paddleocr的基本使用
paddleocr是paddlepaddle专门做ocr的库,我们简单用一下
目录
1??安装
1.1??前言
我使用的系统为windows,python版本为python3.7,paddleocr版本为2.7.0.2
我的显卡是GTX970M,估计是硬件问题,后续使用代码的时候如果使用GPU就不能预测出结果,但CPU可以预测出结果。但在更新CUDA后,在任务管理器中可以查看到GPU的使用情况(之前很少)

综上所述下面安装paddlepaddle-gpu版流程是不一定正确的
1.2??安装paddleocr
pip intall paddleocr


1.3??安装paddlepaddle
之后安装paddlepaddle,由于3.7是很早的版本了,所以直接执行 pip install paddlepaddle-gpu 大概率是可以对应上paddleocr的,最终安装paddlepaddle的版本为2.5.2
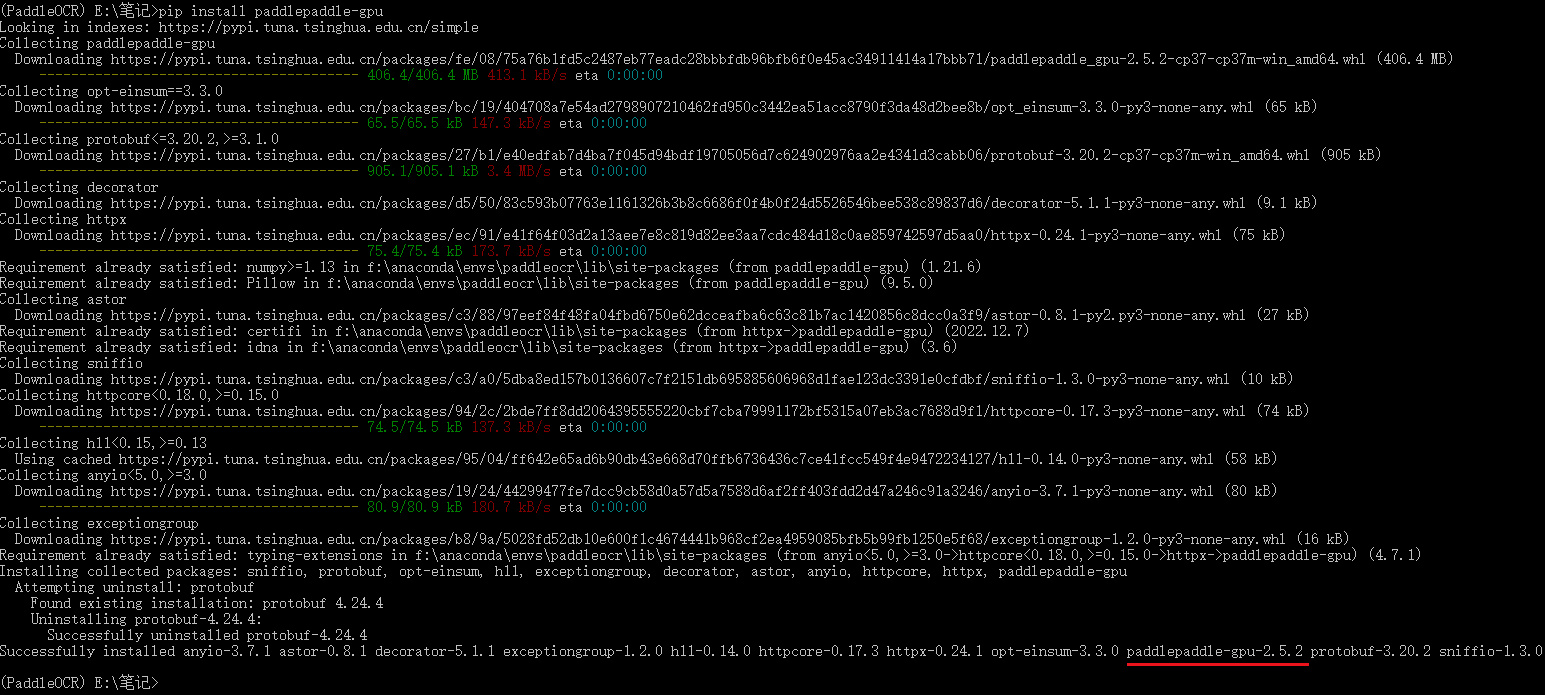
1.4??安装cuda
paddlepaddle-gpu-2.5.2需要cuda与cudnn,我目前这两个版本都比较落后,所以我们需要安装一下新的

