MySQL数据库 | 事务中的一些问题(重点)
文章目录
什么是事务?
数据库中的事务是指对数据库执行一批操作,在同一个事务当中,这些操作最终要么全部执行成功,要么全部失败,不会存在部分成功的情况。
- 事务是一个原子操作。是一个最小执行单元。可以甶一个或多个SQL语句组成
- 在同一个事务当中,所有的SQL语句都成功执行时,整 个事务成功,有一个SQL语句执行失败,整个事务都执行失败。
举个例子:
比如A用户给B用户转账100操作,过程如下:
- 从A账户扣100
- 给B账户加100
如果在事务的支持下,上面最终只有2种结果:
- 操作成功:A账户减少100;B账户增加100
- 操作失败:A、B两个账户都没有发生变化
如果没有事务的支持,可能出现错:A账户减少了100,此时系统挂了,导致B账户没有加上100,而A账户凭空少了100。
事务的几个特性(ACID) -重点
原子性(Atomicity)
事务的整个过程如原子操作一样,最终要么全部成功,或者全部失败,这个原子性是从最终结果来看的,从最终结果来看这个过程是不可分割的。
一致性(Consistency)
一个事务必须使数据库从一个一致性状态变换到另一个一致性状态。
首先回顾一下一致性的定义。所谓一致性,指的是数据处于一种有意义的状态,这种状态是语义上的而不是语法上的。最常见的例子是转帐。例如从帐户A转一笔钱到帐户B上,如果帐户A上的钱减少了,而帐户B上的钱却没有增加,那么我们认为此时数据处于不一致的状态。
从这段话的理解来看,所谓一致性,即,从实际的业务逻辑上来说,最终结果是对的、是跟程序员的所期望的结果完全符合的
隔离性(Isolation)
一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
这里先提一下事务的隔离级别:
- 读未提交:read uncommitted
- 读已提交:read committed
- 可重复读:repeatable read
- 串行化:serializable
持久性(Durability)
一个事务一旦提交,他对数据库中数据的改变就应该是永久性的。当事务提交之后,数据会持久化到硬盘,修改是永久性的。
Mysql中事务操作
mysql中事务默认是隐式事务,执行insert、update、delete操作的时候,数据库自动开启事务、提交或回滚事务。
是否开启隐式事务是由变量autocommit控制的。
所以事务分为隐式事务和显式事务。
隐式事务
事务自动开启、提交或回滚,比如insert、update、delete语句,事务的开启、提交或回滚由mysql内部自动控制的。
查看变量autocommit是否开启了自动提交
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set, 1 warning (0.00 sec)
显式事务
事务需要手动开启、提交或回滚,由开发者自己控制。
2种方式手动控制事务:
方式1:
语法:
//设置不自动提交事务
set autocommit=0;
//执行事务操作
commit|rollback;
示例1:提交事务操作,如下:
mysql> create table test1 (a int);
Query OK, 0 rows affected (0.01 sec)
mysql> select * from test1;
Empty set (0.00 sec)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test1 values(1);
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
示例2:回滚事务操作,如下:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test1 values(2);
Query OK, 1 row affected (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
可以看到上面数据回滚了。
我们把autocommit还原回去:
mysql> set autocommit=1;
Query OK, 0 rows affected (0.00 sec)
方式2:
语法:
start transaction;//开启事务
//执行事务操作
commit|rollback;
示例1:提交事务操作,如下:
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test1 values (2);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test1 values (3);
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
上面成功插入了2条数据。
示例2:回滚事务操作,如下:
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from test1;
Query OK, 3 rows affected (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
上面事务中我们删除了test1的数据,显示删除了3行,最后回滚了事务
savepoint关键字
在事务中我们执行了一大批操作,可能我们只想回滚部分数据,怎么做呢?
