搭建自动化 Web 页面性能检测系统 —— 设计篇
 ?
?
页面性能对于用户体验、用户留存有着重要影响,当页面加载时间过长时,往往会伴随着一部分用户的流失,也会带来一些用户差评。性能的优劣往往是同类产品中胜出的影响因素,也是一个网站口碑的重要评判标准。
一、名称解释
前端监控一般分为合成监控和真实用户监控。
1.1、合成监控
合成监控就是模拟用户的使用场景,访问一个页面,通过一些工具和规则去检测页面,提取一些性能指标,生成一份检测报告,注重检测。
合成监控的优缺点:
| 优点 | 缺点 |
|---|---|
| 实现简单,社区方案成熟 | 配置复杂,不能完全还原用户真实场景 |
| 能采集到更丰富的数据 | 登录等场景需要单独处理 |
| 不影响真实用户的页面访问性能 | 单次检测数据不够准确 |
1.2、真实用户监控

真实用户监控是指用户在页面上访问,访问时会产生各类性能数据,在用户访问停止的时候,将这些性能数据传输到服务端,进行数据整理分析的过程,注重监控。
真实用户监控的优缺点:
| 优点 | 缺点 |
|---|---|
| 完全还原用户真实场景 | 对用户的访问性能有一定影响 |
| 登录等场景无需单独解决 | 无法采集完整的资源加载瀑布图 |
| 数据样本足够大且真实,数据价值高 | 无法可视化展示页面加载过程 |
1.3、定义合适的性能指标
- 首次内容渲染时长(First Contentful Paint, FCP)
页面最新出现的内容渲染时长 - 首次展现平均值(Speed Index, SI)
页面内容可见填充的速度 - 最大内容绘制时间(Largest Contentful Paint, LCP)
页面核心内容呈现时间,不采用 loading 状态的数据 - 可交互时间(Time to Interactive, TTI)
用户是否会体验到卡顿 - 总阻塞时间(Total Blocking Time, TBT)
主线程被阻塞的时间,无法作出输入响应 - 累计布局样式偏移(Cumulative Layout Shift, CLS)
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:691998057【暗号:csdn999】
二、为什么做
基于需要对公司的 Web 产品进行性能优化,在做性能优化的同时,优化的衡量标准也不可或缺。在页面开发时观察页面的性能并不够准确,因为不同的开发设备性能表现不同,所伴随的变量也较多,不能够准确的反映性能优化效果,也无法观察产品的性能变化趋势。为什么自研呢,自研有以下好处:
(1)借助第三方的性能检测服务往往不能保证检测数据的安全性。
(2)第三方的性能检测服务一般无法与公司内部系统打通流程,一般无法自动化检测公司内部产品。
(3)可以做一些自定义开发,比如根据产品特点调整不同的性能指标权重,从而更准确的计算分数。
那么在检测收集到了这么多的指标数据后,页面性能到底如何呢,如果你的老板问你公司的产品页面性能如何,你该如何回复呢?假设列举一大堆时间指标、偏移量等数据,老板看到这些数值的时候可能就是一头雾水,根本理解不了产品的页面性能到底如何。那么自研可以针对产品类型,给出一个统一的标准,这样就方便去对比各个产品的性能表现了。
三、怎么做
3.1、基础依赖
下面是检测系统的整体架构:

这里设计的性能检测系统主要包含前端页面和服务端,其中:
前端页面展示性能检测入口、检测结果、性能趋势、性能排行榜等。
服务端基于 Nestjs + Lighthouse + Puppeteer 实现,通过 Typeorm 操作 MySQL 数据库,记录和查询性能检测数据。
另外辅助一些插件进行定时监测、结果通知等操作,实现自动化检测,相比页面开发时通过开发者工具中的 Lighthouse 检测有以下好处:
(1)不用开发者主动触发;
(2)不会阻塞开发过程,无需等待;
Lighthouse 用于检测 Web 网页的性能,主要基于 4 个主要步骤实现,分别是交互驱动、性能数据收集、审计整理以及记录。具体为:
(1)用户在性能检测入口输入待检测的页面地址,点击开始检测,页面通过接口调用性能检测服务
(2)Lighthouse 遍历当前页面的收集器方法并合成一个总的收集器方法以便于采集数据
(3)对上述采集到的性能数据进行计算和评分
Lighthouse 主要提供六个收集器,通过以下六个收集器即可采集到和实际访问接近的性能数据,每个收集器的功能不一,如下:
(1)收集 DOM 元素相关数据、DOM 节点最大深度、滚动条等
(2)收集页面内的所有图片资源,并记录下每个图片元素的宽高和定位等属性
(3)收集相关指标,如:FCP、LCP、CLS 等
(4)收集 JS 事件监听数量、JS 堆栈等
(5)收集页面的所有请求,包括状态码、请求头、响应头、请求方式等
(6)收集 window.performance 下的性能数据,用于计算加载时间
Puppeteer 是 Chrome 团队提供的一个无界面 Chrome 工具,俗称无头浏览器,通过提供的 API 可以控制 Node 端的 Chrome 工具进行指定的操作。在这里设计的性能检测系统中,由于 Lighthouse 进行检测时打开的类似于无痕窗口,没有登录信息,所以 Puppeteer 主要帮助我们实现模拟登录。
当检测页面需要登录时,分析出页面属于哪个 devops 实例,然后通过 Puppeteer 跳转到对应的登录页面,然后输入用户名、密码、验证码,待登录完成后跳转至正确的页面,再进行页面性能检测。如果登录后还在登录页,表示登录失败,则获取错误提示并抛出。
以下是检测系统的一个流程图:

