书生·浦语大模型全链路开源开放体系
发布时间:2024年01月03日
书生·浦语大模型全链路开源开放体系
大模型成为热门关键词
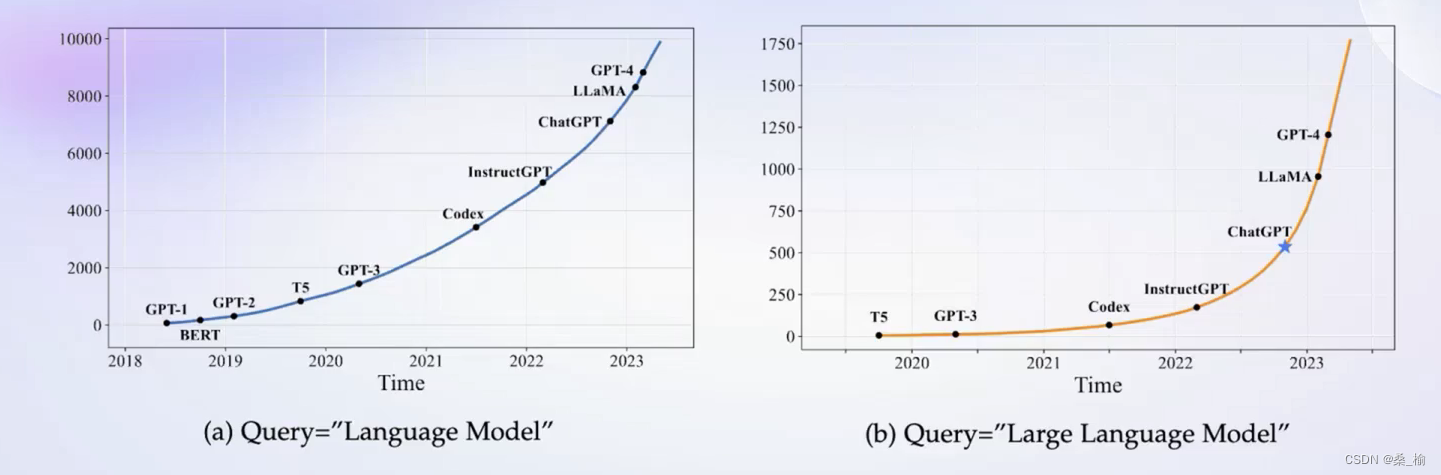
大模型成为发展通用人工智能的重要途径

