【课程笔记】深度学习网络 - 3 - GoogleNet
目录
(2)Inception_Auxiliary模块的设计与封装
〇、GoogleNet理论与背景
????????GoogleNet(也称为Inception v1)是由Google团队于2014年提出的深度卷积神经网络模型。
1、GoogleNet在当时的优越性
????????它的主要优越性和影响如下:
????????(1)较低的参数量和计算复杂度:GoogleNet引入了Inception模块,通过并行使用多个不同尺寸的卷积核和池化操作,减少了参数数量,从而减轻了过拟合的风险,并降低了模型的计算复杂度。
??????? (2)高效地解决了梯度消失问题:由于GoogleNet采用了大量的1x1卷积层,这些卷积层可以起到降维的效果,帮助传递梯度并缓解了梯度消失问题。
??????? (3)提供了一种模块化的网络设计思路:GoogleNet使用了Inception模块,将不同尺寸的卷积核和池化操作并行连接起来,形成了一种高度模块化的结构。这种设计思路使得网络可以在不同的深度和复杂度之间进行平衡调节。
2、GoogleNet提出时产生的影响
????????对深度学习领域的重要影响如下:
??????? (1)模型架构和设计思路的创新:GoogleNet的模块化设计启发了后续深度学习网络的设计,如ResNet、Inception系列等。这种模块化的思路为研究者们提供了更多的网络设计选择,并促进了模型的发展和改进。
??????? (2)推动了计算机视觉任务的研究:GoogleNet在当时在ImageNet图像分类和物体检测竞赛中取得了显著的成绩,证明了深度学习在计算机视觉任务上的优越性。这推动了计算机视觉领域的研究和发展,使深度学习成为计算机视觉任务的主流方法。
3、后续改进方案
????????GoogleNet的改进方案主要集中在进一步降低参数量和计算复杂度的同时提高性能。一些改进包括:
??????? (1)Inception v2/v3/v4:通过引入更多的1x1卷积层和优化Inception模块的结构,进一步降低了参数量和计算复杂度,并提高了网络的准确性。
??????? (2)Inception-ResNet:将ResNet的残差连接思想与Inception模块相结合,提出了Inception-ResNet模型,可以进一步加深网络的深度和增强特征提取能力。
??????? (3)使用辅助分类器:GoogleNet引入了辅助分类器来缓解梯度消失问题,并充分利用了网络中间层的特征,促进了模型的训练和收敛。
4、网络特征与创新点
??????? 【网络特征】

??????? 从最底层的输入开始,黄色代表了网络模型的输出,可以看出,整个网络模型的主干线有着大量重复的部分,一直到最后的黄色输出块,此外,中间也有两个输出块。
??????? 整个网络主干线上大量重复的部分(一共有9个,分别是Inception 3a/3b/4a/4b/4c/4d/4e/5a/5b),叫做Inception模块,其结构如下图,它对输入进来的数据进行4个分支的并行处理,最后叠加在一起作为下一层/模块的输入。
??????? 需要注意的是,Inception模块的输入和输出通道数必须一致。

??????? 以下是网络中各个部分的参数:
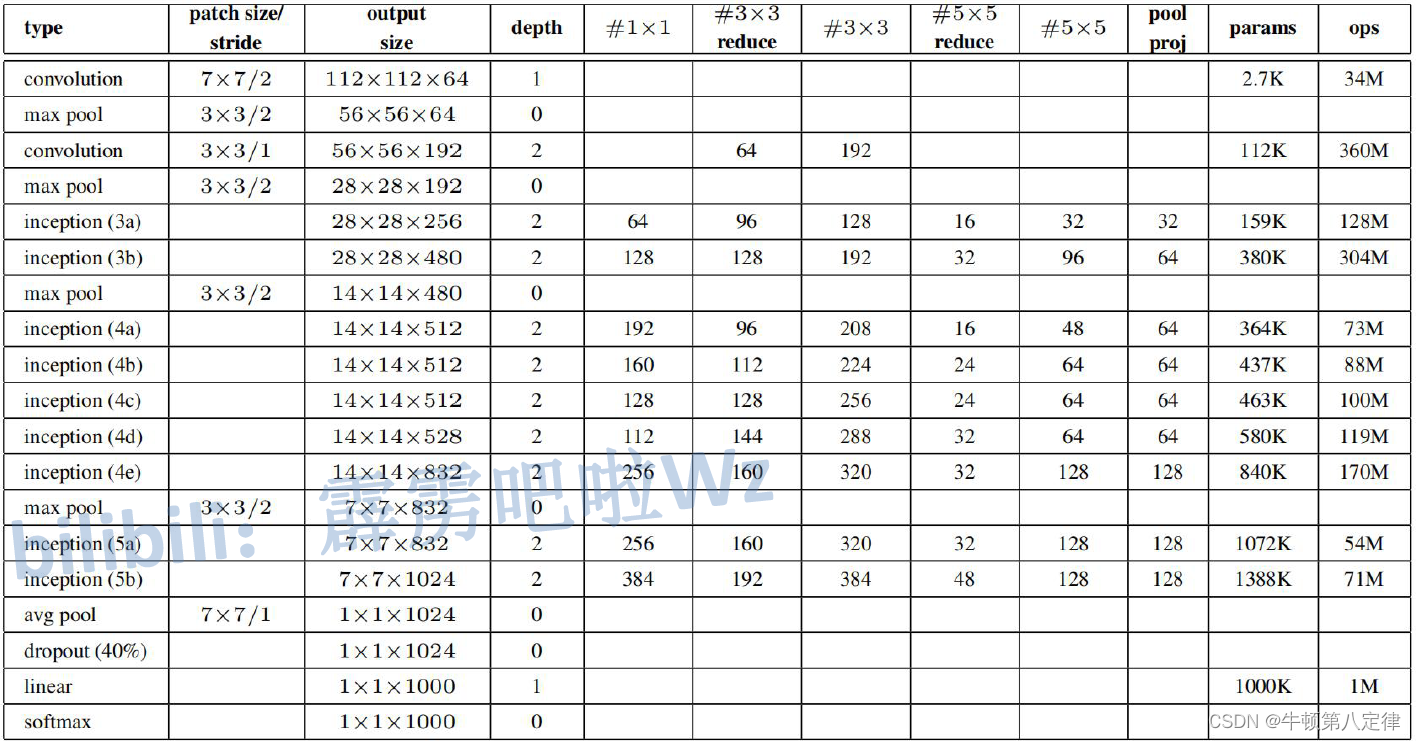
??????? 【创新点】