首先找到cuda的安装包?CUDA Toolkit Archive | NVIDIA Developer

这里的Version指的是windows server,一般选最新的就行,感兴趣可以看一下这个?windows server_百度百科

之后你会下载下来这样一个exe

打开

OK
- 这个只是临时存放的路径,如果我们C盘空间不够可以换其他的地方
等

到100%后,等一会儿会出现这个


等




安装完cuda之后,显卡驱动会自动更新到合适的版本

如果按照上面的方式安装的话,默认安装在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.0
安装之后环境变量也自动给你搞好了
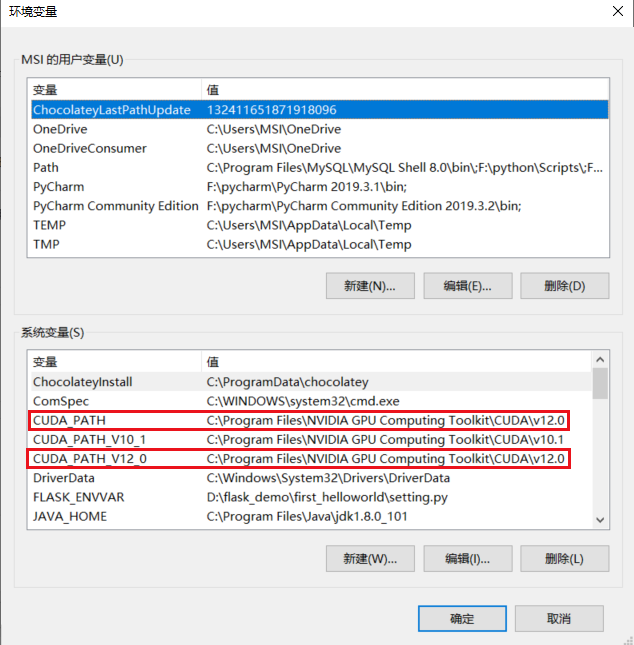
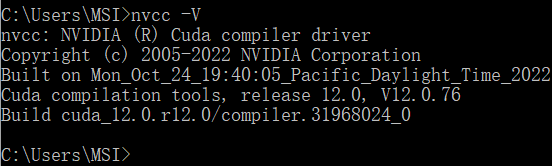
确定这里有环境变量之后,我们重新启动一下,重启后执行 nvcc -V 可以显示cuda12.0
1.5??安装cudnn
我们首先进入cudnn的下载地址?Log in | NVIDIA Developer?,首先你需要登录一下
之后需要做个问卷,随便选选就行了,但是你最好每个空都填一填,不然通过不了