我们可以将一大批操作分为几个部分,然后指定回滚某个部分。可以使用savepoin来实现,效果如下:
先清除test1表数据:
mysql> delete from test1;
Query OK, 3 rows affected (0.00 sec)
mysql> select * from test1;
Empty set (0.00 sec)
演示savepoint效果,认真看:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test1 values (1);
Query OK, 1 row affected (0.00 sec)
mysql> savepoint part1;//设置一个保存点
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test1 values (2);
Query OK, 1 row affected (0.00 sec)
mysql> rollback to part1;//将savepint = part1的语句到当前语句之间所有的操作回滚
Query OK, 0 rows affected (0.00 sec)
mysql> commit;//提交事务
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
从上面可以看出,执行了2次插入操作,最后只插入了1条数据。
savepoint需要结合rollback to sp1一起使用,可以将保存点sp1到rollback to之间的操作回滚掉
只读事务
表示在事务中执行的是一些只读操作,如查询,但是不会做insert、update、delete操作,数据库内部对只读事务可能会有一些性能上的优化。
用法如下:
start transaction read only;
示例:
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> start transaction read only;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
| 1 |
+------+
2 rows in set (0.00 sec)
mysql> delete from test1;
ERROR 1792 (25006): Cannot execute statement in a READ ONLY transaction.
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test1;
+------+
| a |
+------+