??????? 1、GoogleNet引入了Inception模块,通过并行使用多个不同尺寸的卷积核和池化操作,将不同尺度的特征图串联在一起。这种并行结构可以同时学习到不同感受野的特征,从而提高了网络对不同尺度目标的识别能力。
??????? 2、GoogleNet大量使用了1x1卷积层。1x1卷积层可以减少特征图的维度,降低计算复杂度,并且它能够起到非线性的作用,提升网络的表达能力。此外,1x1卷积层还可以帮助传递梯度,缓解梯度消失问题。以下是关于使用1*1卷积层使得参数计算量减小的示意图。


??????? 3、GoogleNet在网络的中间层引入了辅助分类器。辅助分类器可以在训练过程中提供额外的监督信号,帮助网络更好地学习特征表示,并缓解了梯度消失问题。此外,辅助分类器还可以在测试时起到正则化的作用,提高模型的泛化能力。

??????? 关于辅助分类器的参数结构:

??????? 4、通过使用Inception模块和1x1卷积层的结构,GoogleNet在保持模型性能的同时,有效地降低了参数量和计算复杂度。这使得GoogleNet可以在相对较低的计算资源下进行训练和推理。
??????? 5、不使用最大池化层,而使用平均池化层,基本上抛弃了全连接层,使得模型参数大大减少,具体表现在:
????????传统的卷积神经网络(CNNs)通常在卷积层之后使用全连接层来进行分类。全连接层会引入大量的参数,导致模型过于复杂和容易过拟合。为了解决这个问题,GoogleNet抛弃了全连接层,并将全局平均池化层(Global Average Pooling)用于最后一个卷积层的输出上。
????????在全局平均池化层中,将每个特征图的像素进行平均操作,将其转化为一个数值。这样,可以将整个特征图的信息压缩成一个固定维度的向量。通过这种方式,可以有效地减少参数数量,并且提高模型的泛化能力。
????????总的来说,GoogleNet的创新点主要体现在引入了Inception模块和大量的1x1卷积层,将不同尺度的特征进行并行处理,从而提高了网络的表示能力和识别能力。同时,通过优化参数量和计算复杂度,使得GoogleNet可以在资源有限的情况下进行高效的训练和推理。
??????? 关于GoogleNet的参数量问题,以VGGNet作为对比:


一、补充知识点
??????? 暂无补充
二、模型零件与封装
1、特征层的设计与封装(features)
(1)Inception模块的设计与封装
??????? 特征层由一大堆相同结构的Inception模块构成,并且在特定的地方还增设了两条辅助分类器,在中途给出了2个输出。所以我们需要先设计好Inception模块和辅助分类器,才能完整的把GoogleNet网络构建出来,以下就是对Inception模块的构建方法:
??????? 这是Inception模块的具体结构,可以看出有4条分支来处理输入(Previous Layer),这4条分支分别是:
??????? (1)单独的1*1卷积;
??????? (2)先1*1卷积,再3*3卷积;
??????? (3)先1*1卷积,再5*5卷积;
??????? (4)先3*3最大池化,再1*1卷积;
??????? 而且4条分支处理后得到的4个子输出,需要进行凑整操作为一个完整的输出,才能作为下一层 / 模块的输入。
??????? 另外,由于卷积层处理完毕后,需要进行激活层的处理,在图中没有显示,所以我们可以先封装一个小模块,这个小模块的作用就是把卷积层给定义出来,设置好属性,同时再设置一个激活层用于激活卷积层的输出。我们给这小模块命名为:BasicConv2d(意为基础卷积操作),这个模块需要给定输入输出的通道数。
