【prompt一】Domain Adaptation via Prompt Learning
1.Motivation
当前的UDA方法通过对齐源和目标特征空间来学习域不变特征。这种对齐是由诸如统计差异最小化或对抗性训练等约束施加的。然而,这些约束可能导致语义特征结构的扭曲和类可辨别性的丧失。
在本文中,引入了一种新的UDA提示学习范式,即通过提示学习进行领域适应(DAPL)。使用了预训练的视觉语言模型,并且只优化了很少的参数。主要思想是将领域信息嵌入到提示中,这是一种由自然语言生成的表示形式,然后用于执行分类。该域信息仅由来自同一域的图像共享,从而根据每个域动态调整分类器。
2.Introduce
通过对齐域来减少差异可能会导致语义信息的丢失。当数据分布的流形结构很复杂时,这种损失来自于语义和领域信息的纠缠性。为了解决这个问题,最近的一些UDA方法主张保留语义信息以保持类的可判别性。然而,这些方法在领域对齐和保留语义特征之间存在微妙的权衡,因为两个目标可能是对立的。学习解纠缠的语义和领域表示可以是一种选择,因为领域对齐可以被丢弃。
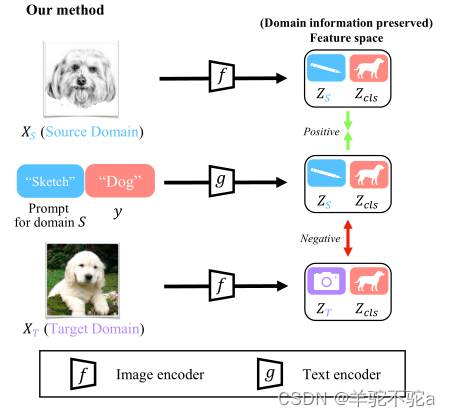
为了学习解纠缠语义和领域表示,将提示学习方法引入UDA,通过学习连续标签空间中的表示。图2说明了提示设计。提示符由三部分组成:与领域无关的上下文、特定于领域的上下文和类标签(token)。每个图像通过提示符的类标签对应一个ground truth类。例如,显示“狗的艺术作品”的图像可以对应提示“绘画狗的图像”。与领域无关的上下文表示一般任务信息,并在所有图像之间共享。特定于域的上下文表示域信息,并在每个域中共享。类标签区分不同的类别。

这种提示学习方法使我们能够学习领域和类别的解纠缠表示,并避免语义信息的丢失。应用对比目标进行训练。图像和文本只有在领域和类别匹配的情况下才构成一对正例,其他情况都是反例。通过对比XS和y的表示,“sketch”和“dogs”的图像和文本表示分别在特征空间中对齐。此外,通过对比XT和y,“sketch”的文本表示被推离“photo”域。因此,领域和类别的表示分别是对齐的。采用对比语言图像预训练(contrast Language Image Pretraining, CLIP)作为主干,促进提示学习和对比学习。
3.Method
3.1. Preliminaries
采用CLIP作为主干。模型由图像编码器f(·)和文本编码器g(·)组成。图像编码器可以是ResNet或Vision Transformer (ViT),文本编码器是Transformer。图像和文本输入可以通过编码器直接从高维空间转换到低维特征空间。
CLIP以对比的方式使用图像-文本对进行训练。每个输入文本以“一张[CLASS]的照片”的格式描述一个类别([CLASS]是类别标记)。正对是一个图像xi及其对应描述xi的类别的文本ti。负对是小批量中图像xi以及具有不相关描述tj, j≠i。训练目标是最大化正对的余弦相似度,最小化负对的余弦相似度。对比学习目标将图像和文本表示在相同的特征空间中对齐。
在特征对齐后,该模型能够进行zero-shot推理。通过转发K个类别描述,一个图像x将属于相似度最大的类别:

其中T是用户定义的超参数(温度),<.>表示余弦相似度。
上面描述的输入文本是一个手工设计的提示符,由一系列离散的记号组成。人工设计的提示符被转换成词嵌入空间中的固定向量。由于这些向量对于类别的表示可能不是最优的,所以可以优化标记的连续嵌入。连续表示tk允许更精确地描述语义特征,这对上下文变量学习很重要。
现有的提示学习方法采用了一种领域不可知论的风格,即上下文在所有领域和所有类别之间共享。它遵循统一的风格:

