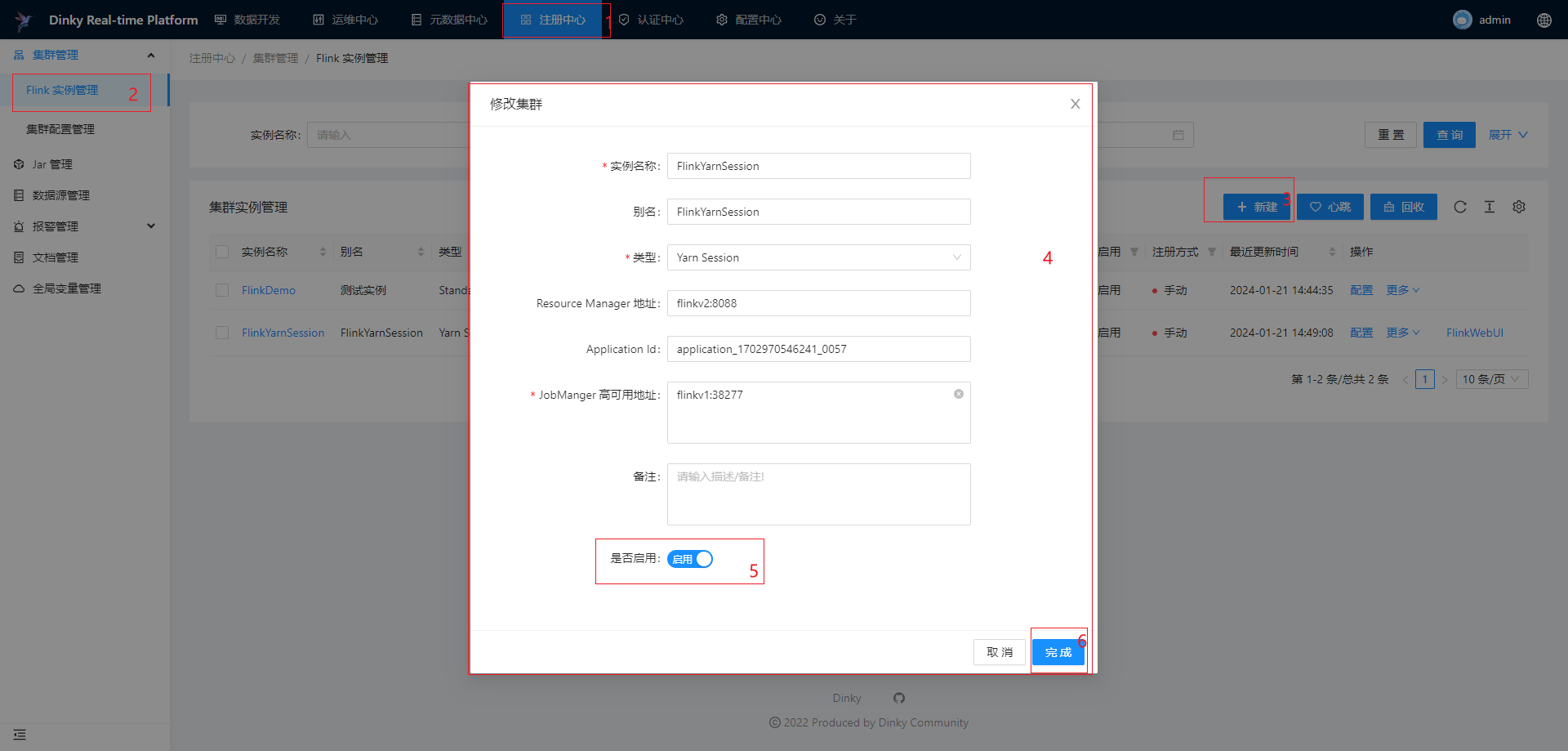
注册Yarn Session集群
需要先手动启动Yarn Session集群:
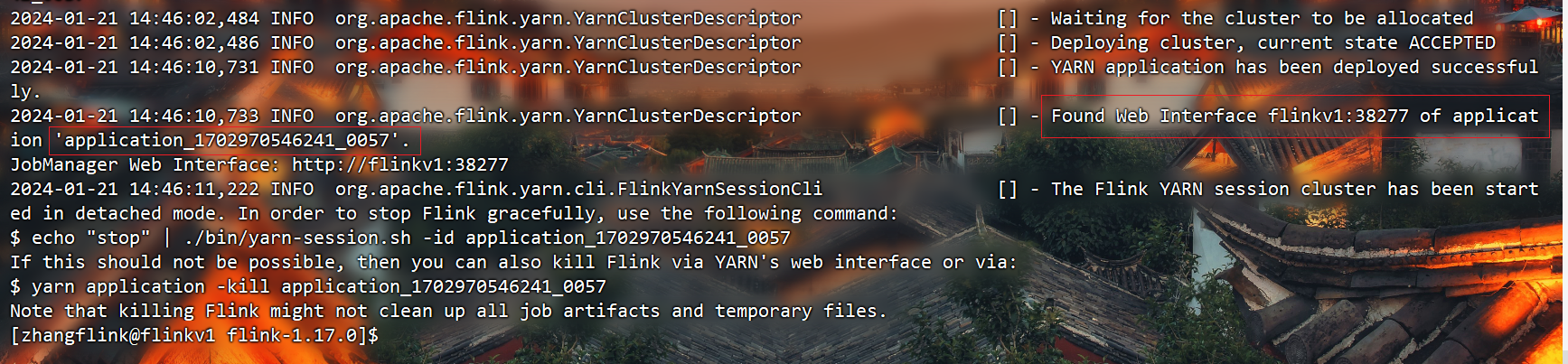
