(2024,开源轻量级 MUSE,VA-GAN,余弦掩蔽)aMUSEd:开源的 MUSE 复现
aMUSEd: An Open MUSE Reproduction
公和众和号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
我们提出了 aMUSEd,这是一个基于 MUSE 的开源、轻量级的掩蔽图像模型(masked image model,MIM),用于文本到图像的生成。使用 MUSE 的参数的 10%(800M 参数,包括来自 U-ViT、CLIP-L/14 文本编码器和 VQ-GAN 的所有参数),aMUSEd 专注于快速图像生成。相对于潜在扩散,这是文本到图像生成的主流方法,我们认为 MIM 相对未被充分探讨。与潜在扩散相比,MIM 需要更少的推理步骤,并且更具可解释性。此外,MIM 可以通过仅使用单个图像进行微调,学习额外的样式。我们希望通过展示 aMUSEd 在大规模文本到图像生成上的有效性,并发布可复现的训练代码,鼓励对 MIM 进行进一步的探索。我们还发布了两个模型的检查点,这两个模型直接生成 256x256 和 512x512 分辨率的图像。
MUSE 成功地将 MIM 应用于大规模文本到图像生成(Chang等人(2023))。MUSE 使用了一个具有微调解码器的 VQ-GAN(Esser等人(2021)),一个 30 亿参数的 Transformer,以及一个10 亿参数的超分辨 Transformer。此外,MUSE 是根据预训练的 T5-XXL 文本编码器(Raffel等人(2023))的文本嵌入进行调节。为了在预测 512x512 分辨率图像时提高图像质量,MUSE 使用了一个根据来自 256x256 分辨率模型的预测标记进行调节的超分辨模型。由于 MIM 的默认预测目标是图像修复的镜像,MUSE 展示了令人印象深刻的零样本修复结果。相比之下,扩散模型通常需要额外的微调来进行修复(RunwayML(2022))。?
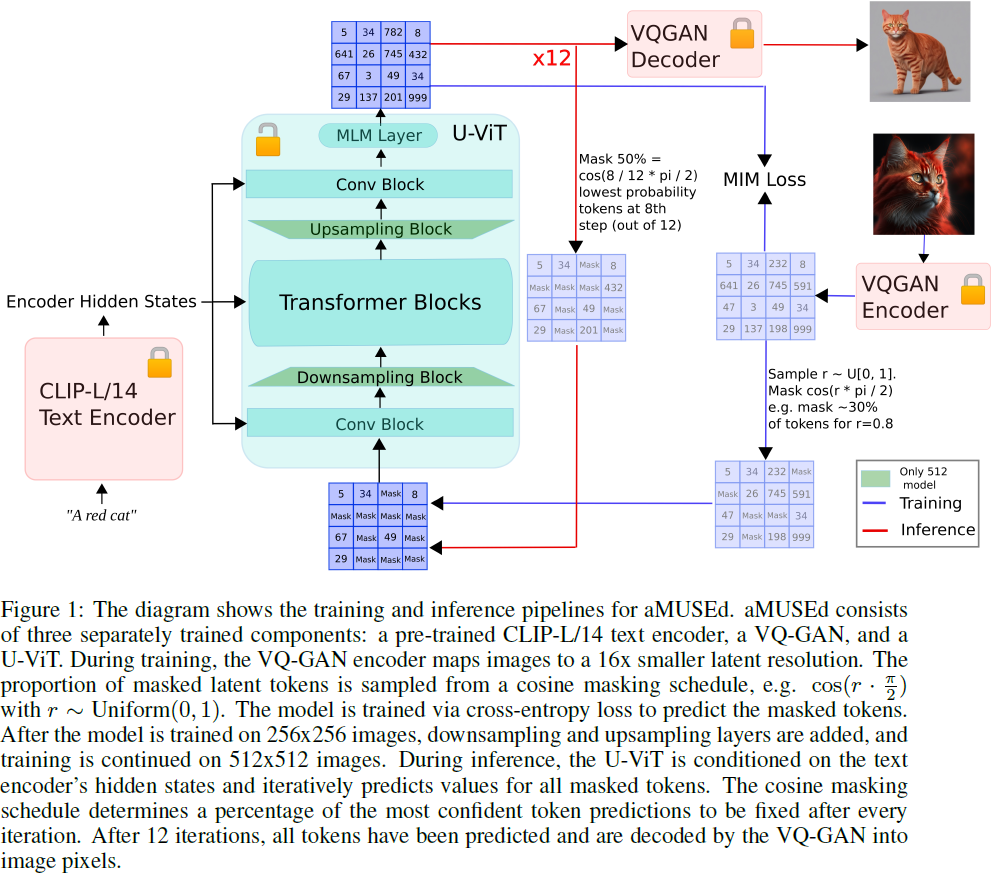