同意

更多

进到这个页面,这个页面需要加载一会儿,完全加载完毕后再进行下面的操作

向下滚到这,然后点击

点开之后点这个
之后你会获得这样一个压缩包

解压之后的文件夹内会有这四个文件

把这三个文件夹的东西,手动复制到CUDA的安装目录下
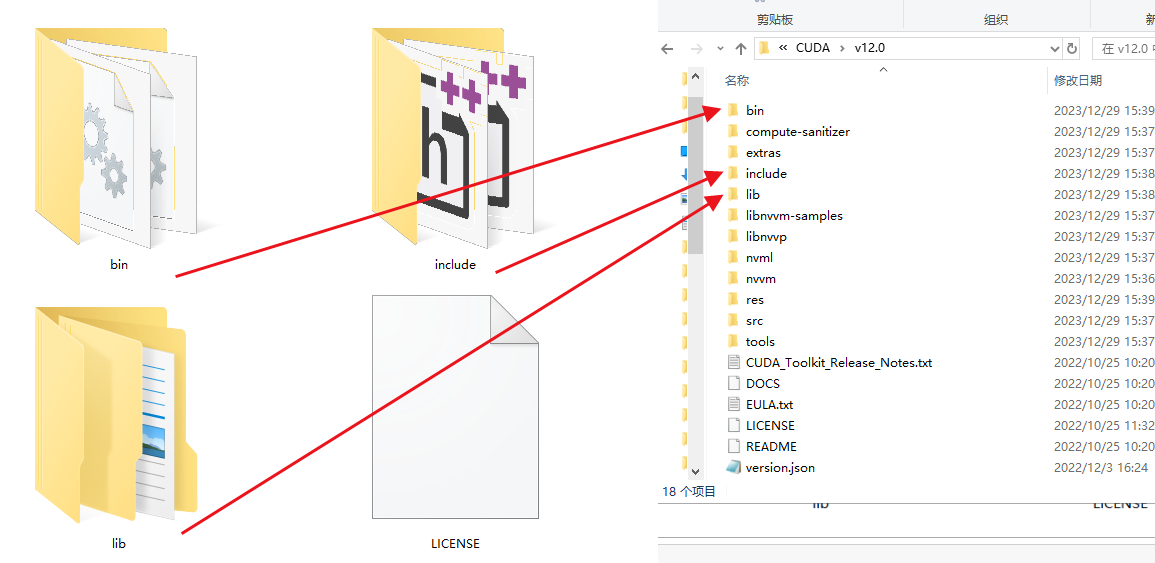
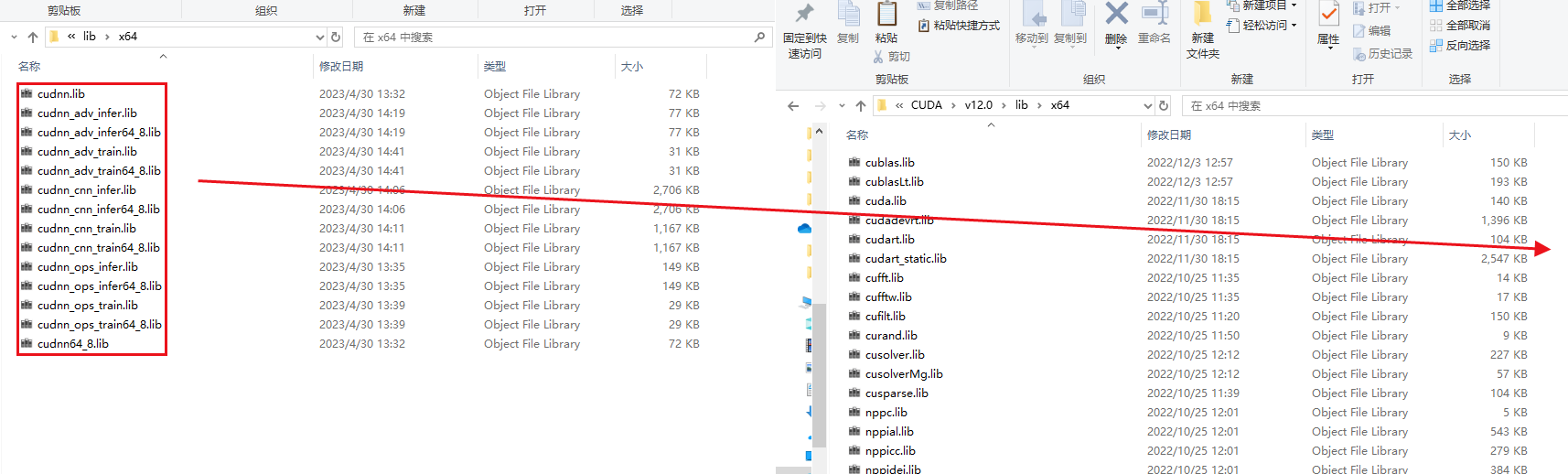
lib会有一个x64的子文件夹,你打开x64,把这些lib文件扔进去
1.6??配置 zlibwapi.dll
我直接用的人家的百度云链接,解压之后会得到这么三个文件