3.2、关键代码
// 开始检测
async run(urlDto: UrlDto): Promise<object> {
const start = new Date().getTime();
try {
const { url, loginUrl } = urlDto;
const needLogin = url.includes('devops') || loginUrl;
console.log(`本次检测${needLogin ? '' : '不'}需要登录`, url);
const runResult = needLogin
? await this.withLogin(urlDto)
: await this.withOutLogin(url);
// 保存检测结果文件,便于预览
const urlStr = url.replace(/http(s?):\/\//g, '').replace(/\//g, '');
fs.writeFileSync(`./static/${urlStr}-report.html`, runResult?.report);
// 性能数据
const performance = runResult?.lhr?.categories?.performance || {};
const data = {
...performance,
auditRefs: performance?.auditRefs?.filter((item) => item.weight),
};
// console.log(data);
console.log(`本次耗时:${((new Date().getTime() - start) / 1000).toFixed(2)}s`);
return {
code: 200,
data,
message: `耗时:${((new Date().getTime() - start) / 1000).toFixed(2)}s`,
};
} catch (error) {
return {
code: 401,
message: error,
};
}
}
3.3、检测规则
系统除了支持手动输入网页地址检测,也支持自动检测。为了便于统计每个子产品的真实表现,每天凌晨自动检测 10 次,去掉最高分,去掉最低分,从其余分数中选择中位数作为每天的检测评分。
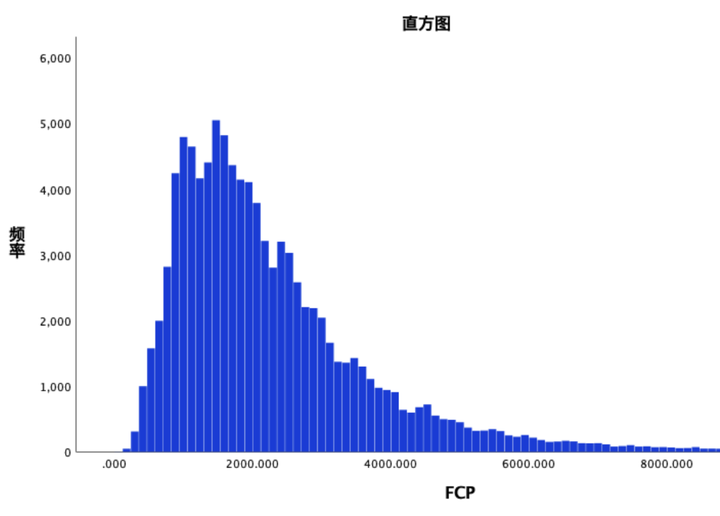
性能检测时的数据采集可能因为网页服务的不稳定性,导致有偏大或偏小的数据,所以提供某个时间段某个指标的直方图来分析数据的基本特征。也会提供某个产品的整体分数趋势,便于统计某个时间段内该产品的性能变化,也可以提现性能优化前后的效果。
四、写在后面
这篇文章简单介绍了下该性能检测系统的初步设计、一些页面性能的概念以及采用的技术点,后续请关注《搭建自动化 Web 页面性能检测系统 —— 实践篇》。
各位朋友如果有关性能测试的任何问题,欢迎文章后留言,谢谢。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【VulnHub靶场】medium_socnet
- 解决律所管理四大难题,Alpha法律智能系统收获用户好评
- 四种自动化测试模型实例及优缺点
- C++继承与派生——(2)派生类
- 《整机柜服务器通用规范》由OCTC正式发布!浪潮信息牵头编制
- springboot 集成websocket
- 016、简单控制流if let
- Mysql索引 大分析!!!!!!!!!!!!!!!!!!!
- 2024安卓岗位面试题总结
- 软件测试|Django 入门:构建Python Web应用的全面指南