式中[v]m1, m1∈{1,2,…M1}是与嵌入词具有相同维数的向量,M1是提示符中应用的上下文令牌的数量。
3.2. Domain Adaptation via Prompt Learning
由于单独的领域不可知上下文不能处理领域之间的分布转移,使用领域特定上下文(DSC)来捕获每个领域的独特特征。具体地说,提示包含两个对应的上下文,一个域不可知论上下文和一个域特定上下文。使用来表示特定于领域的标记,这些标记与词嵌入具有相同的维度。特定于领域的上下文在所有类别之间共享,但专门为每个领域设计
。特定于域的token的数量用M2表示。域指示器表示源域和目标域d∈{s, u}。整个提示符定义为以下格式:

当文本特征空间中的[CLASS]token不能完全建模每个类之间的差异时,领域不可知的上下文可以遵循由类特定上下文表示的类特定样式。每个类都可以用不同的token初始化:
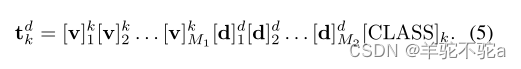
可训练的类特定上下文可以学习比仅[CLASS]令牌更细粒度的表示。
本文的主要结果基于类特定上下文和领域特定上下文,如Eq.(5)。
有2K个类别,因为分别为源域和目标域应用了不同的提示任务。给定源域的一组训练样本{xsi, ysi}Nsi=1,可以得到训练样本属于第k类的概率:

以图像xi属于k类的概率,最小化给定真标签ysi的标准交叉熵损失。损失计算如下:
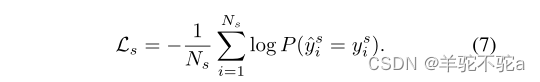
为了进一步利用未标记的数据,在目标域上生成伪标签。从K个预测概率最大的类中选择,作为训练数据的伪标签
:
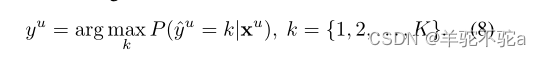
仅为最大预测概率大于伪标签质量的固定阈值τ的未标记数据生成伪标签。利用CLIP的zero-shot推理能力来生成伪标签。用对比目标Eq.(6)来训练这些未标记的图像及其伪标签的目标域提示符:

其中I{·}为指示函数。总的来说,提出的通过提示学习(DAPL)的领域适应方法可以以端到端方式进行训练,并且具有总对比损失:
![]()
现有的域自适应方法在源域上训练分类器学习一个条件概率分布P (y|xs)。通过对齐P (f(xs))和P (f(xu))的边际分布,可以直接利用条件概率在目标域上进行推理。当条件概率分布P (y|xs)≠P (y|xu)时,这些方法可能面临性能下降的风险。本文方法不对齐边缘分布,而是学习两个条件概率分布P (y|xs)和P(y|xu)通过学习两组提示符, k∈{1,2,…K}。因此,本文方法既可以处理条件分布偏移,也可以处理边际分布偏移。DAPL的概述如图3所示。

