检索增强(RAG)的方式---重排序re-ranking
提升RAG:选择最佳嵌入Embedding&重排序Reranker模型
检索增强生成(RAG)技术创新进展:自我检索、重排序、前瞻检索、系统2注意力、多模态RAG
RAG的re-ranking指的是对初步检索出来的候选段落或者文章,通过重新排序的方式来提升检索质量。具体来说:
- RAG首先采用信息检索模型在知识库中检索出与用户查询最相关的一些候选段落或者文章。
- 然后这些候选结果作为输入,通过一个深度学习模型对它们进行重新评分。
- 这个深度学习模型通常会考虑更丰富的特征,比如:
- 用户查询和候选结果中的关键词匹配程度
- 用户查询和候选结果上下文匹配程度
- 用户历史偏好信息
- 候选结果质量反馈信号,如被用户点击次数等
- 经过这个模型计算后的新得分就表示候选结果的真实质量,将得分高的排在前面,实现初步检索结果的重新排序。
- 这样就可以将最相关和质量最高的几个段落或者文章作为RAG系统后续生成对话的输入知识。
所以总体来说,RAG的re-ranking是采用深度学习模型,在初步检索结果基础上加入更多维度的证据,对它们进行全面评估,得出一个重新排序的结果,以提升整体系统性能。
Rerank模型:
为了评估检索系统的准确性,主要依靠两个广泛应用的指标:命中率(Hit Rate)和平均倒数排名(MRR)。考虑到命中率和MRR时,OpenAI+CohereRerank和Voyage+big-reranker-large的组合成为最热门的竞争者。?
命中率(Hit Rate)和平均倒数排名(Mean Reciprocal Rank,简称MRR)是两种常用的信息检索系统性能指标:
命中率(Hit Rate):
计算一个查询中的有效文档是否在前K个检索结果中,如果有则算命中。
Hit Rate = 有效查询中的命中次数 / 总查询次数
用于衡量是否能检索出相关文档,值越大表示系统检索能力越强。
平均倒数排名(MRR):
对每个查询,计算第一位有效文档的倒数排名。如排在第二位,倒数排名为1/2。
MRR = 查询数量的倒数排名总和 / 总查询数量
用于衡量有效文档检索的平均排名位置,值越大表示平均检索效果越好。
区别:
Hit Rate看重是否能检索出相关文档,但不考虑排序质量。
MRR同时考虑检索能力和排序能力,强调首个有效文档应排在前面。
所以两者补充考察了检索系统不同层面的性能,通常结合使用可以获得更全面评估。Hit Rate>=50%,MRR>=0.9表示检索质量较高。
不同的重排序方法
-
使用检索模型进行二次检索:一种常见的重排序方法是使用检索模型进行二次检索。在初始检索后,通过利用更复杂的模型,例如基于嵌入的检索模型,可以再次检索相关文档。这有助于更精确地捕捉文档与查询之间的语义关系。
-
使用交叉模型进行打分:另一种方法是利用交叉模型进行文档打分。这种模型可以考虑文档和查询之间的交互特征,从而更细致地评估它们之间的关联度。通过结合不同特征的交互,可以得到更准确的文档排序。
-
利用大模型进行重排序:大型语言模型(LLM)等大模型的崛起为重排序提供了新的可能性。这些模型通过对整个文档和查询进行深层次的理解,能够更全面地捕捉语义信息。
方法1:交叉模型进行重排序
与嵌入模型不同,重新排序器使用问题和文档作为输入,直接输出相似度而不是嵌入。通过将查询和段落输入到重新排序器中,你可以获得相关性分数。重新排序器是基于交叉熵损失进行优化的,因此相关性分数不受限于特定范围。
BGE Reranker
https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker
import?torch
from?transformers?import?AutoModelForSequenceClassification,?AutoTokenizer
tokenizer?=?AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model?=?AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs?=?[['what?is?panda?',?'hi'],?['what?is?panda?',?'The?giant?panda?(Ailuropoda?melanoleuca),?sometimes?called?a?panda?bear?or?simply?panda,?is?a?bear?species?endemic?to?China.']]
with?torch.no_grad():
????inputs?=?tokenizer(pairs,?padding=True,?truncation=True,?return_tensors='pt',?max_length=512)
????scores?=?model(**inputs,?return_dict=True).logits.view(-1,?).float()
????print(scores)
这个重新排序器是从xlm-roberta-base初始化的,并在混合的多语言数据集上进行训练:
- 中文:来自T2ranking、MMmarco、dulreader、Cmedqa-v2和nli-zh的788,491个文本对。
- 英文:来自msmarco、nq、hotpotqa和NLI的933,090个文本对。
- 其他语言:来自Mr.TyDi的97,458个文本对(包括阿拉伯语、孟加拉语、英语、芬兰语、印度尼西亚语、日语、韩语、俄语、斯瓦希里语、泰卢固语、泰语)。
CohereRerank
#?pip?install?cohere
import?cohere
api_key?=?""
