对 MODNet 其他模块的剪枝探索
写在前面
先前笔者分享了《对 MODNet 主干网络 MobileNetV2的剪枝探索》,没想到被选为了CSDN每天值得看系列,因为笔者开设的专栏《MODNet-Compression探索之旅》仅仅只是记录笔者在模型压缩领域的探索历程,对此笔者深感荣幸,非常感谢官方大大的认可!!!接下来,笔者会加倍努力,创作更多优质文章,为社区贡献更多有价值、有意思的内容!!!!

本文将分享笔者对?MODNet 网络结构内部其他模块的剪枝探索,剪枝策略同前文主干网络是一样的,剪枝完成后对参数进行替换即可,接下来,就开启探索之旅吧~~
1 开展思路
- 访问 MODNet 获取模块;
- torch.save(model.state_dict(), path),并检测能否 load,注意参数;
- 修改替换脚本中 for 循环下的 if 条件判断;
- 修改backbone、MODNet中 IBNorm 以及 wrapper 中的 channels,run script;
- 加载替换后的模型参数,观察是否能够成功执行。
2 核心要义
-
模型分析:根据先前对剪枝后 MobileNet V2 的结构修改,以及嵌入 MODNet 后的 channel 修改情况,确定待修改的网络层;
-
通道裁剪:根据1得到的待修改的网络层进行裁剪,以满足结构与参数匹配的情况;
-
参数嵌入:确认 channel 匹配以后,将参入嵌入 MODNet;
3 探索过程
确定修改后的结构与原先的区别在于下列网络层:
- backbone;
- lr_branch中的 lr16x、lr8x;
- hr_branch中 enc2x;
目前,已对 backbone 成功嵌入。
接下来,针对lr16x、lr8x进行剪枝处理,但通过观察可以发现,这两层的前面存在着 se_block 模块,因此,先对 se_block 进行处理。
3.1 se block
观察该部分在 MODNet 中的尺寸与网络层名称:
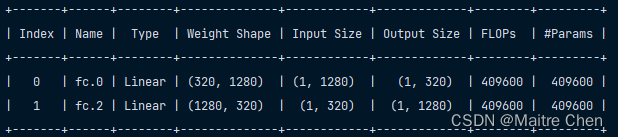

获取并替换成功!不过这部分详细的过程笔者没有记录!存在不周,请谅解~~
3.2 lr16x、lr8x
💥注意:由于起初缺乏对网络层的分析,因此,在进行这两层的嵌入时,仅仅只是单一的嵌入。
将lr16x嵌入以后,出现了“参数 shape > 结构 shape”的情况。
于是,笔者联想到先前的解决方案:固定结构,重新进行参数替换。但即便如此,通过键值对获取参数时,参数中的通道数尺寸并未发生变化。(因此,先前的这种方法存在不合理性,但却在执行后可以成功匹配,目前还没有进一步探寻。)
合理的方案以及针对情况如下:
- 对于output channel:单独提取该层,进行剪枝。(但是,如果和它相连的下一层 input channel 也发生了变化,需要将其合并,同时处理,这样,上一次的输出决定着下一层的输入。)
- 对于input channel:如上,合并处理。但是,如果与该层相连的上一层channel保持不变,那就无法使用剪枝。目前的解决方案是,切片提取,先满足结构要求。
而 lr16x 与 lr8x 正适合第一种情况!