通过提示学习的领域适应(DAPL):(a) DAPL训练可学习的上下文变量:领域不可知的上下文变量和领域特定的上下文变量,以及由文本编码器组合和编码的[CLASS]令牌。(b)图像编码器对来自不同域的图像进行编码。(c)接下来,计算文本和图像特征之间的余弦相似度,并鼓励正对(具有匹配的域和类)对齐。在Eq.(6)中定义分类概率,并在图像特征和地面真值类之间应用交叉熵损失来训练网络。
3.3. Disentanglement by Contrastive Learning
采用对比损失L作为优化目标。在这里,提供了一个直观的解释为什么这个目标达到了预期的目标:视觉编码器和文本编码器各自将输入编码成两个分离的潜在表示,将领域信息与内在类信息分离。只有当类信息和领域信息对齐时,文本特征和图像特征之间的距离才会最小化。通过最小化这些正对之间的距离(最大化相似性),可以最大化正确标签的概率(参见Eq.(6))。
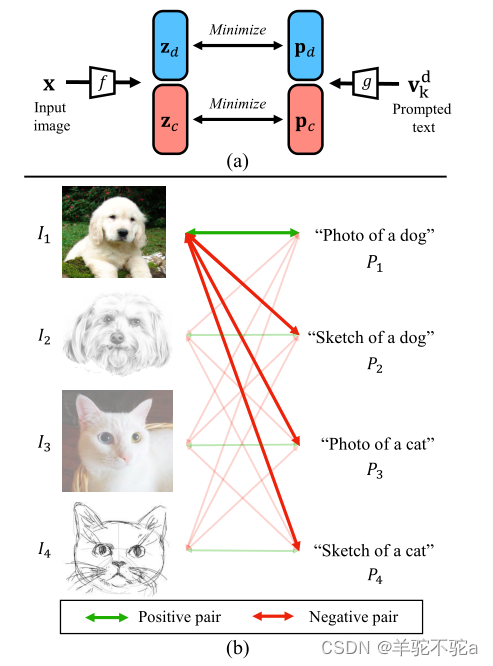
首先,假设可视化表示f(xdi)包含两部分:域d的域信息和类c的固有类信息(图4 (a), zd和zc)。
同样,语言嵌入g(tdk)包含同样的两部分:域d的域信息和类c的类信息(图4 (a), pd和pc)。
接下来,证明了通过优化对比目标可以将这些领域信息和类信息分离开来。
图4 (b)提供了一个说明性示例。在这个例子中,有四个图像-文本对,它们有两个类(猫、狗)和两个域(照片、素描)。以图像I1,提示符P1和P2为例。图像可以与提示符P1形成正对,与提示符P2形成负对。通过优化对比目标,使图像特征f(I1)与g(P1)的句子嵌入之间的距离最小(绿色),而图像特征f(I1)与g(P2)的句子嵌入之间的距离最大(红色)。声称这迫使狗的类信息从照片或素描的领域表示中解脱出来。相反,假设领域信息和类信息在表示中仍然纠缠在一起,即领域表示(p1d和p2d)中包含狗的类信息。在这种情况下,I1和P2仍然匹配,并且f(I1)和g(P2)之间的距离可以通过删除该类信息进一步最大化。换句话说,通过优化对比损失来减少领域表示中的类信息。同样,取(I1, P3)为负对,从类表示中去掉域信息,否则由于类表示中照片的域信息纠缠,f(I1)仍然匹配g(P3)。结合这两个负对,可以通过最小化对比目标,迫使领域表示和内在类信息相互分离。
4.实验
4.1 setting
实现细节。对于Office-Home,使用预训练的CLIP模型,并采用ResNet-50作为其图像编码器。在编码器中固定参数,并使用mini-batchSGD优化器训练提示符200 epoch,其中批大小设置为32。初始学习率设置为0.003,并使用余弦退火规则进行衰减。对于VisDA-2017,使用ResNet-101作为图像编码器,利用预训练的CLIP模型获得结果。图像和文本编码器的参数是固定的,使用32个批次的小批量SGD优化器训练提示符25个epoch。最初将学习率设置为0.003,并使用余弦退火规则进行衰减。对于超参数,上下文令牌M1和域特定令牌M2的长度都设置为16。令牌号的其他选择将在第4.3节中讨论。上下文向量使用标准偏差为0.02的零均值高斯分布随机初始化。Office-Home的伪标记阈值τ设置为0.6,VisDA-2017设置为0.5。关于τ值的进一步讨论见第4.3节。
4.2 实验结果

4.3 消融实验
消融:特定于领域的上下文。为了证明领域特定上下文的有效性和必要性,比较了以下提示设置在VisDA-2017数据集上的性能:
(1)手动设计提示“一张[CLASS]的照片”作为基线;
(2)统一上下文形式的领域不可知论提示(如式(3)所示);
(3)特定类别语境形式的领域不可知论提示;
(4)领域不可知论提示,其形式为与领域特定上下文统一的上下文(如式(4)所示);
(5)领域不可知提示,其形式为类特定上下文和领域特定上下文(如Eq.(5)所示)。

消融:上下文令牌长度。在表4中进行实验,探索上下文令牌长度的影响。
与领域无关和特定于领域的上下文令牌的长度分别用M1和M2表示。从结果可以看出,当M1 < M2时,性能稍低。总的来说,令牌长度对本文方法的性能影响很小。这意味着可以用少量的标记来学习连续表示。

消融:伪标签阈值。在表5中,给出了本文方法对超参数τ的灵敏度,范围从0.4到0.7。由于伪标签的质量和数量之间的权衡,本文方法似乎对τ不敏感。例如,当τ为0.7时,训练模型的伪标签更少,但置信度更高,伪标签的质量可以弥补数量减少带来的性能下降。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解决json.decoder.JSONDecodeError: Extra data: line 1 column 721 (char 720)问题
- 优思学院|为什么精益生产在你的企业就不管用呢?
- 搜索二叉树(BSTree)
- 有没有手机就能操作的视频下载工具?
- POJ3061找到连续子串长度最小值
- 使用Shopee买家通系统能带来哪些好处
- Java操作windows系统功能(二)
- 元旦佳节不整两句,都不好意思在朋友圈混了
- 代码随想录27期|Python|Day18|二叉树|路径总和i&ii|找树左下角的值|从中序与后序遍历序列构造二叉树
- bean的作用范围