打开dll_x64找到zlibwapi.dll与zlibwapi.lib

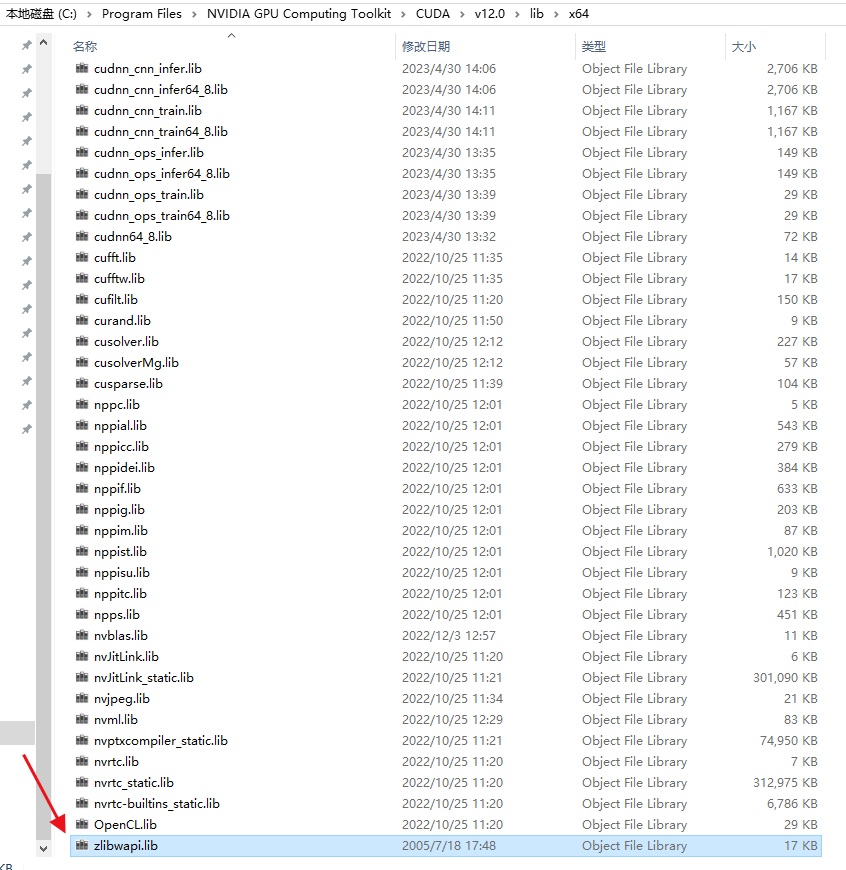
将zlibwapi.lib放在CUDA/v12.0/lib/x64中
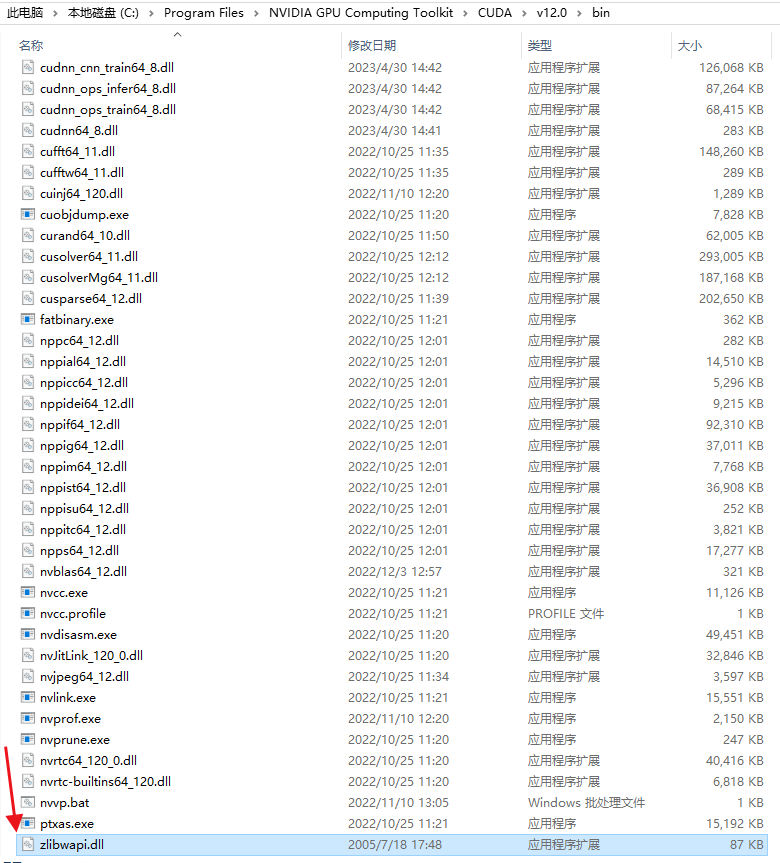
将zlibwapi.dll放在 CUDA/v12.0/bin 中
2??基本使用
我们准备预测这个图像
在预测前我们需要准备simfang.ttf
simfang.ttf 是仿宋字体,可以在 C:\Windows\Fonts 中找到
之后我们直接使用文档中的代码?doc/doc_ch/quickstart.md · PaddlePaddle/PaddleOCR - Gitee.com