/opt/module/flink-1.17.0/bin/yarn-session.sh -d
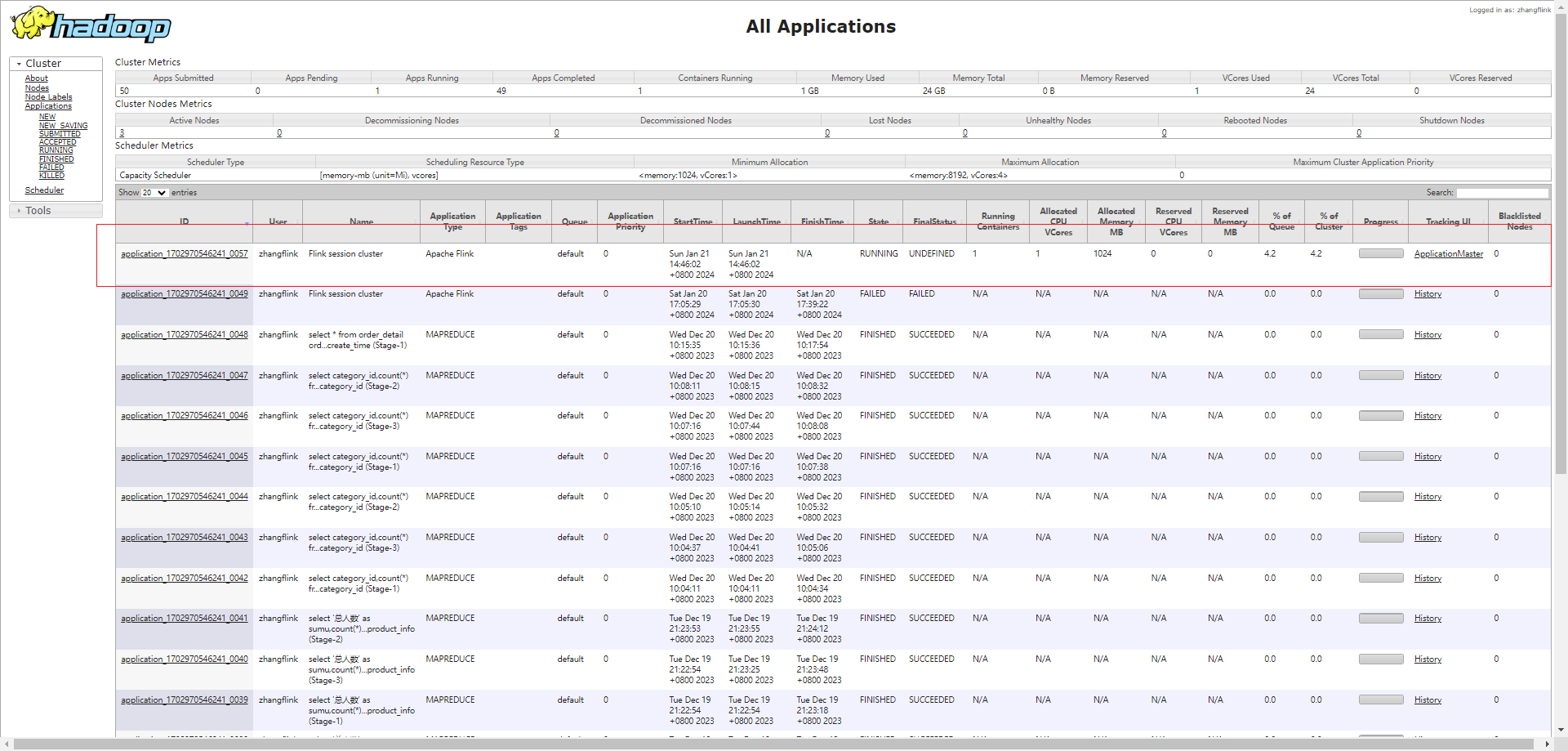
如果flink的配置文件没有指定rest.port,那么记住启动后的主机名、端口,还有启动后的application_id:

