关于Redis面试题
前言
之前为了准备面试,收集整理了一些面试题。
本篇文章更新时间2023年12月27日。
最新的内容可以看我的原文:https://www.yuque.com/wfzx/ninzck/cbf0cxkrr6s1kniv
Redis
是什么
全名:远程字典服务。这是一个开源的在内存中的数据结构存储系统,可以用作数据库、缓存、消息中间件。
应用场景

在统计方面的场景

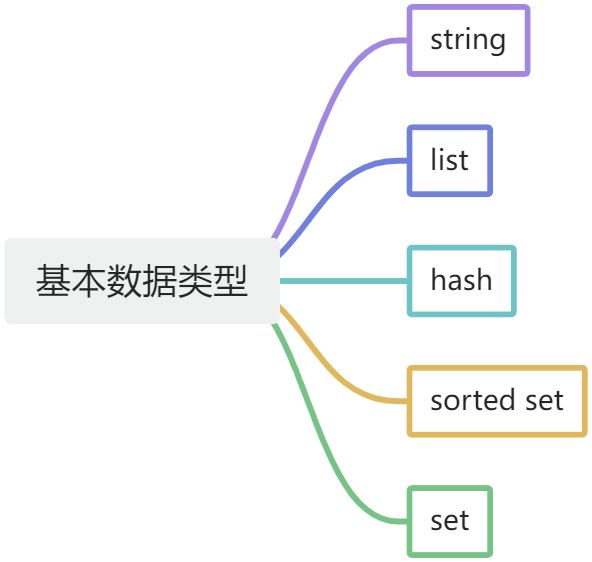
有哪些基本数据类型?
有哪些底层数据结构?

sorted set为什么使用跳表而不是平衡树?
首先,跳表实现起来比平衡树简单,插入、删除操作不需要进行平衡,所以性能也比平衡树好些;
其次,从空间效率的角度来看,跳表的索引占用的空间更加少一点,而平衡树还要在在每个节点维护平衡因子;
然后,还有就是并发度,跳表的插入、删除操作,只需要修改相邻节点的指针即可,平衡树还需要调整多个节点,所以,跳表可以支持更多的同时进行修改。

压缩列表的结构
由头部、数据中部、以及一个结尾符号组成。
头部内容包括 压缩列表大小、尾节点的偏移量、数据条目的个数。
谈谈redis的对象机制(redisObject)
redisObject是一个通用的基础结构,可以统一的表示各种数据类型,降低复杂度;
同时,配合共享内存池,可以复用redisObject对象,减少内存分配,避免构造对象的开销。
其中,它的结构主要由两大部分组成:元数据 + 数据的指针或实际数据值。
