Elastic Search 8.12:让 Lucene 更快,让开发人员更快
作者:来自 Elastic?Serena Chou, Aditya Tripathi

Elastic Search 8.12 包含新的创新,可供开发人员直观地利用人工智能和机器学习模型,通过闪电般的快速性能和增强的相关性来提升搜索体验。 此版本的 Elastic? 基于 Apache Lucene 9.9(有史以来最快的 Lucene 版本)构建,并更新了一些我们最流行的集成(integrations),例如 Amazon S3、MongoDB、MySQL 等。 我们的 inference?API 抽象了单个 API 调用背后嵌入管理的复杂性,并且 kNN 现在已提升为查询 (query) 类型。
与使用旧版本 Elastic 构建的搜索体验相比,通过简单升级,客户可以获得令人难以置信的速度提升,并且开发人员将拥有更有效的工具来定制搜索体验,并且代码更简洁,更易于维护。
Elastic Search 8.12 现已在 Elastic Cloud 上推出,这是唯一包含最新版本中所有新功能的托管 Elasticsearch? 产品。 你还可以下载 Elastic Stack 和我们的云编排产品 Elastic Cloud Enterprise 和 Elastic Cloud for Kubernetes,以获得自我管理的体验。
Elastic 8.12 中还有哪些新功能? 查看 8.12 公告帖子了解更多>>
站在巨人的肩膀上 Lucene 9.9
Apache Lucene 9.9 是有史以来最快的 Lucene 版本,我们很高兴能够根据客户的需求贡献关键创新。 通过 Elastic 投资于所选的行业技术,最先进的搜索体验(无论是基于 BM25、向量搜索、语义搜索还是上述所有搜索的混合组合)对于用户来说只是一次升级。 Elastic 用户首先受益,并且可以放心,这些创新是在考虑到他们的环境的情况下构建的。
所有搜索用户都将受益于对标量量化、搜索并发性(默认启用)的支持以及融合乘加 (FMA) 和 block-max MAXSCORE 工作带来的大幅加速。
借助 8.12,客户可以以适合自己的价格体验这些功能,并通过使用 Elastic Cloud 体验最佳的 TCO (total cost of ownership)。 对于 AWS 云用户,现在有一个向量搜索优化的硬件配置文件,可使用 Elastic 平台来加速和提升所有用例的搜索体验。
_inference:在单个 API 调用后面的嵌入管理
今年早些时候,我们推出了 Elasticsearch 相关性引擎,这是几年研发的成果。 这些功能的核心部分始终是灵活的第三方模型管理,使客户能够利用当今市场上下载最多的向量数据库及其选择的转换器模型。
我们通过更新_inference(一个顶级 API 端点,将嵌入管理的复杂性抽象为单个请求)来支持与供应商无关的模型访问,从而不断改进开发人员体验。
想要一键部署我们相关性领先的 Elastic Learned Sparse EncodeR 模型并开始使用它进行推理?
POST _inference/sparse_embedding/my-elser-model
{
"input": "Semantic search is within reach."
}比如,我们可以使用如下的命令来创建一个 inference API:
PUT _inference/sparse_embedding/.elser_model_2
{
"service": "elser",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
},
"task_settings": {}
}我们可以通过如下的方法来进行推理:
POST _inference/sparse_embedding/.elser_model_2
{
"input": "Semantic search is within reach."