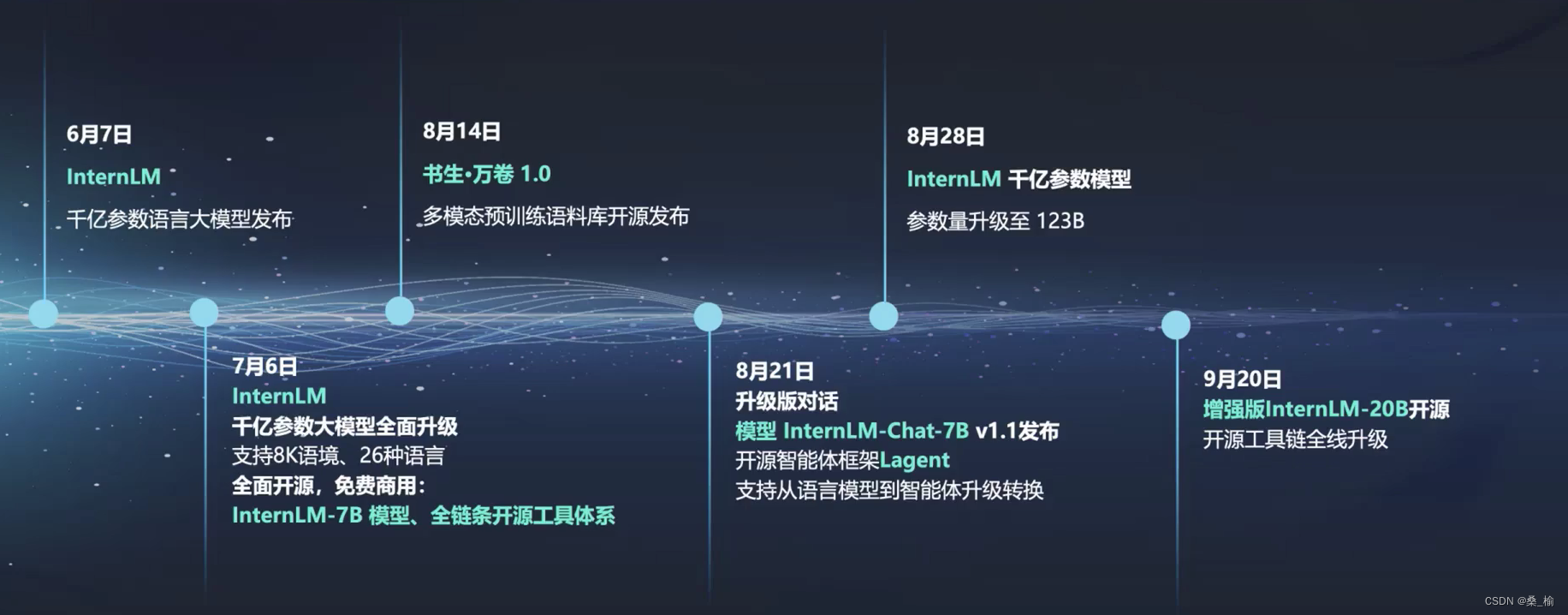
书生·浦语大模型开源历程

书生·浦语20B开源大模型性能
- 全面领先相近量级的开源模型(包含Llama-33B、Llama2-13B以及国内主流的7B、13B开源模型)
- 以不足三分之一的参数量,达到Llama2-70B水平