| 1 |
| 1 |
+------+
2 rows in set (0.00 sec)
只读事务中执行delete会报错。
事务中的一些问题(重点)
这些问题主要是基于数据在多个事务中的可见性来说的。也是并发事务产生的问题。
隔离级别
当多个事务同时进行的时候,如何确保当前事务中数据的正确性,比如A、B两个事物同时进行的时候,A是否可以看到B已提交的数据或者B未提交的数据,这个需要依靠事务的隔离级别来保证,不同的隔离级别中所产生的效果是不一样的。
事务隔离级别主要是解决了上面多个事务之间数据可见性及数据正确性的问题。(或者说为了解决并发控制可能产生的异常问题,数据库定义了四种事务的隔离级别)
隔离级别 有四种,分别是:读未提交、读已提交、可重复读、序列化。
- 读未提交: Read Uncommitted,顾名思义,就是一个事务可以读取另一个未提交事务的数据。最低级别,它存在4个常见问题(脏读、不可重复读、幻读、丢失更新)。
- 读已提交: Read Committed,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。 它解决了脏读问题,存在3个常见问题(不可重复读、幻读、丢失更新)。
- 可重复读: Repeatable Read,就是在开始读取数据(事务开启)时,不再允许修改操作 。它解决了脏读和不可重复读,还存在2个常见问题(幻读、丢失更新)。
- 序列化: Serializable,序列化,或串行化。就是将每个事务按一定的顺序去执行,它将隔离问题全部解决,但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
大多数数据库默认的事务隔离级别是 Read Committed,比如 SQL Server , Oracle。但 MySQL 的默认隔离级别是 Repeatable Read。
上面4中隔离级别越来越强,会导致数据库的并发性也越来越低。
查看隔离级别
mysql> show variables like 'transaction_isolation';
+-----------------------+----------------+
| Variable_name | Value |
+-----------------------+----------------+
| transaction_isolation | READ-COMMITTED |
+-----------------------+----------------+
1 row in set, 1 warning (0.00 sec)
隔离级别的设置
分2步骤,修改文件、重启mysql,如下:
修改mysql中的my.init文件,我们将隔离级别设置为:READ-UNCOMMITTED,如下:
# 隔离级别设置,READ-UNCOMMITTED读未提交,READ-COMMITTED读已提交,REPEATABLE-READ可重复读,SERIALIZABLE串行
transaction-isolation=READ-UNCOMMITTED
脏读
一个事务在执行的过程中读取到了其他事务还没有提交的数据。 这个还是比较好理解的。
两个事务同时操作同一数据,A事务对该数据进行了修改还没提交的时候,B事务访问了该条事务,并且使用了该数据,此时A事务回滚,那么B事务读到的就是脏数据。
事例
老板要给程序员发工资,程序员的工资是3.6万/月。但是发工资时老板不小心按错了数字,按成3.9万/月,该钱已经打到程序员的户口,但是事务还没有提交,就在这时,程序员去查看自己这个月的工资,发现比往常多了3千元,以为涨工资了非常高兴。但是老板及时发现了不对,马上回滚差点就提交了的事务,将数字改成3.6万再提交。
分析
实际程序员这个月的工资还是3.6万,但是程序员看到的是3.9万。他看到的是老板还没提交事务时的数据。这就是脏读,也就是看到了脏的数据。
演示脏读
1、新建一个数据库(bank库),并准备一张表(account表)
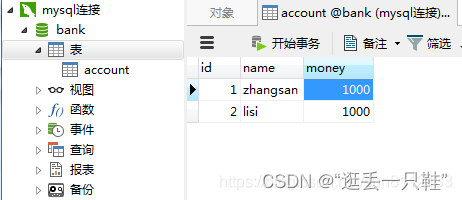
2、打开两个窗口,并分别设置自动提交方式为off
show variables like 'autocommit'; – 查看当前的自动提交是否开启
set autocommit = off; – 将自动提交关闭
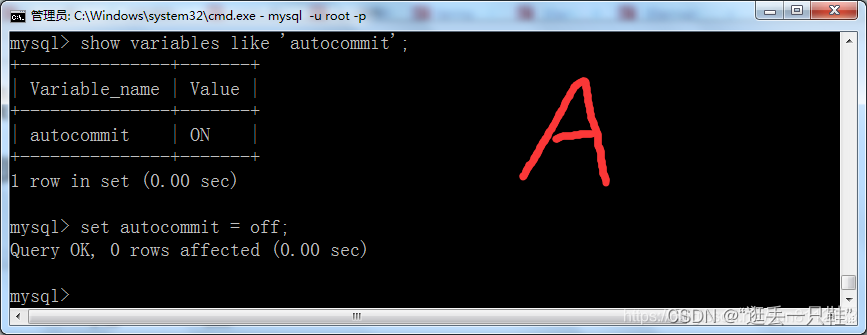
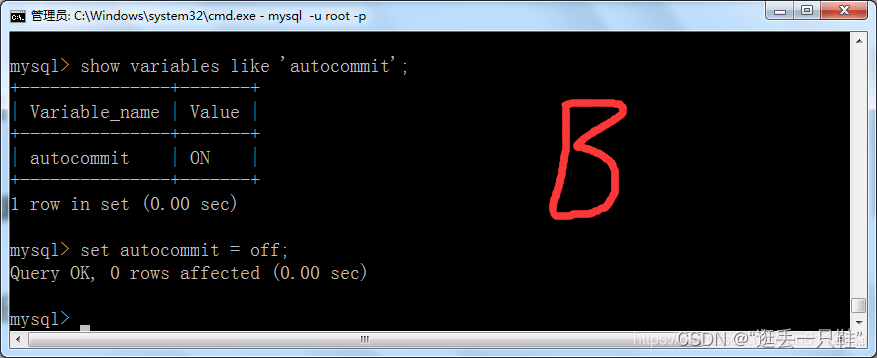
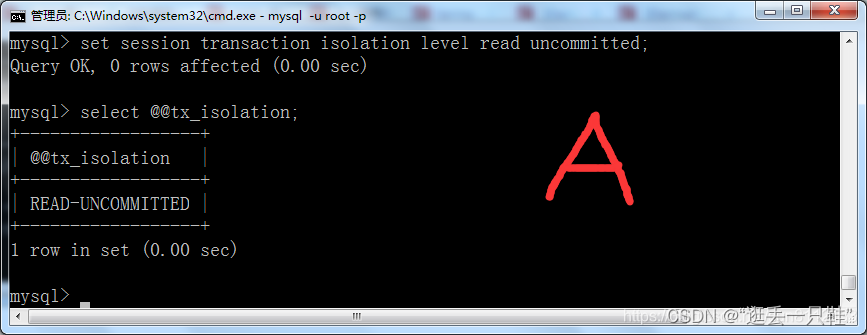
3、将A窗口的隔离级别设置成 “读未提交”
select @@tx_isolation; – 查询当前的隔离级别
set session transaction isolation level read uncommitted; – 设置当前会话隔离级别为“读未提交”
4、两个窗口分别开启事务
start transaction; – 开启事务 或 begin; 也可以显式开启事务
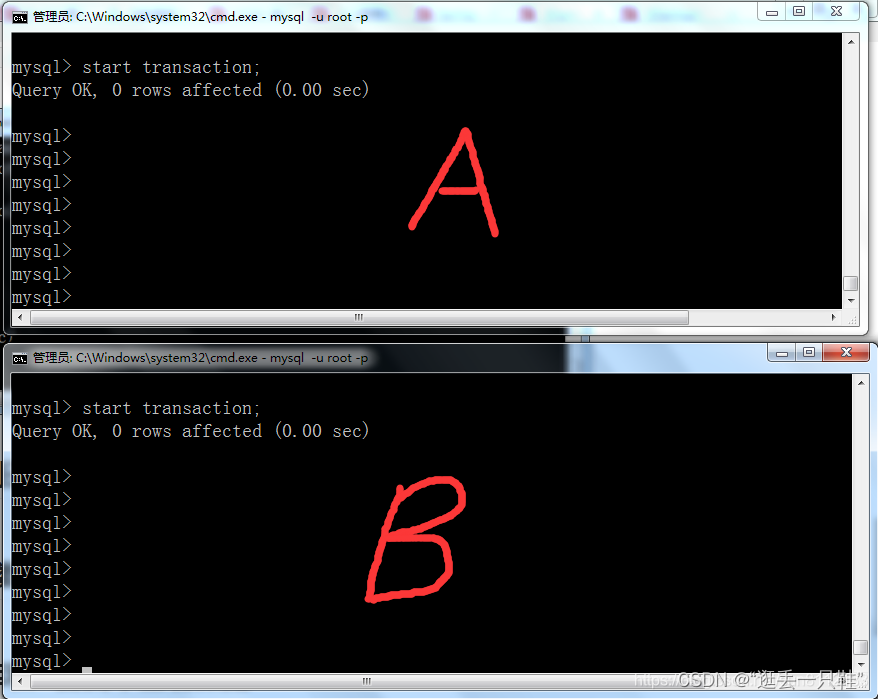
5、在B窗口更改数据,但不要提交事务
update account set money = money - 100 where id = 1; – 修改account表中id为1的money字段数据
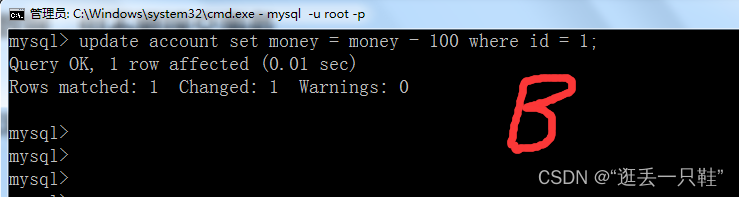