# 1、对BasicConv2d零件的设计与封装:相当于把卷积层和激活层封装在一起
class BasicConv2d(nn.Module):
# 该零件的结构包含一个卷积层,一个激活层
def __init__(self, input_channels, output_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(input_channels, output_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
# 该零件对输入的处理是先进行卷积再进行激活
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x??????? 有了这个小模块后,剩下的操作就比较容易了,对各个分支来说:
??????? 分支1:一个小模块解决
??????? 分支2:两个小模块解决
??????? 分支3:两个小模块解决
??????? 分支4:一个最大池化层+一个小模块解决
??????? 我们开始构建Inception模块,该模块需要给定输入通道,输出通道,以及各层需要的输入通道数和输出通道数,靠近原始输入的层是(input_channels, xxx_reduce_channels),靠近最终输出的层是(xxx_reduce_channels, output_channels),所以:
??????? 分支1:只有1个模块,输入通道input_channels,输出通道conv1x1
??????? 分支2:有2个模块,都是由BasicConv2d构建,下层输入通道input_channels,输出通道conv3*3reduce;上层输入通道同下层输出通道,上层输出通道conv3*3
??????? 分支3:同分支2的配置方式
??????? 分支4:同分支1的配置方式,只是加了一个池化层
??????? 这样下来,一个Inception模块就定义好了,后续可以反复利用这个封装好的模块。
# 2、对Inception零件的设计与封装
# 该零件一共包含4个分支,从branch1 ~ branch4
class Inception(nn.Module):
def __init__(self, input_channels, conv1x1, conv3x3reduce, conv3x3, conv5x5reduce, conv5x5, pool_conv1x1):
super(Inception, self).__init__()
# branch1:由1*1基本卷积结构组成,输入通道为原输入的通道数,输出通道为conv1*1
self.branch1 = BasicConv2d(input_channels, conv1x1, kernel_size=1)
# branch2:先1*1基本卷积结构,后3*3基本卷积结构,输出通道为conv3*3
self.branch2 = nn.Sequential(
BasicConv2d(input_channels, conv3x3reduce, kernel_size=1),
BasicConv2d(conv3x3reduce, conv3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