3. 方法
VQ-GAN。我们使用了一个拥有146M 参数的 VQ-GAN(Esser等人(2021)),没有自注意力层,词汇大小为 8192,潜在维度为 64。我们的 VQ-GAN 使用 16 倍降采样分辨率,例如,256x256(512x512)分辨率的图像被减少到 16x16(32x32)的潜在编码。我们对 VQ-GAN 进行了 250 万步的训练。
文本调节(Text Conditioning)。由于我们关注推理速度,我们决定,模型以来自较小 CLIP 模型(Radford等人(2021))的文本嵌入为条件,而不是 T5-XXL(Raffel等人(2023))。我们尝试过原始的CLIP-L/14(Radford等人(2021))和与 DataComp 一起发布的等大小的 CLIP 模型(Gadre等人(2023))。即使在 Gadre 等人(2023)中报告的改进,我们发现原始的 CLIP-L/14 能够产生质量更好的图像。倒数第二层的文本编码器隐藏状态通过标准的交叉注意机制注入。此外,最终池化的文本编码器隐藏状态通过自适应归一化层注入(Perez等人(2017))。
U-ViT。对于基础模型,我们使用了 U-ViT 的一个变种(Hoogeboom等人(2023)),这是一个受 Transformer(Vaswani等人(2023))启发的可扩展 U-Net(Ronneberger等人(2015))。Hoogeboom 等人(2023)发现 U-Net 通过增加低分辨率块的数量可以有效地进行扩展,因为增加的参数超过了小特征图的补偿。此外,Hoogeboom 等人(2023)通过将最低分辨率块替换为MLP,将其转换为 Transformer。对于我们的 256x256 分辨率模型,在卷积残差块中没有降采样或上采样。对于我们的 512x512 分辨率模型,我们在卷积残差块中使用了单一的 2x 降采样和相应的 2x 上采样。因此,256x256 和 512x512 模型的较低分辨率 U-ViT 接收一个具有 1024 的特征维度的 256(16x16)的输入向量序列。256x256 分辨率模型有 603M 参数,512x512 分辨率模型有608M 参数。512x512 分辨率模型中的额外 5M 参数是由于额外的降采样和上采样层。