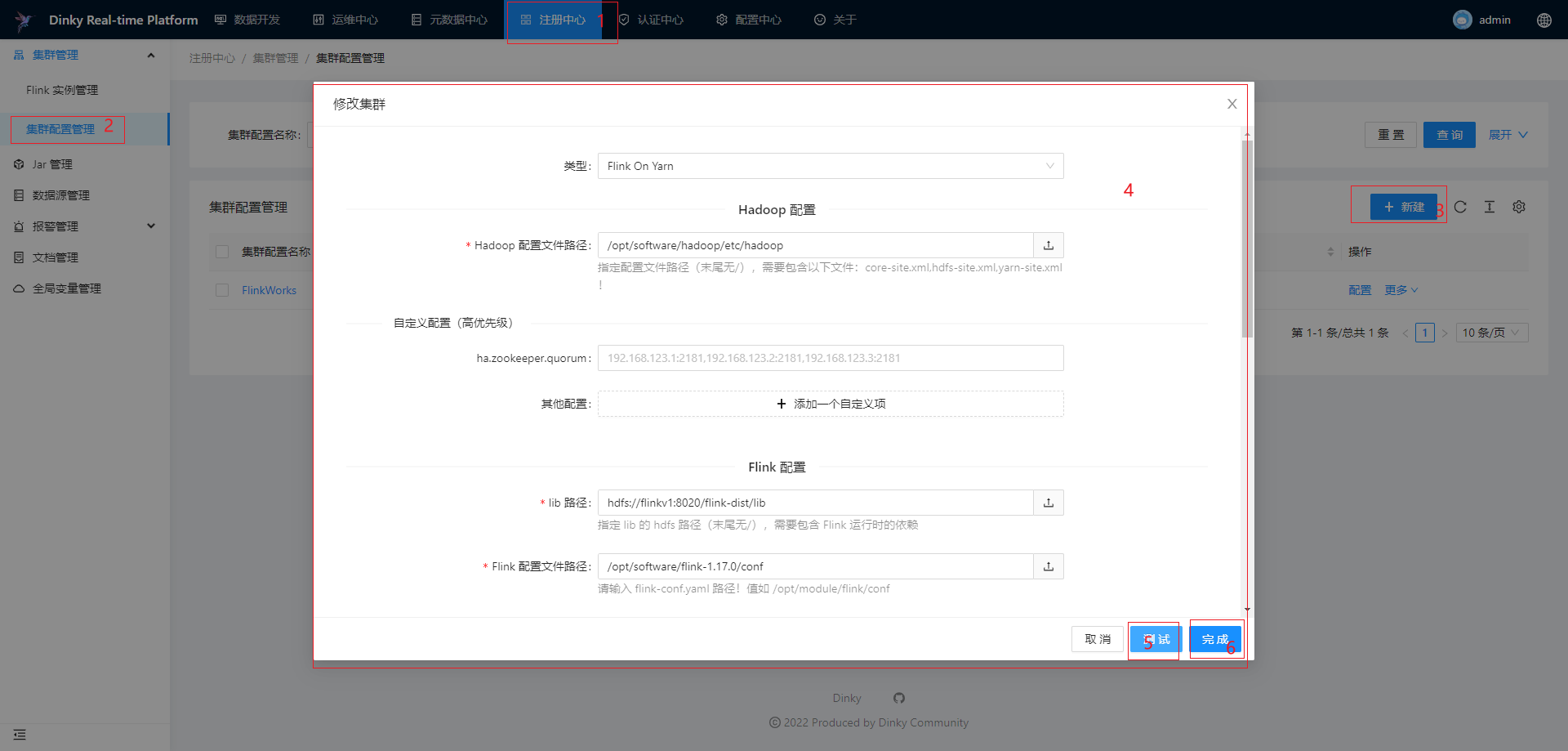
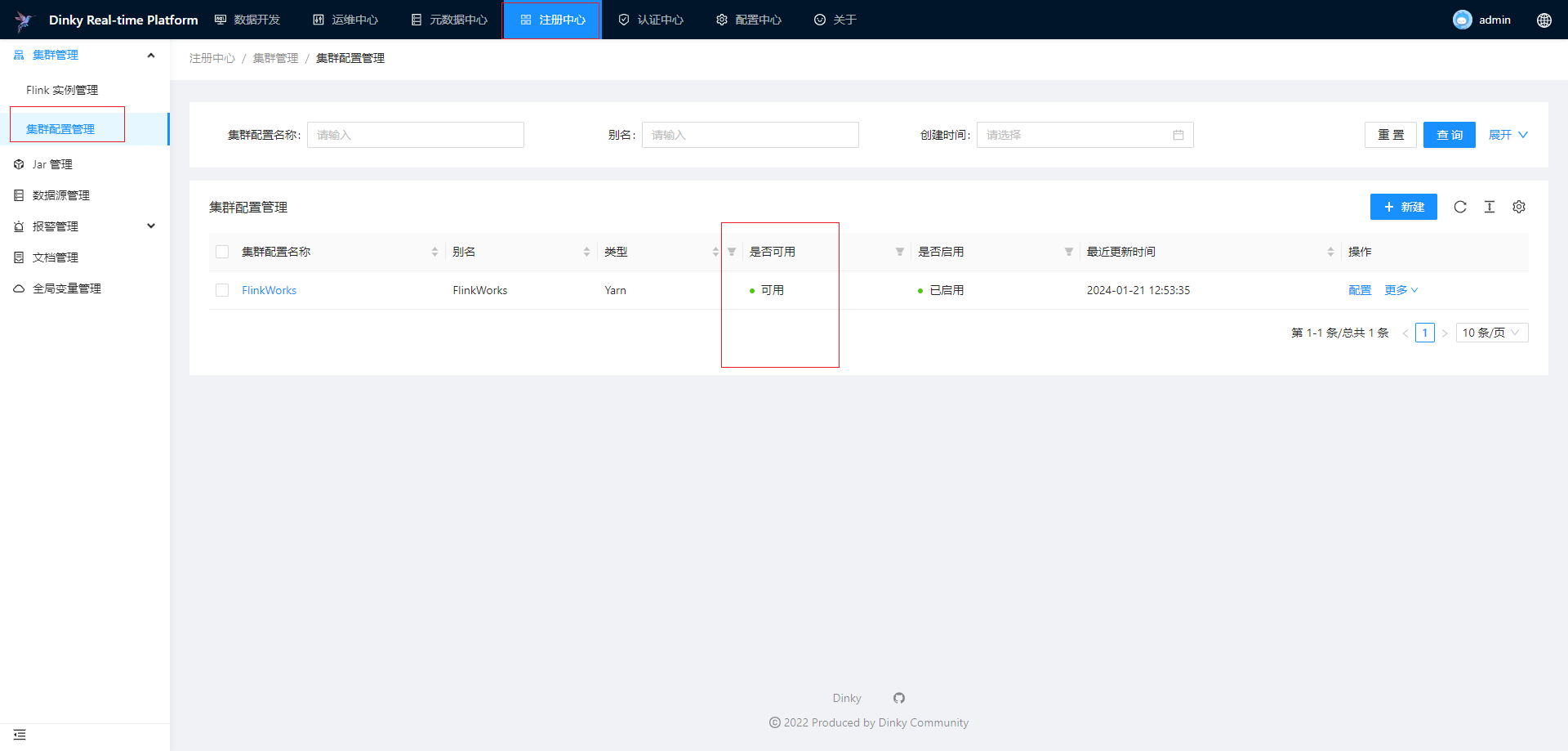
集群配置管理
集群配置管理适用于 Yarn Per-job、Yarn Application 和 