# branch3:先1*1基本卷积结构,后5*5基本卷积结构,输出通道为conv5*5
self.branch3 = nn.Sequential(
BasicConv2d(input_channels, conv5x5reduce, kernel_size=1),
# 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue
# Please see https://github.com/pytorch/vision/issues/906 for details.
BasicConv2d(conv5x5reduce, conv5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
# branch4:先3*3最大池化层,后1*1基本卷积结构,输出通道为pool_conv1*1
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(input_channels, pool_conv1x1, kernel_size=1)
)
# 定义Inception零件是如何处理输入x的
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
# 将4个分支得到的输出放在列表中,用torch.cat()指令,按照维度1的方向拼凑在一起,维度1就是通道数(Batch, Channel, Weight, Height)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)(2)Inception_Auxiliary模块的设计与封装
??????? Inception_Auxiliary是辅助分类器模块,按照辅助分类器的样图:
# 3、对InceptionAux零件的设计与封装
class InceptionAux(nn.Module):
# 零件结构包括:AveragePool2d(平均池化层5*5,s=3),基本卷积结构(1*1,s=1)
# 全连接层2个(2048-1024-num_classes)
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
# InceptionAux零件对输入x的处理
# 平均池化,卷积结构conv,展平(N, 128*4*4),随机失活,全连接+激活1,失活,全连接+激活2
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# training参数告诉dropout层当前是处于训练模式还是评估模式,并决定了它是否会随机删除输入中的某些元素(训练模式会进行dropout操作)。
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x??????? 1、这里需要解释的是:辅助分类器aux1,aux2分别挂在Inception4a,Inception4d上,这里需要对输入x进行一次全盘的[N, C, W, H]分析,分析得出:输入到4a模块时的输出是[N, 512, 14, 14],4d模块的输出是[N, 528, 14, 14]。所以,aux1和aux2的输入信息分别就对应了4a和4d的输出信息。(这里牵涉到的参数信息分析需要花点时间耐心推导,从原始输入[N, 3, 224, 224]一直经过各种卷积层,池化层和Inception模块就能慢慢得出这些结论)。
??????? 2、再经过aux1/2的处理后,输出信息都会变成[N, 128, 4, 4],所以通过flatten操作展平后,就变成了[N, 2048]的张量,把这个张量送入到全连接层1中,变成[N, 1024],再送入全连接层2,变成[N, num_classes]。
??????? 3、整个aux辅助分类器需要传入两个参数,一个是输入通道数,一个是分类数。对于aux1来说,输入通道数是512,对于aux2来说,输入通道数是528,分类数都是5。
??????? 4、另外需要注意的是:aux1/2在将输入传入到全连接层之前也做了2次Dropout操作,失活比例为50%,并且在Dropout里面设置了开关,即:training = self.training。第一个training是Dropout方法自带的一个可选参数,第二个self.training是Dropout方法会自动检测当前的运算是训练集的运算,还是测试集的运算,如果是训练集的运算,Dropout会被允许,如果不是,即:测试集的运算,那么Dropout将不被允许。(因为Dropout一般只用在训练集中防止过拟合)
(3)完整的特征层设计与封装
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module):
# 根据Google网络的样板图,所需要的零件有:
# conv1,conv2,conv3,maxpool1,maxpool2,maxpool3,Inception3a/3b/4a/4b/4c/4d/4e/5a/5b,avgpool,dropout,linear,softmax,aux1,aux2
# 这些零件所需要的下一级零件有:BasicConv2d, Inception, InceptionAux, AdaptiveAvgPool2d, MaxPool2d
# BasicConv2d:自定义的基本卷积结构,包含一个卷积层和一个激活层
# Inception:自定义的GoogleNet核心结构,包含4个处理分支branch1~branch4
# InceptionAux:自定义的GoogleNet辅助结构,包含一个平均池化层,一个基本卷积结构,两个全连接层与两个dropout层
# AdaptiveAvgPool2d:Pytorch自带的指令
# MaxPool2d:同上
# 构造器中的aux_logits默认为True,表示GoogleNet中默认需要辅助结构,如果该选项为True,则会在最后的if语句中开启辅助结构
def __init__(self, num_classes=1000, aux_logits=True):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
# 使用nn.MaxPool2d()函数时,如果输入的形状无法完全被池化核大小整除,那么默认情况下会向下取整(flooring)并舍弃超出池化核边界的部分。
# 如果ceil_mode = True,则nn.MaxPool2d()将进行向上取整操作,将不能整除池化核大小的输入的尾部部分反向填充至恰好能整除池化核为止。
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
??????? 我们封装好Inception模块和Inception_Auxiliary模块后,可以封装features了,在features中,我们预先定义了以下零件:
??????? (1)普通卷积层(3个):conv1 / 2 / 3
??????? (2)最大池化层(4个):maxpool 1 / 2 / 3 / 4
??????? (3)Inception模块(9个):Inception 3a / 3b / 4a / 4b / 4c / 4d / 4f / 5a / 5b
??????? (4)Inception_Auxiliary模块(2个):Inception_Aux 512 / 528
??????? (5)自适应均值池化层(1个):AdaptiveAvgPool2d
??????? (6)随机失活层:Dropout
??????? (7)全连接层:Linear
??????? 其中,在features的构造器参数中,需要传入分类总数num_classes,还携带了一个“是否使用辅助分类器”的开关aux_logits,这个开关默认为True,即默认使用辅助分类器。
?