从模型到应用
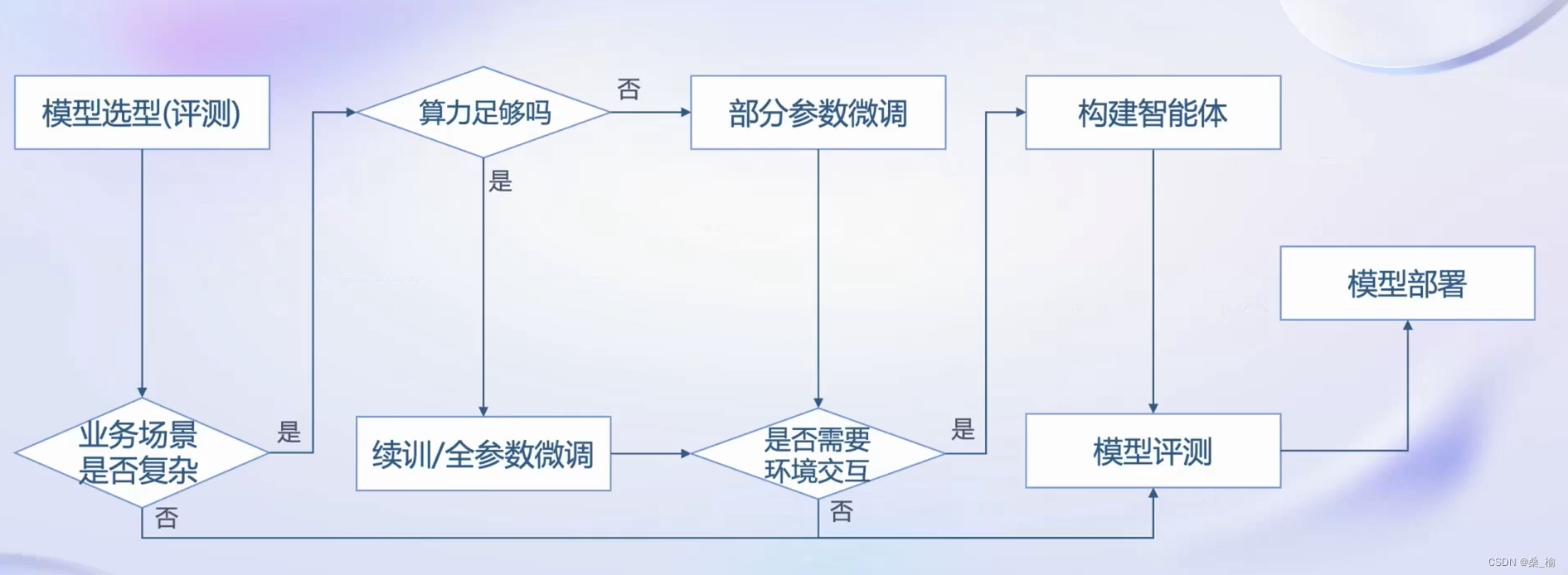
书生·浦语全链路开源开放体系
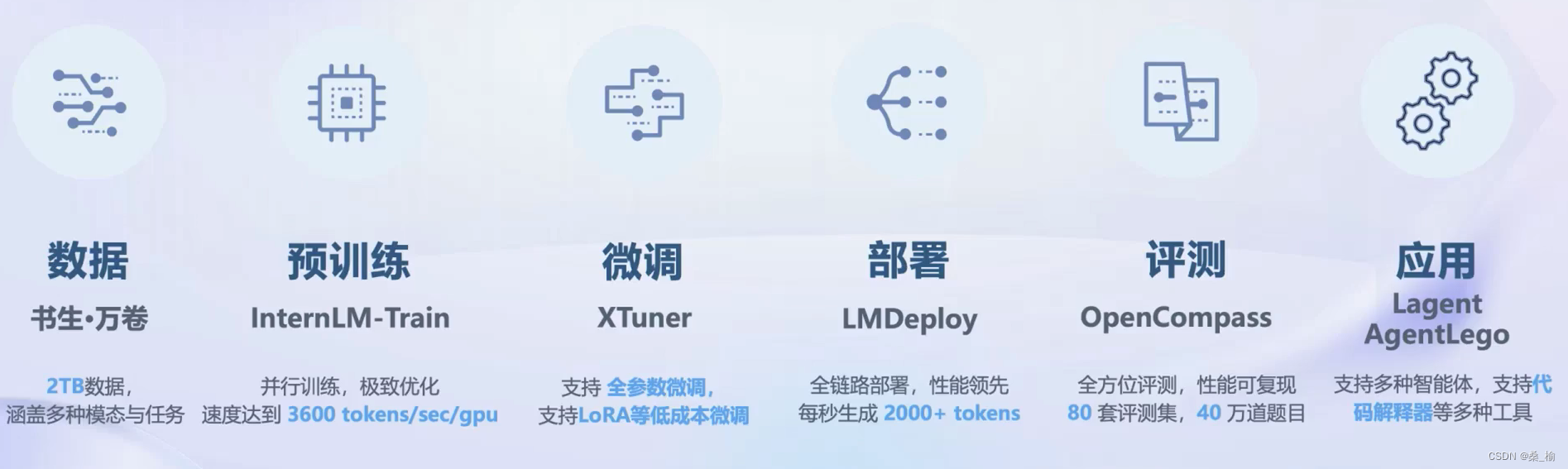
数据