Kubernetes Application 这三种类型配置。对于已经注册的集群配置,您可以对集群配置做编辑、删除和搜索等。
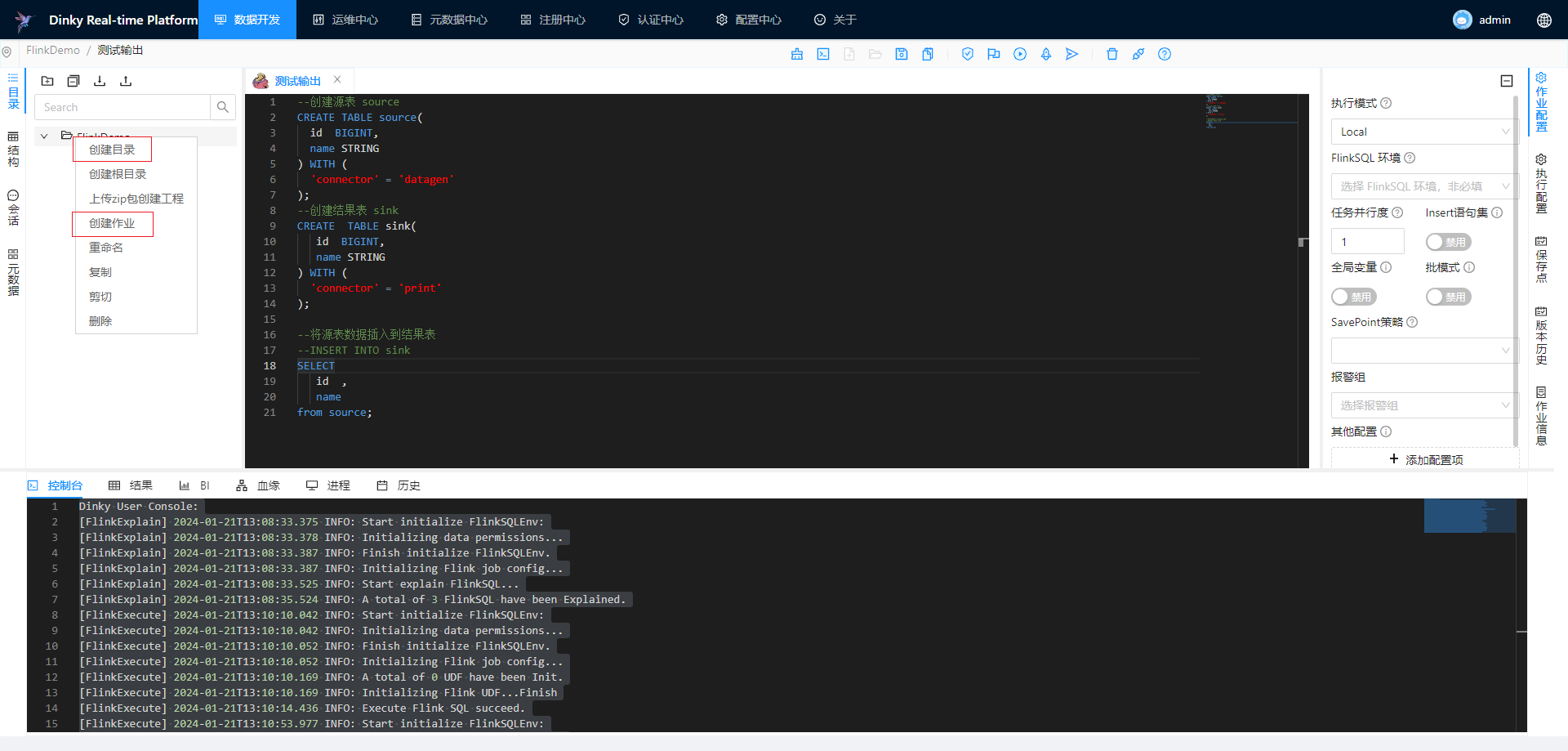
简单案例
FlinkSQL:
--创建源表 source
