数据分析概述
发布时间:2024年01月07日
1.数据分析的基本类型:
这就不得不提到Gartner分析学价值扶梯模型了,这个模型从复杂度和价值两个维度,将数据分析分为描述性分析(Descriptive Analytics)、诊断性分析(Diagnostic Analytics)、预测性分析(Predictive Analytics)和规范性分析(Prescriptive Analytics)
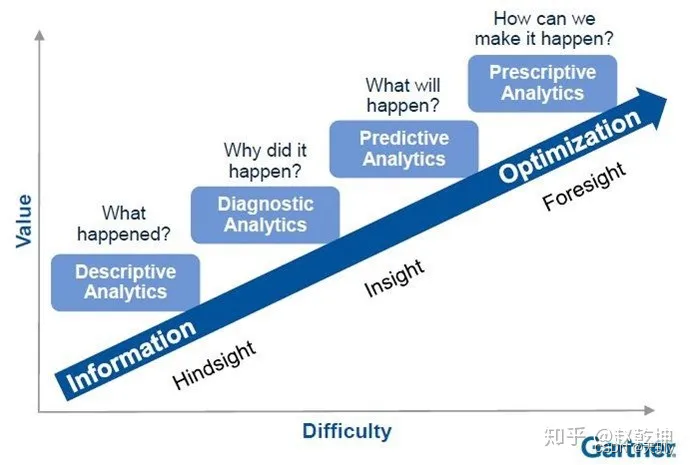
描述性分析:主要关注的是过去,回答“已发生了什么?”,用来揭示客观现象。
诊断性分析:主要关注的是过去,回答“为什么发生?”,用来揭示数据之间的因果关系。
预测性分析:主要关注的是未来,回答“将要发生什么”,属于预测性分析。
规范性分析:主要关注的是模拟与优化,回答“我们如何使它发生”,用来给出最优行动建议,产生产业价值。
2.数据分析的实现方式:
主要有3种:机器学习、统计学、数据可视化
3.机器学习和统计学的区别:
3.1统计学
统计学包括两种:
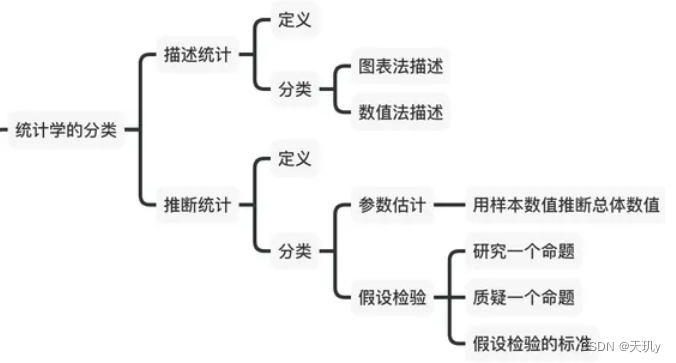
也就是说统计学需要事先对处理对象的概率分布做出假定(比如正态分布),而机器学习不需要做事先假定。
统计学通过各种统计指标(比如R方、置信区间)来评估统计模型(比如线性回归模型)的拟合优度,而机器学习通过交叉验证或划分训练集和测试集的方法来评估算法的准确度。
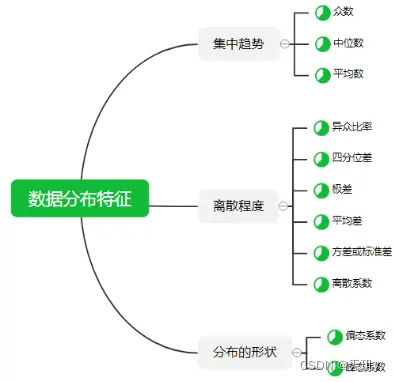
统计学中的描述统计常用的指标有:
统计学中的推断统计(利用样本数据来推断总体特征)常用的理论有:
参数估计(点估计、区间估计)
假设检验(置信度)
3.2机器学习
基于机器学习的数据分析主要分为两个阶段:
- 建模阶段:基于已知数据集(x, y) 和 算法,学习出一个具体的分析模型
- 模型应用阶段:将新样本的特征(x new) 作为分析模型的输入,通过模型计算出对应的目标值(y predicted)
机器学习算法分为:
- 有监督学习:所有示例均有标签数据(包括最近邻、朴素贝叶斯、决策树、随机森林、线性回归、支持向量机、神经网络)
- 无监督学习:所有示例均无标签数据(k-means聚类、主成分分析、关联规则分析)
- 半监督学习:部分示例带有标签信息;部分示例不带标签信息(半监督分类方法、半监督回归方法、半监督聚类方法、半监督降维方法)
小结:
关注我给大家分享更多有趣的知识,以下是个人公众号,提供 ||代码兼职|| ||代码问题求解||
由于本号流量还不足以发表推广,搜我的公众号即可:
文章来源:https://blog.csdn.net/m0_72249799/article/details/135361064
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringBoot集成MongoDB(6.0.12)
- 好用的网站性能监测与服务可用性监测工具盘点
- 爱奇艺批量玩法以及技巧
- 【力扣题解】P94-二叉树的中序遍历-Java题解
- 华为OD机试真题-字符串拼接-2023年OD统一考试(C卷)
- 【算法题】61. 旋转链表
- 八爪鱼拉拉手
- 微信小程序 ---- 通过 URLScheme 或 URLLink 从短信、邮件、微信外网页等场景打开小程序
- 什么是双亲委派模型?
- TSINGSEE青犀基于opencv的安全帽/反光衣/工作服AI检测算法自动识别及应用