掩蔽计划(Masking Schedule)。按照 MUSE(Chang等人(2023))和 MaskGIT(Chang等人(2022))的做法,我们使用基于余弦的掩蔽计划。在每个步骤 t 之后,预测的标记中置信度最高的的标记将永不掩蔽,使被掩蔽的标记比例为 cos( t / T · π / 2 ),其中 T 为总采样步骤数。我们在所有的评估实验中使用了 T = 12 个采样步骤。通过消融实验证明,Chang等人(2022)表明,像余弦这样的凹面掩蔽计划优于凸面掩蔽计划。Chang 等人(2022)假设凹面掩蔽计划受益于较早去噪过程中的固定预测较少,而较晚去噪过程中的固定预测较多。(注:国外的凹凸的定义和国内相反)
微调节(Micro-conditioning)。与 Podell等人(2023)一样,我们在原始图像分辨率、裁剪坐标 和 LAION 审美分数(Schuhmann(2022))上进行微调节。微调节值被投影到正弦嵌入中,并作为额外通道附加到最终池化的文本编码器隐藏状态中。
5. 结果
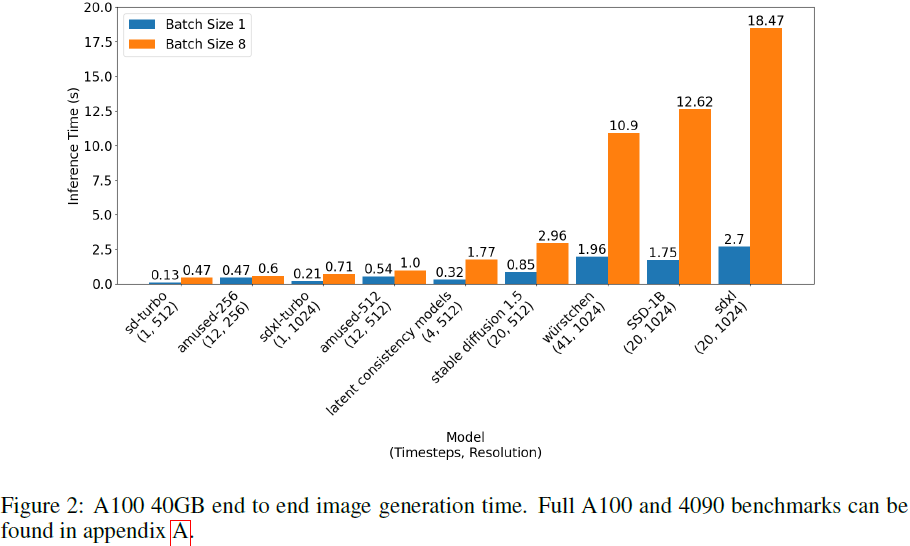
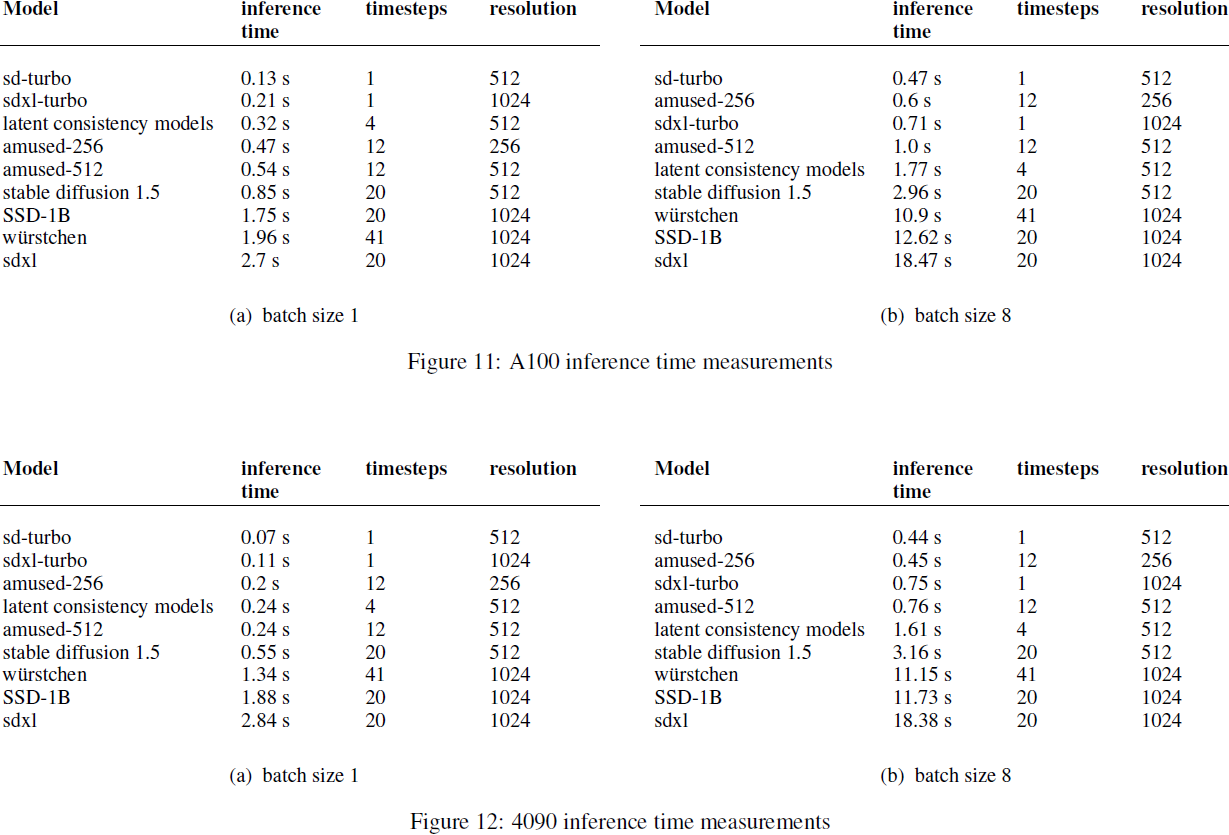
aMUSEd 的推理速度优于未经蒸馏的扩散模型,并且在与少步骤蒸馏扩散模型的竞争中表现出色。

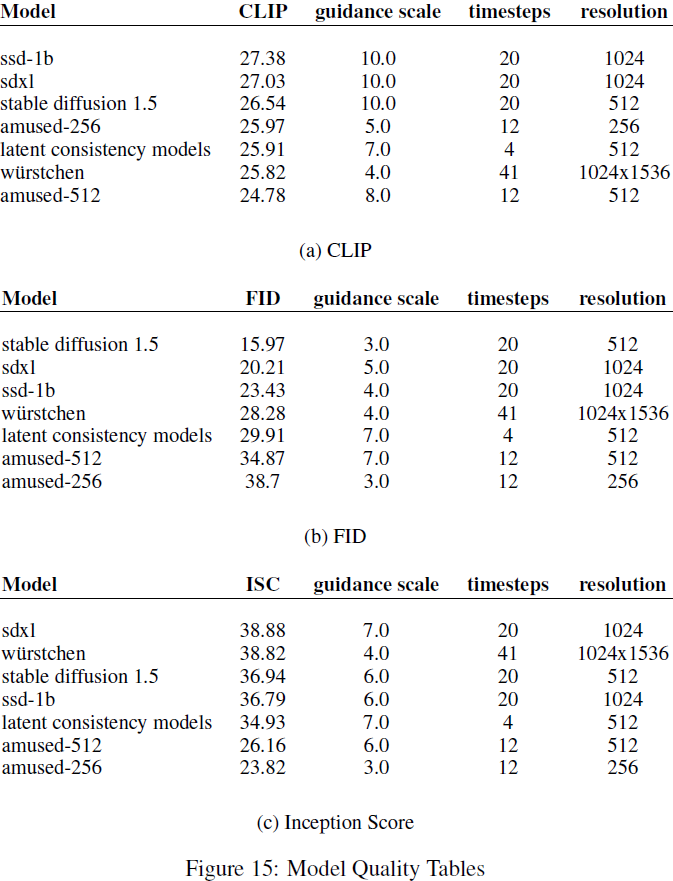
我们的 512x512 分辨率模型具有竞争力的 CLIP 分数。然而,我们的 256x256 和 512x512 分辨率模型在 FID 和 Inception 分数上都落后。
S. 总结
S.1 主要贡献
本文提出?aMUSEd,一个用于文本到图像的生成的基于 MUSE 的开源、轻量级的掩蔽图像模型(MIM)。与潜在扩散相比,MIM 需要更少的推理步骤,并且更具可解释性。此外,MIM 可以通过仅使用单个图像进行微调,学习额外的样式。