原结构:
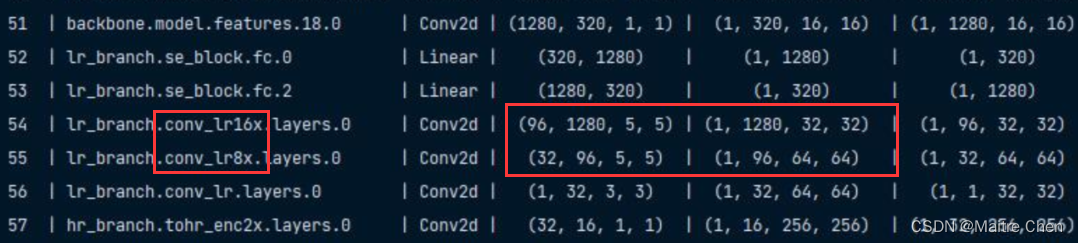
修改后的结构:
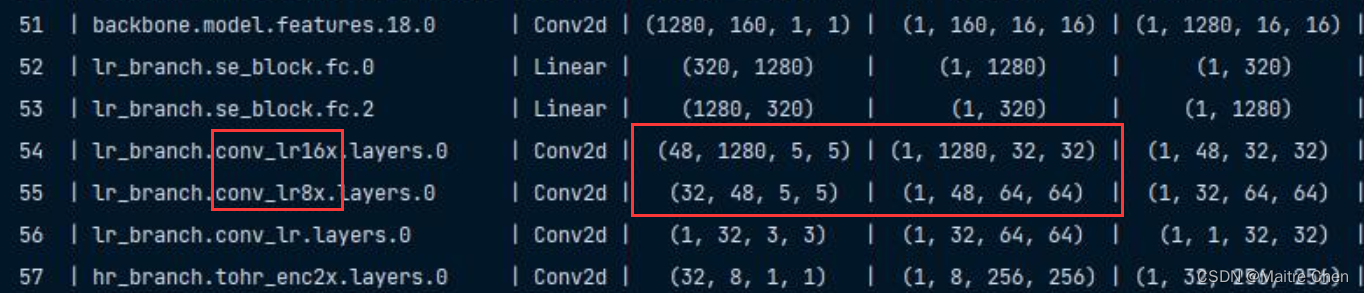
将 lr16x 与 lr8x 作为一个 sequential,剪枝:
model = modnet.MODNet(backbone_pretrained=False)
pretrained_ckpt = 'modnet_photographic_portrait_matting.ckpt'
model.load_state_dict({k.replace('module.', ''): v for k, v in torch.load(pretrained_ckpt).items()})
# get model
model = nn.Sequential(model.lr_branch.conv_lr16x, model.lr_branch.conv_lr8x)
print(model)
# pruning
# 由于是针对lr16x的output以及lr8x的input,因此这里排除lr8x即可
config_list = [{'sparsity': 0.5,
'op_types': ['Conv2d']},
{'exclude': True,
'op_names': ['1.layers.0']}
]
pruner = L1NormPruner(model, config_list)
_, masks = pruner.compress()
pruner._unwrap_model()
ModelSpeedup(model, dummy_input, masks).speedup_model()
print(model)结构变化:
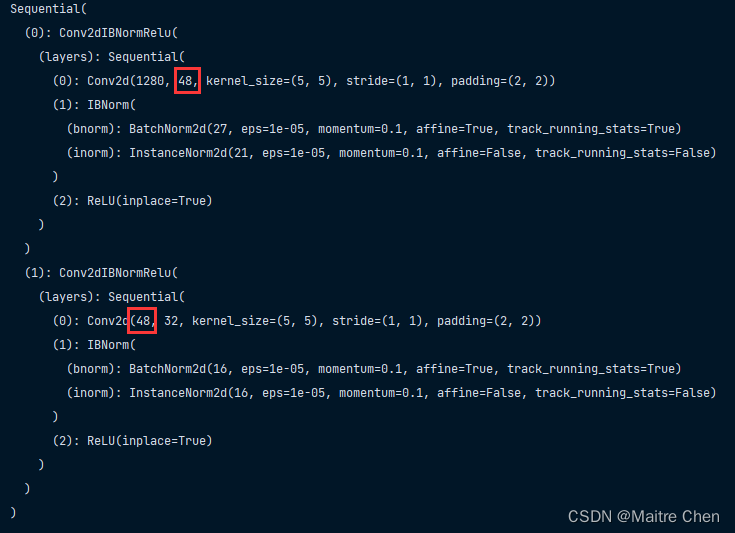
修改网络结构(mobilenet、wrapper、IBNorm),加载裁剪后的参数,能成功执行计算:
IBNorm结构变化,init部分:
def __init__(self, in_channels):
super(IBNorm, self).__init__()
in_channels = in_channels
# 针对lr_16x
if in_channels == 48:
self.bnorm_channels = 27
self.inorm_channels = 21
else:
self.bnorm_channels = int(in_channels / 2)
self.inorm_channels = in_channels - self.bnorm_channels 加载:
model = modnet.MODNet(backbone_pretrained=False)
model = nn.Sequential(model.lr_branch.conv_lr16x, model.lr_branch.conv_lr8x)
model.load_state_dict(torch.load('test.pth'))
dummy_input = torch.randn([1, 1280, 32, 32])
flops, params, _ = count_flops_params(model, dummy_input, verbose=True)
print(f"Model FLOPs {flops / 1e6:.2f}M, Params {params / 1e6:.2f}M")结果:
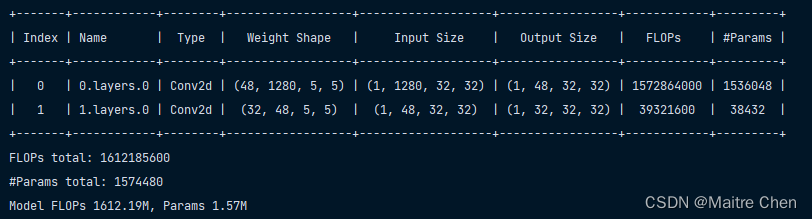
替换MODNet中,这一部分的参数,保存并加载:
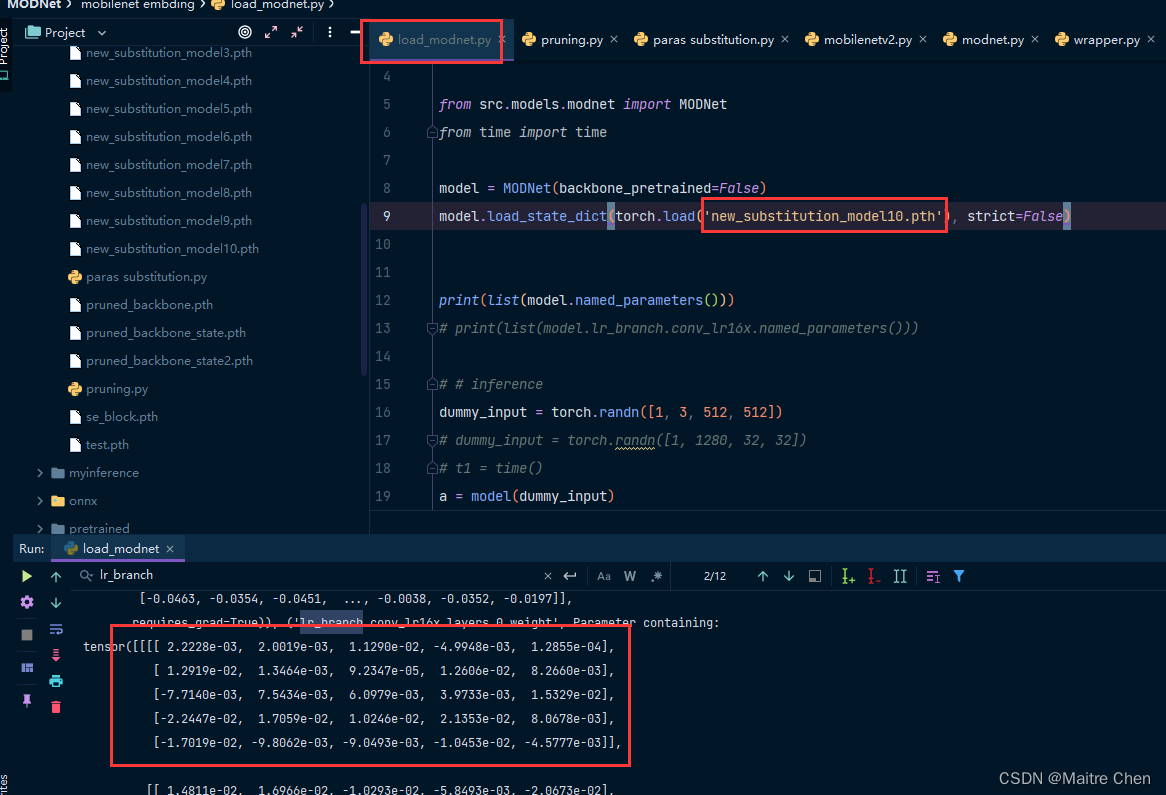
3.3 enc2x
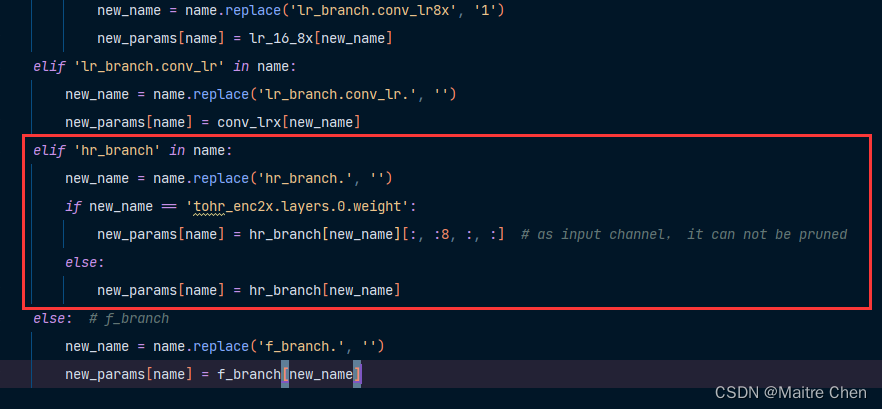
至此,三个模块的参数全部嵌入!