CREATE TABLE source(
id BIGINT,
name STRING
) WITH (
'connector' = 'datagen'
);
--创建结果表 sink
CREATE TABLE sink(
id BIGINT,
name STRING
) WITH (
'connector' = 'print'
);
--将源表数据插入到结果表
--INSERT INTO sink
SELECT
id ,
name
from source;
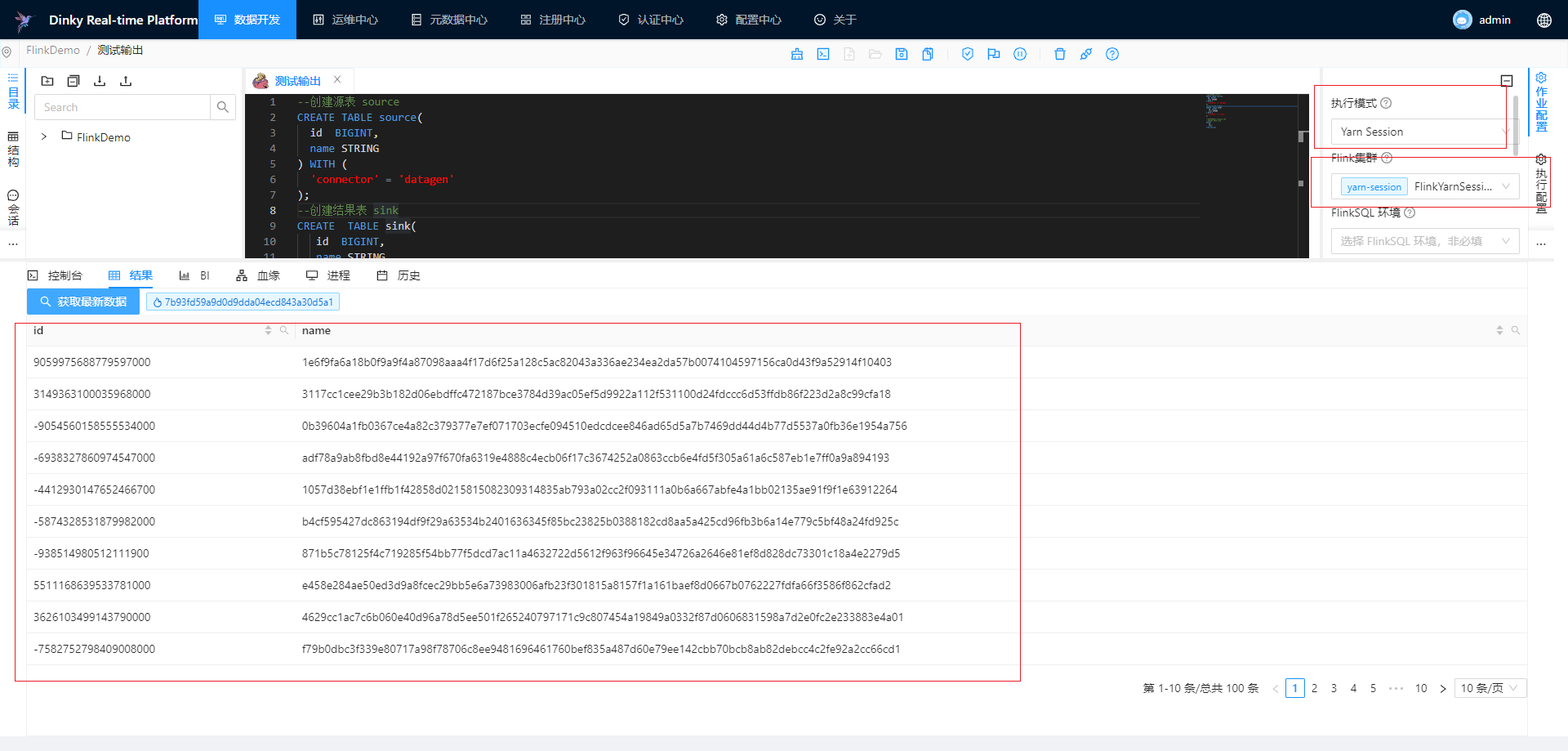