6、分别在数据库和A窗口中查看数据
select * from account; – 查看account中的全部数据
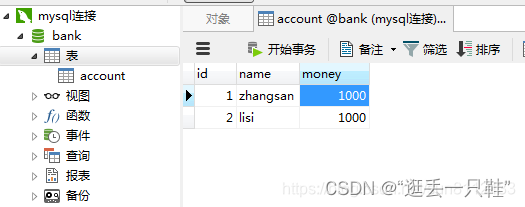
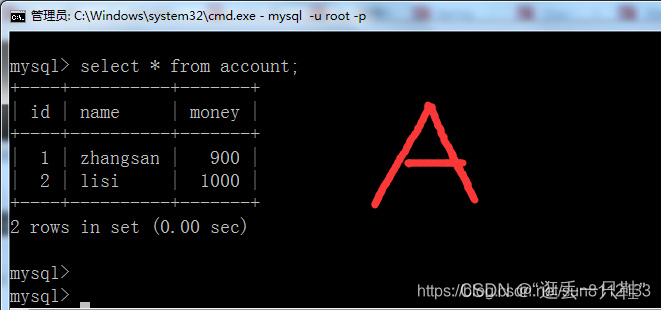
因为B窗口还没有提交事务,所以数据库中的数据是不会发生改变的,这个是正常现象。
而下一个现象你会惊喜的发现,A窗口却读到了B窗口更新后但还未提交的数据。
这就是A窗口读到了 “脏的数据”,这个现象就是 “脏读”,“读未提交” 这种隔离级别会发生 “脏读”、“不可重复读”、“幻读”、“丢失更新” 这四个问题。
解决办法:
- 方法1:事务隔离级别设置为:read committed 读已提交。
- 方法2:**读取时加排它锁(select…for update),事务提交才会释放锁,修改时加共享锁(update …lock in share mode)。**加排它锁后,不能对该条数据再加锁,能查询但不能更改数据。
mysql InnoDB引擎默认的修改数据语句,update,delete,insert都会自动给涉及到的数据加上排他锁,select语句默认不会加任何锁类型,如果加排他锁可以使用select …for update语句,如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁,共享锁下其它用户可以并发读取,查询数据。但不能修改,增加,删除数据。资源共享。
幻读
脏读、不可重复读、可重复读、幻读,其中最难理解的是幻读
以mysql为例:
幻读现象例子:
可重复读模式下,比如有个用户表,手机号码为主键,有两个事物进行如下操作
事务A操作如下:
1、打开事务
2、查询号码为X的记录,不存在
3、插入号码为X的数据,插入报错(为什么会报错,先向下看)
4、查询号码为X的记录,发现还是不存在(由于是可重复读,所以读取记录X还是不存在的)
事物B操作:在事务A第2步操作时插入了一条X的记录,所以会导致A中第3步插入报错(违反了唯一约束)
上面操作对A来说就像发生了幻觉一样,明明查询X(A中第二步、第四步)不存在,但却无法插入成功
幻读可以这么理解:事务中后面的操作(插入号码X)需要上面的读取操作(查询号码X的记录)提供支持,但读取操作却不能支持下面的操作时产生的错误,就像发生了幻觉一样。
看第二种解释:
事务A在操作一堆数据的时候,事务B插入了一条数据,A事务再次(第二次)查询,发现多了一条数据,像是幻觉。与不可重复读类似,不同的是一个是修改删除操作,一个是新增操作。
如果还是理解不了的,继续向下看,后面后详细的演示。
1、事例