}
可以在 Elastic 平台内管理 E5 等第三方多语言模型,或者通过相同的简单 _inference API 调用部署在 Hugging Face Inference Endpoints 上时可以轻松访问它们。
PUT _inference/text_embedding/my_test_service
{
"service": "hugging_face",
"service_settings": {
"url": "<url>",
"api_key": "<api key>"
}
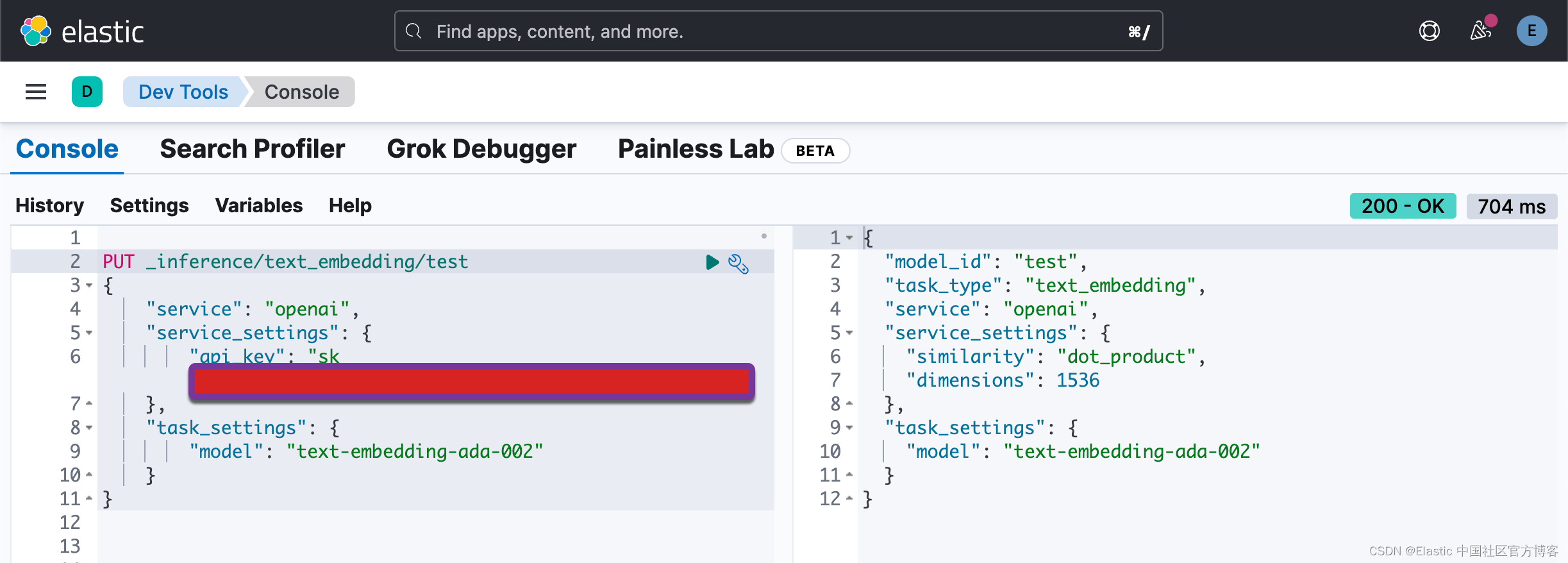
}比如,在我的电脑上,我使用如下的命令来创建一个叫做 test 的 model id:
PUT _inference/text_embedding/test
{
"service": "openai",
"service_settings": {
"api_key": "YourOpenAiKey"
},
"task_settings": {
"model": "text-embedding-ada-002"
}
}
我们可以使用如下的方式来获得 embeddings:
POST _inference/text_embedding/test
{
"input": "Semantic search is within reach."
}
在上面它返回 1536 维的向量。
同样,我们也可以针对 hunggingface 来做同样的事:
PUT _inference/text_embedding/hugging-face-embeddings
{
"service": "hugging_face",
"service_settings": {
"api_key": "<access_token>",
"url": "<url_endpoint>"
}
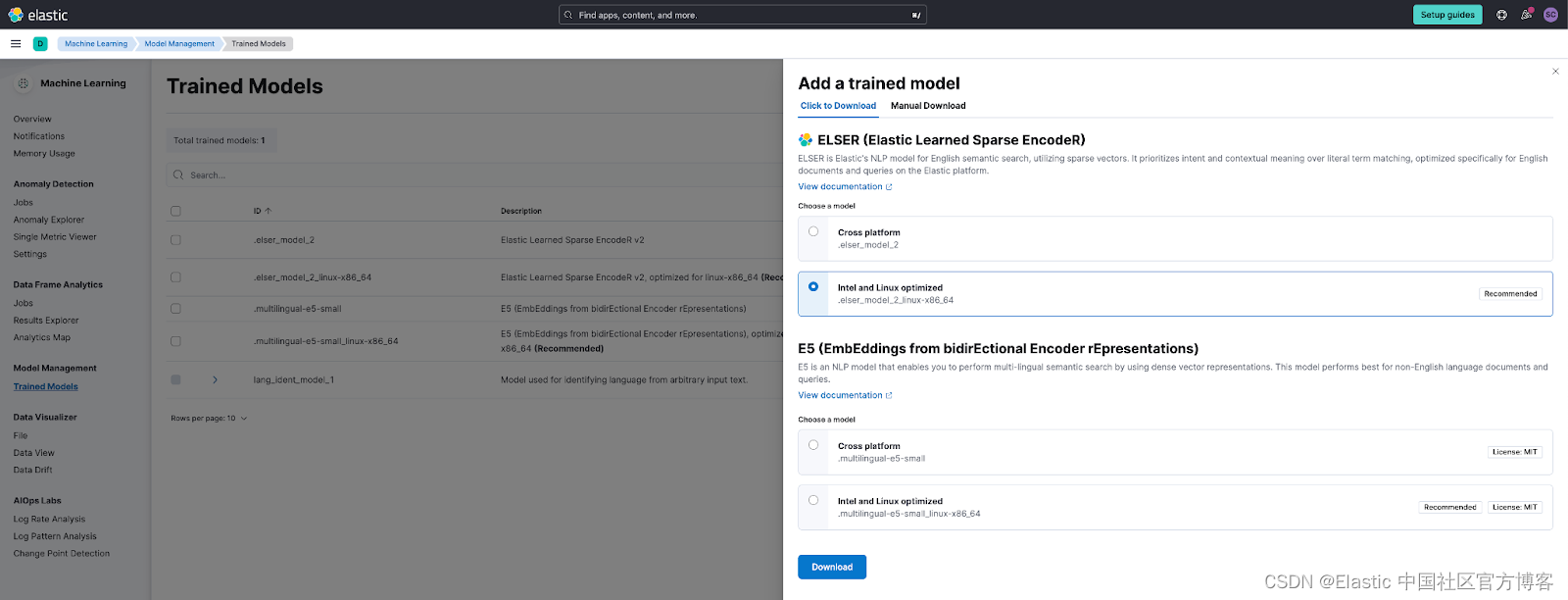
}在 Hugging Face 端点页面上创建新的推理端点以获取端点 URL。 选择要在新端点创建页面上使用的模型 - 例如 intfloat/e5-small-v2 - 然后选择高级配置部分下的句子嵌入任务。 创建端点。 端点初始化完成后复制 URL。
在 Elastic Search 8.12 中,只需简单下载或单击按钮即可快速完成使用 Elastic 平台管理 E5 模型的操作。 选择在 Elastic 中管理此模型使用户能够从特定于平台的优化中受益,从而获得更好的搜索体验性能。
_inference 也与 OpenAI 原生集成,因此使用像 text-embedding-ada-002 这样的模型可以简单如下:
PUT _inference/text_embedding/test
{
"service": "openai",
"service_settings": {
"api_key": <api key>,
"organization_id": <org id>
},
"task_settings": {