在数据开发模块开发上面的FlinkSQL进行测试
local模式

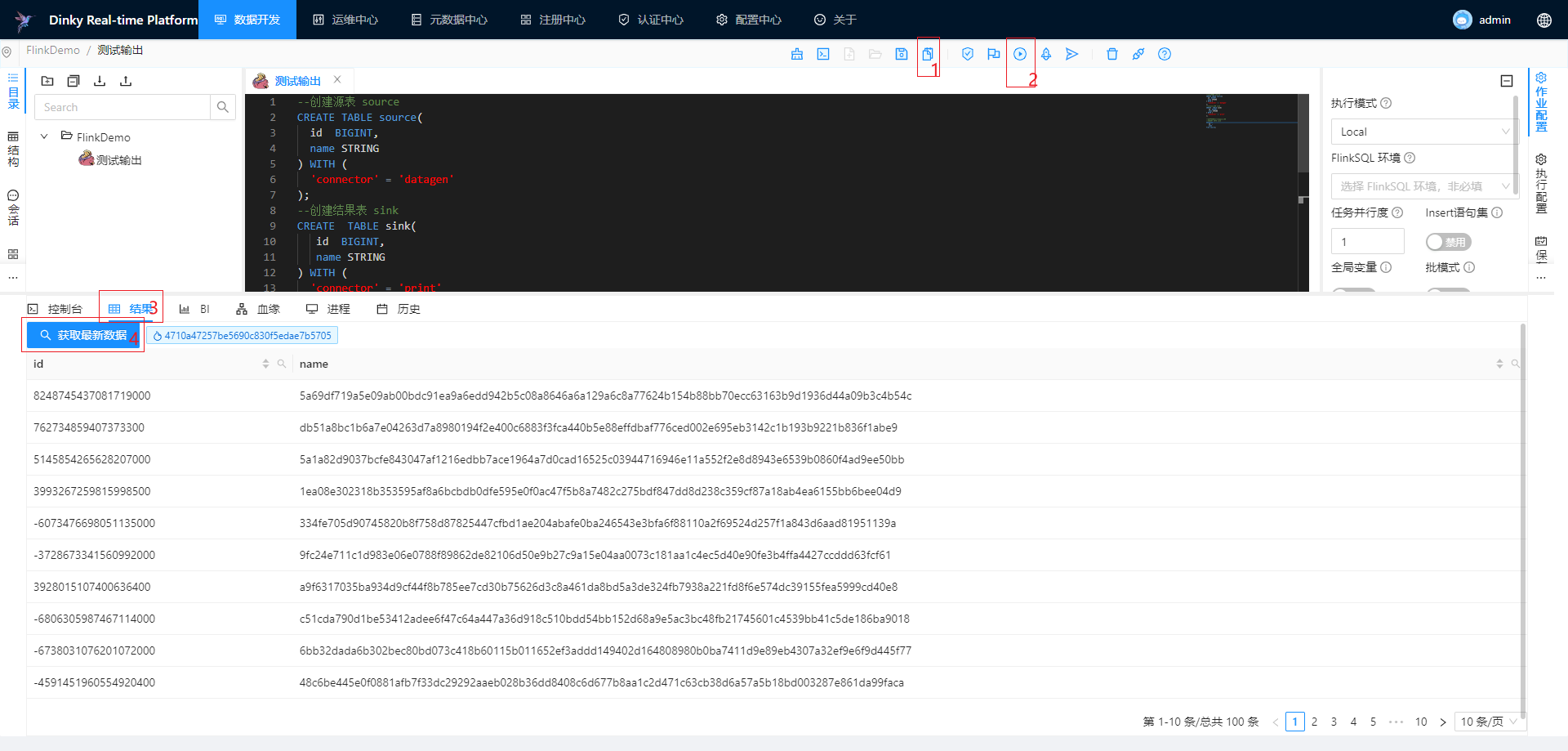
Yarn模式:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!