程序员某一天去消费,花了2千元,然后他的妻子去查看他今天的消费记录(妻子事务开启),看到确实是花了2千元,就在这个时候,程序员花了1万买了一部电脑,即新增INSERT了一条消费记录,并提交。当妻子打印程序员的消费记录清单时(妻子事务提交),发现有两条记录,共花了1.2万元,似乎出现了幻觉,这就是幻读。
2、分析
在这个事例中,事务B读取了数据,接着另一个事务A插入了一条数据。在随后的查询中,事务B就会发现多了一条原本不存在的记录,就好像发生了幻觉一样,这是由于数据新增导致的。
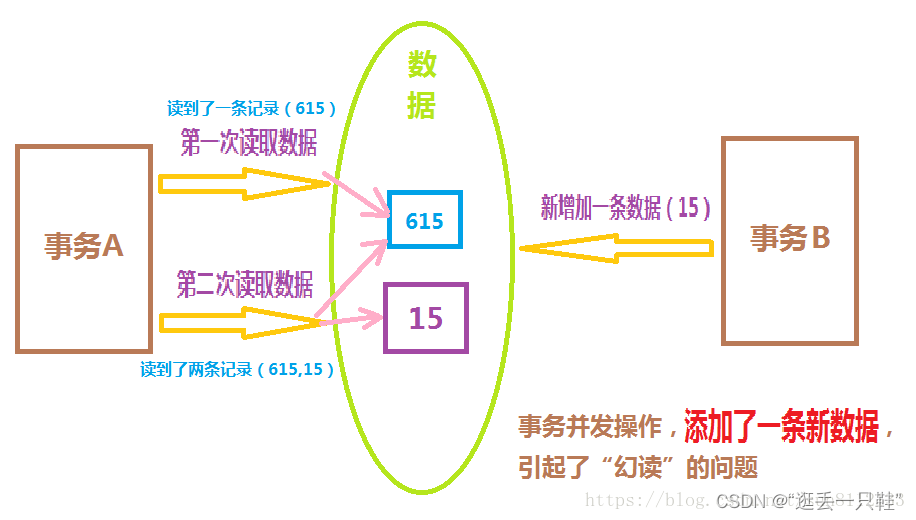
演示幻读
1、新建一个数据库(bank库),并准备一张表(account表)
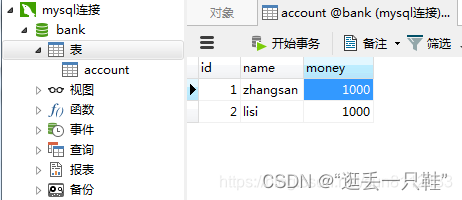
2、打开两个窗口,并分别设置自动提交方式为off
show variables like 'autocommit'; – 查看当前的自动提交是否开启
set autocommit = off; – 将自动提交关闭
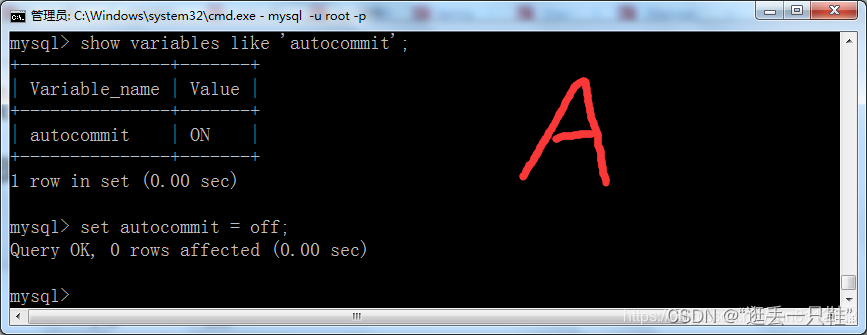
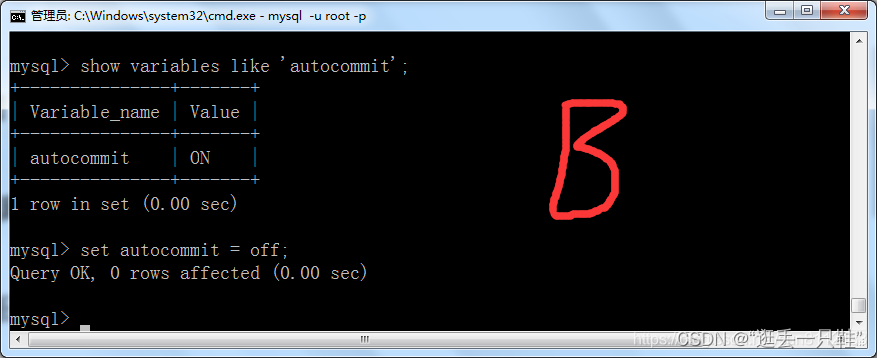
3、将A窗口的隔离级别设置成 “读已提交”
注意: 虽然 “可重复读” 这种隔离级别也会发生“幻读”这个问题,但是如果设置成这种隔离级别是演示不出效果的,因为只有在多个事务并发了,才可能出现 “幻读” 问题了,但是大家要记住“可重复读”这种隔离级别也是有可能会出现“幻读”的。
select @@tx_isolation; – 查询当前的隔离级别
set session transaction isolation level read committed; – 设置当前会话隔离级别为“读已提交”
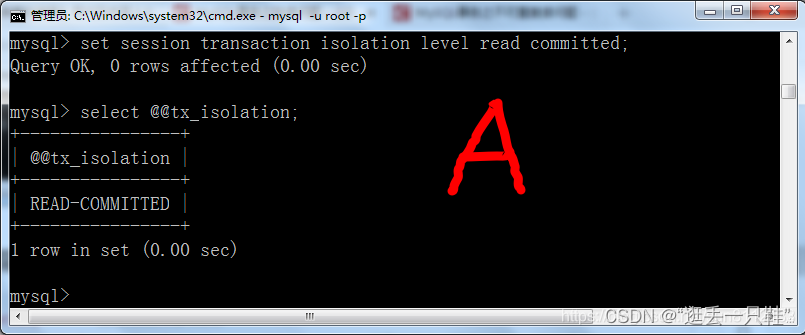
4、两个窗口分别开启事务
start transaction; – 开启事务 或 begin; 也可以显式开启事务
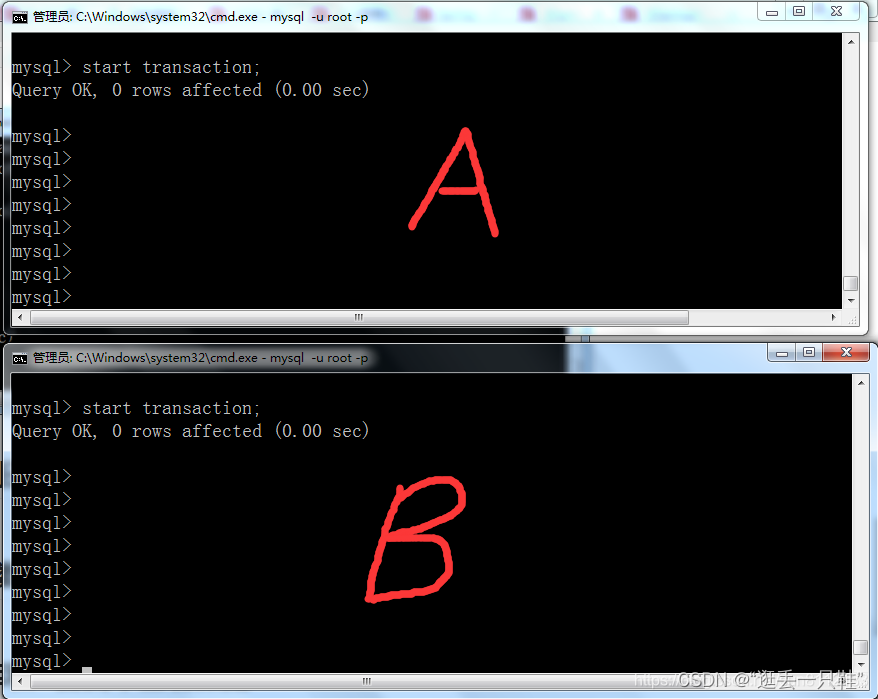
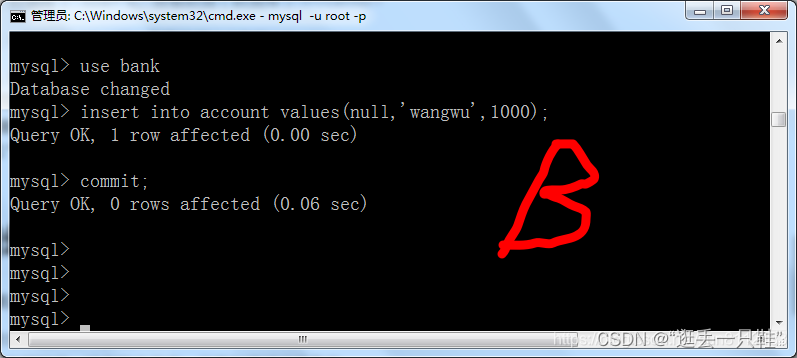
5、在B窗口新增一条数据,并提交事务
use bank – 切换到bank数据库
insert into account values(null, 'wangwu', 1000); – 增加一条数据
commit; – 提交事务
6、分别在数据库和A窗口中查看数据
select * from account; – 查看account中的全部数据
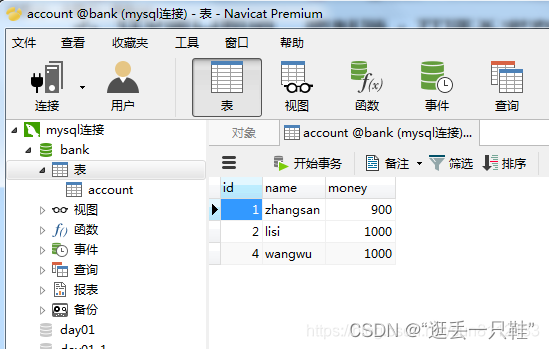
