植物分类-PlantsClassification
一、模型配置
一、backbone
resnet50
二、neck
GlobalAveragePooling
三、head
fc
四、loss
type=‘LabelSmoothLoss’,
label_smooth_val=0.1,
num_classes=30,
reduction=‘mean’,
loss_weight=1.0
五、optimizer
lr=0.1, momentum=0.9, type=‘SGD’, weight_decay=0.0001
六、scheduler
T_max=260, begin=20, by_epoch=True, end=300, type='CosineAnnealingLR
七、evaluator
topk=(1, 5 ), type=‘Accuracy’
八、max_epochs
300
九、Config
auto_scale_lr = dict(base_batch_size=256)
data_preprocessor = dict(
mean=[
123.675,
116.28,
103.53,
],
num_classes=30,
std=[
58.395,
57.12,
57.375,
],
to_rgb=True)
dataset_type = 'ImageNet'
data_root = 'data/PlantsClassification'
default_hooks = dict(
checkpoint=dict(interval=1, type='CheckpointHook', max_keep_ckpts=2, save_best="auto"),
logger=dict(interval=100, type='LoggerHook'),
param_scheduler=dict(type='ParamSchedulerHook'),
sampler_seed=dict(type='DistSamplerSeedHook'),
timer=dict(type='IterTimerHook'),
visualization=dict(enable=False, type='VisualizationHook'))
default_scope = 'mmpretrain'
env_cfg = dict(
cudnn_benchmark=False,
dist_cfg=dict(backend='nccl'),
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0))
launcher = 'none'
load_from = './work_dirs/resnet50_8xb32-coslr_in1k/resnet50_8xb32_in1k_20210831-ea4938fc.pth'
log_level = 'INFO'
model = dict(
backbone=dict(
depth=50,
num_stages=4,
out_indices=(3,),
style='pytorch',
type='ResNet'),
head=dict(
in_channels=2048,
# loss=dict(loss_weight=1.0, type='CrossEntropyLoss'),
loss=dict(
type='LabelSmoothLoss',
label_smooth_val=0.1,
num_classes=30,
reduction='mean',
loss_weight=1.0),
num_classes=30,
topk=(
1,
5,
),
type='LinearClsHead'),
data_preprocessor=data_preprocessor,
neck=dict(type='GlobalAveragePooling'),
type='ImageClassifier')
train_cfg = dict(by_epoch=True, max_epochs=300, val_interval=1)
optim_wrapper = dict(
optimizer=dict(lr=0.1, momentum=0.9, type='SGD', weight_decay=0.0001))
param_scheduler = dict(
T_max=260, begin=20, by_epoch=True, end=300, type='CosineAnnealingLR')
randomness = dict(deterministic=False, seed=None)
resume = False
test_cfg = dict()
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(edge='short', scale=256, type='ResizeEdge'),
dict(crop_size=224, type='CenterCrop'),