co?=?cohere.Client(api_key)
query?=?"What?is?the?capital?of?the?United?States?"
docs?=?[
????"Carson?City?is?the?capital?city?of?the?American?state?of?Nevada.?At?the?2010?United?States?Census,?Carson?City?had?a?population?of?55,274.",
????"The?Commonwealth?of?the?Northern?Mariana?Islands?is?a?group?of?islands?in?the?Pacific?Ocean?that?are?a?political?division?controlled?by?the?United?States.?Its?capital?is?Saipan.",
????"Charlotte?Amalie?is?the?capital?and?largest?city?of?the?United?States?Virgin?Islands.?It?has?about?20,000?people.?The?city?is?on?the?island?of?Saint?Thomas.",
????"Washington,?D.C.?(also?known?as?simply?Washington?or?D.C.,?and?officially?as?the?District?of?Columbia)?is?the?capital?of?the?United?States.?It?is?a?federal?district.?The?President?of?the?USA?and?many?major?national?government?offices?are?in?the?territory.?This?makes?it?the?political?center?of?the?United?States?of?America.",
????"Capital?punishment?(the?death?penalty)?has?existed?in?the?United?States?since?before?the?United?States?was?a?country.?As?of?2017,?capital?punishment?is?legal?in?30?of?the?50?states.?The?federal?government?(including?the?United?States?military)?also?uses?capital?punishment."]
????
results?=?co.rerank(query=query,?documents=docs,?top_n=3,?model='rerank-english-v2.0')?#?Change?top_n?to?change?the?number?of?results?returned.?If?top_n?is?not?passed,?all?results?will?be?returned.
实验结果
从数据中清晰可见重新排序器在优化搜索结果方面的重要性。几乎所有嵌入都受益于重新排序,表现出改善的命中率和MRR。
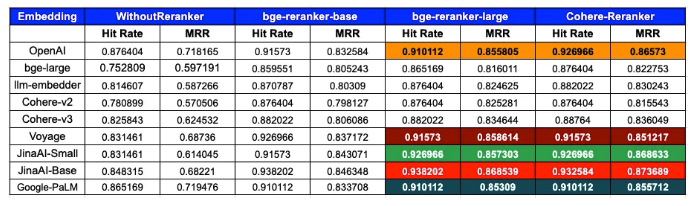
-
bge-reranker-large:对于多个嵌入,该重新排序器经常提供了最高或接近最高的MRR,有时其性能与CohereRerank相媲美甚至超过。
-
CohereRerank:在所有嵌入上一致提升性能,往往提供最佳或接近最佳的结果。
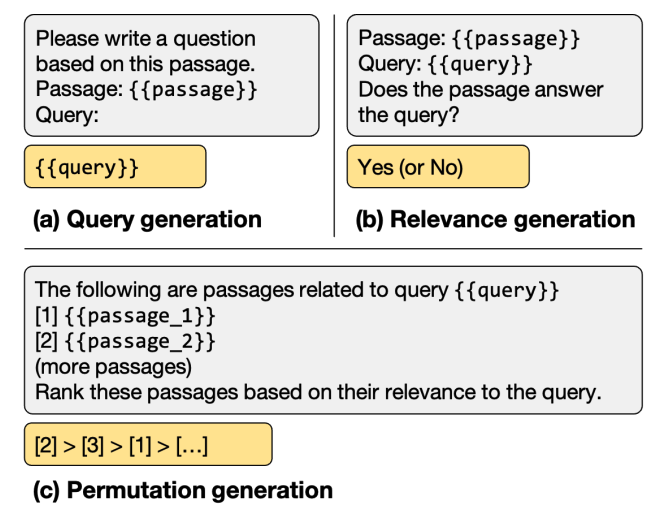
方法2:大模型进行重排序
现有的涉及LLM的重排方法大致可以分为三类:用重排任务微调LLM,使用prompt让LLM进行重排,以及利用LLM做训练数据的增强。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 6314A/B/C 稳定光源
- 【STM32】STM32学习笔记-ADC模数转换器(21)
- Tortoise-orm 使用(二) 元类及Mixin
- React Native:入门知识了解
- c语言操作符详解(三)
- 创意无限!在线画图必备工具,这十款使用率超高,让你随心所欲
- 栈的数据结构实验报告
- C //练习 4-4 在栈操作中添加几个命令,分别用在不弹出元素的情况下打印栈顶元素;复制栈顶元素;交换栈顶两个元素的值。另外增加一个命令用于清空栈。
- PyTorch各种损失函数解析:深度学习模型优化的关键(2)
- mysql数据库学习笔记(1)