???????
2、分类器的设计与封装(classifier)
??????? 由于GoogleNet基本上丢弃了全连接层,所以分类器的构造非常简单,就暂不赘述了,可以直接看特征层最后是如何处理经过Inception后的数据的。
三、模型对输入的处理(forward)
# GoogleNet对输入数据x的处理流程
# x - 卷积1 - 最池1 - 卷积2 - 卷积3 - 最池2 - 3a - 3b - 最池3 - 4a - 4b - 4c - 4d - 4e - 最池4 - 5a - 5b - 均池 - 展平 - 失活 - 全连接
# (aux1) (aux2)
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x) # N x 512 x 14 x 14
# self.training and self.aux_logits表达式用于判断当前模型是否处于训练模式,并且是否需要对输入进行辅助分类。如果这个条件为真,就会执行下面的代码块。
# 如果处于评估模式,那么不会执行辅助分类器的功能
if self.training and self.aux_logits:
aux1_pred = self.aux1(x)
# N x 512 x 14 x 14
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x) # N x 528 x 14 x 14
# self.training and self.aux_logits表达式用于判断当前模型是否处于训练模式,并且是否需要对输入进行辅助分类。如果这个条件为真,就会执行下面的代码块。
# 如果处于评估模式,那么不会执行辅助分类器的功能
if self.training and self.aux_logits:
aux2_pred = self.aux2(x)
# N x 528 x 14 x 14
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
y_pred = self.fc(x)
# N x (num_classes)
# 在这个代码块中,返回了三个变量 x, aux2, aux1_pred。其中 x 是主要的输出,而 aux2 和 aux1_pred 是辅助分类器的输出。
# 在训练模式下,辅助分类器可以起到一种正则化的作用,帮助提高模型的泛化能力。但在评估模式下,不需要辅助分类器的输出,所以只返回主要的输出 x。
if self.training and self.aux_logits:
return y_pred, aux2_pred, aux1_pred
return y_pred??????? 在对输入x的处理流程中,所有的操作细节是如下操作:
????????x - 卷积1 - 最大池1 - 卷积2 - 卷积3 - 最大池2 - 3a - 3b - 最大池3 - 4a - 4b - 4c - 4d - 4e - 最大池4 - 5a - 5b - 均池 - 展平 - 失活 - 全连接
??????? 在4a和4d处分别挂了aux1和aux2两个支路。并且在训练模式下,会开启辅助分类器,并在处理完输入x后,会返回3个输出,分别是y_pred, aux1_pred, aux2_pred。辅助分类器可以起到训练时正则化的作用,提高模型泛化能力。但是在测试模式下,就不应该开启辅助分类器了,也不需要返回辅助分类器的输出值,所以在使用辅助分类器以及输出辅助分类器的值的地方需要增设if语句。
四、配置GPU与输入图像预处理(transform)
??????? 导入的包
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from torch.utils.data import DataLoader
from GgN_01_Model import GoogLeNetdef main():
# 一、配置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 二、数据预处理规则定义
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}五、训练集 / 测试集的获取(DataLoader)
# 三、数据集文件路径定位
data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
image_path = os.path.join(data_root, "data_set", "flower_data")
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
# 四、训练集/测试集的数据加载器定义
batch_size = 32
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_loader = DataLoader(train_dataset,batch_size=batch_size, shuffle=True,
num_workers=0)
test_dataset = datasets.ImageFolder(root=os.path.join(image_path, "test"),
transform=data_transform["test"])
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False,
num_workers=0)六、索引 - 分类文件存储(JSON)