S.2 方法
VQ-GAN。使用了一个拥有146M 参数的 VQ-GAN,没有自注意力层,词汇大小为 8192,潜在维度为 64,使用 16 倍降采样分辨率。(MUSE 使用具有微调解码器的 VQ-GAN)
文本调节。为提升推理速度,模型以来自较小 CLIP (CLIP-L/14)而不是 T5-XXL 的文本嵌入为条件。(MUSE 使用预训练的 T5-XXL 文本编码器)
U-ViT。对于基础模型,使用了 U-ViT 的一个变种,这是受 Transformer 启发的可扩展 U-Net。(MUSE 包含一个 30 亿参数的 Transformer,以及一个10 亿参数的超分辨 Transformer)
掩蔽计划。按照 MUSE 和 MaskGIT 的做法,使用基于余弦的掩蔽计划来提升性能。一种假设是:凹面(例如,余弦)掩蔽计划受益于较早去噪过程中的固定预测较少,而较晚去噪过程中的固定预测较多。
微调节(Micro-conditioning)。在原始图像分辨率、裁剪坐标 和 LAION 审美分数上进行微调节。微调节值被投影到正弦嵌入中,并作为额外通道附加到最终池化的文本编码器隐藏状态中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- k8s搭建(二、k8s组件安装)
- Mysql适用Sql语句对数据库表的字段进行增加、删除和修改等一系列操作
- 备份方式和Linux基础
- 输电线路分布式故障诊断装置的应用-深圳鼎信
- 20231218给Firefly的AIO-3399J【RK3399】开发板刷Android12挖掘机方案
- FolkMQ 国产消息中间件(助力信创),v1.0.23
- Xcode 15.2 (15C500b) 发布 (含下载) - Apple 平台 IDE
- wordpress在界面将站点地址直接修改为https导致上不去问题的解决办法
- 国产六核CPU,三屏异显,赋能新一代商显
- Java小案例-RocketMQ的11种消息类型,你知道几种?(请求应答消息)