元数据就包括 数据类型type、底层树结构encoding、最后一次被访问时间lru,以及引用计数refcount。

处理问题思路导图

为什么要设计sds?
回答这个问题之前,先简单说明一下sds的数据结构,数据结构包括三个属性:记录空闲空间的free,记录当前内容长度的length、以及存储数据的buf数组。


数据结构有哪些
五种数据类型:string、list、sorted set、set、hash
其它数据结构:HyperLogLog、Geo、、Push/sub
其它的还有Redis Moudle、BloomFilter等
单线程还是多线程
Redis6.0+
读写还是单线程(主线程),处理网络请求、结果回写用多线程处理(IO线程并行处理,处理期间主线程阻塞)。
聊聊持久化机制
RDB+AOF
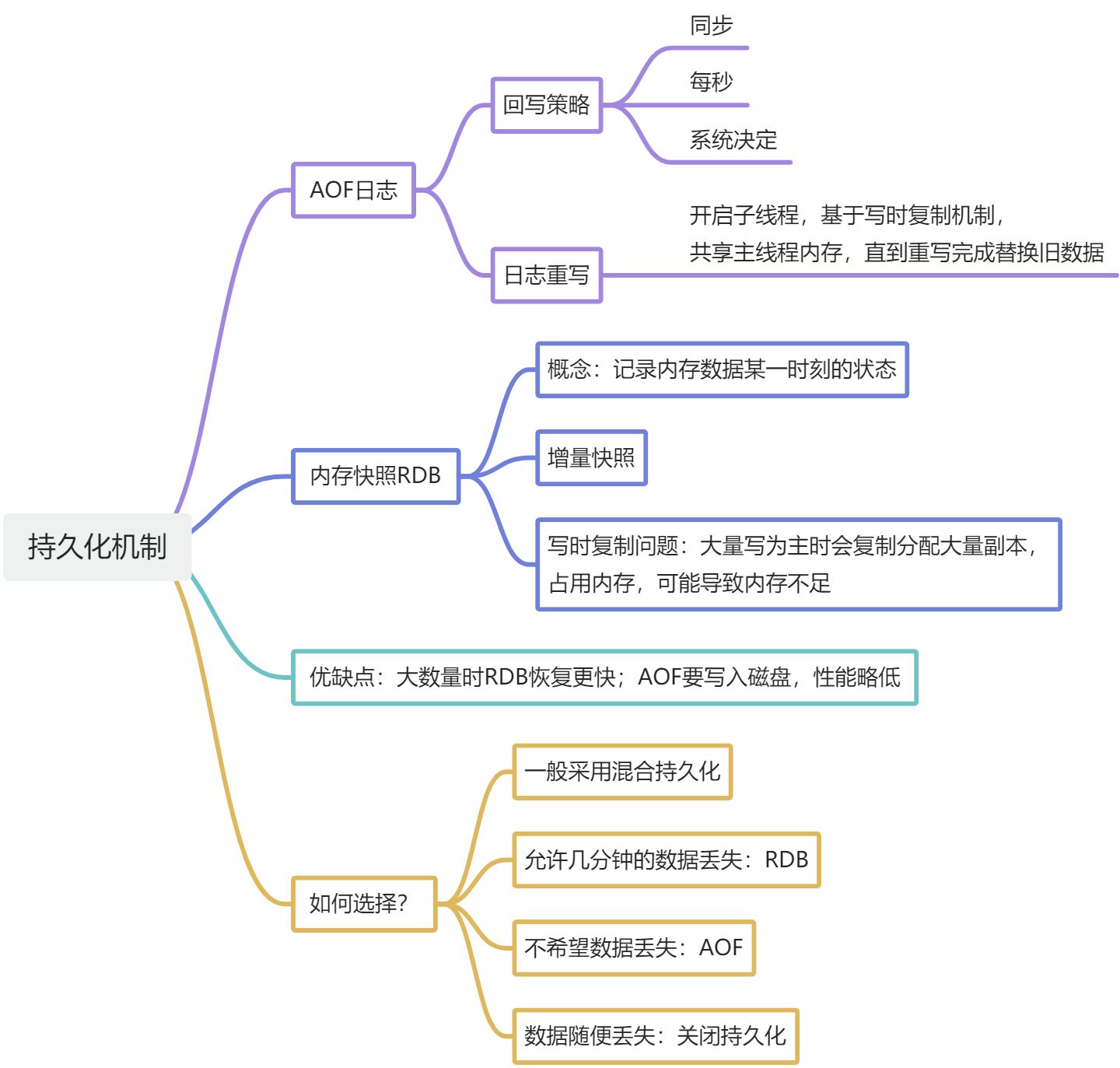
说一下 Copy On Write 技术
多个线程共享内存资源,当发生修改的时候,就复制一份出来。
Redis在使用RDB进行持久化的时候,会fork一个子线程执行持久化工作,子线程跟主线程共享内存,子线程遍历读取数据写入到磁盘,如果数据发生改动,主线程会先复制一份再修改。
缓存淘汰策略
细分的话有8种。
根据情况大体可以分为两类,一类是针对过期的key,另一类是内存满的时候触发。
更具体一点的话,就有随机淘汰、最近最久未使用的、最近最少使用、比较早过期的


MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如 何保证 redis 中的数据都是热点数据?