# 五、把数据集的分类信息写入到JSON文件中,方便预测的时候调用
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)七、损失函数与优化器定义
# 六、创建GoogleNet的实例化对象
net = GoogLeNet(num_classes=5, aux_logits=True)
net.to(device)
# 七、配置损失函数与优化器
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)八、准备阶段
# 八、准备阶段
epochs = 30
best_accuracy = 0.0
train_total_number = len(train_dataset)
test_total_number = len(test_dataset)
save_path = './best_accuracy_params/googleNet.pth'
train_steps = len(train_loader)
print("using {} train_inputs for training, {} train_inputs for validation.".format(train_total_number,
test_total_number))九、训练测试环节(train-test)
# 九、训练与测试过程
# 【关于Aux辅助结构】
# 通过引入辅助输出来帮助训练网络。辅助输出在GoogleNet中的作用是为了避免梯度消失(gradient vanishing)的问题,提供额外的梯度反向传播路径。
# 它可以增加网络的深度,从而增强网络对于特征的表示能力,并且有助于减轻梯度消失导致的训练困难。
# 在计算总的损失时,将辅助输出的损失加权添加到主要输出的损失上,其中的权重因子0.3是根据经验调整得出的。
for epoch in range(epochs):
# 训练阶段
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
train_inputs, train_labels = data
train_inputs, train_labels = train_inputs.to(device), train_labels.to(device)
optimizer.zero_grad()
# 有3个输出,y_pred, aux1_pred, aux2_pred
y_pred, aux2_pred, aux1_pred = net(train_inputs)
loss0 = loss_function(y_pred, train_labels)
loss1 = loss_function(aux1_pred, train_labels)
loss2 = loss_function(aux2_pred, train_labels)
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward()
optimizer.step()
# 打印统计数据
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# test
net.eval()
current_correct_number = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
test_bar = tqdm(test_loader, file=sys.stdout)
for test_data in test_bar:
test_inputs, test_labels = test_data
test_inputs, test_labels = test_inputs.to(device), test_labels.to(device)
outputs = net(test_inputs)
_, predict_y = torch.max(outputs, dim=1)
current_correct_number += torch.eq(predict_y, test_labels).sum().item()
test_accuracy = current_correct_number / test_total_number
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, test_accuracy))
if test_accuracy > best_accuracy:
best_accuracy = test_accuracy
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
十、Model代码全览
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module):
# 根据Google网络的样板图,所需要的零件有:
# conv1,conv2,conv3,maxpool1,maxpool2,maxpool3,Inception3a/3b/4a/4b/4c/4d/4e/5a/5b,avgpool,dropout,linear,softmax,aux1,aux2
# 这些零件所需要的下一级零件有:BasicConv2d, Inception, InceptionAux, AdaptiveAvgPool2d, MaxPool2d
# BasicConv2d:自定义的基本卷积结构,包含一个卷积层和一个激活层
# Inception:自定义的GoogleNet核心结构,包含4个处理分支branch1~branch4
# InceptionAux:自定义的GoogleNet辅助结构,包含一个平均池化层,一个基本卷积结构,两个全连接层与两个dropout层
# AdaptiveAvgPool2d:Pytorch自带的指令
# MaxPool2d:同上
# 构造器中的aux_logits默认为True,表示GoogleNet中默认需要辅助结构,如果该选项为True,则会在最后的if语句中开启辅助结构
def __init__(self, num_classes=1000, aux_logits=True):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
