吃瓜教程Task1:概览西瓜书+南瓜书第1、2章
发布时间:2024年01月18日
由于本人之前已经学习过西瓜书,本次学习主要是对以往知识的查漏补缺,因此本博客记录了在学习西瓜书中容易混淆的点以及学习过程中的难点。更多学习内容可以参考下面的链接:
南瓜书的地址:https://github.com/datawhalechina/pumpkin-book
【视频链接】https://www.bilibili.com/video/BV1Mh411e7VU?p=1
绪论
如何对机器学习任务进行分类?
- 按标记的取值类型分:回归(连续)和分类(离散)
- 按是否用到标记信息分:有有监督学习(有标记)和无监督学习(无标记)
归纳偏好的意义?
- 机器学习算法在学习过程中对某种类型假设的偏好。
- 任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上“等效”的假设所迷惑,而无法产生确定的学习结果。
- 归纳偏好对应了学习算法本身所做出的关于“什么样的模型更好”的假设。在具体的现实问题中,这个假设是否成立,即算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能。
没有免费的午餐定理(NFL)
众算法生而平等
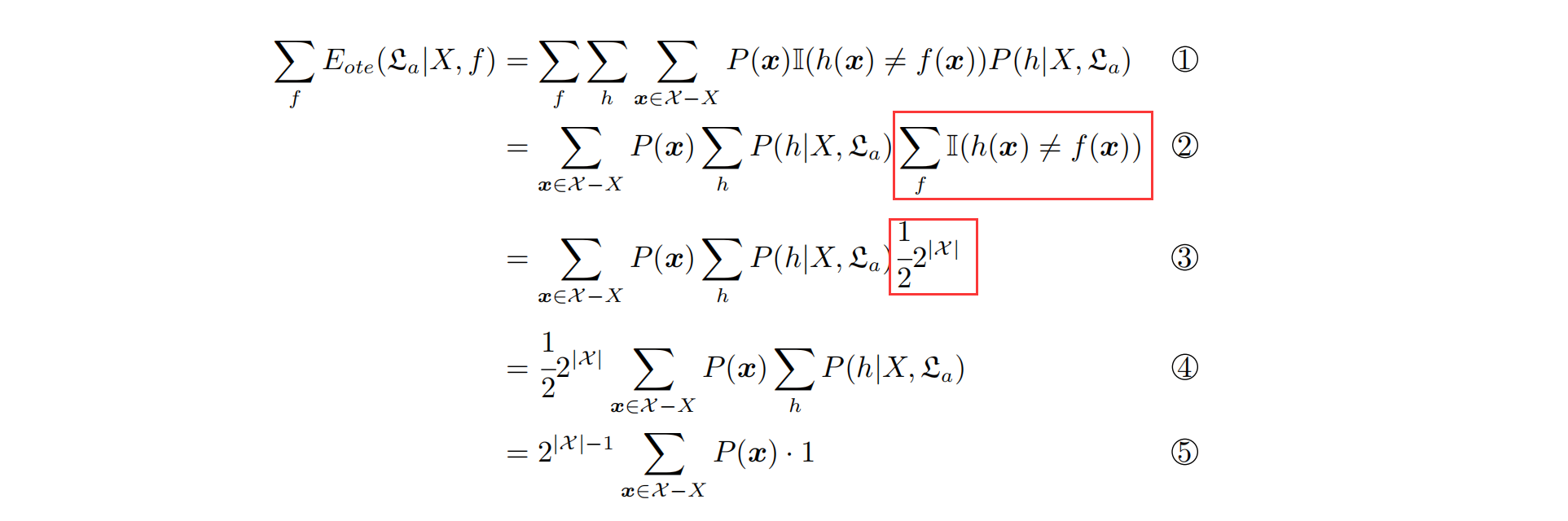
实际应用:哪个算法训出来的模型在测试集上表现好哪个算法就nb
数据决定模型的上限,而算法则是让模型无限逼近上限
- 数据决定模型效果的上限:其中数据是指从数据量和特征工程两个角度考虑。
- 从数据量的角度来说,通常数据量越大模型效果越好,因为数据量大即表示累计的经验多,因此模型学习到的经验也多,自然表现效果越好。
- 从特征工程的角度来说,通常对特征数值化越合理,特征收集越全越细致,模型效果通常越好,因为此时模型更易学得样本之间潜在的规律。
- 算法则是让模型无限逼近上限:是指当数据相关的工作已准备充分时,接下来便可用各种可适用的算法从数据中学习其潜在的规律进而得到模型,不同的算法学习得到的模型效果自然有高低之分,效果越好则越逼近上限,即逼近真相。
模型评估与选择
常见的性能指标有那些?