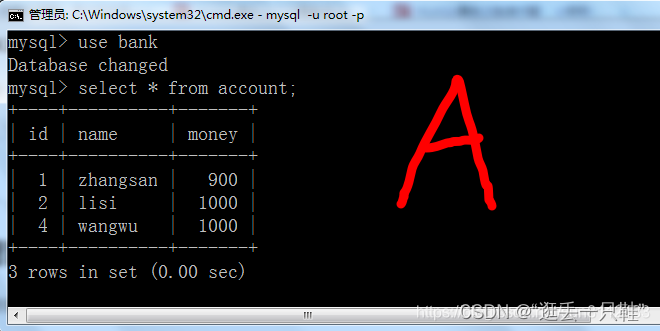
这种效果和 不可重复读 的效果是一样的。
数据库和A窗口中的数据都发生了改变,因为B窗口已经提交了事务,所以数据库中的数据发生改变,是属于正常现象。
但是这种事务的隔离性似乎不是太好(事务的隔离性是一个事务的执行,不受其他事务的干扰)
B窗口提交了事务,影响到了A窗口中数据,这种隔离级别虽然解决了 ”脏读“ 问题,但是还会引发 “不可重复读”、“幻读”及“丢失更新” 问题。
不可重复读和幻读的区别
大家可能会有这样的疑问,幻读不是因为第二次读到的结果和第一次读到的结果不一样而产生幻觉,所以叫幻读嘛?好像不可重复读也是这样的,那为什么不可重复读不叫幻读呢?那是因为大家可能忽略了一个细节,不可重复读改变的是同一条数据,而幻读改变的是数据的条数。第一次读到一条,第二次却读到了两条,好像产生了幻觉一样,所以叫幻读;而不可重复读是第一次读到这个数据的值和第二次读到这个数据的值不一样,也就是相同的数据不能重复读两次,否则会出错,所以它叫做不可重复读。
不可重复读的重点是修改数据,幻读的重点是新增或者删除记录。
不可重复读,改变的是数据,数据记录总条数并没有发生改变;
幻读,改变的是数据记录总条数,原来数据的值,没有发生改变,只是新增了记录条数。
更新丢失
丢失更新就是两个不同的事务(或者Java程序线程)在某一时刻对同一数据进行读取后,先后进行修改。导致第一次操作数据丢失。
第一类丢失更新:A,B 事务同时操作同一数据,A先对改数据进行了更改,B再次更改时失败然后回滚,把A更新的数据也回滚了。(事务撤销造成的撤销丢失)
第二类丢失更新:A,B 事务同时操作同一数据,A先对改数据进行了更改,B再次更改并且提交,把A提交的数据给覆盖了。(事务提交造成的覆盖丢失)
小结
-
读未提交( Read Uncommitted )
- 读未提交是隔离级别最低的一种事务级别。 在这种隔离级别下,一个事务会读到另一个事务更新后但未提交的数据,如果另一个事务回滚,那么当前事务读到的数据就是脏数据,这就是脏读(Dirty Read)。
-
读已提交( Read Committed )
- 在 Read Committed 隔离级别下,一个事务可能会遇到不可重复读(Non Repeatable Read)的问题。不可重复读是指,在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致。
-
可重复读( Repeatable Read ) 默认级别
- 在Repeatable Read隔离级别下,一个事务可能会遇到幻读(Phantom Read)的问题。幻读是指,在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,竟然能成功,并且,再次读取同一条记录,它就神奇地出现了。幻读就是没有读到的记录,以为不存在,但其实是可以更新成功的,并且,更新成功后,再次读取,就出现了。