# 使用nn.MaxPool2d()函数时,如果输入的形状无法完全被池化核大小整除,那么默认情况下会向下取整(flooring)并舍弃超出池化核边界的部分。
# 如果ceil_mode = True,则nn.MaxPool2d()将进行向上取整操作,将不能整除池化核大小的输入的尾部部分反向填充至恰好能整除池化核为止。
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
# GoogleNet对输入数据x的处理流程
# x - 卷积1 - 最池1 - 卷积2 - 卷积3 - 最池2 - 3a - 3b - 最池3 - 4a - 4b - 4c - 4d - 4e - 最池4 - 5a - 5b - 均池 - 展平 - 失活 - 全连接
# (aux1) (aux2)
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x) # N x 512 x 14 x 14
# self.training and self.aux_logits表达式用于判断当前模型是否处于训练模式,并且是否需要对输入进行辅助分类。如果这个条件为真,就会执行下面的代码块。
# 如果处于评估模式,那么不会执行辅助分类器的功能
if self.training and self.aux_logits:
aux1_pred = self.aux1(x)
# N x 512 x 14 x 14
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x) # N x 528 x 14 x 14
# self.training and self.aux_logits表达式用于判断当前模型是否处于训练模式,并且是否需要对输入进行辅助分类。如果这个条件为真,就会执行下面的代码块。
# 如果处于评估模式,那么不会执行辅助分类器的功能
if self.training and self.aux_logits:
aux2_pred = self.aux2(x)
# N x 528 x 14 x 14
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
y_pred = self.fc(x)
# N x (num_classes)
# 在这个代码块中,返回了三个变量 x, aux2, aux1_pred。其中 x 是主要的输出,而 aux2 和 aux1_pred 是辅助分类器的输出。
# 在训练模式下,辅助分类器可以起到一种正则化的作用,帮助提高模型的泛化能力。但在评估模式下,不需要辅助分类器的输出,所以只返回主要的输出 x。
if self.training and self.aux_logits:
return y_pred, aux2_pred, aux1_pred
return y_pred
# 1、对BasicConv2d零件的设计与封装:相当于把卷积层和激活层封装在一起
class BasicConv2d(nn.Module):
# 该零件的结构包含一个卷积层,一个激活层
def __init__(self, input_channels, output_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(input_channels, output_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
# 该零件对输入的处理是先进行卷积再进行激活
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
# 2、对Inception零件的设计与封装
# 该零件一共包含4个分支,从branch1 ~ branch4
class Inception(nn.Module):
def __init__(self, input_channels, conv1x1, conv3x3reduce, conv3x3, conv5x5reduce, conv5x5, pool_conv1x1):
super(Inception, self).__init__()
# branch1:由1*1基本卷积结构组成,输入通道为原输入的通道数,输出通道为conv1*1
self.branch1 = BasicConv2d(input_channels, conv1x1, kernel_size=1)
# branch2:先1*1基本卷积结构,后3*3基本卷积结构,输出通道为conv3*3
self.branch2 = nn.Sequential(
BasicConv2d(input_channels, conv3x3reduce, kernel_size=1),
BasicConv2d(conv3x3reduce, conv3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