错误率、精度、查准率、查全率、F1、ROC和AUC
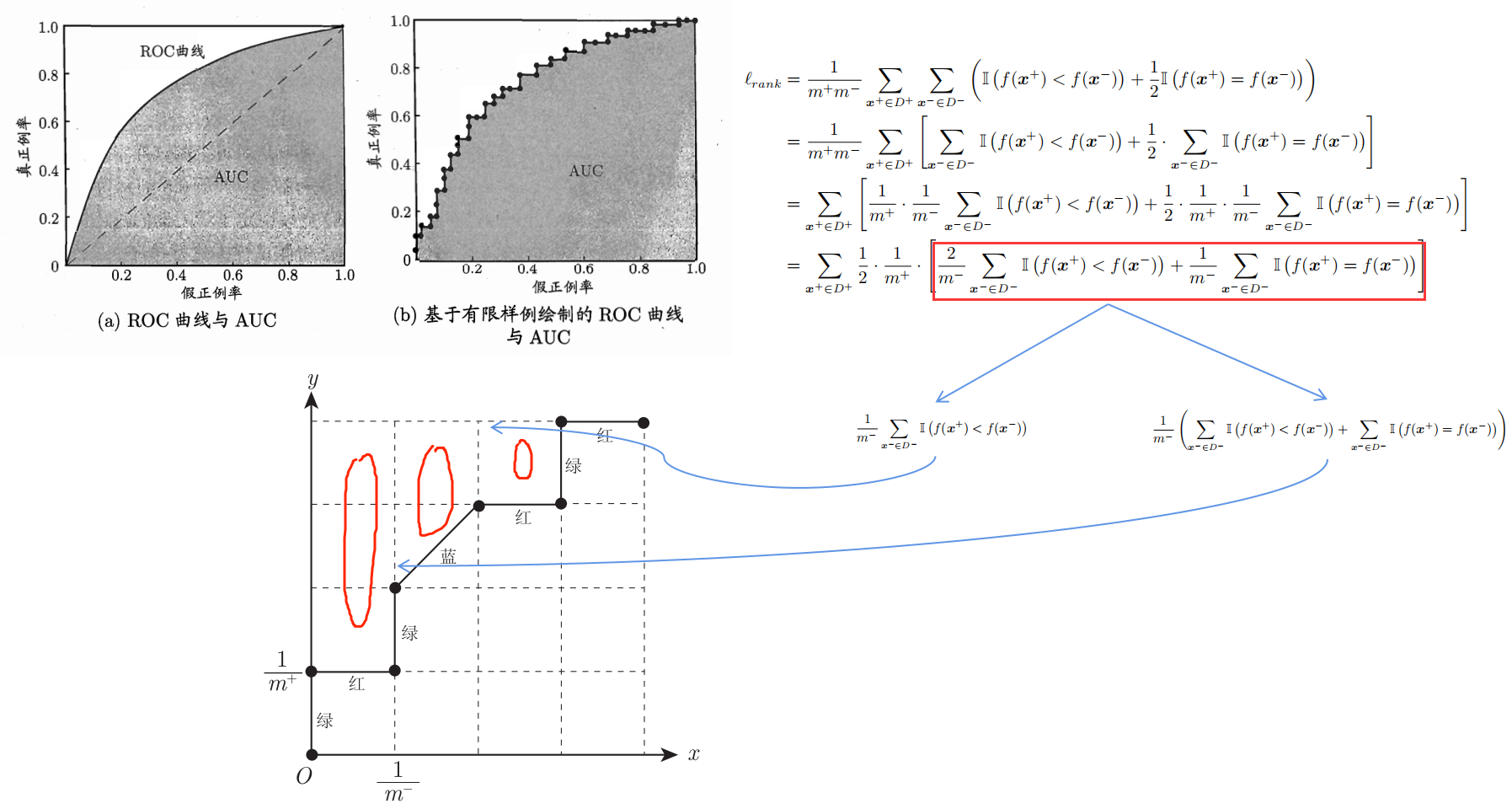
ROC曲线和AUC
与P-R曲线使用查准率、查全率为纵、横轴不同,ROC曲线的纵轴是“真正例率”(True Positive Rate,简称TPR),横轴是“假正例率”(False PositiveRate,简称FPR)。关键推导的理解如下,更多内容见西瓜书。
总结
本文主要记录了在复习西瓜书一二章过程中容易混淆的一些点。
文章来源:https://blog.csdn.net/qq_46378251/article/details/135655034
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据洞察力,驱动企业财务变革
- MySQL 的 ngram 全文解析器
- AGV小车磁导航传感器CNS-MGS-080N磁条布置方法
- Java使用Microsoft Entra微软 SSO 认证接入
- 【数据结构 — 排序 — 交换排序】
- shiro入门demo(三)认证+授权+拦截
- 全志F1C100s Linux 系统编译出错:不能连接 github
- 【精选】samba服务的下载和使用 (超详细)
- 分布式基础概念
- (2023,提示扩展,图像反演,文本到文本生成)自适应文本到图像生成的提示扩展