核心思想是LRU:最近最少使用。
将非热点数据淘汰掉。
具体的策略包括针对过期的key进行被动淘汰的策略、以及主动进行缓存淘汰的策略。
假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以 某个固定的已知的前缀开头的,如果将它们全部找出来?
scan指令
如何应对Redis变慢
预防:避免单线阻塞操作
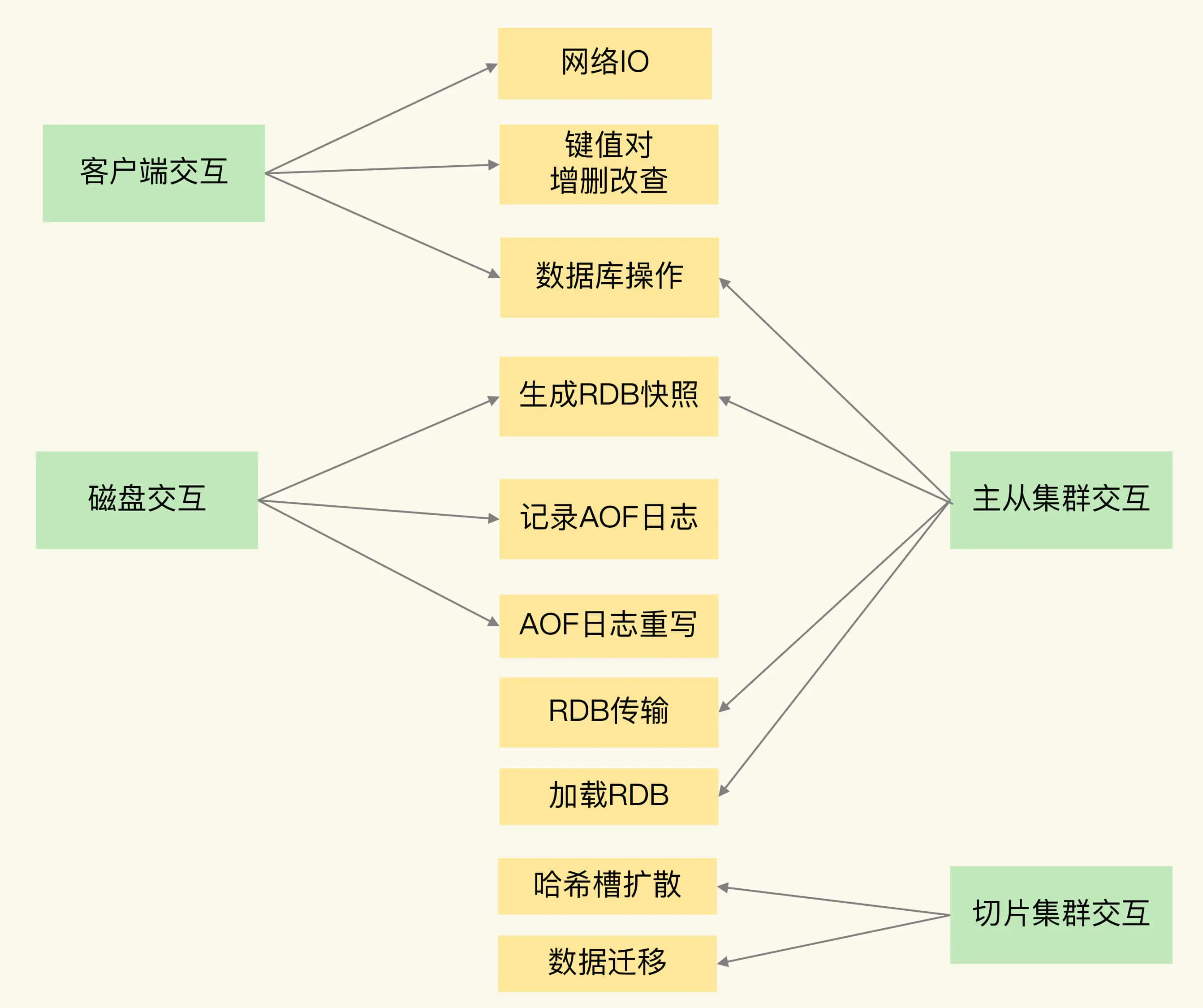
- 大key操作、释放大量内存、聚合计算等
- 生成快照、AOF刷盘
- 集群之间传输、加载快照
- 数据迁移
硬件:CPU结构对性能的影响
观察上下文切换情况:绑核减少切换次数。
在一些处理器架构下,考虑把网络中断程序核Redis主线程绑在一个CPU:避免远端内存访问
注意避免主线程跟子线程竞争CPU。
是否真的变慢了?