"model": "text-embedding-ada-002"
}
}使用 kNN 搜索的开发人员会很高兴得知 kNN 现在可以作为另一种查询类型。 这使得可以使用其他平台功能,例如通过 kNN 搜索固定查询。 我们将其与添加到 Profile API 中的其他统计数据配对,以便更好地调试 kNN 搜索 - 进行了一些更改,从而形成了一套非常强大的工具,可以将向量搜索添加到您今天的应用程序中。 请参阅 8.12 平台发布博客了解更多详细信息。
更多原生连接器现已正式发布,而且它们的功能甚至更多
检索增强生成 (RAG) 实施凭借结构良好、优化的数据而蓬勃发展。 通过我们的 Elastic 集成目录,最好使用本机连接器来为这些类型的搜索体验构建正确的上下文。
原生连接器是托管在 Elastic Cloud 中的 Elastic 集成,只需要一些输入即可配置集成。 对于希望以自我管理方式同步内容的开发人员来说,所有本机连接器都可以使用 Docker 部署的连接器客户端,并使用新的 _connector API 进行管理。
在 8.12 中,我们启用了 Amazon S3、Google Cloud Storage、Salesforce 和 Oracle 连接器的原生使用,并且以下连接器已普遍可用:
- Azure Blob 存储
- 谷歌云存储
- 亚马逊 S3
- MongoDB
- MySQL
- Postgres
- SQL 数据库
添加了对连接器的其他改进,例如对 Dropbox、GitHub 连接器的文档级安全支持以及对 Amazon S3 连接器的高级同步规则支持。
使用 Elastic 集成时,所有摄取的数据都可以快速转换或分块,以利用 _inference 提供的所有令人难以置信的 8.12 机器学习功能以及 Lucene 9.9 引入的创新。
试试看
请阅读发行说明中了解这些功能以及更多信息。 在 Search Labs 中查找代码参考、笔记本和最新研究。
现有 Elastic Cloud 客户可以直接从 Elastic Cloud 控制台访问其中许多功能。 没有利用云上的 Elastic? 开始免费试用。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Elastic Search 8.12: Making Lucene fast and developers faster | Elastic Blog
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 利用网络教育系统构建个性化学习平台
- 【代码整理】基于COCO格式的pytorch Dataset类实现
- 【Qt-编码】
- 【降龙算法】基于QT插件机制实现一个机器视觉算法小框架
- 分布式事务--TC服务的高可用和异地容灾
- 回溯算法篇-01:全排列
- FPGA-Xilinx ZYNQ PS端实现SD卡文件数据读取-完整代码
- 一个程序员“玩”出来的网站:每月成本仅 350 元,如今赚了 16.4 万元
- 纯前端 文件上传汇总
- redis安装bloom过滤器