4 探索结果
4.1 模型大小

4.2 参数量与计算量
| 剪枝前 | 剪枝后 | |
| 参数量 | 6.45 M | 3.36 M |
| 计算量 | 18117.07 M | 15315.94 M |
4.3 推理时延
| 序号 | 剪枝前 | 剪枝后 |
|---|---|---|
| 1 | 0.89 | 0.67 |
| 2 | 0.96 | 0.68 |
| 3 | 0.86 | 0.67 |
4.4 精度
| 评估指标 | 原模型 | 针对MobileNet V2剪枝后 | 微调后 | 从头训练后 |
|---|---|---|---|---|
| MSE | 0.004299 | 0.360781 | 0.140384 | 0.104005 |
| MAD | 0.008141 | 0.576560 | 0.211169 | 0.124459 |
5 实际推理测试
使用微调后的pth导出onnx模型:
model.eval()
batch_size = 1
height = 512
width = 512
dummy_input = Variable(torch.randn(batch_size, 3, height, width))
torch.onnx.export(
model, dummy_input, 'test_modnet.onnx', export_params=True,
input_names=['input'], output_names=['output'],
dynamic_axes={'input': {0: 'batch_size', 2: 'height', 3: 'width'},
'output': {0: 'batch_size', 2: 'height', 3: 'width'}}, opset_version=11)推理:

和微调前的推理结果并无差别,但在直接使用pth格式模型推理时差异较大。
为何会这样?难道是因为笔者选用的不是人像,而是天线宝宝?
在观察导出的 ONNX 格式模型时,笔者发现模型输出节点的个数发生了变化。
原因是笔者在导出时没有注意 output,使用官方脚本解决了~
💥注意:这也就告诉我们,模型导出时的成功提示并不一定是真正处理好了,很多内部细节的丢失会对模型的推理精度带来致命的效果,这时我们可以重新思考模型的输入与输出,或者采用可视化的方式进行查看!
再次推理:
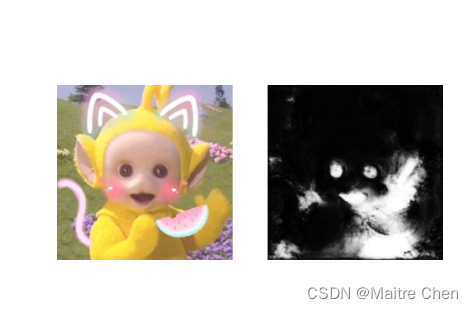
虽然效果仍然不理想,但至少好了很多,而且可以看出来,笔者选用的测试样例确实不是人!
推理时延变化:240ms---> 192ms,有明显改进!
在导出时也遇到了一个error:
onnxruntime::UpsampleBase::ScalesValidation scale >= 1 was false. Scale value should be greater tha
分析原因:调用?torch.export 时未指定 op_version;
解决方案:考虑到 笔者的pytorch version>=1.3.1,因此直接指定其为op为11,完成了推理!
6 结论?
- 在替换除了 MobileNet V2 以外的其他部分时,没有考虑整体,仅仅只是对单一的卷积层剪枝,以致于相连的下一个卷积层无法修改通道数。因此,剪枝无法直接对 input channels 操作,只能针对 output channels,进而影响 input channels。
- 关于IBNorm,直接修改了channels,可以运行,但缺乏通用性!
- 成功嵌入了除 MobileNet V2 以外的参数,并成功导出 ONNX 模型,完成模型推理!
- 经测试,模型大小、参数量降低了一半,推理时延降低 20%,从模型压缩的轻量化角度来看,本次探索是成功的,但从模型本身的精度来看,还有很长一段路要走!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!