使用redis-cli --latency -h host -p port指令查看最大延迟。
真的慢了!重点三个方面入手
- 自身特性:注意指令的一个时间复杂度、避免大面积key过期
- 文件系统:避免虚拟内存交换
- 操作系统:可以考虑关闭内存大页,避免修改10b数据就要拷贝2M内存也的情况
Redis事务的三个阶段
开启事务、加入命令、执行事务
Redis为什么不支持回滚
从设计层面来看,这个可以让redis更简单快速;
对于开发者来说,语法错误的问题应该在开发中就要发现,而不是在生产环境发生。
Redis key 的过期时间和永久有效分别怎么设置?
默认过期。
如果设置了过期时间,想要设置为永久,可以使用PERSIST命令。
主从库网络断开了怎么办?
从库发送同步(psync)命令给主库,主库会对照当前offset,判断进行全量同步还是增量同步。
Redis 1主4从,5个哨兵,哨兵配置quorum为2,如果3个哨兵故障,当主库宕机时,哨兵能否判断主库“客观下线”?能否自动切换?
能判定客观下线,但是不能进行自动切换。
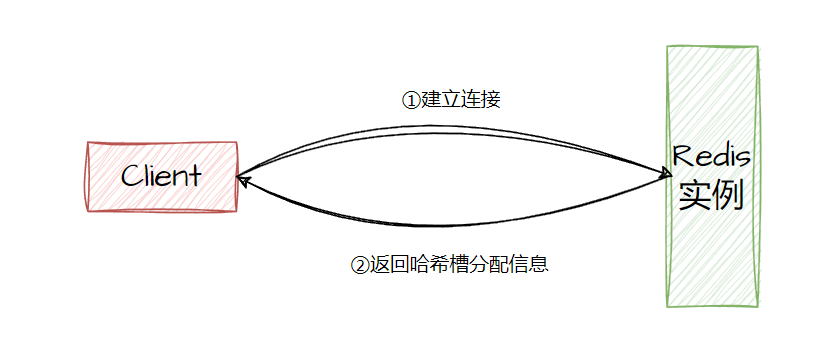
说说Redis哈希槽的概念?
随着数据量的增加,我们进行一些阻塞主线程的一些操作的时候,操作带来的影响就会越来越明显,比如RDB持久化操作,所以,这时候我们可能需要进行扩展,对数据进行切片,将数据分散到不同的实例上,在这方面,官方提供了redis cluster方案。
redis cluster采用了哈希槽,处理数据和实例之间的映射关系。
客户端在跟集群建立连接的时候,会拿到槽的分配信息,通过计算key映射到那个槽,来定位要发送的实例。
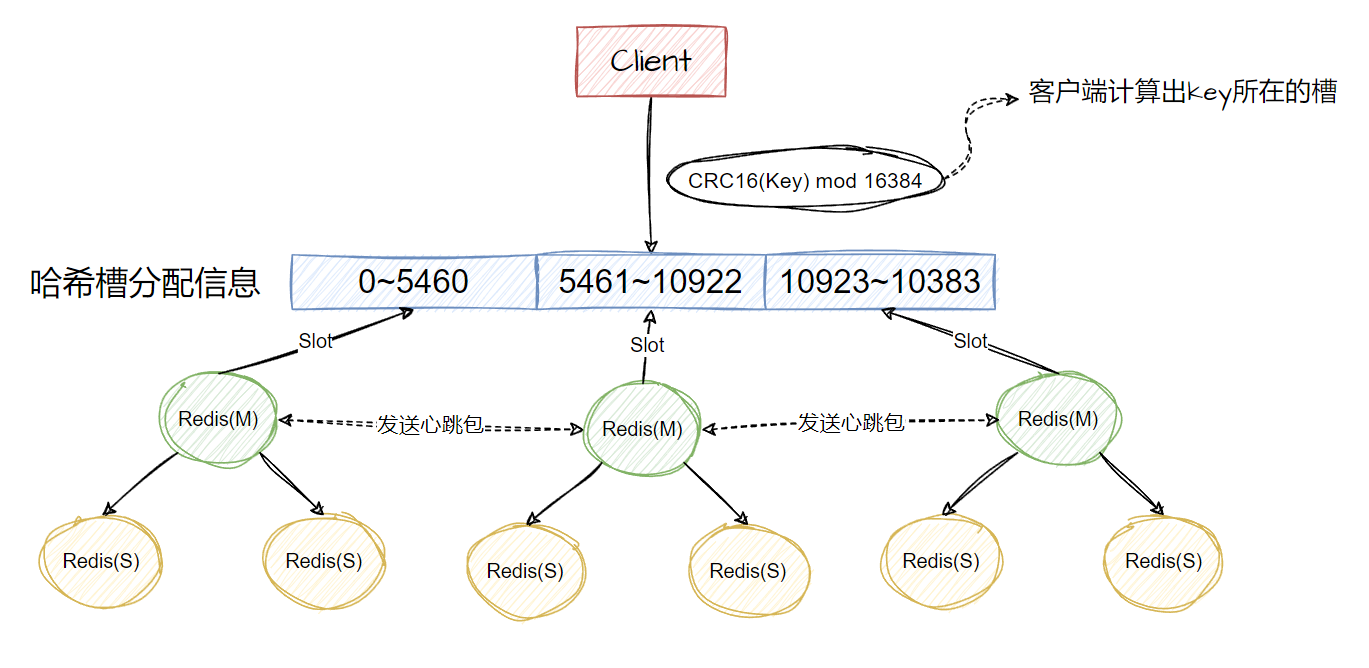
为什么是16384个?