dict(type='PackInputs'),
]
test_dataloader = dict(
batch_size=32,
collate_fn=dict(type='default_collate'),
dataset=dict(
data_root=data_root,
pipeline=test_pipeline,
split='test',
ann_file='test.txt',
type=dataset_type),
num_workers=1,
persistent_workers=True,
pin_memory=True,
sampler=dict(shuffle=False, type='DefaultSampler'))
test_evaluator = dict(
topk=(
1,
5,
), type='Accuracy')
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(scale=224, type='RandomResizedCrop'),
dict(direction='horizontal', prob=0.5, type='RandomFlip'),
dict(type='PackInputs'),
]
train_dataloader = dict(
batch_size=45,
collate_fn=dict(type='default_collate'),
dataset=dict(
data_root=data_root,
pipeline=train_pipeline,
split='train',
ann_file='train.txt',
type=dataset_type),
num_workers=1,
persistent_workers=True,
pin_memory=True,
sampler=dict(shuffle=True, type='DefaultSampler'))
val_cfg = dict()
val_dataloader = dict(
batch_size=45,
collate_fn=dict(type='default_collate'),
dataset=dict(
data_root=data_root,
pipeline=test_pipeline,
split='val',
ann_file='val.txt',
type=dataset_type),
num_workers=1,
persistent_workers=True,
pin_memory=True,
sampler=dict(shuffle=False, type='DefaultSampler'))
val_evaluator = test_evaluator
vis_backends = [
dict(type='LocalVisBackend'),
]
visualizer = dict(
type='UniversalVisualizer', vis_backends=[
dict(type='LocalVisBackend'),
])
work_dir = './work_dirs\\resnet50_8xb32-coslr_in1k'
二、训练结果
采用kaggle植物分类数据集,30分类,标签:
IMAGENET_CATEGORIES = [‘aloevera’, ‘banana’, ‘bilimbi’, ‘cantaloupe’, ‘cassava’, ‘coconut’, ‘corn’, ‘cucumber’,
‘curcuma’, ‘eggplant’, ‘galangal’, ‘ginger’, ‘guava’, ‘kale’, ‘longbeans’, ‘mango’, ‘melon’,
‘orange’, ‘paddy’, ‘papaya’, ‘peperchili’, ‘pineapple’, ‘pomelo’, ‘shallot’, ‘soybeans’,
‘spinach’, ‘sweetpotatoes’, ‘tobacco’, ‘waterapple’, ‘watermelon’]
“accuracy/top1”: 90.00000762939453, “accuracy/top5”: 98.0666732788086
三、结果分析
分析分类结果发现,更改不同的训练策略,结果不会增加,且总有个别类别分类错误,仔细分析数据发现,引起该问题的主要原因是数据集本身引起的,在个别类别中混入了其他类别的图片,甚至出现两个类别使用的数据完全一致的情况,比如melon和cantaloupe使用的是相同的数据集,且内部混入了西瓜的数据集
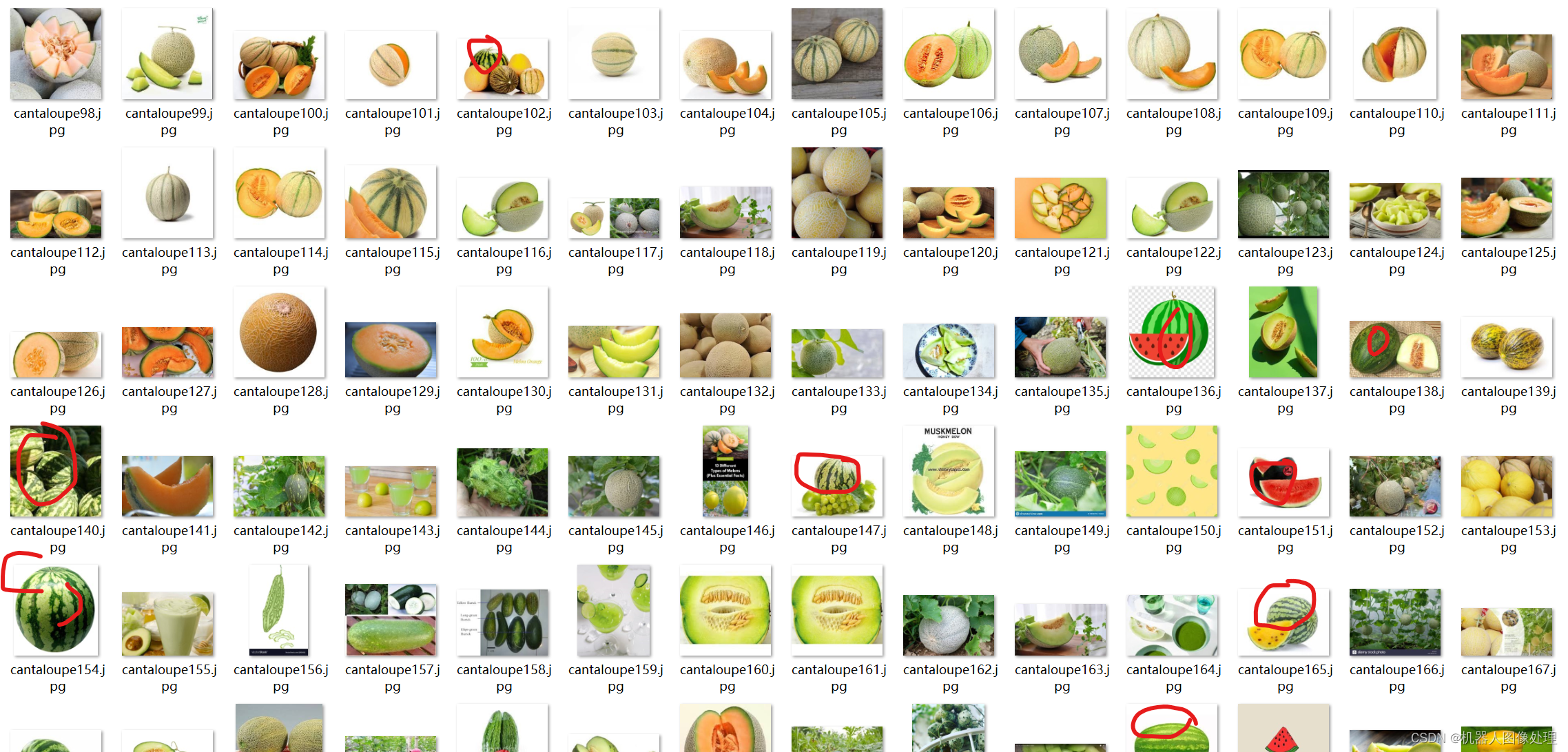
四、预测测试
























五、总结
在训练前,必须检查数据集
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!