# branch3:先1*1基本卷积结构,后5*5基本卷积结构,输出通道为conv5*5
self.branch3 = nn.Sequential(
BasicConv2d(input_channels, conv5x5reduce, kernel_size=1),
# 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue
# Please see https://github.com/pytorch/vision/issues/906 for details.
BasicConv2d(conv5x5reduce, conv5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
# branch4:先3*3最大池化层,后1*1基本卷积结构,输出通道为pool_conv1*1
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(input_channels, pool_conv1x1, kernel_size=1)
)
# 定义Inception零件是如何处理输入x的
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
# 将4个分支得到的输出放在列表中,用torch.cat()指令,按照维度1的方向拼凑在一起,维度1就是通道数(Batch, Channel, Weight, Height)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
# 3、对InceptionAux零件的设计与封装
class InceptionAux(nn.Module):
# 零件结构包括:AveragePool2d(平均池化层5*5,s=3),基本卷积结构(1*1,s=1)
# 全连接层2个(2048-1024-num_classes)
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
# InceptionAux零件对输入x的处理
# 平均池化,卷积结构conv,展平(N, 128*4*4),随机失活,全连接+激活1,失活,全连接+激活2
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# training参数告诉dropout层当前是处于训练模式还是评估模式,并决定了它是否会随机删除输入中的某些元素(训练模式会进行dropout操作)。
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
十一、Train&Test代码全览
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from torch.utils.data import DataLoader
from GgN_01_Model import GoogLeNet
def main():
# 一、配置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 二、数据预处理规则定义
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# 三、数据集文件路径定位
data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
image_path = os.path.join(data_root, "data_set", "flower_data")
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
# 四、训练集/测试集的数据加载器定义
batch_size = 32
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_loader = DataLoader(train_dataset,batch_size=batch_size, shuffle=True,
num_workers=0)
test_dataset = datasets.ImageFolder(root=os.path.join(image_path, "test"),
transform=data_transform["test"])
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False,
num_workers=0)
# 五、把数据集的分类信息写入到JSON文件中,方便预测的时候调用
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 六、创建GoogleNet的实例化对象
net = GoogLeNet(num_classes=5, aux_logits=True)
# 如果要使用官方的预训练权重,注意是将权重载入官方的模型,不是我们自己实现的模型
# 官方的模型中使用了bn层以及改了一些参数,不能混用
# import torchvision
# net = torchvision.models.googlenet(num_classes=5)
# model_dict = net.state_dict()
# # 预训练权重下载地址: https://download.pytorch.org/models/googlenet-1378be20.pth
# pretrain_model = torch.load("googlenet.pth")
# del_list = ["aux1.fc2.weight", "aux1.fc2.bias",
# "aux2.fc2.weight", "aux2.fc2.bias",
# "fc.weight", "fc.bias"]
# pretrain_dict = {k: v for k, v in pretrain_model.items() if k not in del_list}
# model_dict.update(pretrain_dict)
# net.load_state_dict(model_dict)
net.to(device)
# 七、配置损失函数与优化器
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)
# 八、训练周期与权重文件初始化
epochs = 30
best_accuracy = 0.0
train_total_number = len(train_dataset)
test_total_number = len(test_dataset)
save_path = './best_accuracy_params/googleNet.pth'
train_steps = len(train_loader)
print("using {} train_inputs for training, {} train_inputs for validation.".format(train_total_number,
test_total_number))
# 九、训练与测试过程
# 【关于Aux辅助结构】
# 通过引入辅助输出来帮助训练网络。辅助输出在GoogleNet中的作用是为了避免梯度消失(gradient vanishing)的问题,提供额外的梯度反向传播路径。
# 它可以增加网络的深度,从而增强网络对于特征的表示能力,并且有助于减轻梯度消失导致的训练困难。
# 在计算总的损失时,将辅助输出的损失加权添加到主要输出的损失上,其中的权重因子0.3是根据经验调整得出的。
for epoch in range(epochs):
# 训练阶段
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
train_inputs, train_labels = data
train_inputs, train_labels = train_inputs.to(device), train_labels.to(device)
optimizer.zero_grad()
# 有3个输出,y_pred, aux1_pred, aux2_pred
y_pred, aux2_pred, aux1_pred = net(train_inputs)
loss0 = loss_function(y_pred, train_labels)
loss1 = loss_function(aux1_pred, train_labels)
loss2 = loss_function(aux2_pred, train_labels)
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward()
optimizer.step()
# 打印统计数据
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# test
net.eval()
current_correct_number = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
test_bar = tqdm(test_loader, file=sys.stdout)
for test_data in test_bar:
test_inputs, test_labels = test_data
test_inputs, test_labels = test_inputs.to(device), test_labels.to(device)
outputs = net(test_inputs)
_, predict_y = torch.max(outputs, dim=1)
current_correct_number += torch.eq(predict_y, test_labels).sum().item()
test_accuracy = current_correct_number / test_total_number
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, test_accuracy))
if test_accuracy > best_accuracy:
best_accuracy = test_accuracy
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码随想录算法训练营第五十八天| 739 每日温度 496 下一个更大元素 |
- 【开题报告】基于SSM的动物保护知识科普平台的设计与实现
- hyperf 和 laravel、lumen防止xss攻击中间件封装
- 【JAVA------GUI基础知识】
- LoRA模型原理
- 复习回顾、静态、继承、引用类型使用
- 老子云支持70+格式模型转FBX/OBJ/STL/STP,一键处理无损转换!
- 监督学习 - 支持向量回归(Support Vector Regression,SVR)
- Spring中通过注解给Bean的属性进行赋值
- c4d怎么建模沙发?