设计这从两个方面回答了这个问题:
- 降低消息大小:一万六千多个槽,心跳包大小为2K,相比与6万多的槽,小很多,可以节省带宽。
- 集群规模设计考虑:集群最多支持1000个分片,假如1万六千个槽在分配均匀的情况下,分片平均分到的槽不至于太小。
Redis集群会有写操作丢失吗?为什么?
会丢失,Redis不保证强一致性。

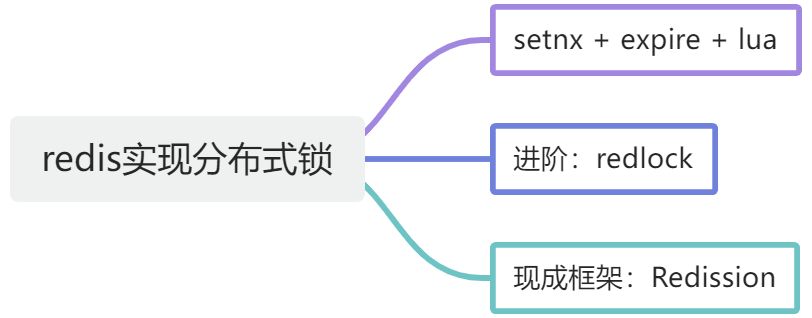
redis实现分布式锁实现?RedLock?
SETNX:key不存在时设置key,成功则返回1。
RedLock:想集群多个节点请求获取锁,当半数节点成功获取到锁时,才算获取锁成功。
redis缓存有哪些问题,如何解决?
redis和其它数据库一致性问题如何解决?

主从数据不一致问题?