对代码做一些修改

运行后会生成result.jpg

打开后是这样的

3??针对单行文本的识别
3.1??识别本地图像
比如验证码,我们先写个demo
from paddleocr import PaddleOCR
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch",use_gpu=False) # need to run only once to download and load model into memory
img_path = './RandCode.png'
result = ocr.ocr(img_path, cls=True)
print()
print(result[0][0][1][0])我现在想识别这个图像

运行后可以得到结果

3.2??服务
现在每一次预测都实例化一次对象,这个时间比较长,我们简单搞一个服务

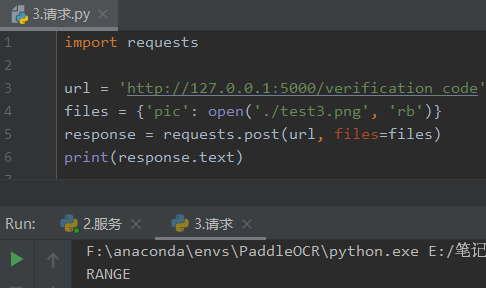
3.3??请求
之后我们直接发请求就可以了

经测试车牌也可以检测出来,比如


但必须是单行文本(服务端只做了简单处理,如果处理好一点也没有问题),比如这个就不行

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【python】python实现代码雨【附源码】
- Docker部署
- 数据库攻防学习
- 加速应用开发:低代码云SaaS和源码交付模式如何选
- CT检测中的CT是什么意思,可以用来哪些检测,如何成像的。
- Leetcode—1572.矩阵对角线元素的和【简单】
- python实现定时访问web并点击按钮任务
- Redis命令 - Hashes命令组常用命令
- 必备 | SQL语句的封装操作大全
- 智慧地球(AI?Earth)社区成立一周年啦!独家福利与惊喜彩蛋等你来拿!