-
可串行化( Serializable )
- Serializable 是最严格的隔离级别。在Serializable隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现。
虽然 Serializable 隔离级别下的事务具有最高的安全性,但是,由于事务是串行执行,所以效率会大大下降,应用程序的性能会急剧降低。如果没有特别重要的情景,一般都不会使用Serializable隔离级别。
- Serializable 是最严格的隔离级别。在Serializable隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现。
默认隔离级别:如果没有指定隔离级别,数据库就会使用默认的隔离级别。在MySQL中,如果使用 InnoDB,默认的隔离级别是Repeatable Read。
关于隔离级别的选择
- 需要对各种隔离级别产生的现象非常了解,然后选择的时候才能游刃有余
- 隔离级别越高,并发性也低,比如最高级别SERIALIZABLE会让事物串行执行,并发操作变成串行了,会导致系统性能直接降低。
- 具体选择哪种需要结合具体的业务来选择。
- 读已提交(READ-COMMITTED)通常用的比较多。
总结
- 理解事务的4个特性:原子性、一致性、隔离性、持久性
- 掌握事务操作常见命令的介绍
- set autocommit可以设置是否开启自动提交事务
- start transaction:开启事务
- start transaction read only:开启只读事物
- commit:提交事务
- rollback:回滚事务
- savepoint:设置保存点
- rollback to 保存点:可以回滚到某个保存点
- 掌握4种隔离级别及了解其特点
- 脏读、不可重复读、幻读
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- STL-stack and queue
- MySQL 知识点总结
- 从零开始做题:逆向 ret2text level2_x64
- MySQL高级DBA的理论与实践,MySQL数据库管理员从入门到精通
- 微信小程序怎么引入webview的url是本地的路径
- 【从零开始学技术】Fiddler 抓取 https 请求大全
- 用免费敏捷工具Leangoo领歌做敏捷需求管理
- Qt pro文件
- 2024年腾讯云新用户专属优惠活动及代金券活动汇总
- 【无标题】