问题:主库修改了key,从库没有及时更新。
原因:由于网络延迟、从库在执行高复杂命令等。
处理:外部程序监控复制进度、保证网络通常。
主从模式下在从库读到过期数据
升级版本、设置一个过期时间为一个具体的时间点。
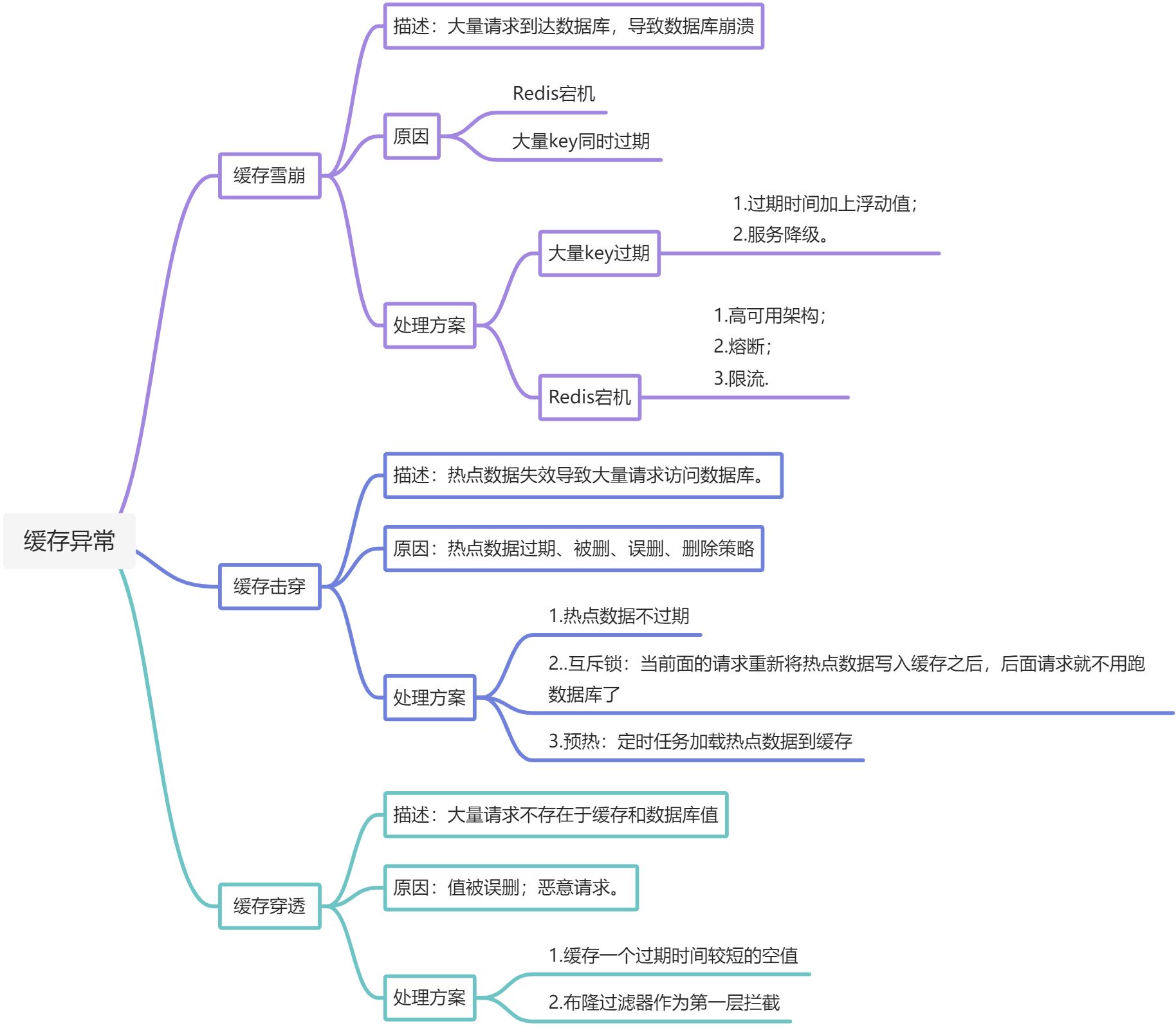
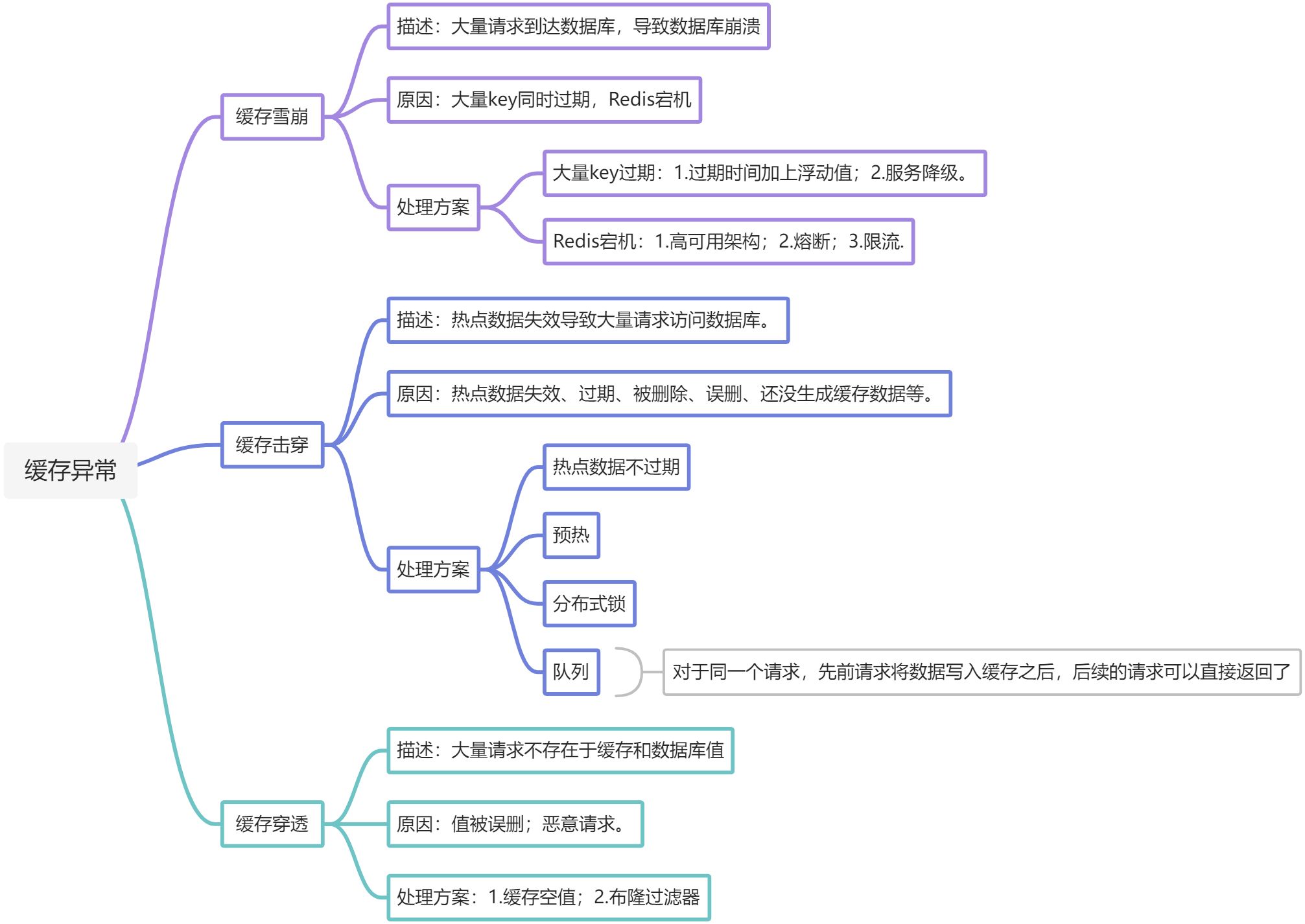
缓存问题:雪崩、击穿、穿透
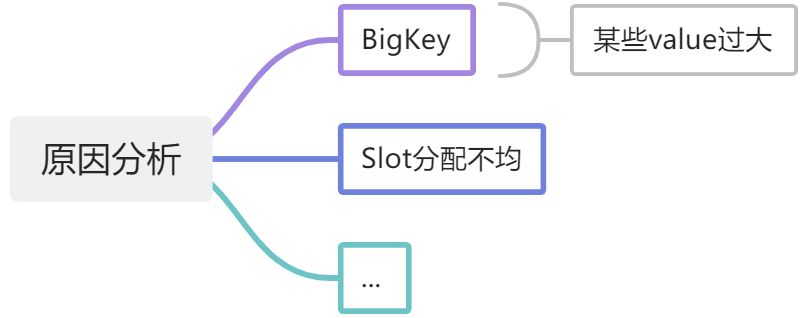
数据量倾斜问题
原因分析
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 智慧用电,同为云(TOWE Cloud)平台为机房供配电提供数字化赋能
- Python 直方图的绘制-`hist()`方法(Matplotlib篇-第7讲)
- 如何给NVIDIA JetsonOrin Nano开发套件安装CSI摄像头
- 在 Centos 7.9 中,安装与配置 Docker 20.10.18
- GBASE南大通用分享,关于BEGIN WORK 的示例
- 深耕汽车检测设备领域,引领行业技术革新
- 全景叙事定位 Towards Real-Time Panoptic Narrative Grounding by an End-to-End Grounding Network 论文阅读笔记
- 【开题报告】基于SpringBoot的茶文化宣传网站设计与实现
- 自动化运维平台Spug本地部署结合内网穿透实现远程访问
- 【51单片机】IO 扩展(串转并)--74HC595