总数据量 2TB
包含:
- 文本数据 50亿个文档
- 图像-文本数据集 2200万个文件
- 视频数据 超1000个文件

预训练

微调
- 增量续训
- 垂直领域知识 文章、书籍、代码等
- 有监督微调
- 高质量的对话、问答数据
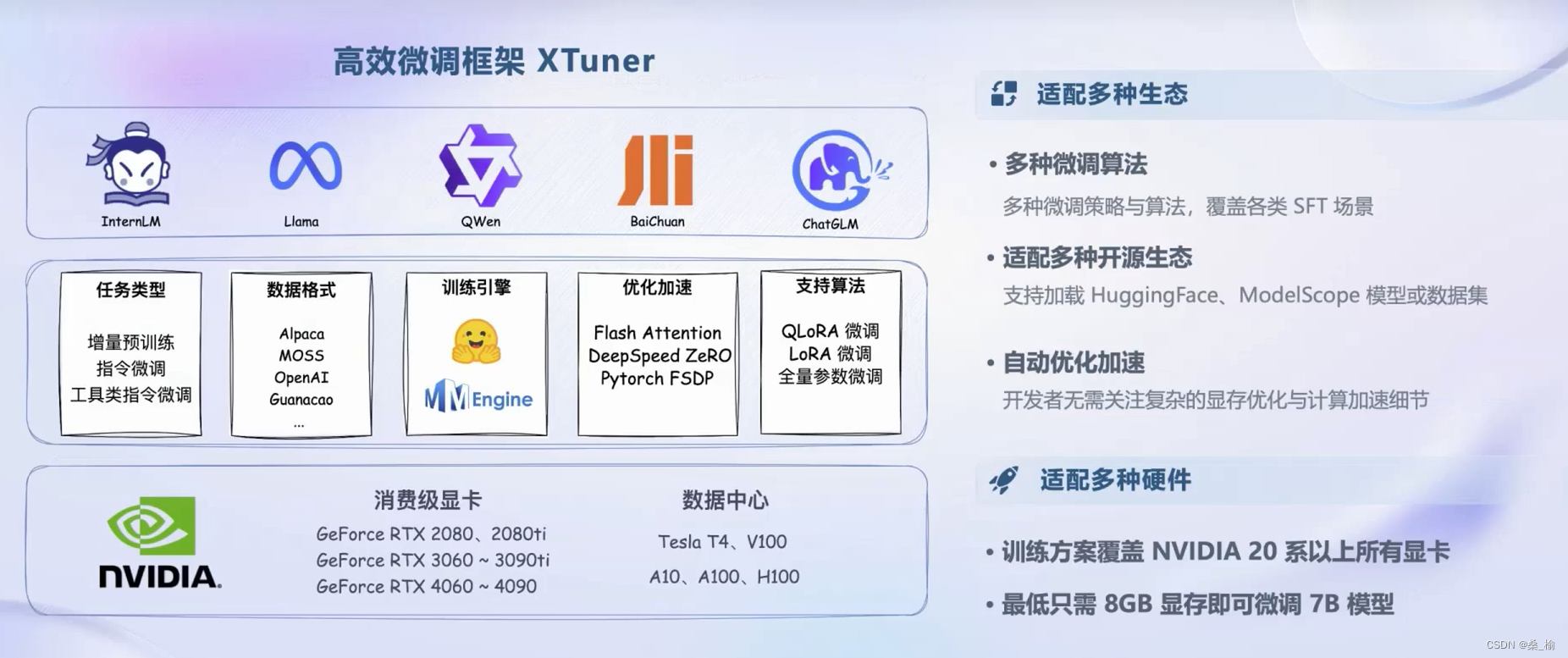
- 高质量的对话、问答数据
评测
 提出了OpenCompass评测体系
提出了OpenCompass评测体系
6大维度 80+评测集、40万+评测题目


部署


智能体

局限:
- 最新信息和知识的获取
- 回复的可靠性
- 数学计算
- 工具使用和交互



文章来源:https://blog.csdn.net/shengweiit/article/details/135372800
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 练习题 拼接最大数
- 基于ssm大学学术交流论坛论文
- MYSQL 索引分类
- 常见面试题之HTML
- 品牌价值的累积与倍增:指数函数的含义及其在企业运营中的应用
- sql 语句查询今天、昨天、近7天、近30天、一个月内、上一月 数据 及 CONVERT 中数字参数用法
- 软件测试和软件开发哪个发展更好?我来告诉你怎么选
- 服务器托管在数据中心,如何有效避免中勒索病毒?
- DEJA_VU3D - Cesium功能集 之 119-三维热力图
- 【6】密评中对服务端采用“挑战-响应”机制进行身份鉴别的验证